GPU 提供的高度并行计算可以利用网络流量的实时处理。在这些类型的应用程序中,优化的数据包获取或传输可以避免瓶颈,并使整体执行能够跟上高速网络的步伐。在这种情况下,DOCA GPUNetIO 将 GPU 提升为一个独立的组件,可以在没有 CPU 干预的情况下执行网络和计算任务。
本文提供了一个 GPU 数据包处理应用程序的列表,这些应用程序虽然专注于不同和无关的场景,但都集成了NVIDIA DOCA GPUNetIO以降低延迟并最大限度地提高性能。
NVIDIA DOCA GPUNetIO API
NVIDIA DOCA GPUNetIO 是随着 NVIDIA DOCA 软件框架一起发布的新库之一。DOCA GPUNetIO 库通过一个或多个 CUDA 内核实现网卡和 GPU 之间的直接通信,从而将 CPU 从关键路径中移除。
使用 DOCA GPUNetIO 库中的 CUDA 设备函数,CUDA 内核可以直接向 GPU 发送和接收数据包,而无需 CPU 核心或内存。此库的主要功能包括:
GPUDirect 异步内核启动的网络(GPUDirect Async Kernel-Initiated Network,GDAKIN):是一种以太网通信,GPU(CUDA 内核)在没有 CPU 干预的情况下直接与网卡交互,并在 GPU 内存(GPU Direct RDMA)中发送或接收数据包。
GPU 内存暴露:在单个函数中结合利用 GDRCopy 库的基本 CUDA 内存分配功能,无需使用 CUDA API 即可将GPU 内存缓冲区暴露给 CPU 进行直接访问(读或写)。
准确的发送调度:可以从 GPU 调度未来数据包突发的传输,将时间戳与之关联,并将此信息提供给网卡,网卡将负责在正确的时间发送数据包。
信号量:这是一种有用的消息传递对象,可在不同的 CUDA 内核之间,或者在 CUDA 内核和 CPU 线程之间共享信息和进行同步。
如果您想深入了解 DOCA GPUNetIO 的原理和优势,请参阅使用 NVIDIA DOCA GPUNetIO 进行的内联 GPU 数据包处理。如需获取 DOCA GPUNetIO API 的更多详细信息,请参阅 DOCA GPUNetIO SDK 编程指南。
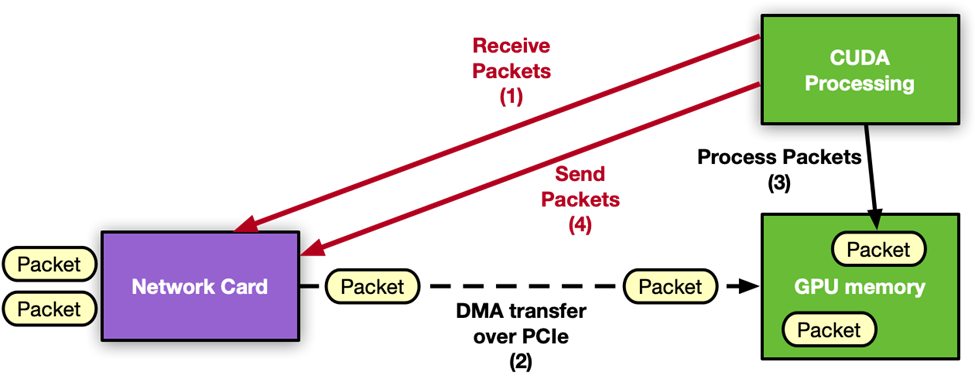
图 1:NVIDIA DOCA GPUNetIO 应用程序中接收进程的布局。不涉及 CPU,因为 GPU 可以独立地接收和处理网络数据包
