

本文转自知乎,本篇主要分享访存的基本原理、面临的主要问题和解法等相关内容。
原文链接:https://zhuanlan.zhihu.com/p/608663298
《What Every Programmer Should Know About Memory》是Ulrich Drepper大佬的一篇神作,洋洋洒洒100多页,基本上涵盖了当时(2007年)关于访存原理和优化的所有问题。即使今天的CPU又有了进一步的发展,但是依然没有跳出这篇文章的探讨范围。只要是讨论访存优化的文章,基本上都会引用这篇论文。
这篇文章也是常读常新的,不同出发点和不同阶段的同学看这篇文章都会有自己的收获。刚入职的时候读了一遍,初窥门径,最近团队的论文分享又读了一遍,有了进一步的理解,这里简单梳理了一下这篇文章自己感兴趣的知识点,初步解答了访存的基本原理,访存面临的主要问题和解法,希望对大家有所帮助。更重要的是,希望能激起大家阅读这篇论文的兴趣。
一 原理
1.1 Cache架构
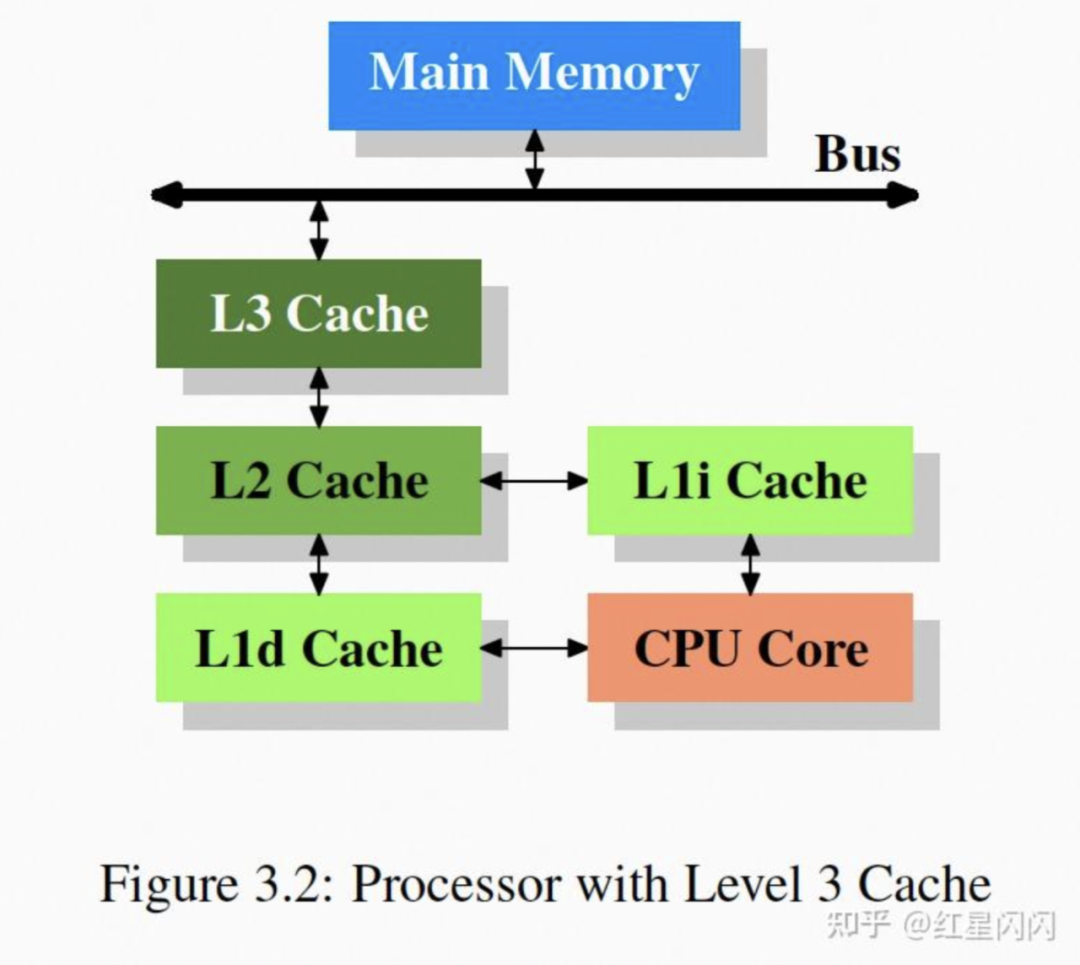
图1
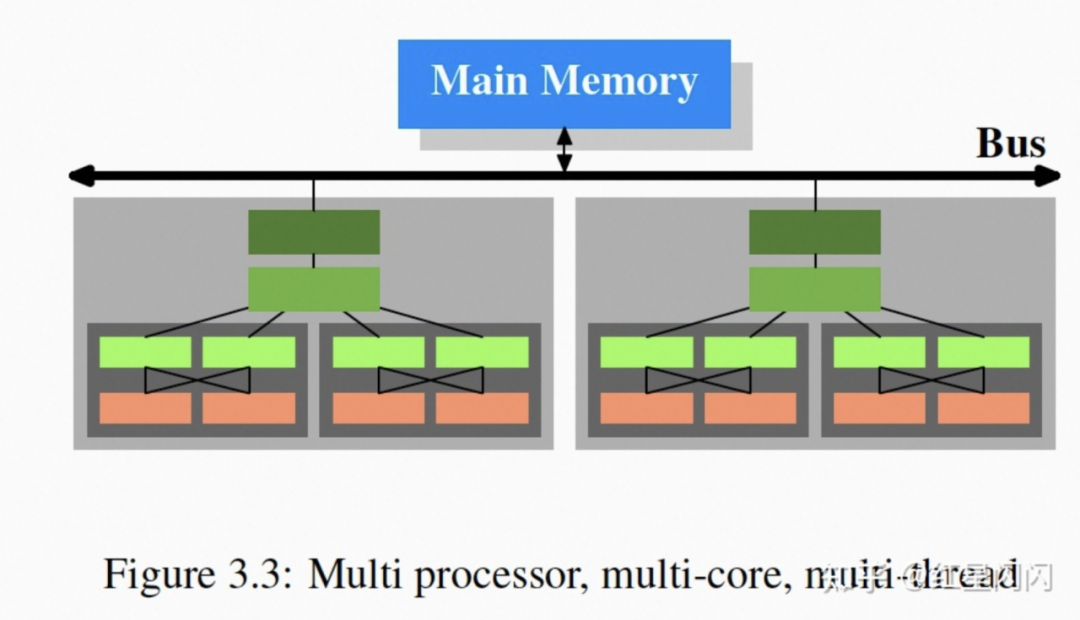
图2
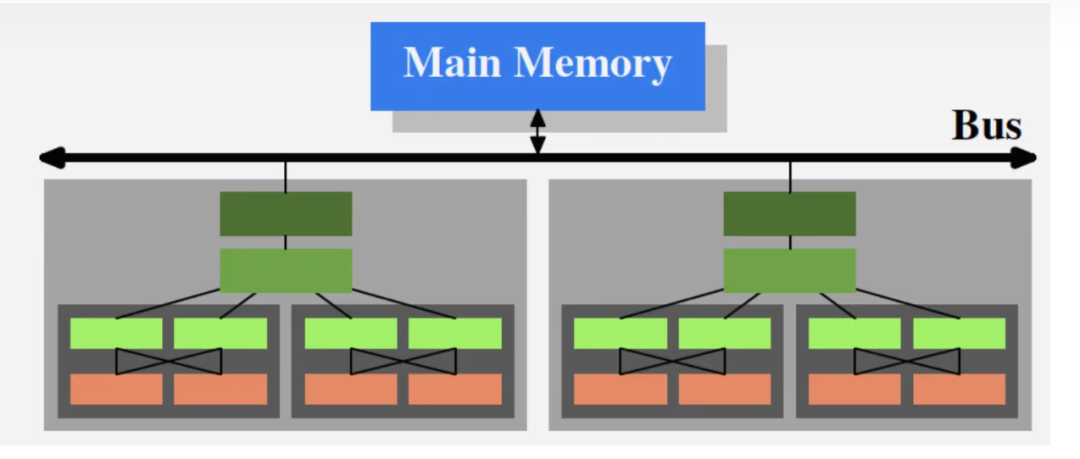
●浅灰色代表一个Processor,代表一个CPU的物理封装,通过总线和内存相连。
●深灰色代表一个物理Core:
每个Core中有两个Hyper-Thread,常见于Intel的CPU,每个H-Thread对上抽象出一个Core,但并没有物理上的拓展,硬件级别进行时间片并发。优势在于,当一个H-Thread执行内存Stall的指令时,可以切换成另一个H-Thread,并不阻塞。
每个Core有一个L1d和一个L1i。两个H-Thread共享通过一个L1指令和数据Cache。
●L2和L3被多个Core共享。
真实场景:
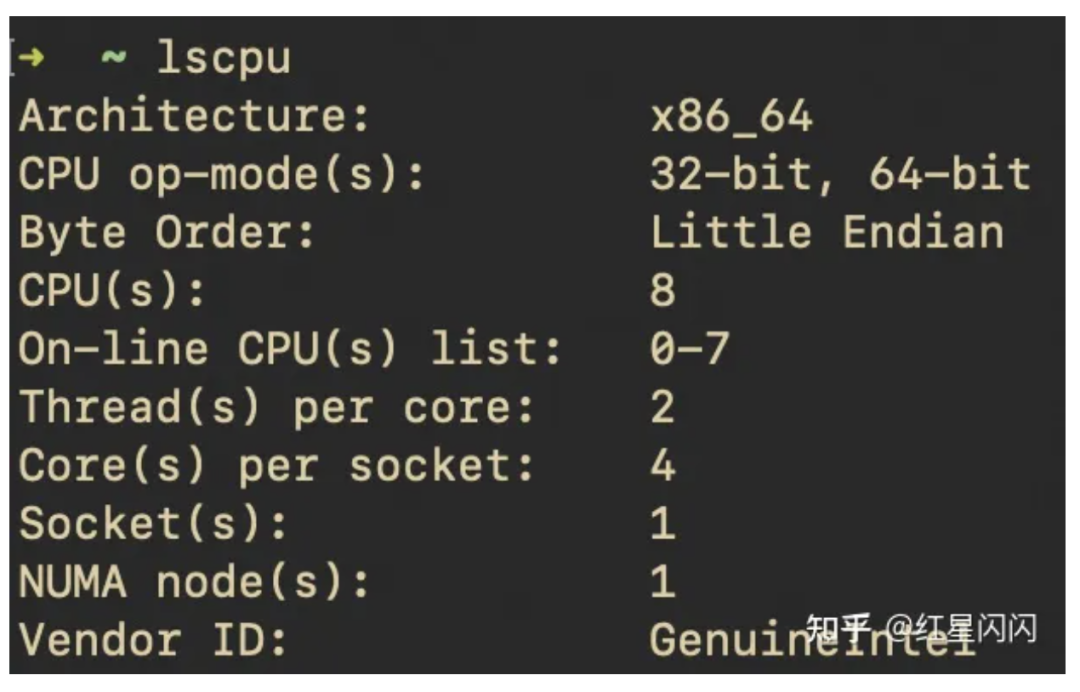
图3
1个物理CPU,里面有4个core,每个core有两个H-Thread。对上层一共暴露142=8个CPU。

