


在SIGGRAPH 2023上,NVIDIA宣布推出全新的NVIDIA L40S GPU以及搭载L40S的NVIDIA OVX服务器。L40S GPU和OVX服务器主要针对生成式人工智能模型的训练和推理环节,有望进一步提升生成式人工智能模型的训练和推理场景下的计算效率。来源参考“英伟达发布L40S GPU,中高速光模块或将受益”。
L40S基于Ada Lovelace架构,配备有48GB的GDDR6显存和 846GB/s 的带宽。在第四代 Tensor 核心和 FP8 Transformer 引擎的加持下,可以提供超过 1.45 PFLOPS 的张量处理能力。根据英伟达给出的数据,在微调(Fine-tune)和推理场景的测试用例下,L40S 的计算效率较 A100 均有所提高。
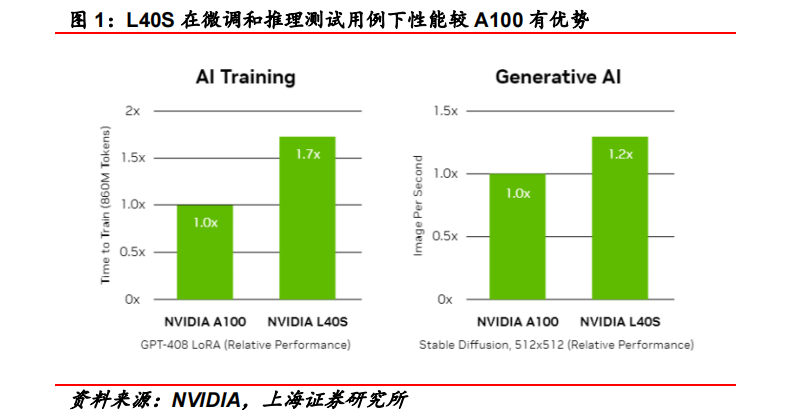
相比于 A100 GPU,L40S 在显存、算力等多方面有所差异:
(1)L40S采用较为成熟的GDDR6显存,相比A100与H100使用的 HBM 显存,在显存带宽上有所降低,但技术更成熟,市场供应较为充足。
(2)L40S 在 FP16 算力(智能算力)上较 A100 有所提高,在 FP32 算力(通用算力)上较 A100 提高明显,更适应科学计算等场景。
(3)L40S 在功率上较 A100 有所降低,有利于降低数据中心相关能耗。
(4)根据 Super Micro 的数据,L40S 在性价比上较 A100 更有优势。
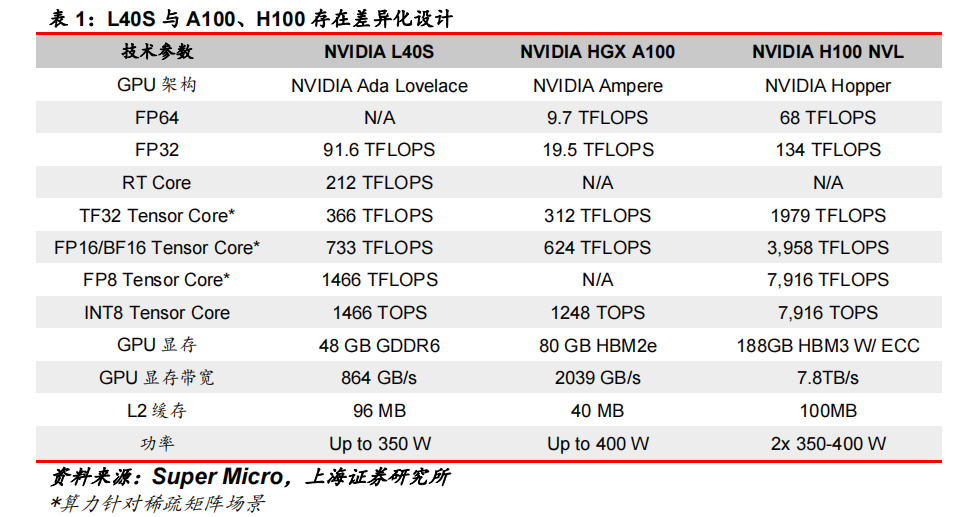
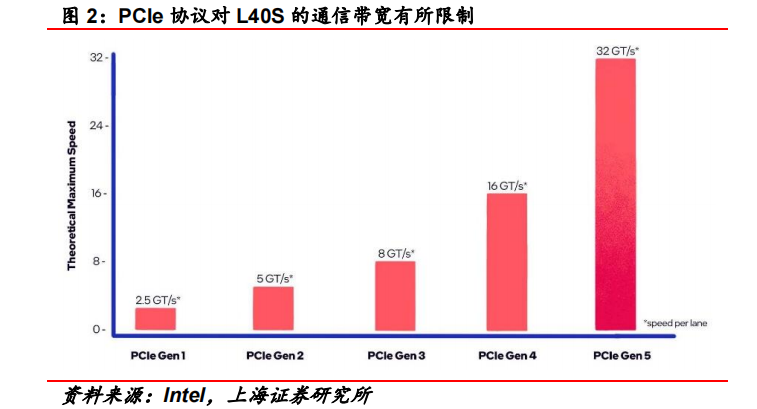
