


01
存储体系结构
速度快的存储硬件成本高、容量小,速度慢的成本低、容量大。为了权衡成本和速度,计算机存储分了很多层次,扬长避短,有寄存器、L1 cache、L2 cache、L3 cache、主存(内存)和硬盘等。图1 展示了现代存储体系结构。
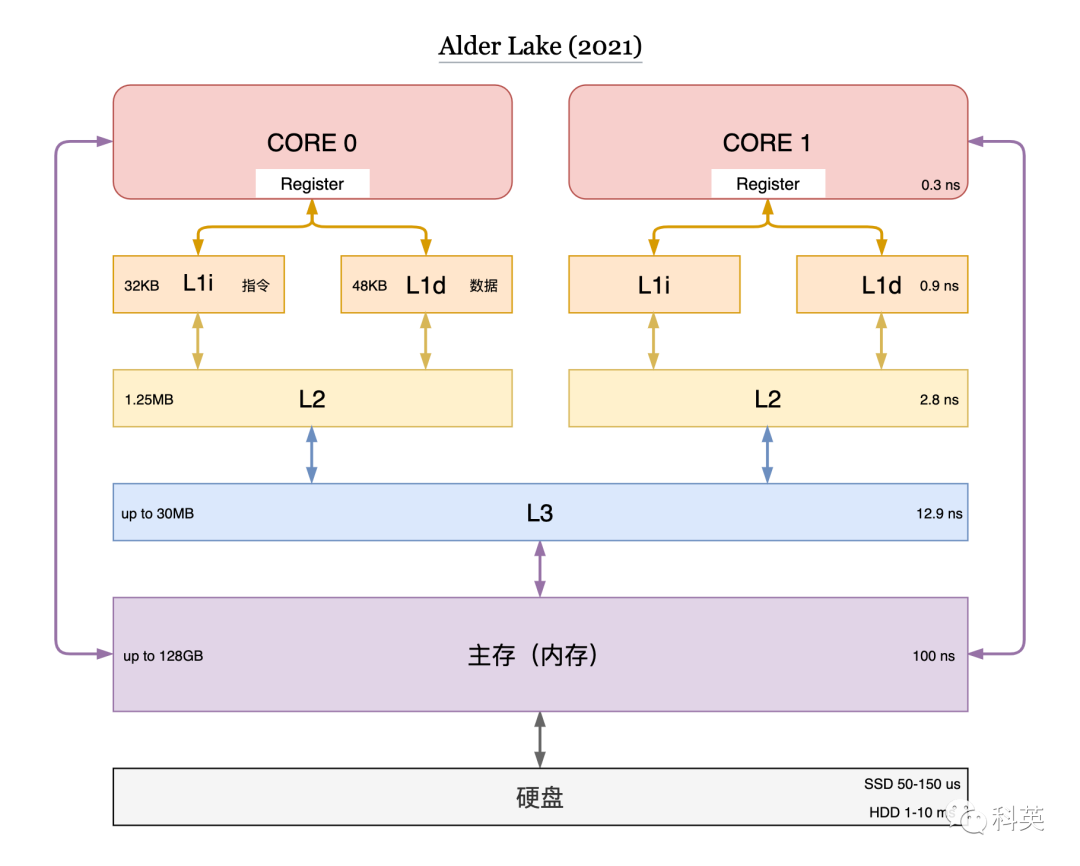
图1
根据程序的空间局部性和时间局部性原理,缓存命中率可以达到 70~90% 。因此,增加缓存可以让整个存储系统的性能接近寄存器,并且每字节的成本都接近内存,甚至是磁盘。
所以缓存是存储体系结构的灵魂。
缓存原理
2.1 缓存的工作原理
cache line(缓存行)是缓存进行管理的最小存储单元,也叫缓存块,每个 cache line 包含 Flag、Tag 和 Data ,通常 Data 大小是 64 字节,但不同型号 CPU 的 Flag 和 Tag 可能不相同。从内存向缓存加载数据是按整个缓存行加载的,一个缓存行和一个相同大小的内存块对应。
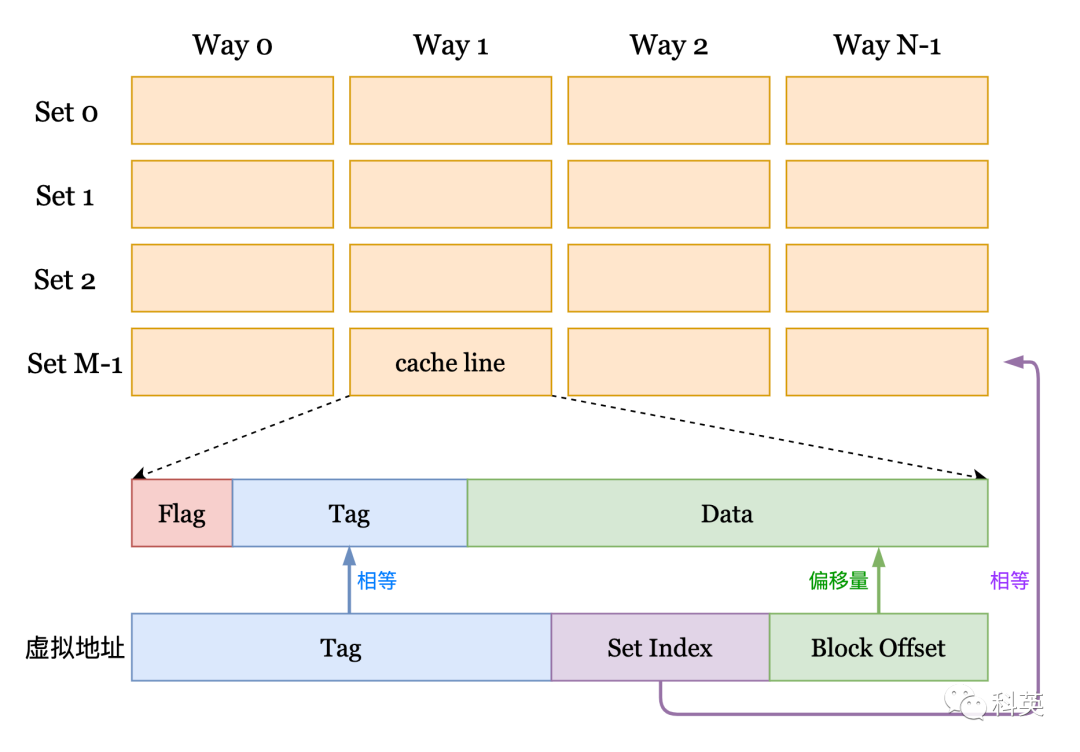
图2
图2中,缓存是按照矩阵方式排列(M × N),横向是组(Set),纵向是路(Way)。每一个元素是缓存行(cache line)。
那么给定一个虚拟地址 addr 如何在缓存中定位它呢?首先把它所在的组号找到,即:
//左移6位是因为 Block Offset 占 addr 的低 6 位,Data 为 64 字节Set Index = (addr >> 6) % M;
然后遍历该组所有的路,找到 cache line 中的 Tag 与 addr 中 Tag 相等为止,所有路都没有匹配成功,那么缓存未命中。
整个缓存容量 = 组数 × 路数 × 缓存行大小我电脑的CPU信息:
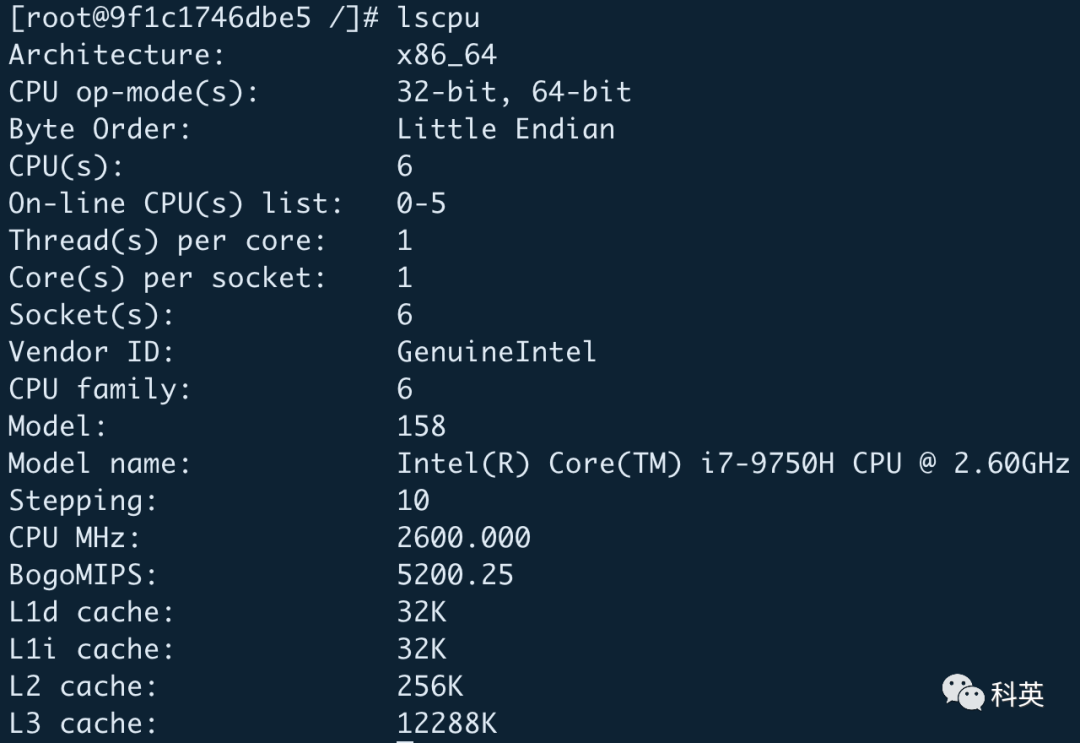
我电脑的缓存信息:
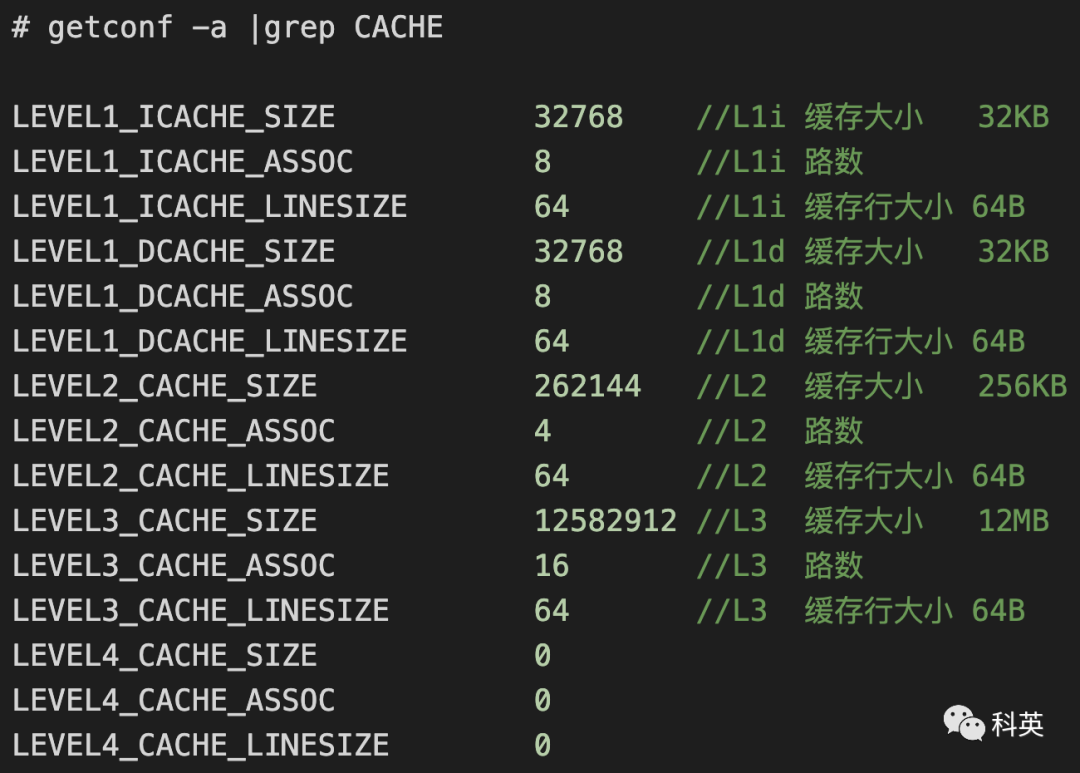