与该库一起,以下 NVIDIA DOCA 应用程序和 NVIDIA DOCA 示例还展示了如何使用该库提供的功能和特性。
NVIDIA DOCA 应用程序:这是一个 GPU 数据包处理应用程序,能够检测、管理、过滤和分析 UDP 、 TCP 和 ICMP 流量。此应用程序还实现了 HTTP over TCP 服务器。使用简单的 HTTP 客户端(例如 curl 或 wget ),可以建立 TCP 三次握手连接,并通过向 GPU 发出 HTTP GET 请求来获取简单的 HTML 页面。
NVIDIA DOCA 示例:这是一个 GPU 仅发送示例,展示了如何使用“准确发送调度(Accurate Sent Scheduling)”功能(包括系统配置和要使用的功能)。
DOCA GPUNetIO 在实际中的应用
DOCA GPUNetIO 已被用于 NVIDIA Aerial SDK,用于使用 GPU 进行发送和接收,从而无需 CPU 介入。想要了解更多详细信息,请参阅使用 NVIDIA DOCA GPUNetIO 进行内联 GPU 数据包处理。下面的部分提供了成功使用 DOCA GPUNetIO 来利用 GDAKIN 技术进行 GPU 数据包获取的新示例。
NVIDIA Morpheus AI
NVIDIA Morpheus 是一个面向性能的应用程序框架,使网络安全开发人员能够创建完全优化的 AI 流水线,用于过滤、处理和分类大量实时数据。该框架通过一个由 Python 和 C ++ API 组成的可访问编程模型来抽象 GPU 和 CPU 的并行性和并发性。
利用这个框架,开发人员可以快速构建由为下游消费者获取、变异和发布数据的阶段组成任意数据流水线。您可以在不同的环境中应用 Morpheus,包括恶意软件检测、网络钓鱼/鱼叉式网络钓鱼检测、勒索软件检测等。其灵活性和高性能是实时网络流量分析的理想选择。
针对于网络监控用例,NVIDIA Morpheus 团队最近集成了 DOCA 框架,以实现高速、低延迟的 GPU 数据包获取的源阶段,并将实时数据包馈送到负责分析数据包内容的 AI 流水线。想要了解更多详细信息,请访问GitHub 上的 Morpheus。
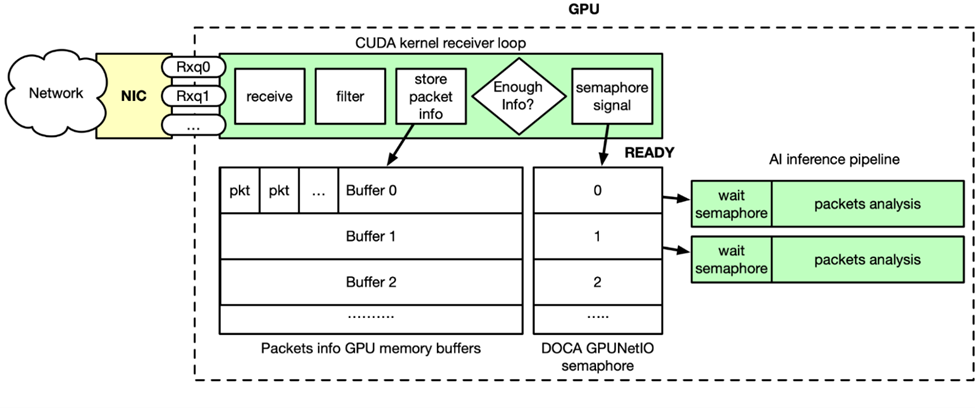