图4
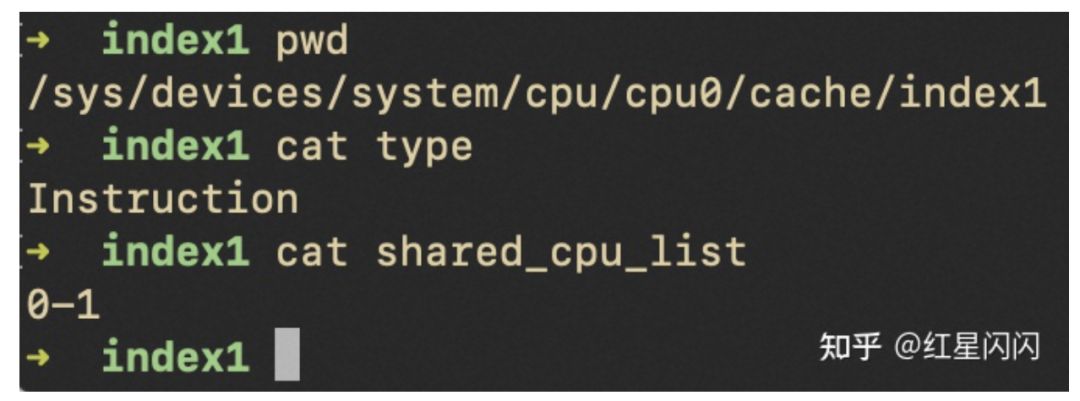
图5
L1的Data和Instruction Cache被同一个Core的两个H-Thread共用。
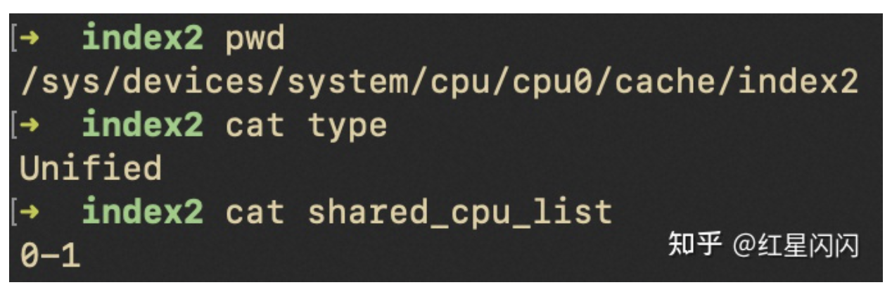
图6
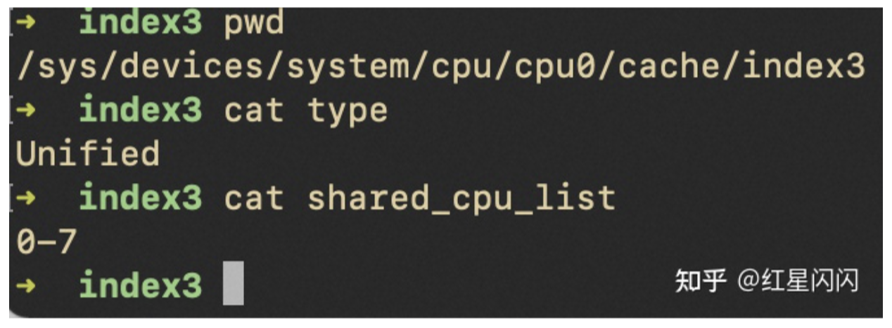
图7
L2和L3都是Unified类型,可以同时存指令和数据。L3被同一个CPU封装里的所有Core共享,和论文所述一致。但是L2有点不一样,只被同一个Core的两个H-Thread共享,不跨Core共享。
1.2 Cache速度差距
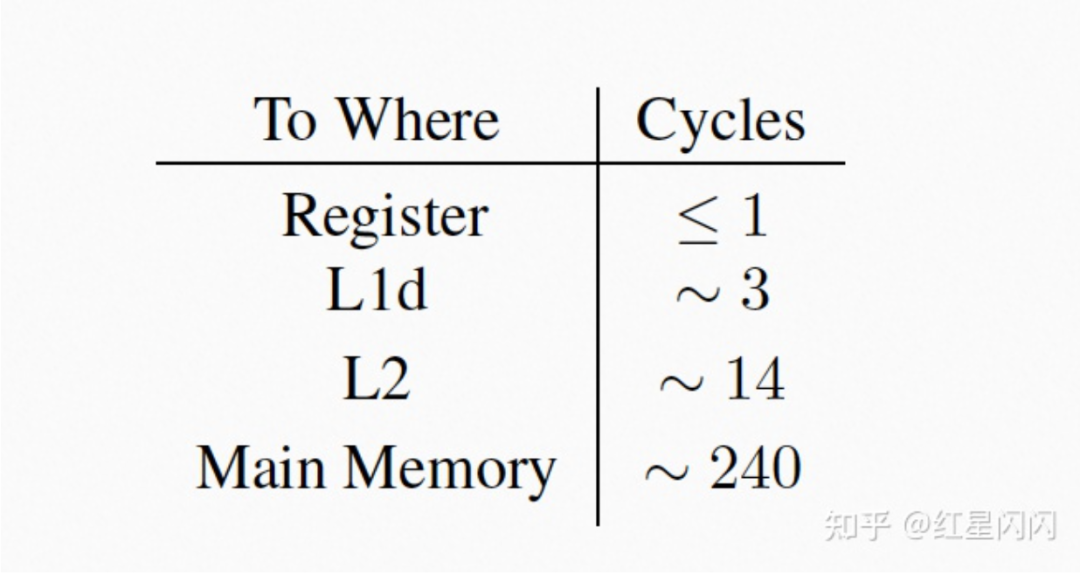
图8
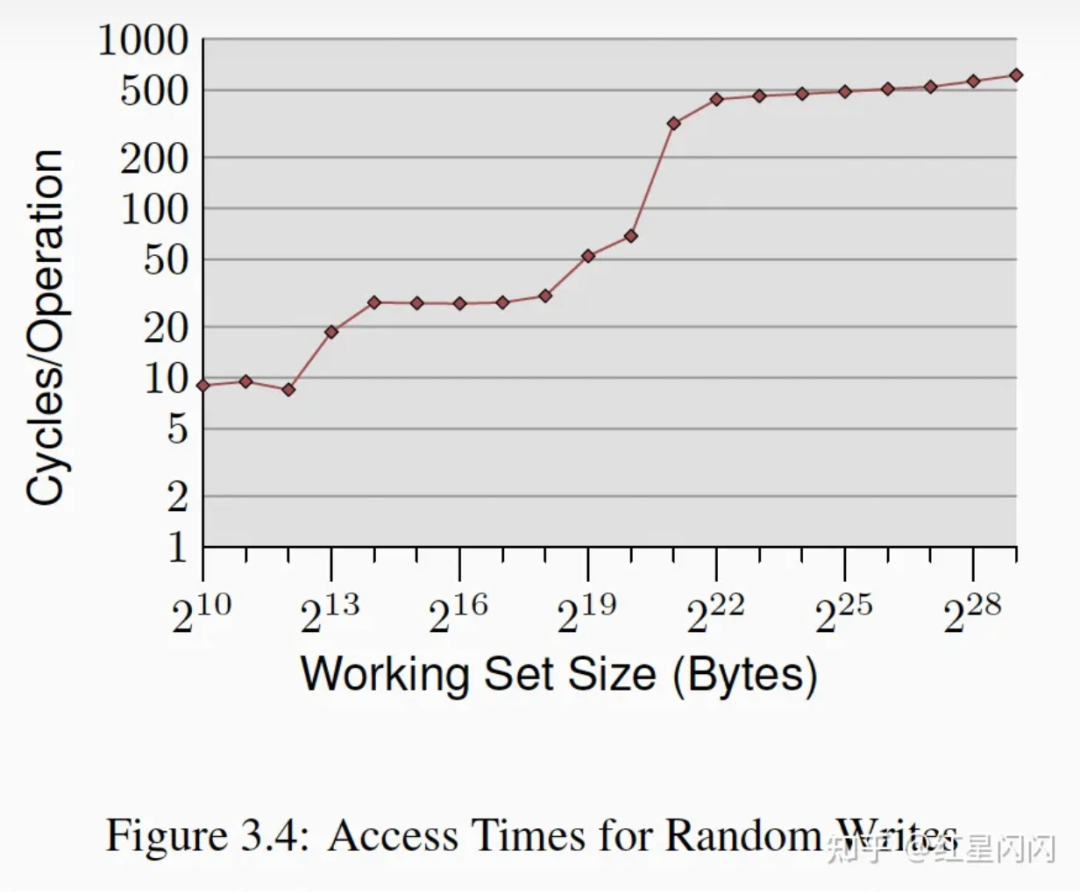
图9
1.3 Cache实现细节
1.3.1 Cache的Key