通过缓存行大小和路数可以倒推出缓存的组数,即:
缓存组数 = 整个缓存容量 ÷ 路数 ÷ 缓存行大小2.2 缓存行替换策略
目前最常用的缓存替换策略是最近最少使用算法(Least Recently Used ,LRU)或者是类似 LRU 的算法。
LRU 算法比较简单,如图3,缓存有 4 路,并且访问的地址都哈希到了同一组,访问顺序是 D1、D2、D3、D4 和 D5,那么 D1 会被 D5 替换掉。算法的实现方式有很多种,最简单的实现方式是位矩阵。
首先,定义一个行、列都与缓存路数相同的矩阵。当访问某个路对应的缓存行时,先将该路对应的所有行置为 1,然后再将该路对应的所有列置为 0。
最近最少使用的缓存行所对应的矩阵行中 1 的个数最少,最先被替换出去。

图3
2.3 缓存缺失
缓存缺失就是缓存未命中,需要把内存中数据加载到缓存,所以运行速度会变慢。
就拿我的电脑来测试,L1d 的缓存大小是 32KB(32768B),8路,缓存行大小 64B,那么
缓存组数 = 32 × 1024 ÷ 8 ÷ 64 = 64char *a = new char(64 * 64 * 8); //32768Bfor(int i = 0; i < 20000000; i++)for(int j = 0; j < 32768; j += 4096)a[j]++;
调整上面的代码,并运行
char *a = new char(64 * 64 * 8 * 2); //65536Bfor(int i = 0; i < 10000000; i++)for(int j = 0; j < 65536; j += 4096)a[j]++;
2.4 程序局部性
程序局部性就是读写内存数据时读写连续的内存空间,目的是让缓存可以命中,减少缓存缺失导致替换的开销。
我电脑上运行下面代码
int M = 10000, N = 10000;char (*a)[N] = (char(*)[N])calloc(M * N, sizeof(char));for(int i = 0; i < M; i++)for(int j = 0; j < N; j++)a[i][j]++;
