--关注、星标、回复“智驾圈子”--
↓↓查看:「智驾最前沿」智驾圈子超百份资料目录↓↓
原文链接:https://zhuanlan.zhihu.com/p/648278653
基本思路
首先图森的基本方案是联合预测和规划的思路,就是说规划的时候,预测是能够考虑到自车的行为的,这个非常重要,因为在自车的不同规划轨迹下面,周围的环境肯定是不同的,所以预测结果必然不同,如果只是机械的用但一的预测模型给一个不考虑自车的结果,肯定不合理。最近我在这一块做了一些粗浅的学界方案研究,后续再做详细分享。我记得之前看过印象最深的是一个来自母校的文章,PiP: Planning-informed Trajectory Prediction for Autonomous Driving将的就是考虑自车规划的预测方法。欢迎关注「智驾最前沿」微信视频号
然后决策上面则是采用了博弈模型,前面的预测同学讲用的level-k博弈,不过没有人对他们怎么做的决策有详细介绍的,我们暂且默认就是level-k吧,level-k博弈模型下,根据自车的不同轨迹,博弈出其他车的意图概率,因为有level-k,所以可以产生多个目标不同激进程度的概率,然后在这个分布下进行contingency。然后上面说了,有多个自车的轨迹,所以每个轨迹下都会演化出对应的环境,现在就通过reward function来评估一下cost, 找到最好的自车策略,到这里还没结束,他们的优化目标是策略参数而不是控制策略本身,所以还有一道对策略参数进行全局优化的过程,得到自车最优的控制策略。这里面我们可以看到,轨迹的优化是在参数空间上的,决策结果以及交互都能映射到参数空间上,说白了,优化这套参数空间就相当于把轨迹,决策,交互都搞了。这玩的什么套路呢?这里经图森的决策规划负责人,也就是讲这些东西的人的提醒,更正为“principle based, 即基于数学分析与建模的方法”,建立起策略参数和具体控制策略之间的联系。细节怎么做的完全没有,思路理解一下就行了。算法框架如下: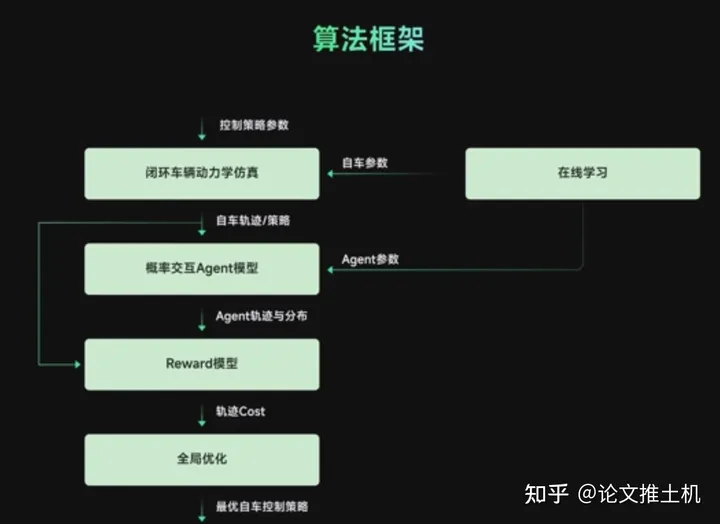
contingency规划