图10
●T和S一起,唯一标识一个CacheLine,将Cache的组织想象成一个二维数组,通过两个角标T和S定位。
●Offset标识CacheLine里的具体数据位置。一个CacheLine通常是64Byte,所以需要6bit的Offset来定位里面的每个Byte。
1.3.2 Associative Cache
●全路组相连:最朴素的思想,没有Set位,Cache用一维数组的方式组织。查询时直接通过Tag拿到数据。但是当Cache较大时,需要大量的Comp原件,成本高。
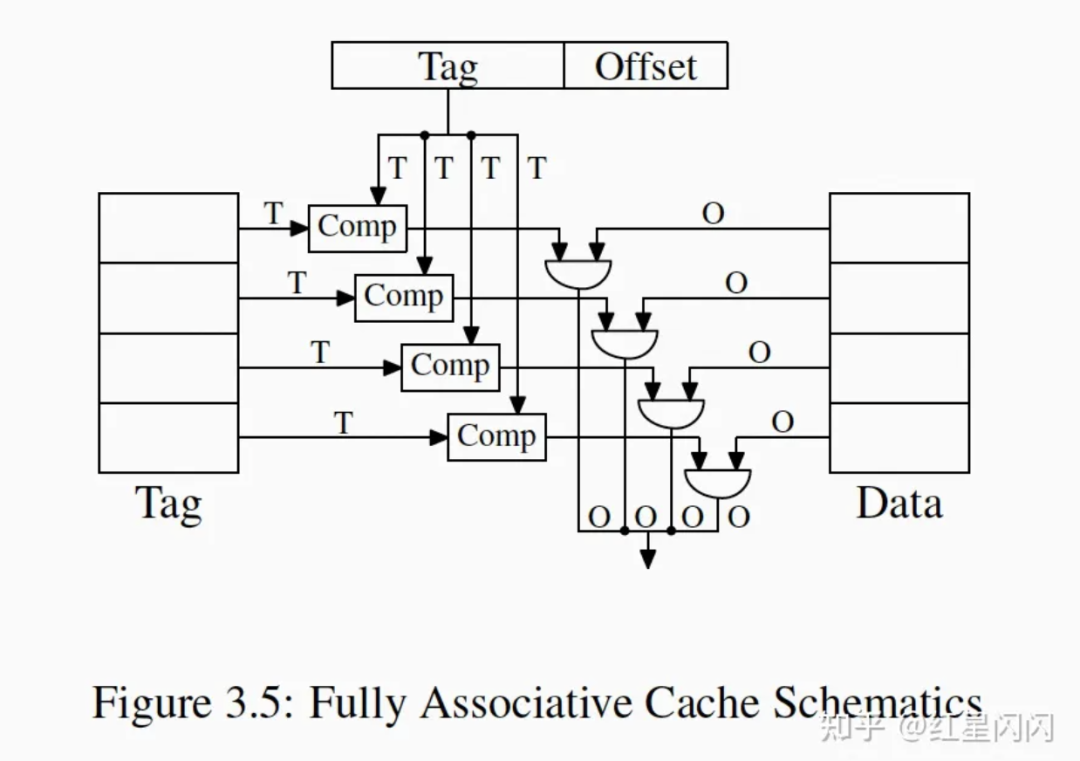
图10
●直接组相连。一个Set里面只有一个CacheLine,给定Set值可以唯一选择(MUX)出一个Tag。
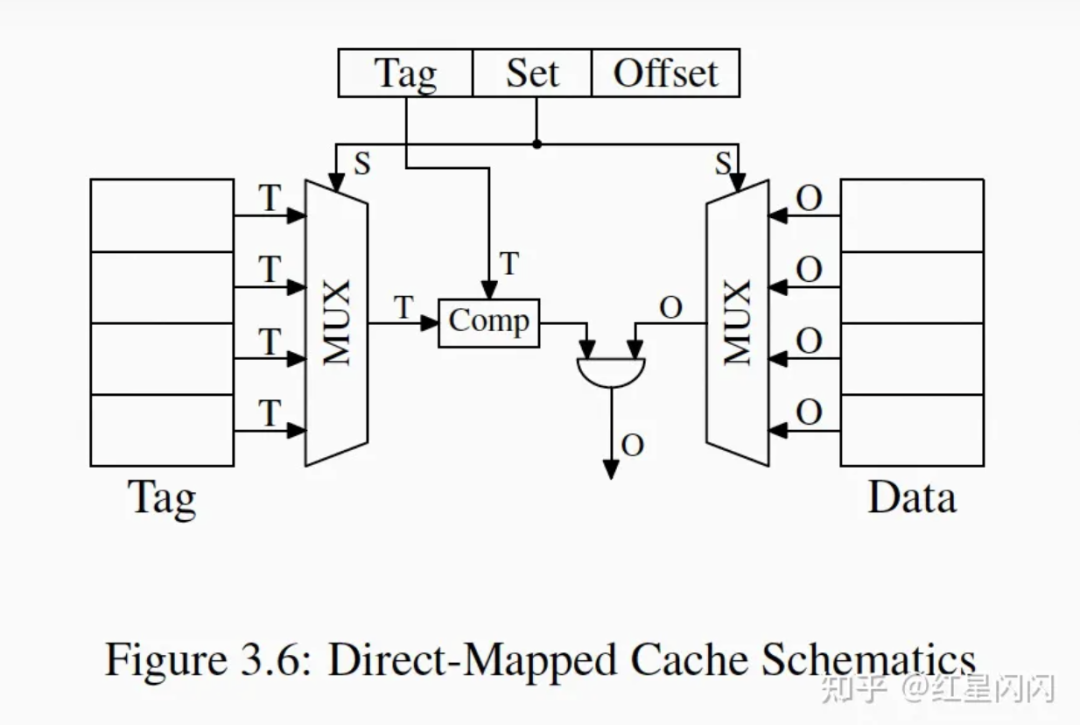
图11
●多路组相连。一个Set里面有多个CacheLine,给定Set值可以选择出多个Tag,再通过Tag,拿到数据。
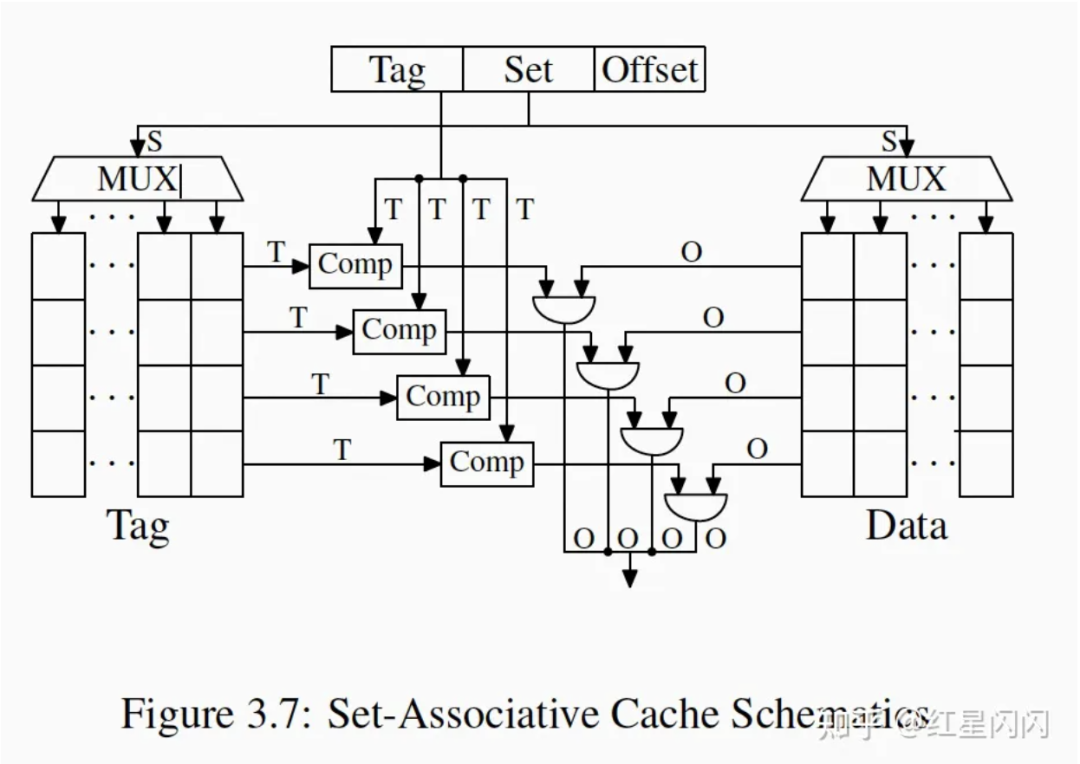
图12
下图是各种组相连的性能数据:
●Cache越大CacheMiss越小
●组数的提升有利于CacheMiss的减少
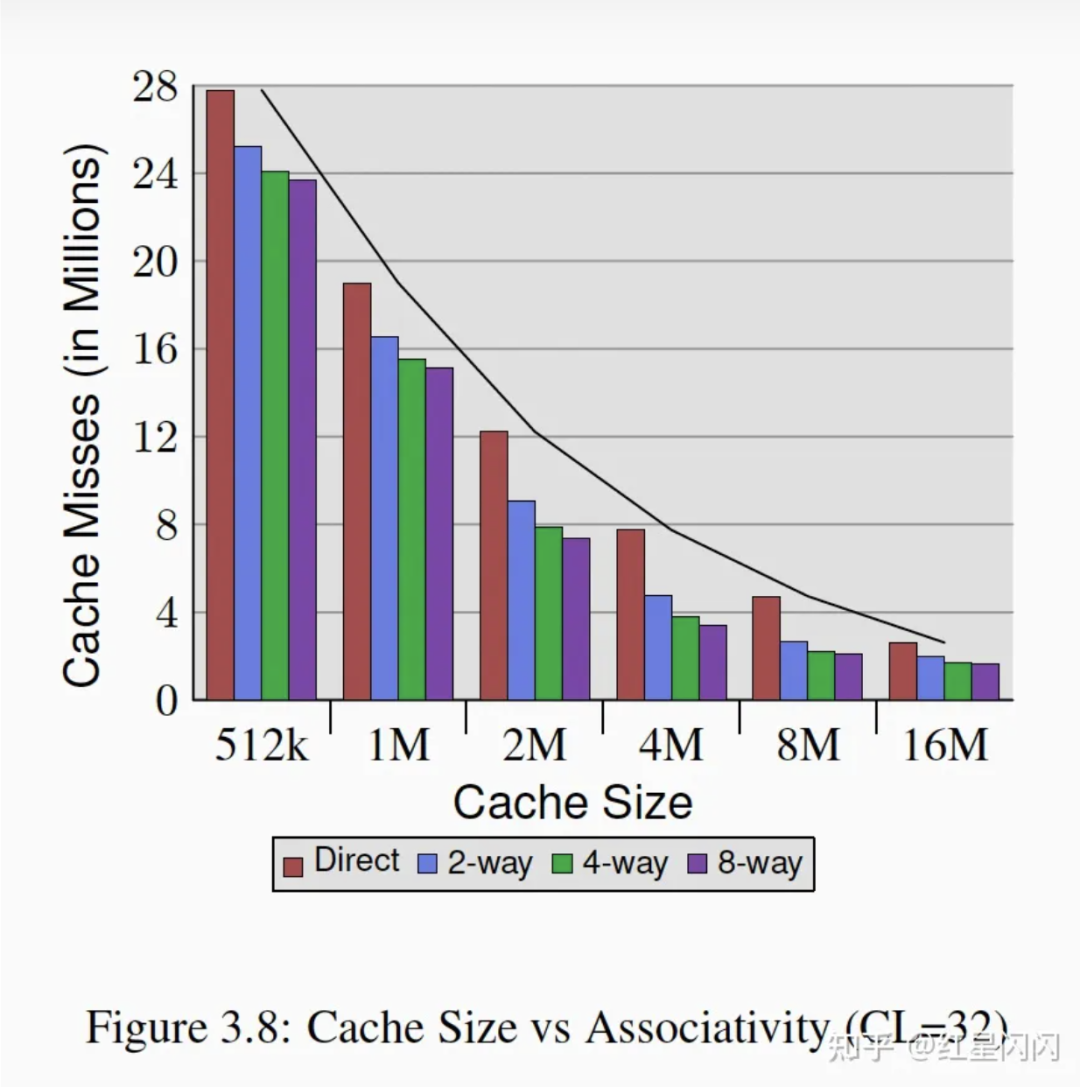
图13
1.4 Cache实验
1.4.1 实验设计