结果:循环 100000000 次,耗时 314 ms。利用了程序局部性原理,缓存命中率高。
修改上面的代码如下,并运行
int M = 10000, N = 10000;char (*a)[N] = (char(*)[N])calloc(M * N, sizeof(char));for(int j = 0; j < N; j++)for(int i = 0; i < M; i++)a[i][j]++;
结果:循环 100000000 次,耗时 1187 ms。没有利用程序局部性原理,缓存命中率低,所以耗时增加了 2 倍。
2.5 伪共享(false-sharing)
当两个线程同时各自修改两个相邻的变量,由于缓存是按缓存行来整体组织的,当一个线程对缓存行中数据执行写操作时,必须通知其他线程该缓存行失效,导致另一个线程从缓存中读取其想修改的数据失败,必须从内存重新加载,导致性能下降。
我电脑运行下面代码
struct S {long long a;long long b;} s;std::thread t1([&]() {for(int i = 0; i < 100000000; i++)s.a++;});std::thread t2([&]() {for(int i = 0; i < 100000000; i++)s.b++;});
结果:耗时 512 ms,原因上面提到了,就是两个线程互相影响,使对方的缓存行失效,导致直接从内存读取数据。
解决办法是对上面代码做如下修改:
struct S {long long a;long long noop[8];long long b;} s;
本小节的测试代码都没有开启编译器优化,即编译选项为-O0 。
03
缓存一致性协议
在单核时代,增加缓存可以大大提高读写速度,但是到了多核时代,却引入了缓存一致性问题,如果有一个核心修改了缓存行中的某个值,那么必须有一种机制保证其他核心能够观察到这个修改。