现在我们还是回到规划方案上面,规划上用的contingency planning, 从而同时应对目标的多模态,仿真结果的展示上面效果还行。
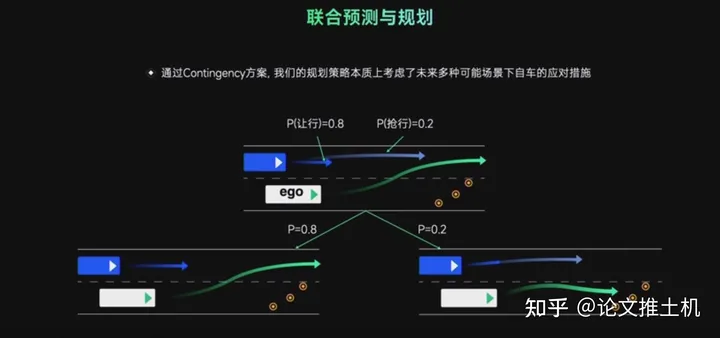 如上图contingency能够同时考虑交互目标的多模态,在同时考虑目标的不同意图下做出自车的综合考虑下的最佳策略。不好意思,大疆很早以前就用了。
如上图contingency能够同时考虑交互目标的多模态,在同时考虑目标的不同意图下做出自车的综合考虑下的最佳策略。不好意思,大疆很早以前就用了。时空联合规划
时空联合优化确实不再被人为限制解空间,所以肯定比解耦方案要优越。图森的做法是先搞一个时空间联合采样,并且是在策略参数空间上的采样,给定策略参数,再给定车辆模型,得出对应的开环推演的轨迹: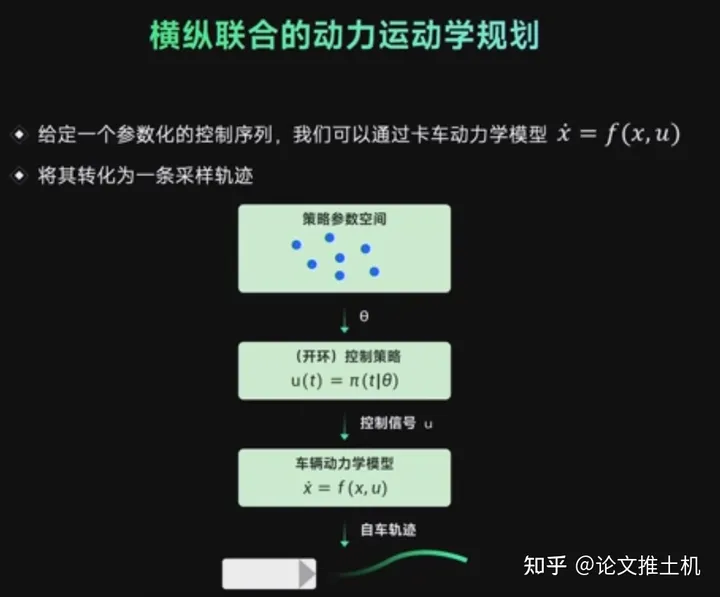
reward策略参数评估
说这个reward function肯定是高度非凸非光滑的,怎么整,有一个高端的全局优化器,具体是啥思路没有:
反馈控制
上面讲了用开环推演得到未来轨迹,最后得到的控制序列那肯定不够,不能直接提供控制,就算是高频刷新planning,也不保证稳定性,所以后面还有一个反馈控制。这就不多解释了,肯定得有反馈控制。这里还有一个在学学习模块。学的什么东西呢,就是planning中会低频更新策略参数。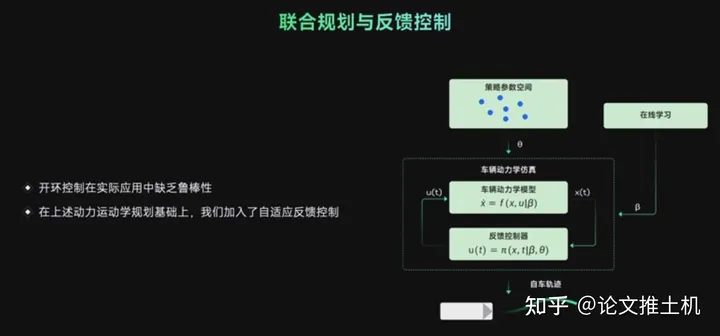 最后给了一个例子,把控制序列的优化和planning放在一起的好处就是planning的结果非常丝滑,且控制能够很好执行它:
最后给了一个例子,把控制序列的优化和planning放在一起的好处就是planning的结果非常丝滑,且控制能够很好执行它: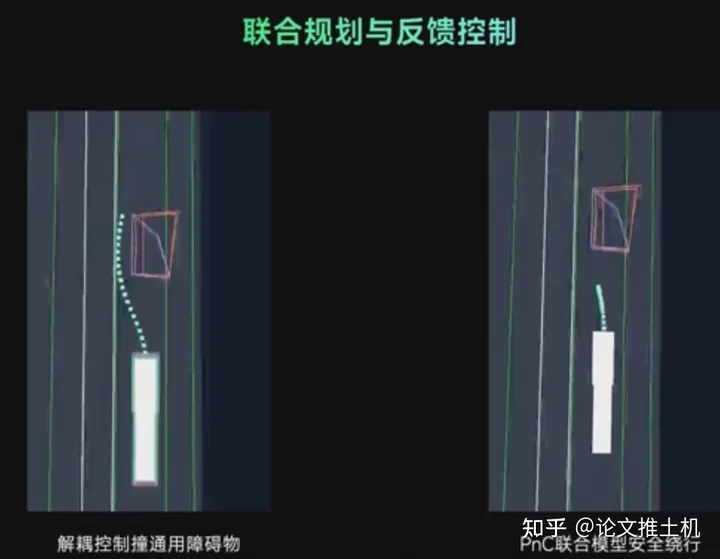 转载自知乎@论文推土机,文中观点仅供分享交流,不代表本公众号立场,如涉及版权等问题,请您告知,我们将及时处理。
转载自知乎@论文推土机,文中观点仅供分享交流,不代表本公众号立场,如涉及版权等问题,请您告知,我们将及时处理。-- END --