图14
在内存中开辟一块连续的内存初始化成结构体数组,每个结构体如上图所示。有两个变化点:
●指针n(如下图所示):
依次指向下一个item,顺序访问。
随机指向一个item,随机访问。
●填充数据pad:用于增加减少两个item的内存距离。
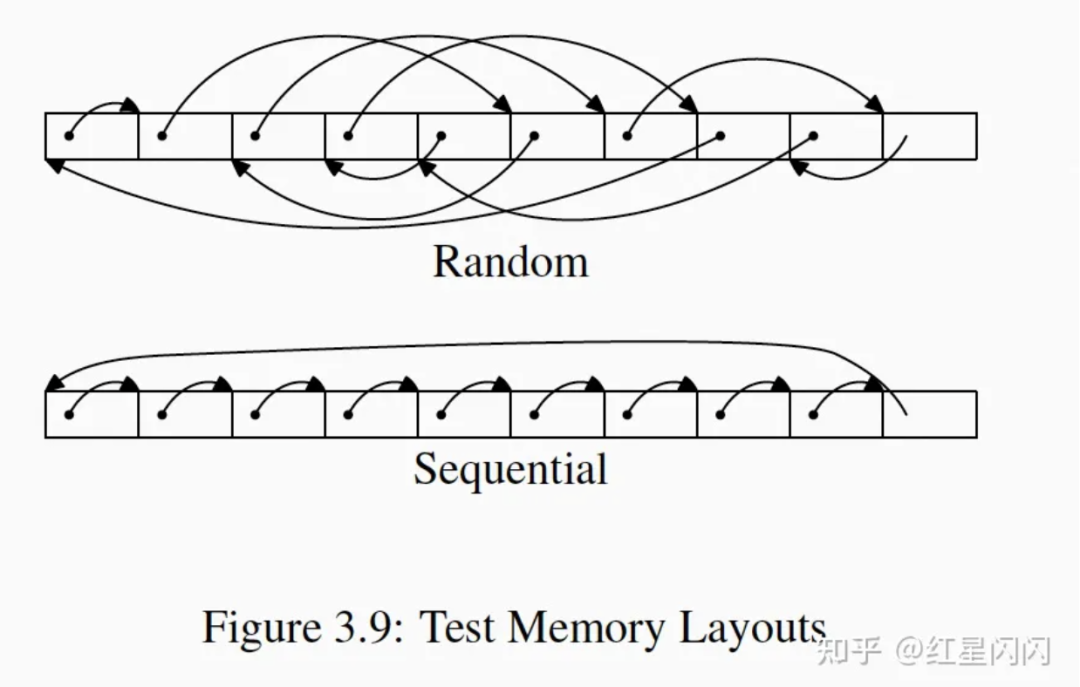
图15
1.4.2 实验结果与分析
NPAD=0顺序读
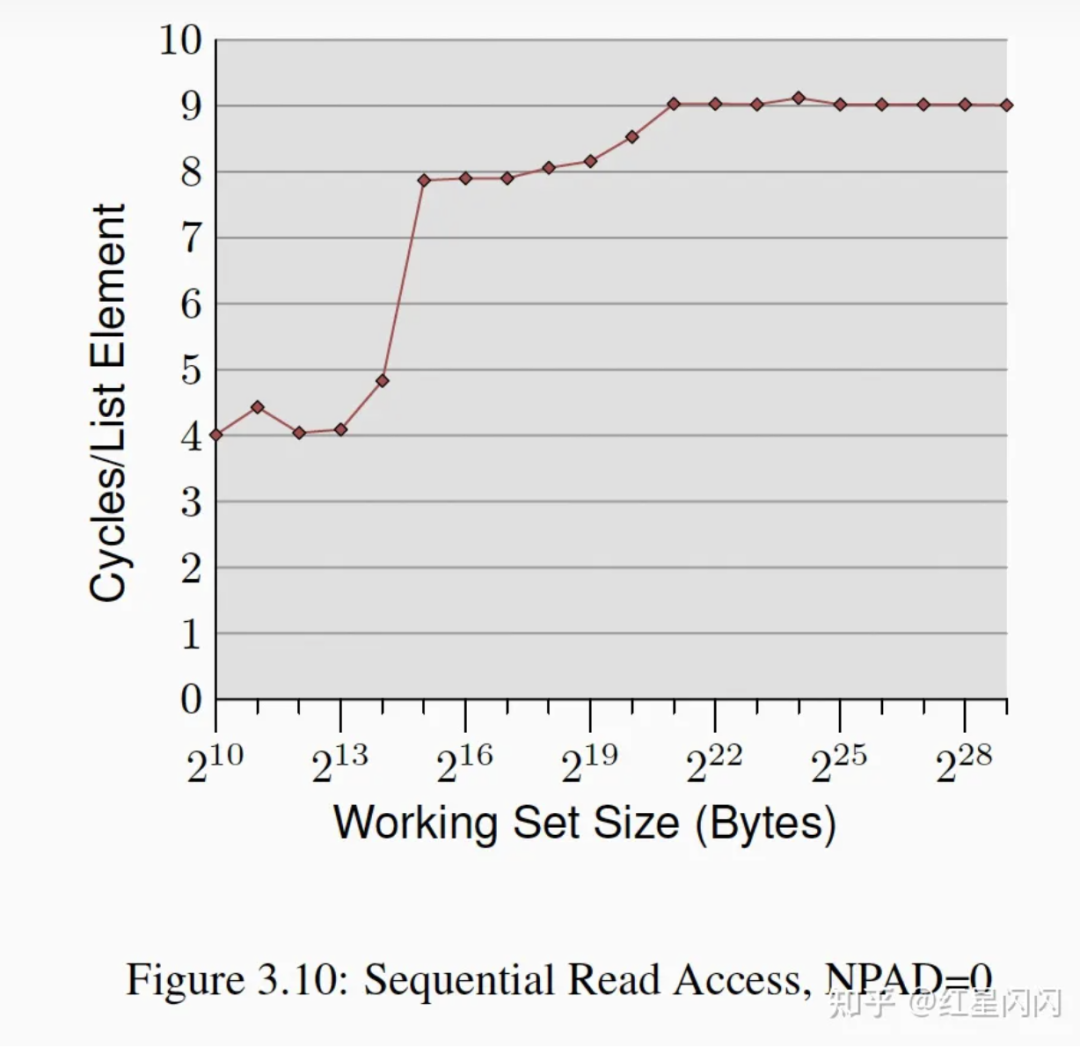
图16
上图是NPAD=0的顺序访问,实际上就是顺序遍历一个数组:
●总体耗时曲线都比较低。最大也就9个Cycle,这是因为顺序访问会触发CPU硬件预取,减少了CacheMiss。
●有3个较为明显的台阶。分别对应L1,L2和Memory。不是有预取么?为啥还有有差异?这是因为访问数据时还没有完全预取上来,会有一定的Memory Stall,但这个Stall时间远远小于Cache Miss的时间。
不同NPAD的顺序读
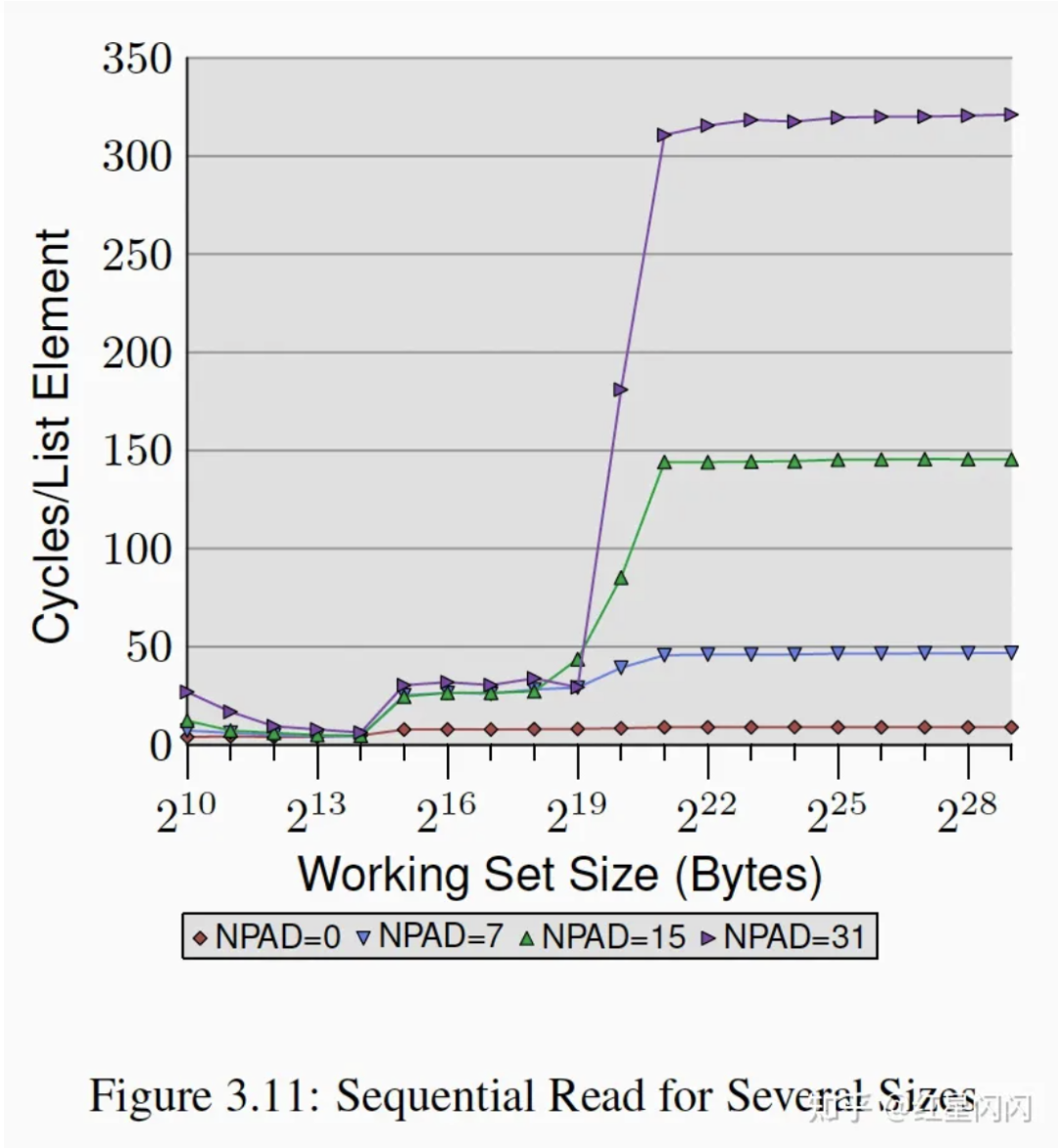
图17
NPAD的增加,意味着顺序访问的步长增加:
●NPAD=0就是前面的图3.10,在这张图里基本上是一条直线。
●在L1 Cache内,NPAD的差异基本对性能没有影响,不涉及任何的预取。
●在L2Cache内,NPAD=0除外的3条线基本在一起,并高于NPAD=0的用时。这和CacheLine相关,CacheLine的Cache的基本单位,通常是64Byte:
当NPAD=0时,sizeof(struct_l)=8Byte,一个CacheLine可以装8个Struct元素。一次预取可以支持8个元素的访问。
当NPAD=7时,sizeof(struct_l)=64Byte,一个CacheLine只能装1个Struct元素。一次预取只能支持1个元素的访问。
当NPAD>7时类似。
一方面,因为每次预取通常只是减少MemoryStall,无法完全消除,平均每次访问所需要的预取次数越多,耗时越多。另一方面,更多的预取也可能占用更多的内存带宽,降低速率。
●超出L2后需要访问内存,4条线的差异很大,主要有三个原因:
Prefetch无法完全消除Memory Stall。被访问的数据虽然被预取,但是在访问时还没有完全加载到Cache中。这个原因可以解释NPAD>=7的3条线高于NPAD=0,但是无法解释NPAD7,15,31的差异。
PageBoundaries的影响。一个物理页通常是4KB,在物理页边界时无法预取,因为PageFault需要操作系统来调度,CPU做不了。当NPAD越大,达到PageBoundaries所需要的元素个数越少,每次PageBoundaries开销均摊下来也就越大。
TLB表Miss。假设有N个TLB表entry,平均访问了N*4K大小后,会触发一次TLB表Miss。如果NPAD越大,达到TLBMiss所需要的元素个数越少,每次TLB表Miss开销均摊下来也就越大。
触发TLB表Miss的场景
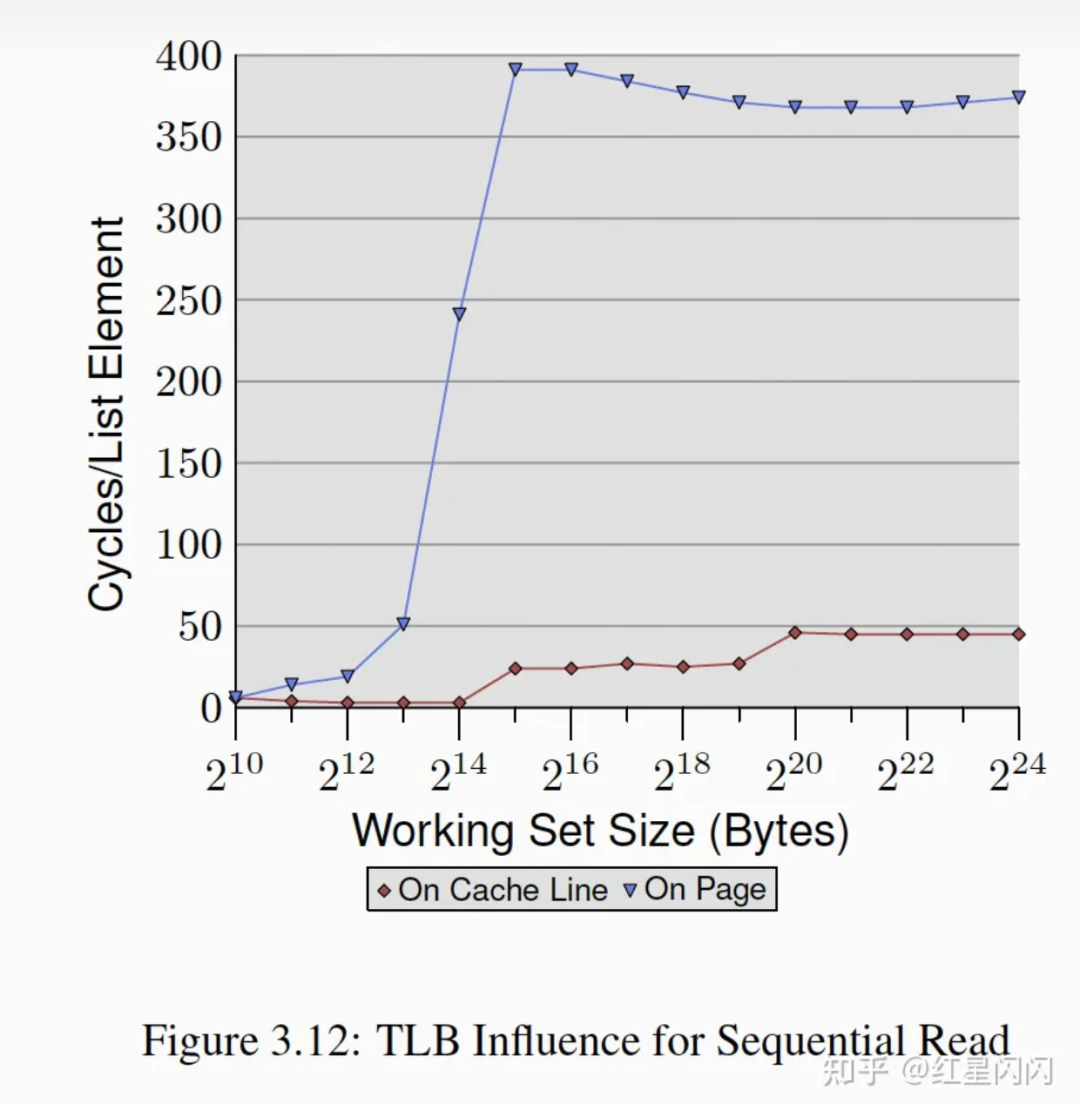
图18
●On Cache Line表示一个数组元素的大小为64Byte,也就是一个CacheLine大小,也是图3.11中的NPAD=7。
●On Page表示一个数组元素大小为4K,也就是一个物理页大小,每次指针跳跃会跨越一个Page。
●计算Working Set Size的逻辑不太一样:
OnCacheLine的逻辑是计算真实消耗的内存,一个数组元素消耗的真实内存是64B,WorkingSetSize也是64B。
OnPage的逻辑是指计算一个Page个中的CacheLine大小。一个元素占用了一个Page的大小(4K),但是只算一个CacheLine的大小(64B)。
也就是说,同样是64B的WorkingSize,OnCacheLine消耗真实内存64B,OnPage消耗真实内存是4K。
为啥做这么奇怪的规定?因为数组元素的大小只是决定顺序访问的Stride,每次访问的只有第一个指针,只访问一个CacheLine。
●可以看到从2^13开始OnPage飙高,这意味着2^12刚好可以装载TLB中,也就是2^12/2^6=64个Page(如前面所述,一个Page在WorkingSize中只算64Byte)可以推算出这台机器的TLB表有64个entry。
●作者特别强调了这个实验进行了内存锁定,不会有Page Fault的影响。
●虽然Stride是一个Page,但是每次只是访问一个CacheLine,为什么Cache没有生效?L2的key是物理地址,需要先经过TLB的转换,所以失效。L1通常是依照逻辑地址,但是载入L1之前需要先载入到L2,所以也受TLB限制。
●超过64*4K=2^18Byte就会触发TLB Miss,TLB Miss的开销是很大的。这也解释了图3.11的NPAD=31为啥在顺序访问主存用时为300多Cycle,这台机器的理论主存访问为240个Cycle。
随机读
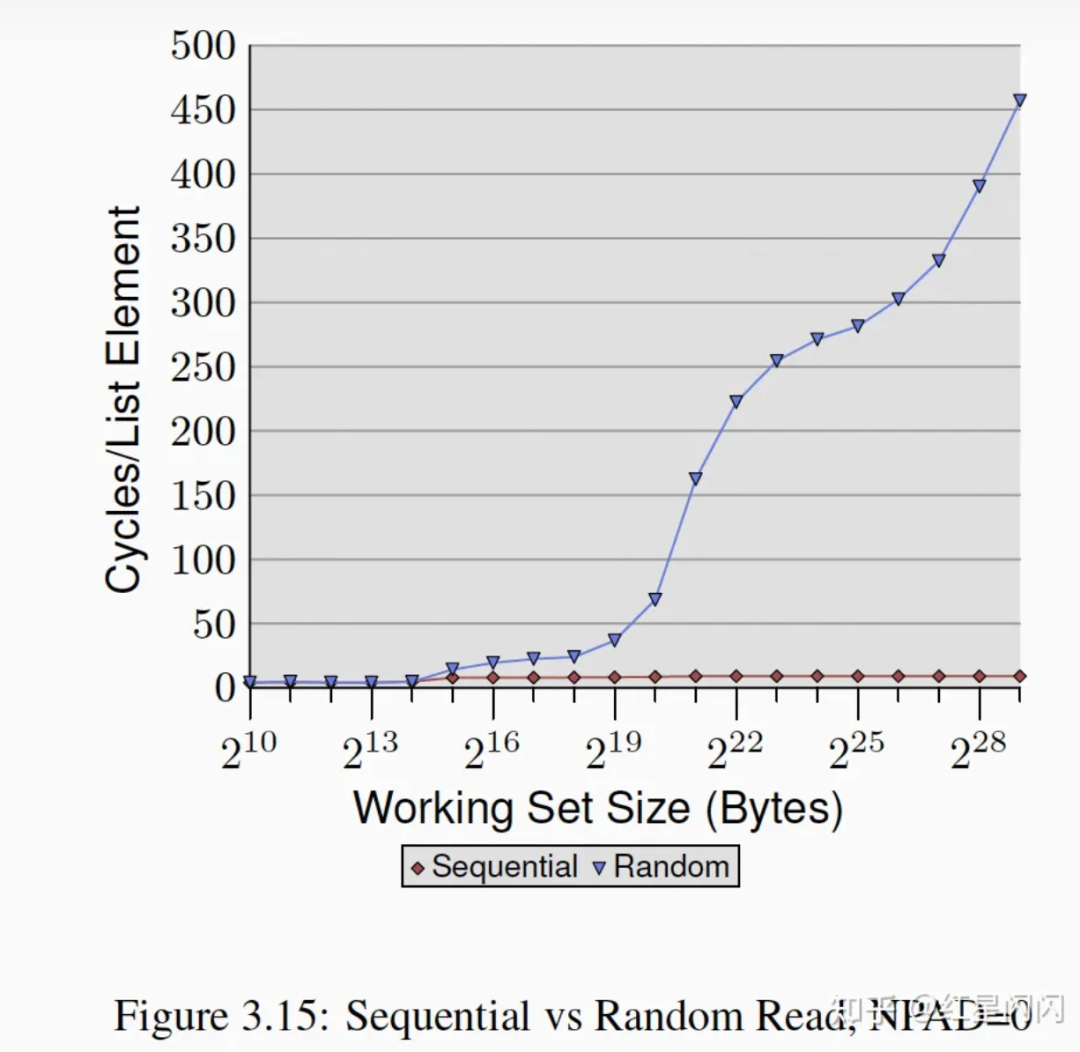
图19
●在L1内,随机读和顺序读没有本质差别。
●超出L1后,顺序读和随机读逐渐拉开差距,顺序读基本上是一条水平线,开销很小。
二 实践
2.1 绕开Cache
Cache被无关数据占据称为Cache污染,我们需要尽可能减少Cache污染,提高Cache利用率。
一种经典的Cache污染场景就是写数据。对于写数据,CPU的通常行为是只修改Cache中的数据,标为脏数据,并不急于写入内存。当被写脏的CacheLine被淘汰时(或定时刷内存时)进行真正的落内存。这通常是有效的,比如对临时变量的反复读写,可以一直将这个临时变量装载Cache中,最后只落一次内存。
但也存在另外一种场景,就是写完数据后很长一段时间并不会用到,此时采用“写回”的Cache模式就很浪费,Cache住的脏数据占据了Cache,但实际上并不会被用到。此时可以考虑使用“写穿”的模式,“写穿”不是默认行为,需要调用特定的API,称为Non-temporal接口。
“写穿”需要进行内存访问,所以很慢,但是现代CPU有“write-combining”机制可以解决这个问题。设计实验如下:

图20
分配一个二维数组,每一行的数据在物理内存上连续,每列数据在物理内存上不连续(也就是按行存)。左边是行优先遍历,右边是列优先遍历。
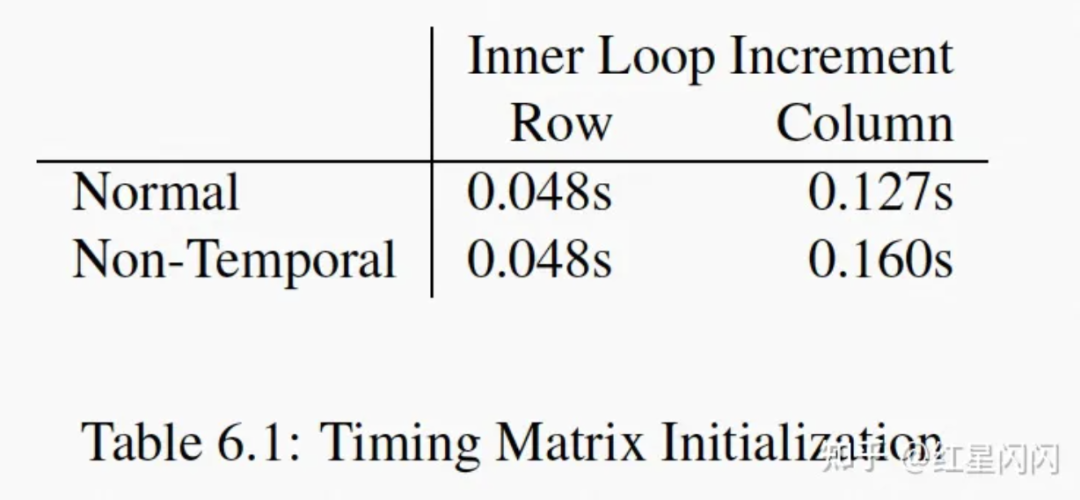
图21
遍历耗时如上图所示,在行优先的场景下,Non-temporal的性能和Normal的性能一样。Non-temporal需要直接写到内存,为什么速度和Normal这种写Cache的一样?
这获益于CPU的“write-combining”机制。CPU有特殊的硬件,会积攒属于同一个CacheLine的写内存数据,直到收到的写入数据不属于这个CacheLine,将之前积攒的数据“批”写入到内存。然后积攒新来的这个CacheLine。
行优先时,写入的数据物理上连续,所以触发“write-combining”,有提速。列优先时,写入的数据物理上不连续,无法“write-combining”,所以写穿会更慢。
有的CPU还提供类“读穿”的功能,配合combining机制,也可以做到既不退性能,也不污染Cache。
此外,这个实验还告诉我们一个道理,尽可能优化算法变成顺序访问,现代CPU有很多优化顺序访问的机制。
2.2 优化L1 Data访问
2.2.1 算法优化
主要是调整算法,提升代码的时间和空间局部性。以矩阵乘法为例:
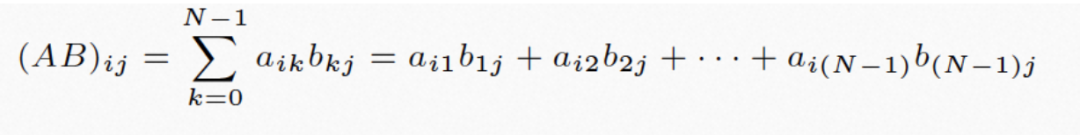
图22
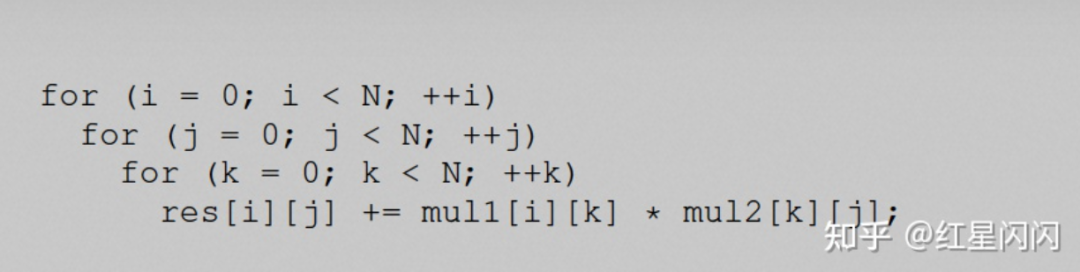
图23
根据前面的论述,最里面循环的mul1是行优先遍历,访存友好,mul2是列优先遍历,访存不友好,有优化空间。
根据数学变化,调整代码如下:
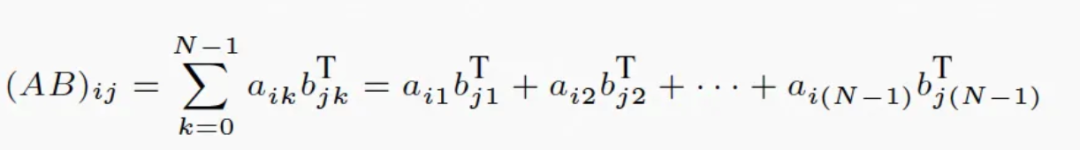
图24