3.1 缓存写策略
从缓存和内存的更新关系来看,分为:
从写缓存时 CPU 之间的更新策略来看,分为:
MESI协议是⼀个基于失效的缓存⼀致性协议,是⽀持写回(write-back)缓存的最常⽤协议。也称作伊利诺伊协议 (Illinois protocol,因为是在伊利诺伊⼤学厄巴纳-⾹槟分校被发明的)。
为了解决多个核心之间的数据传播问题,提出了总线嗅探(Bus Snooping)策略。本质上就是把所有的读写请求都通过总线(Bus)广播给所有的核心,然后让各个核心去嗅探这些请求,再根据本地的状态进行响应。
这些状态信息实际上存储在缓存行(cache line)的 Flag 里。
3.2.2 事件
处理器对缓存的请求:
PrWr:核心请求向缓存块写入数据。
总线对缓存的请求:
3.2.3 状态机
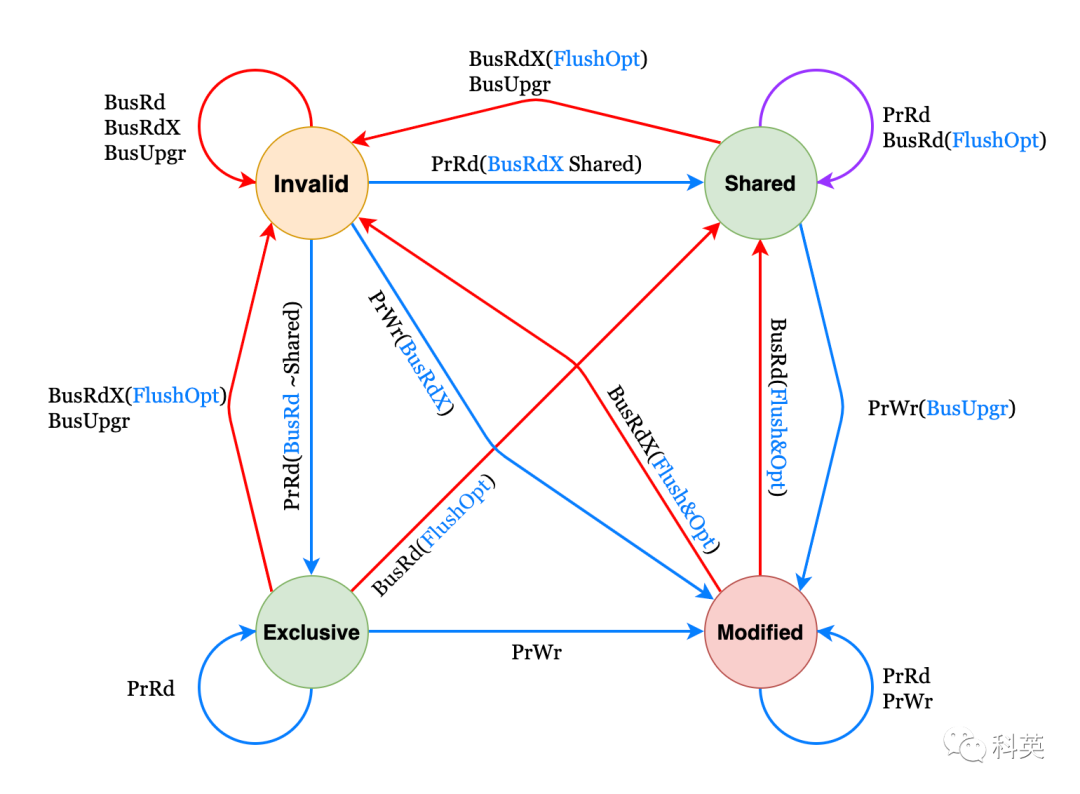
图4
表1是对状态机图4 的详解讲解(选读)
| 当前状态 | 事件 | 响应 |
| PrRd |
| |
| PrWr |
| |
| BusRd |
| |
| BusRdX |
| |
E | PrRd |
|
| PrWr |
| |
BusRd |
| |
BusRdX |
| |
| S | PrRd |
|
PrWr |
| |
| BusRd |
| |
BusRdX |
| |
| I | PrRd |
|
PrWr |
| |
BusRd |
| |
BusRdX/BusUpgr |
|
表1
3.2.4 动画演示
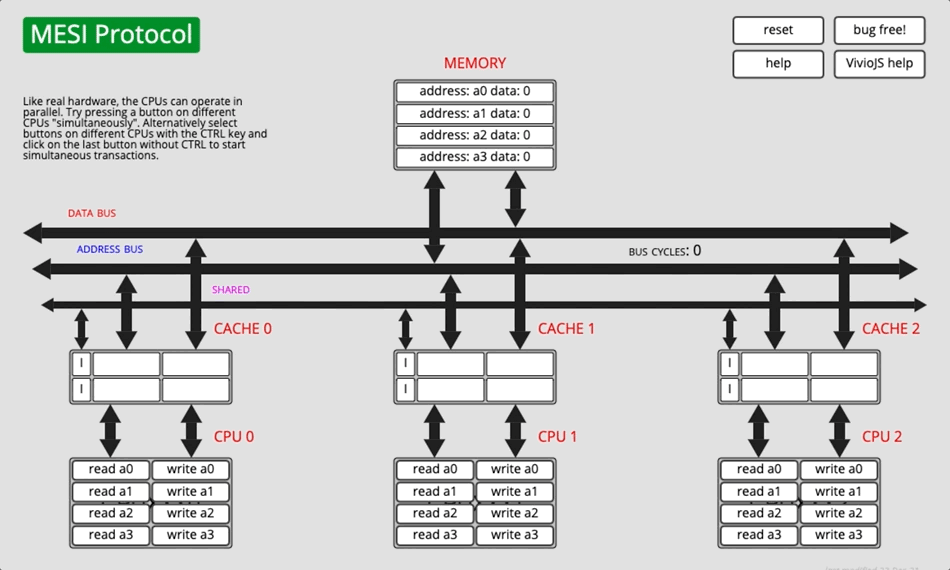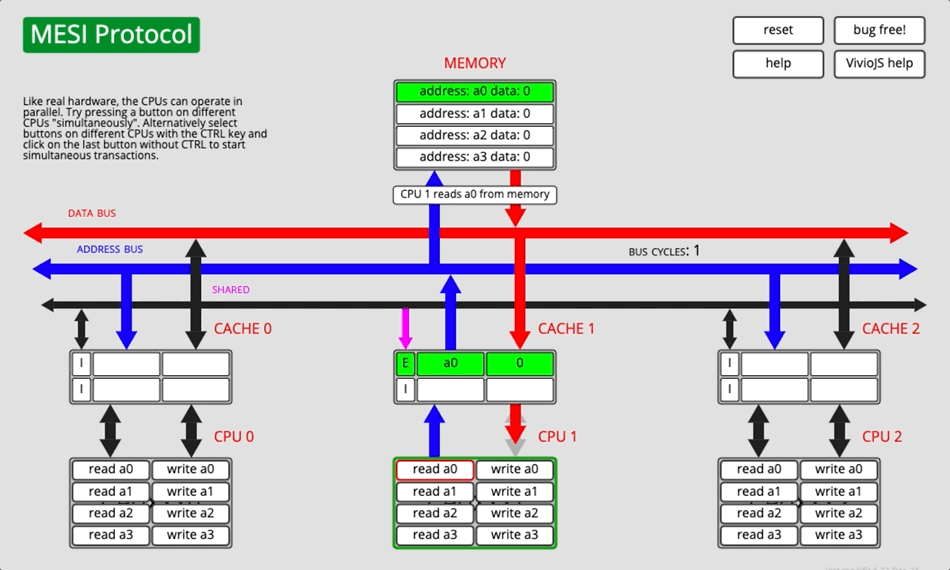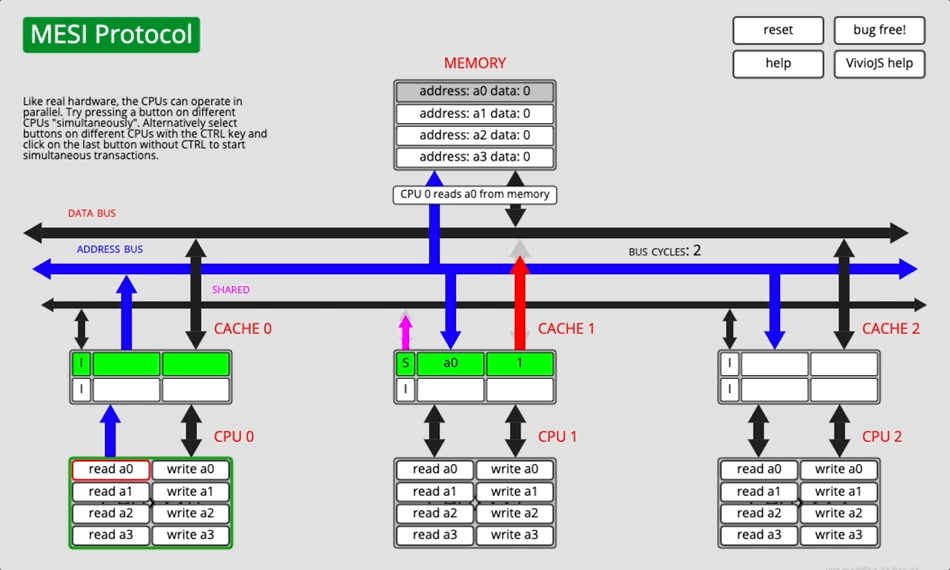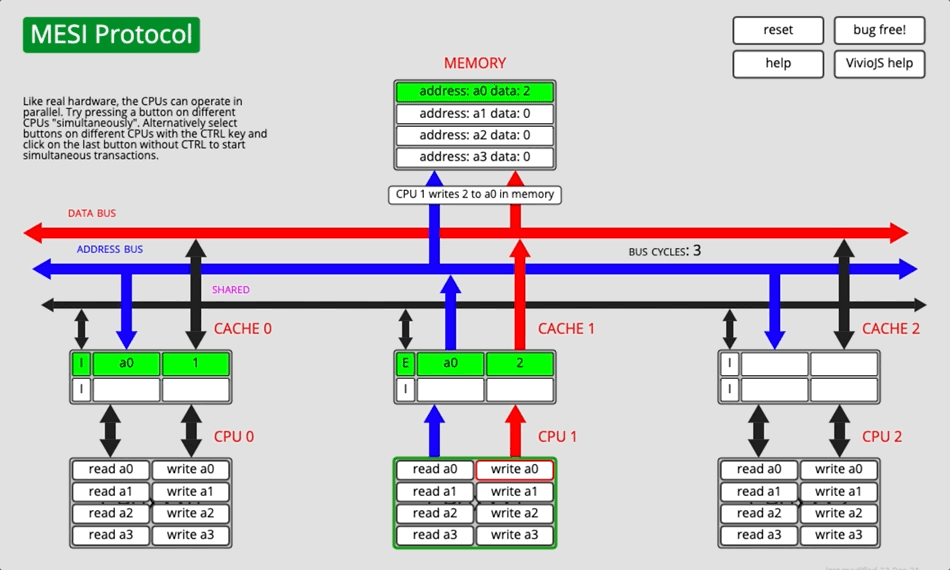
图5