基于Ada Lovelace架构的L40S,配备有48GB的GDDR6显存和846GB/s的带宽。在第四代Tensor核心和FP8 Transformer引擎的加持下,可以提供超过1.45 PetaFLOPS的张量处理能力。
对于算力要求较高的任务,L40S的18,176个CUDA核心可以提供近5倍于A100的单精度浮点(FP32)性能,从而加速复杂计算和数据密集型分析。
此外,为了支持如实时渲染、产品设计和3D内容创建等专业视觉处理工作,英伟达还为L40S 还配备了142个第三代RT核心,可以提供212TFLOP的光线追踪性能。功耗同时也达到了350瓦。
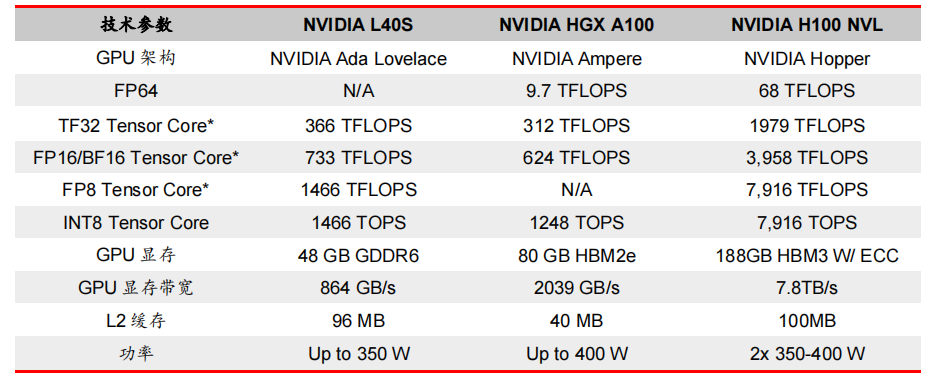
对于具有数十亿参数和多种模态的生成式AI工作负载,L40S相较于A100可实现高达1.2倍的推理性能提升,以及高达1.7倍的训练性能提升。
在L40S GPU的加持下,英伟达还针对数据中心市场,推出了最多可搭载8张L40S的OVX服务器。英伟达方面宣布,对于拥有8.6亿token的GPT3-40B模型,OVX服务器只需7个小时就能完成微调;对于Stable Diffusion XL模型,则可实现每分钟80张的图像生成。
《AIGC行业深度报告系列合集》
本号资料全部上传至知识星球,更多内容请登录智能计算芯知识(知识星球)星球下载全部资料。
免责申明:本号聚焦相关技术分享,内容观点不代表本号立场,可追溯内容均注明来源,发布文章若存在版权等问题,请留言联系删除,谢谢。
温馨提示:
请搜索“AI_Architect”或“扫码”关注公众号实时掌握深度技术分享,点击“阅读原文”获取更多原创技术干货。