图25
首先对mul2进行了矩阵转置运算,用一块临时内存tmp存下来。然后使用tmp矩阵和mul1进行运算。mul1和tmp都是行优先遍历。前面做转置的时候,mul2也是行优先遍历。整个算法都是行优先,访存友好。效果很好,提速了76%。

图26
转置算法消耗了额外的内存,我们希望可以不消耗额外内存进行优化,如下:

图27
SM通过宏定义,代表一个CacheLine可以装下的double个数。将一个大矩阵拆分成了长宽为SM的小矩阵进行分治计算。小矩阵中非连续访问的内存距离不超过一个CacheLine的大小。效果略好过转置方案。
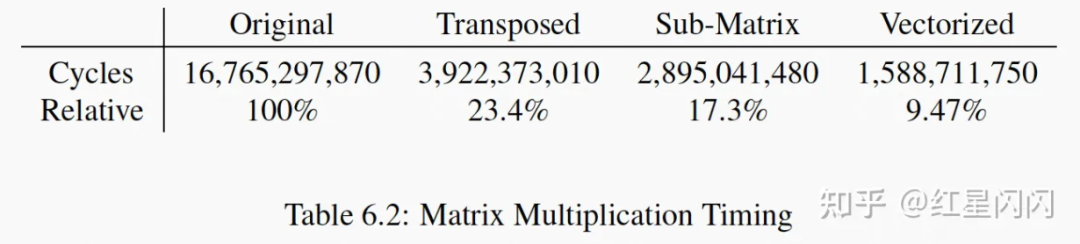
图28
2.2.2 数据结构优化
2.2.2.1 结构体内部对齐

图29
对如上结构体,使用pahole分析出具体的内存布局:

图30
●结构体内部按照操作系统位数对齐,32bit系统按照4Byte对齐,64bit系统按照8Byte对齐。
●最右边的注释表示数据的起始位置,和占用的数据大小,比如第一个成员int a,在结构体偏移为0的地方开始,占用了4Byte。
●按照8Byte对齐,所以在int a之后需要填充4个Byte进行对齐,这里产生了1和hole,大小为4Byte。
●一个CacheLine是64Byte,在long int数组结束后使用完了一个CacheLine的大小,下面的成员只能分配到下一个CacheLine中。
一个显然的优化是调整成员b的位置,将其放在成员a后面,这样有两个好处:
●消除了因为对齐产生的空洞。
●整个结构体的大小刚好可以装进一个CacheLine。
除此之外,为了尽可能避免跨CacheLine访问,还需要:
●尽可能把经常用到的结构体元素放在最前面。
●访问结构体时,如果没有特别的业务逻辑需要,尽可能顺序访问结构体里的元素。
2.2.2.2 结构体外部对齐
在满足上述结构体优化后依然是不够的,一个结构体大小即使在一个CacheLine大小内,但如果起始位没有CacheLine对齐,依然会跨CacheLine访问。所以,还需尽可能做到CacheLine对齐。
Malloc分配出来的结构体是8(32bit系统)或者16Byte(64bit系统)对齐的。也就是说Malloc出来的对象在64bit系统中的起始地址一定是16的倍数,用十六进制表示,结尾一定是0,简单实验一下:
printf("address t: %x\n",malloc(sizeof(st)));printf("address c: %x\n",malloc(sizeof(char)));printf("address x: %x\n",malloc(sizeof(int)));printf("address y: %x\n",malloc(sizeof(long)));
输出:
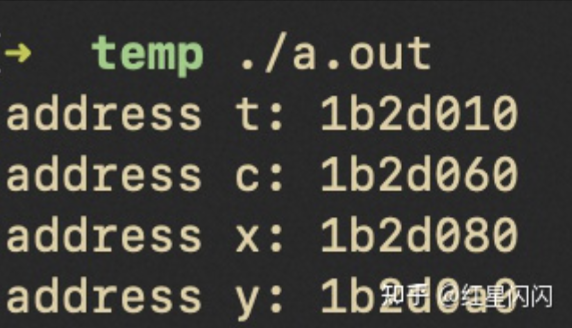
图31
按照16Byte外部对齐可能跨CacheLine,进而导致性能问题。如下,一个结构体的size为32Byte,Malloc可能把它放在地址48上(16Byte对齐)。但这跨CacheLine了,需要加载两个CacheLine才能读取这个数据。
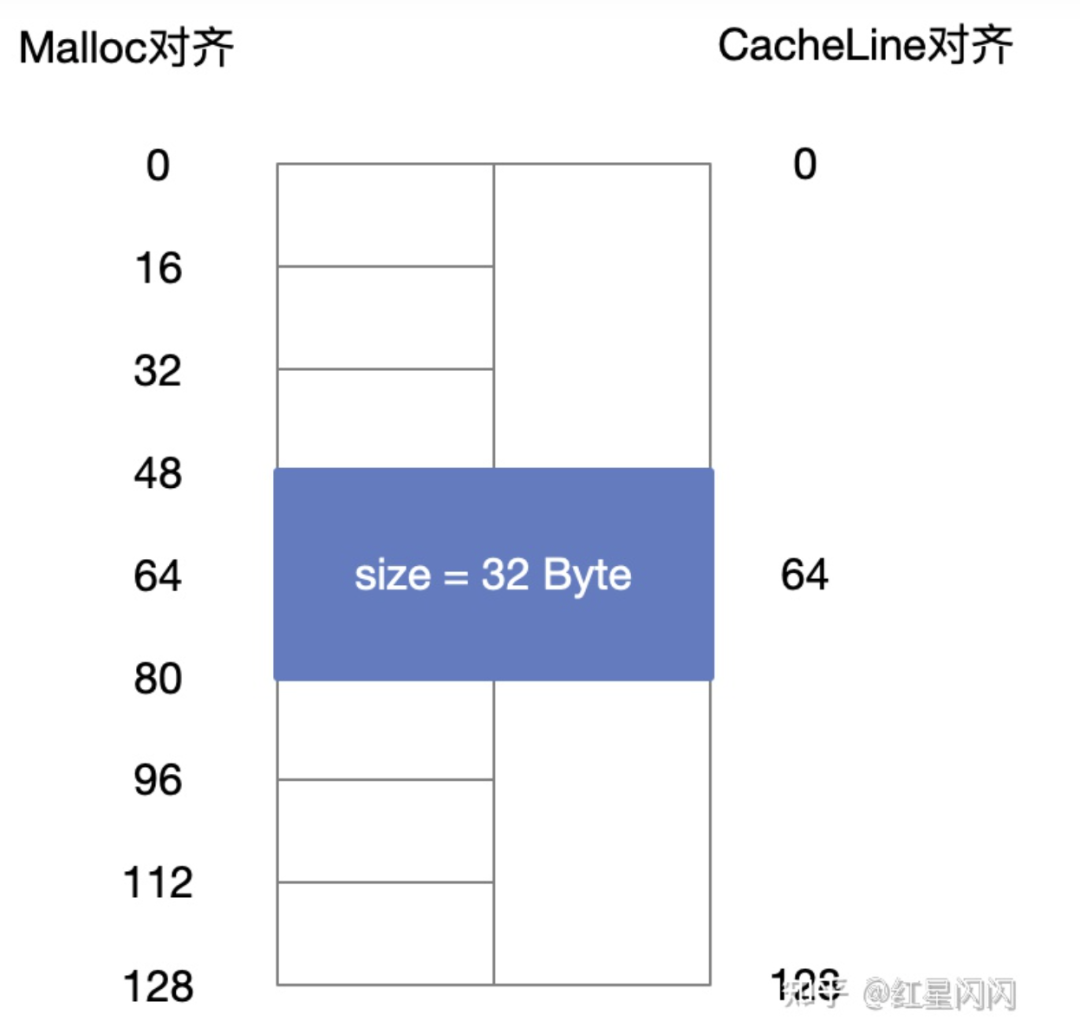
图32
直接使用接口指定对齐字节

图33
void * x2;posix_memalign(&x2,64,sizeof(int));printf("address x2: %x\n",x2);void * x3;posix_memalign(&x3,64,sizeof(long));printf("address x3: %x\n",x3);return 0;
结果如下,地址一定是64的倍数,也就是6个0结尾。

图34
在声明时指定对齐字节
如果是零时变量怎么对齐呢?