各家 CPU 厂商没有都完全按照 MESI 实现缓存一致性协议,导致 MESI 有很多变种,例如:Intel 采用的 MESIF 和 AMD 采用的 MOESI,ARM 大部分采用的是 MESI,少部分使用的是 MOESI 。
3.3 MOESI 协议(选读)
MOESI 是一个完整的缓存一致性协议,它包含了其他协议中常用的所有可能状态。除了四种常见的 MESI 协议状态之外,还有第五种 Owned 状态,表示修改和共享的数据。
这就避免了在共享数据之前将修改过的数据写回主存的需要。虽然数据最终仍然必须写回,但写回可能是延迟的。
⽆效Invalid (I):缓存⾏是⽆效的。
3.4 MESIF 协议(选读)
MESIF 是一个缓存一致性和记忆连贯协议,该协议由五个状态组成:已修改(M),互斥(E),共享(S),无效(I)和转发(F)。
M,E,S 和 I 状态与 MESI 协议一致。F 状态是 S 状态的一种特殊形式,当系统中有多个 S 时,必须选取一个转换为 F,只有 F 状态的负责应答。通常是最后持有该副本的转换为 F,注意 F 是干净的数据。
04
内存屏障(Memory Barriers)
编译器和处理器都必须遵守重排序规则。在单处理器的情况下,不需要任何额外的操作便能保持正确的顺序。但是对于多处理器来说,保证一致性通常需要增加内存屏障指令。即使编译器可以优化掉字段的访问(例如因为未使用加载到的值),编译器仍然需要生成内存屏障,就好像字段访问仍然存在一样(可以单独将内存屏障优化掉)。
内存屏障只与内存模型中的高级概念(例如 acquire 和 release)间接相关。内存屏障指令只直接控制 CPU 与其缓存的交互,以及它的写缓冲区(持有等待刷新到内存的数据的存储)和它的用于等待加载或推测执行指令的缓冲。这些影响可能导致缓存、主内存和其他处理器之间的进一步交互。
几乎所有的处理器都至少支持一个粗粒度的屏障指令(通常称为 Fence,也叫全屏障),它保证了严格的有序性:在 Fence 之前的所有读操作(load)和写操作(store)先于在 Fence 之后的所有读操作(load)和写操作(store)执行完。对于任何的处理器来说,这通常都是最耗时的指令之一(它的开销通常接近甚至超过原子操作指令)。大多数处理器还支持更细粒度的屏障指令。
表2 是各处理器支持的内存屏障和原子操作
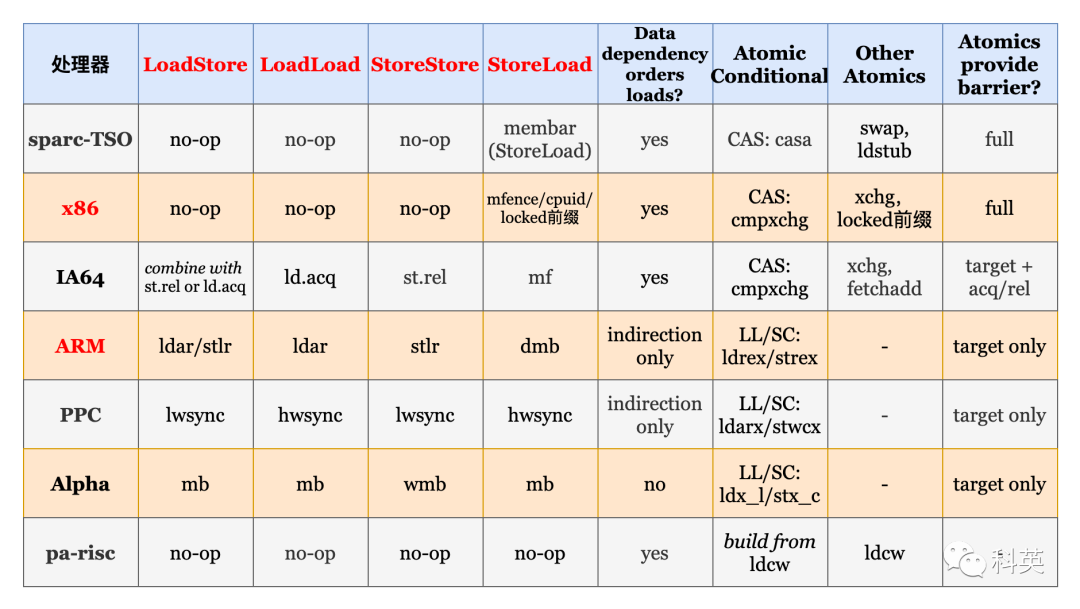
表2
4.1 写缓冲与写屏障
严格按照MESI协议,核心0 在修改本地缓存之前,需要向其他核心发送 Invalid 消息,其他核心收到消息后,使他们本地对应的缓存行失效,并返回 Invalid acknowledgement 消息,核心0 收到后修改缓存行。这里核心0 等待其他核心返回确认消息的时间对核心来说是漫长的。
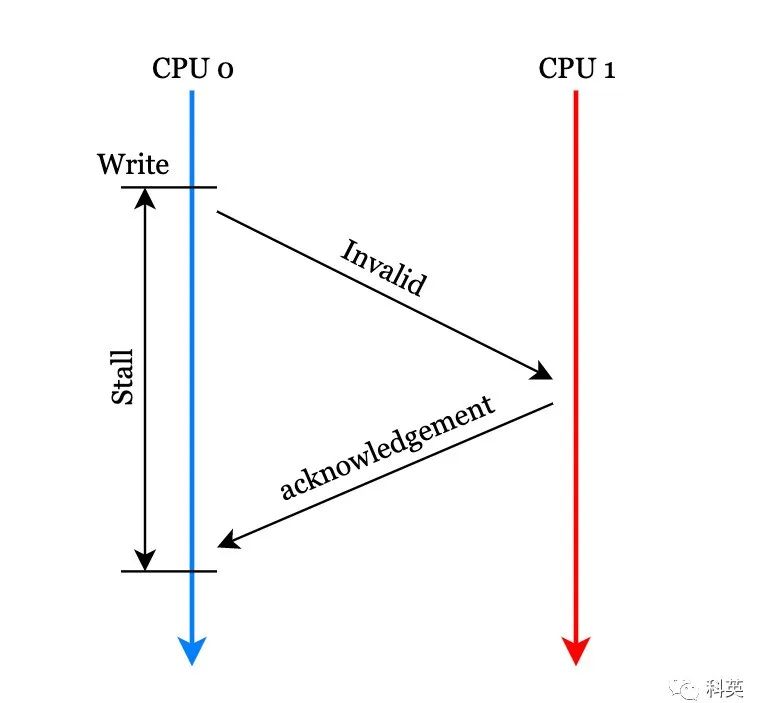
图6
为了解决这个问题,引入了 Store Buffer ,当核心想修改缓存时,直接写入 Store uffer ,无需等待,继续处理其他事情,由 Store Buffer 完成后续工作。
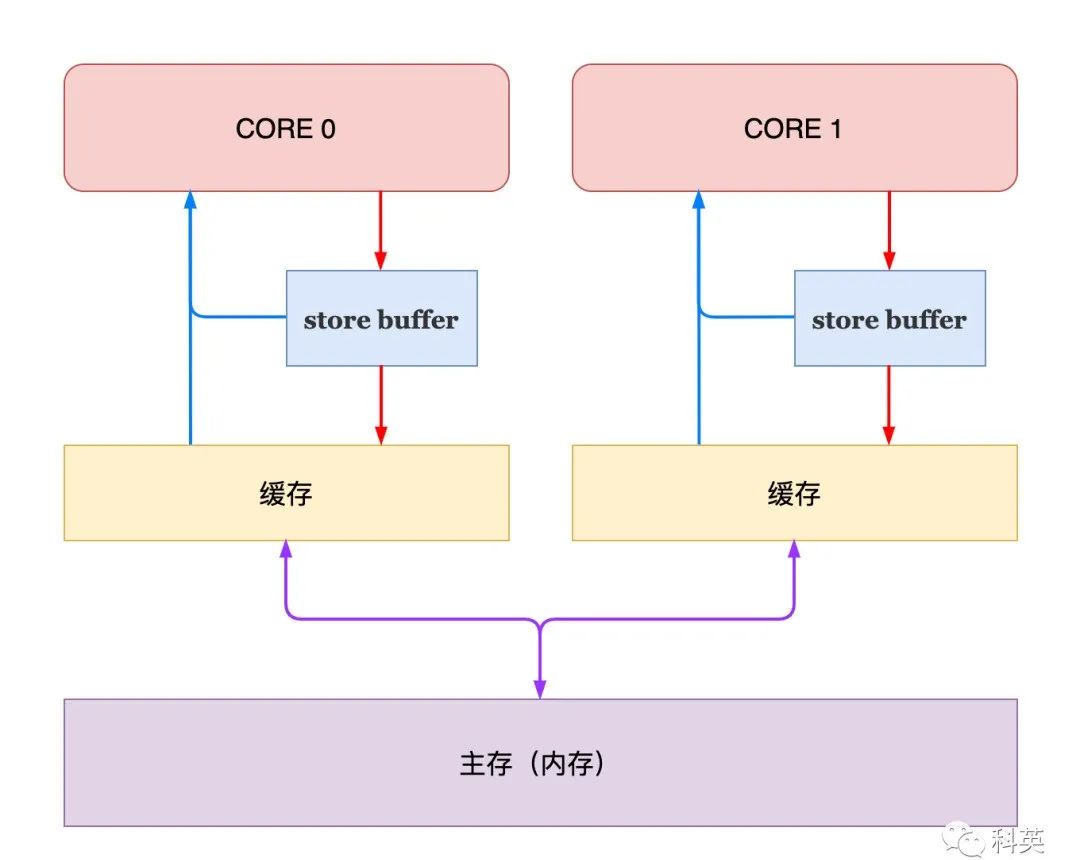
图7
这样一来写的速度加快了,但是引来了新问题,下面代码的 bar 函数中的断言可能会失败。
int a = 0, b = 0;// CPU0void foo() {a = 1;b = 1;}// CPU1void bar() {while (b == 0) continue;assert(a == 1);}
第二种情况:Store Buffer 在写入时,b 所对应的缓存行是 E 状态,a 所对应的缓存行是 S 状态,因为对 b 的修改不需要核心间同步,但是修改 a 则需要,也就是 b 会先写入缓存。与之对应 CPU1 中 a 是 S 状态,b 是 I 状态,由于 b 所对应的缓存区域是 I 状态,它就会向总线发出 BusRd 请求,那么 CPU1 就会先把 b 的最新值读到本地,完成变量 b 值的更新,但是从缓存直接读取 a 值是 0 。