图35
struct _st st3 __attribute((aligned(64)));char c3 __attribute((aligned(64)));printf("address st3: %x\n",&st3);printf("address c3: %x\n",&c3);

图36
在定义处指定对齐字节
上述两种方法都有一个问题,如果是数组的话,只能对齐第一个数据:
struct _st st3[4] __attribute((aligned(64)));printf("address st3: %x\n",&st3[0]);printf("address st3: %x\n",&st3[1]);
第二个元素没有64byte对齐。

图36
解法是在定义出指定对齐字节。
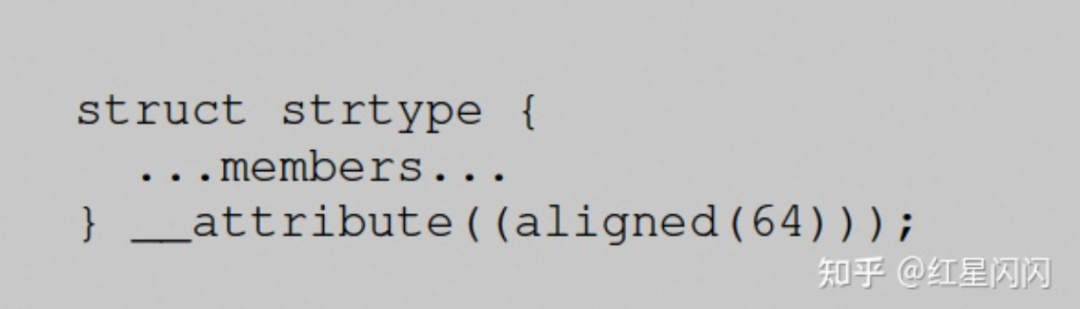
图37
typedef struct _st{int a;long fill[7];int b;} __attribute((aligned(64))) st;struct _st st3[4];printf("address st3: %x\n",&st3[0]);printf("address st3: %x\n",&st3[1]);
输出如下,每个元素都是对齐的。

图38
CacheLine对齐不是没有代价的,会产生大量空洞,消耗更多的内存。
未对齐较之于对齐后的性能回退如下图,未对齐的耗时都会增加,在Cache大小内的耗时增加更大。Random在L2中没有对齐的时间增加较少,这是因为随机访问本来的耗时基数较大,对齐与否的影响层度减弱。
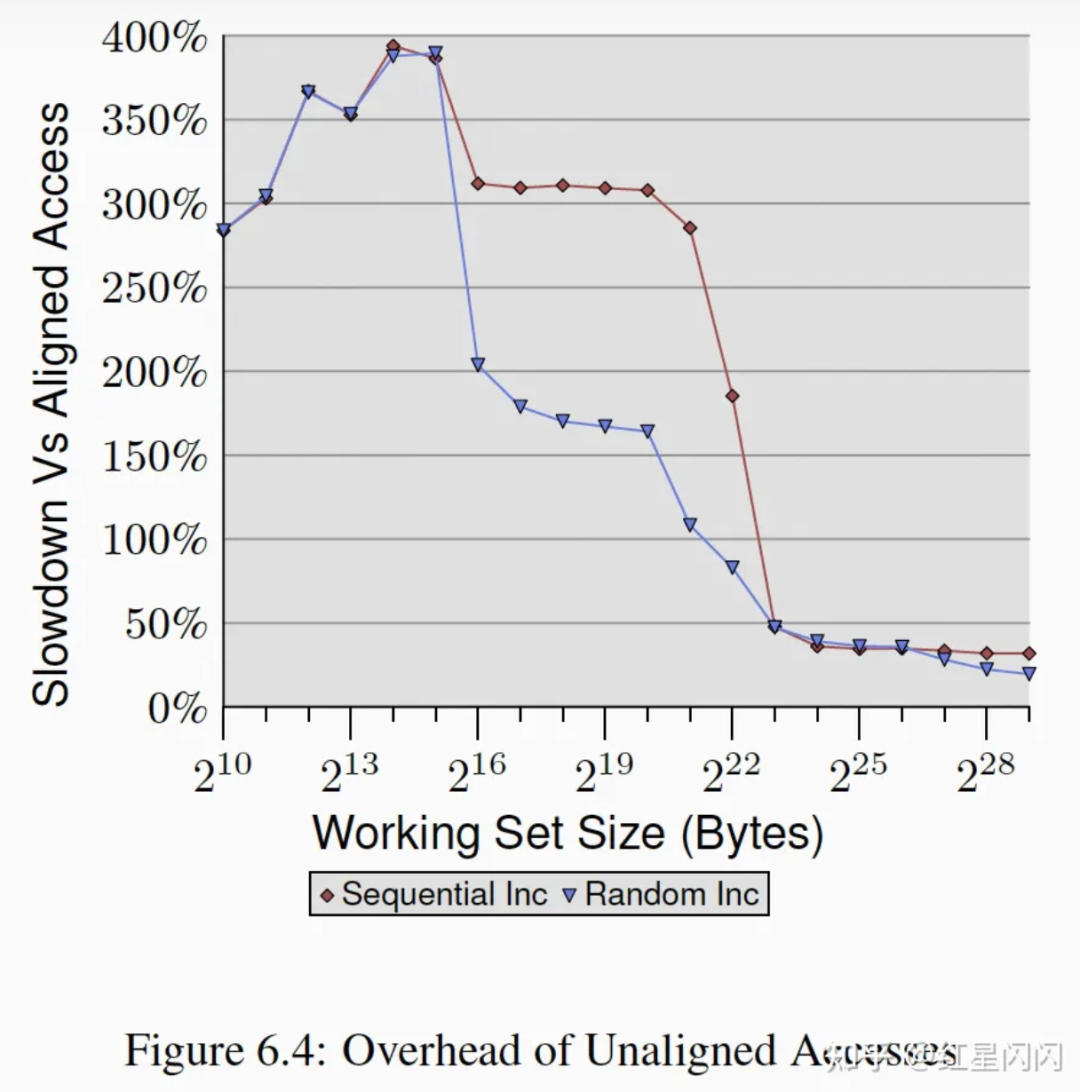
图39
2.2.2.3 结构体的拆分
如下图,通常我们会按照业务逻辑封装对象。

图40
根据使用成员的频率进行拆分,有利于提升性能。比如,上面的结构体中的price和paid经常用到,buyer和buyer_id不常用到,拆分成两个独立的结构体,对于price和paid组成的新结构体而言,有效数据密度更大,Cache的效果也越好。但这样的拆分会引入代码的负载度,要根据实际情况进行判断。
2.2.2.4 避免触发conflict misses
现代CPU都采用多路组相连,在没有占满整个Cache的情况下,由于占满了一个set,导致的Cache的淘汰。
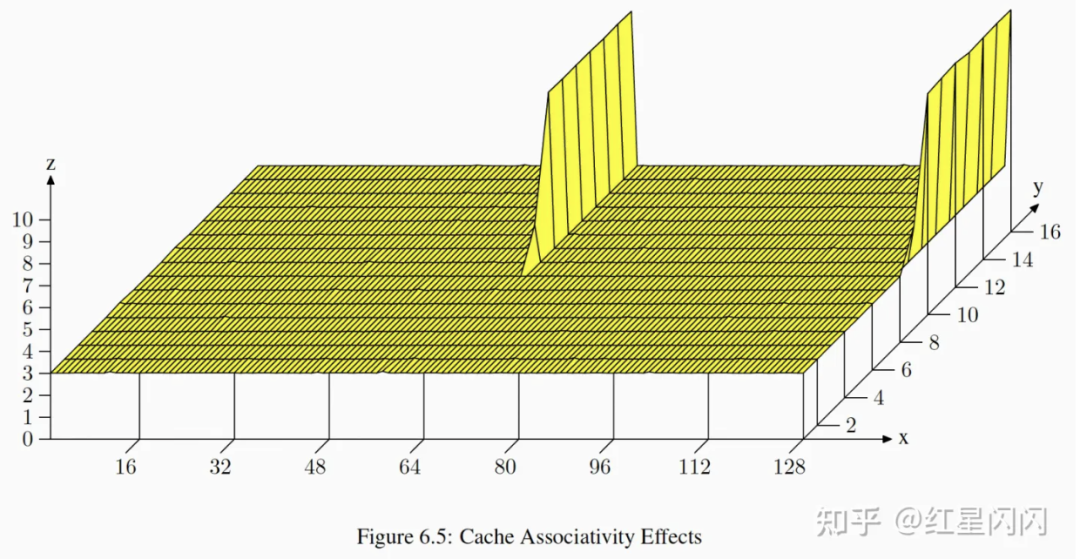
图41
●实验的目标是验证conflict miss。L1的Key是逻辑地址,L2是物理地址,我们无法控制物理地址的访问,所以只能验证L1的Conflict miss。构造一个前文多次提到的链表,每个节点的NPAD=15,节点总大小是64Byte,一个CacheLine大小。按照一定的Stride进行多次遍历。
●X坐标表示访问的Stride距离,也是链表节点的距离,比如说距离为2,就是相隔两个链表节点,64*2Byte。Y坐标表示链表的总长度。Z表示耗时,单位是CPU Cycles。
●水平面是3个Cycles,刚好是L1的访存速度。
●此CPU是8路组相连,地址按照4096Byte(64距离* 64B的CacheLine)取模选择Cache Set。所以,距离是64的倍数,每次访问链表节点都会落入同一个Cache Set,当List的长度超过8,CacheSet一定会满,进而把之前的CacheLine挤掉。再一次遍历时,无法命中,还需要再一次加载Cache。
2.3 其他Cache优化
2.3.1 优化L1 Instruction访问
主要有3个优化方向:
●减少代码体积。但这需要和unloop和inline优化做好权衡,因为unloop和inline会增加代码体积。
●应该减少代码空洞。主要是减少代码中的jump指令,顺序执行的预取友好的。
●如有可能,对代码本身进行对齐,避免跨CacheLine。
具体做法有:
●使用-Os编译选项优化CodeSize。会关闭掉影响CodeSize的优化项,比如inline和unloop,具体谁更快,需要测试。
●inline可能加剧代码空洞,如下图,如果代码块B不是经常走到,inline后会增加A和C之间的代码距离。
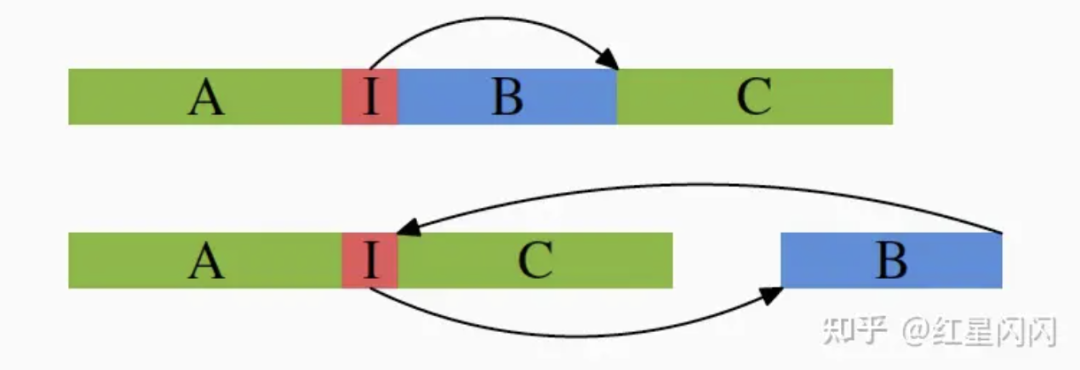
图42
●分支判断失败的开销很大,一方面是L1i的CacheMiss,另一方面还需要重新decode指令。消除的方式有两种:
两次编译,第一次收集分支统计信息,第二次正式编译利用统计信息选择概率更大的分支。
手动指定预测分支:
//接口long __builtin_expect(long EXP, long C);//宏定义//使用if (likely(a > 1))
●代码对齐。通常有3中对齐场景:
函数对齐
分支对齐
循环对齐
函数和分支对齐直接jump到对齐代码块即可,没有什么开销。但循环的代码对齐不一样,loop代码块通常是紧接着其他的顺序代码后面的,要对齐只有两种办法:
●插入无效指令占位
●显示jump一次
这两种方式都是有开销的,所以,只有当循环次数很大时才有必要循环对齐。
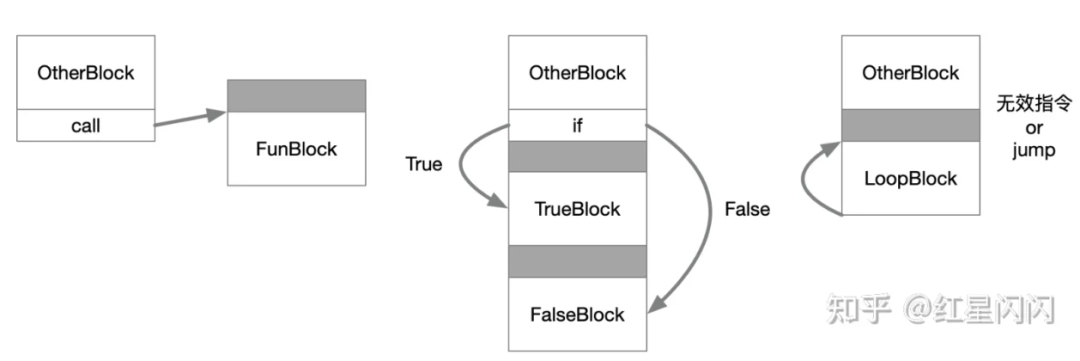
图43
2.3.2 L2 优化
L2Cache(在文中是最后一个Level的Cache)的优化和L1基本一致,但是有两个点比较特殊:
●如果Miss,开销更大。L1Cache不住,还可以L2Cache,性能损失有限。L2Miss就要访问内存了,开销很大。
●L2会被多个Core共享。可以利用的Cache不及预期。在涉及L2敏感算法时,需要用L2Size处于共享的核数。如果是Linux系统,在/sys/devices/system/cpu/cpu*/cache中的shared_cpu_map查看。
2.3.3 TLB优化
避免跨页访问,尽可能将Code和Data聚集在一个Page范围内集中访问。但ASLR(AddressSpaceLayoutRandomization)机制无法避免代码的跨页访问。如果代码加载到固定地址,将很容易受到攻击,所以操作系统加载代码时会进行随机处理。
2.4 预取优化
2.4.1 硬件预取
一个core通常会有8到16个硬件预取原件,会对CacheMiss进行监控,如果miss的CacheLine的Stride是定长,且累积miss次数超过阈值,触发硬件预取。通常预取原件都是部署在L2和更高层级的Cache上,由于L2会被共享,所以预取原件很快就会被消耗完。
前文已经提到过,硬件预取不能跨页。通常硬件预取的Stride不会超过512B,一个物理页是4K,如果Stride超过512B,预取8次就跨页了,不合理。
如果内存带宽被打满。可以考虑关闭掉硬件预取,但是这是CPU级别生效。可以将低优先级线程绑定在的定的CPU上,并关闭其硬件预取功能,减少内存带宽压力。
2.4.2 软件预取