举一个更极端的例子
// CPU0void foo() {a = 1;b = a;}
为了解决上面问题,引入了内存屏障,屏障的作用是前边的读写操作未完成的情况下,后面的读写操作不能发生。这就是 Arm 上 dmb 指令的由来,它是数据内存屏障(Data Memory Barrier)的缩写。
int a = 0, b = 0;// CPU0void foo() {a = 1;smp_mb(); //内存屏障,各CPU平台实现不一样b = 1;}// CPU1void bar() {while (b == 0) continue;assert(a == 1);}
总的来说,Store Buffer 提升了写性能,但放弃了缓存的顺序一致性,这种现象称为弱缓存一致性。通常情况下,多个 CPU 一起操作同一个变量的情况是比较少的,所以 Store Buffer 可以大幅提升程序的性能。但在需要核间同步的情况下,还是需要通过手动添加内存屏障来保证缓存一致性。
上面解决了核间同步的写问题,但是核间同步还有一个瓶颈,那就是读。
4.2 失效队列与读屏障
前面引入 Store Buffer 提升了写入速度,那么 invalid 消息确认速度相比起来就慢了,带来了速度不匹配,很容易导致 Store Buffer 的内容还没及时写到缓存里,自己就满了,从而失去了加速的作用。
为了解决这个问题,又引入了 Invalid Queue。收到 Invalid 消息的核心立刻返回 Invalid acknowledgement 消息,然后把 Invalid 消息加入 Invalid Queue ,等到空闲的时候再去处理 Invalid 消息。
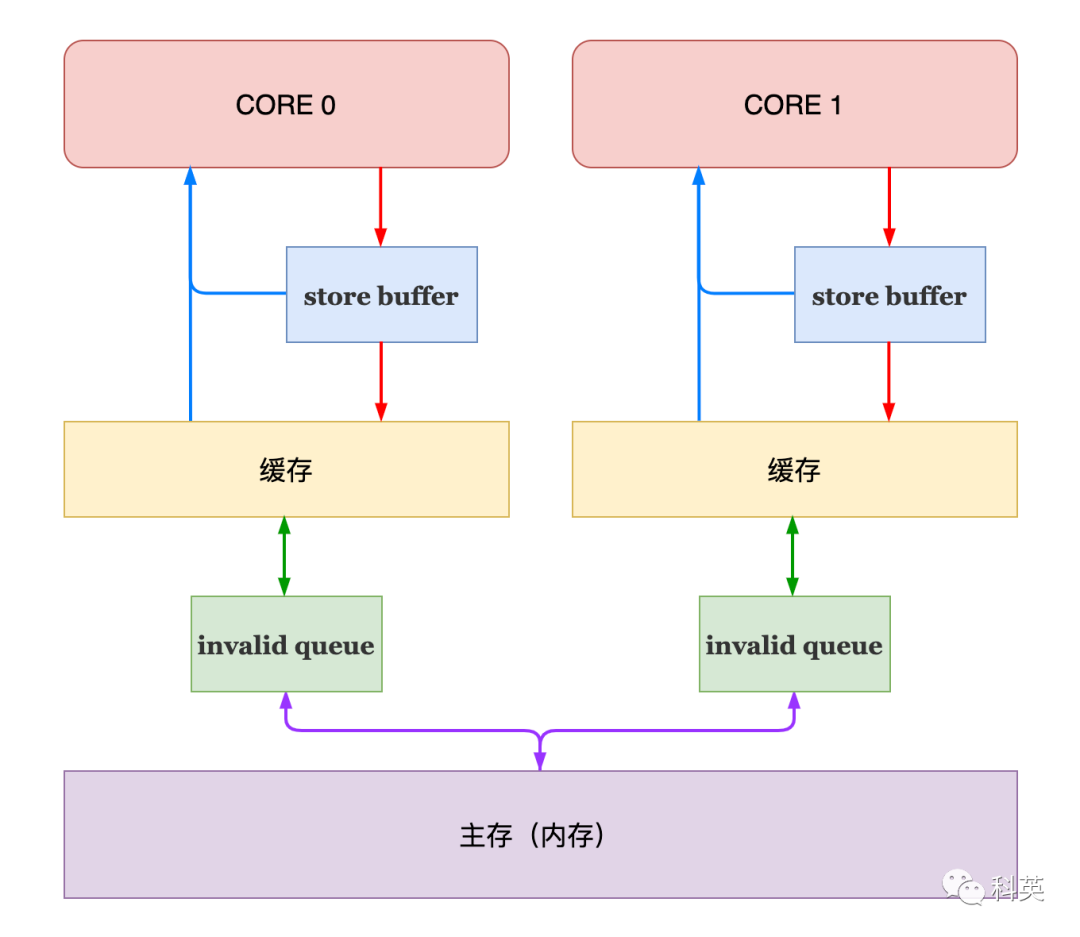
图8
运行上面增加内存屏障的代码,第 11 行的断言又可能失败了。
核心0 中 a 所对应的缓存行是 S 状态,b 所对应的缓存行是 E 状态;核心1中 a 所对应的缓存行是 S 状态,b 所对应的缓存行是 I 状态;