图44
●T0,T1,T2分别将CacheLine加载到L1,L2,L3中,如果加载到L1中,L2和L3也会被加载。使用预取指令时需要考虑WorkSet大小,如果太大,不应该直接使用T0,而是考虑更合适的T1和T2。
●NTA,尽可能避免Cache污染进行预取。也就是前文提到的non-temporal操作。
●随机访问的软件预取效果如下,有一定的提升。
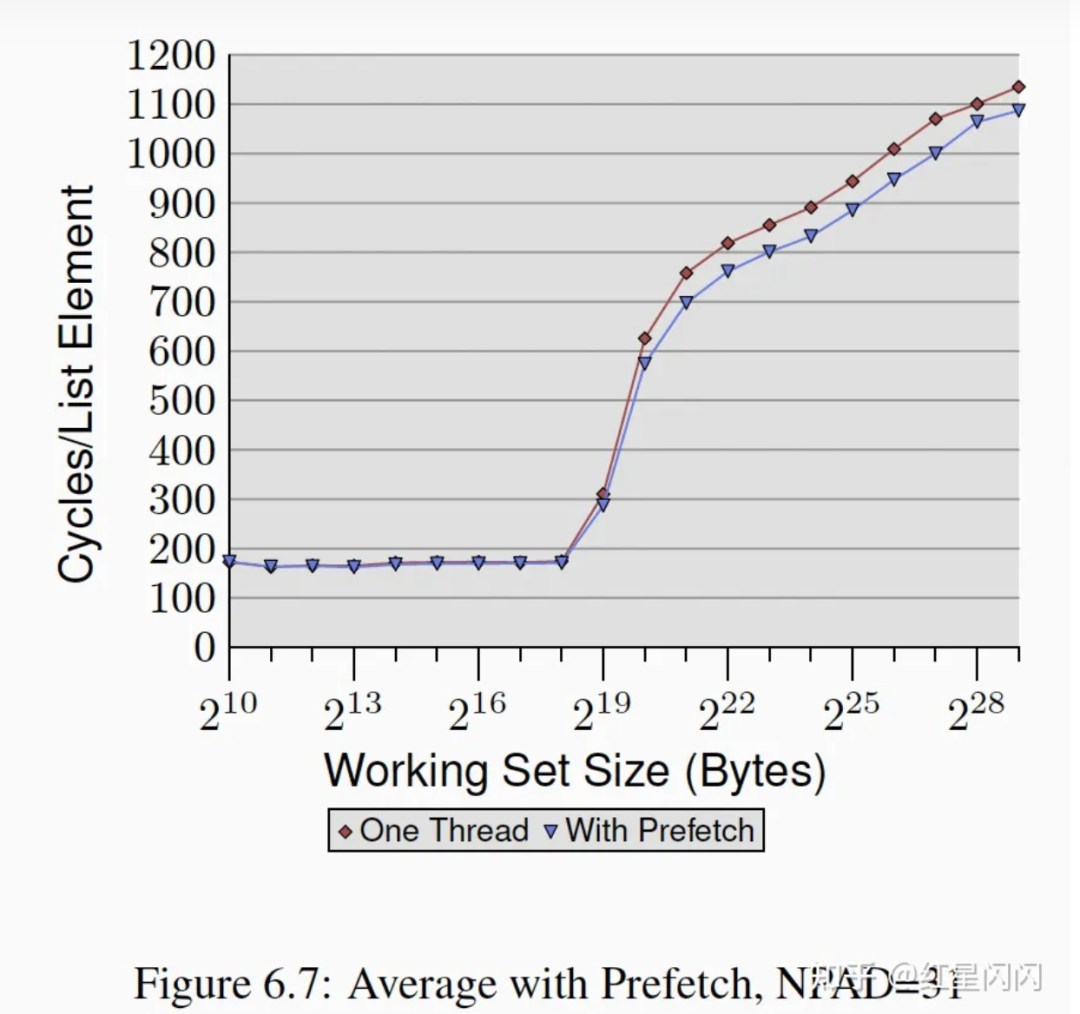
图45
2.4.3 Helper Thread预取
H-Thread会共用L1 Cache,容易造成Cache污染等问题,论文提到了一种解决办法,使用Helper-Thread专门进行prefetch。属于同一个Core的两个H-Thread作为一组,一个用于用于处理业务逻辑,另一个专门用于辅助预取数据。可以使用NUMA库绑定线程到特定的H-Thread上实现。
Helper-Thread方法的效果如下,收益明显,但是也有自己的问题:
●Helper线程和主线程的同步需要额外逻辑和开销。
●Helper线程本来可以用来做其他的计算任务,两种方式需要权衡。
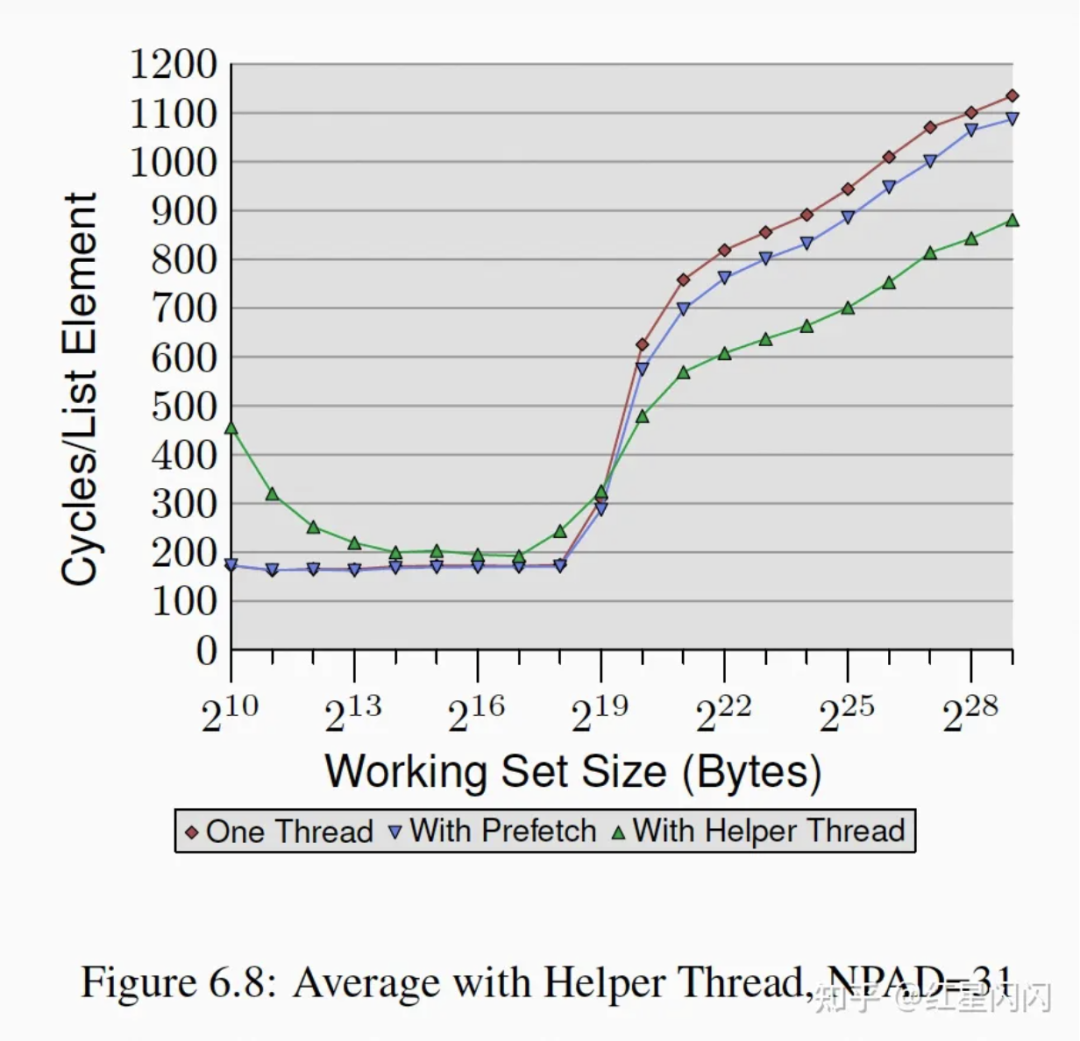
图46