核心1 发送 BusRd 消息,读取到新的 b 值,然后获取 a(S 状态)值是0,因为使其无效的消息还在 Invalid Queue 中,第 11 行断言失败。
引入 Invalid Queue 后,对核心1 来说看到的 a 和 b 的写入又出现乱序了。
解决办法是继续加内存屏障,核心1 想越过屏障必须清空 Invalid Queue,及时处理了对 a 的无效,然后读取到新的 a 值,如下代码:
int a = 0, b = 0;// CPU0void foo() {a = 1;smp_mb();b = 1;}// CPU1void bar() {while (b == 0) continue;smp_mb(); //继续加内存屏障assert(a == 1);}
4.3 读写屏障分离
分离的写屏障和读屏障的出现,是为了更加精细地控制 Store Buffer 和 Invalid Queue 的顺序。
优化前面的代码如下
int a = 0, b = 0;// CPU0void foo() {a = 1;smp_wmb(); //写屏障b = 1;}// CPU1void bar() {while (b == 0) continue;smp_rmb(); //读屏障assert(a == 1);}
4.4 单向屏障
单向屏障 (half-way barrier) 也是一种内存屏障,但它不是以读写来区分的,而是像单行道一样,只允许单向通行,例如 ARM 中的 stlr 和 ldar 指令就是这样。
StoreLoad barrier 就只能使用 dmb(全屏障) 代替了。
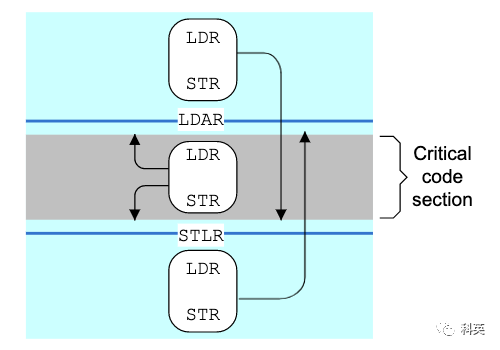
图9 ARM Figure 13.2. One-way barriers
来源:【科英】
文章来源于网络,版权归原作者所有,如有侵权,请联系删除。


关注我【一起学嵌入式】,一起学习,一起成长。
觉得文章不错,点击“分享”、“赞”、“在看” 呗!