图 2 : DOCA GPUNetIO 和 NVIDIA Morpheus AI 流水线通过 CUDA 内核连接,该内核接收、过滤和分析传入数据包
如图 2 所示,GPU 数据包获取是实时发生的。通过 DOCA Flow,流转向规则应用于以太网接收队列,这意味着队列只能接收特定类型的数据包(例如 TCP )。Morpheus 启动 CUDA 内核,该内核在一个循环中执行以下步骤:
使用 DOCA GPUNetIO 接收功能接收数据包
在 GPU 内存中过滤和分析并行数据包
复制相关数据包信息到 GPU 内存缓冲区的列表中
当缓冲区已经累积了足够的数据包信息时,相关的 DOCA GPUNetIO 信号量被设置为 READY
AI 流水线前面的 CUDA 内核正在轮询信号量
当信号量为 READY 时,由于在缓冲区中的数据包信息已准备就绪, AI 将被解锁
GTC 会议 Defensive Cyber Operations(DCO)on Edge Newtorks 提供了一个具体的示例,展示了如何使用该架构部署一个高性能的、支持人工智能的 SPAN /网络 TAP 解决方案。该解决方案由信息技术(IT)和运营技术(OT)网络中的高数据速率、第 7 层应用程序数据的异构性和边缘计算的尺寸、重量和功率(SWaP)约束所驱动。
在边缘计算的情况下,当计算需求增加时,许多组织无法“将突发上云”,尤其是在断开连接的边缘网络上。这个场景需要为应对 I/O 和计算挑战设计一个架构,以在整个 SWaP 范围内提供性能。
此 DCO 示例通过一个常见的网络安全问题来解决这些限制,识别未加密 TCP 流量中的泄露数据(例如,泄露的密码、密钥和 PII),并代表了 Morpheus SID 演示的扩展。识别和修复这些漏洞可以减少攻击面,提高组织的安全状况。
在该示例中,DCO 解决方案将数据包接收到异构 Morpheus 流水线(用 Python 和 C ++ 混合形式编写的 GPU 和并发 CPU 阶段)中,该流水线应用 transformer 模型来检测第 7 层应用程序数据中泄漏的敏感数据。它将输出与 ELK 堆栈集成,包括安全运营中心(SOC)分析师可利用的直观可视化(图 3 和图 4)。
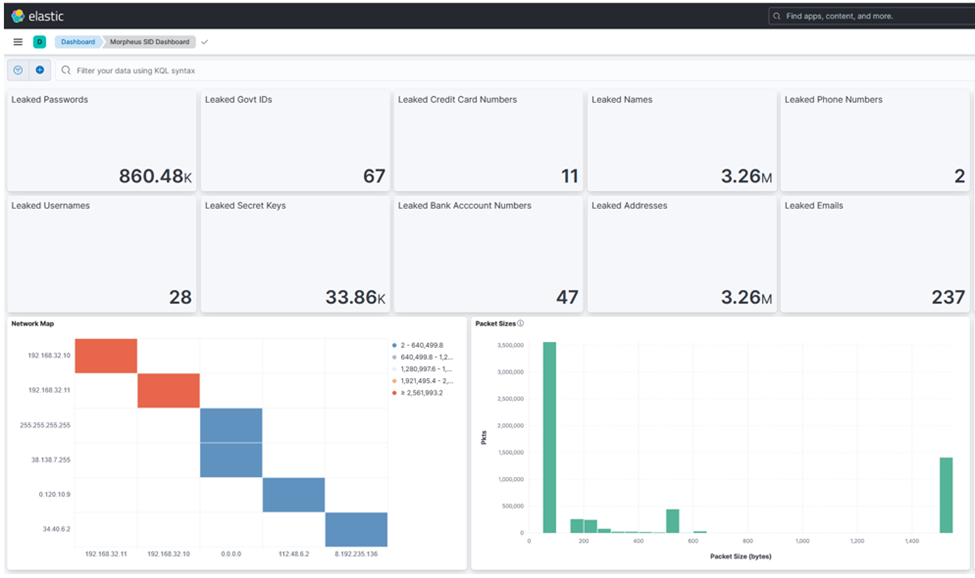
图 3:Kibana 仪表板显示 DOCA GPUNetIO
加上 Morpheus 敏感信息检测的结果,包括每种类型的总检测数、
成对网络图和数据包大小的分布
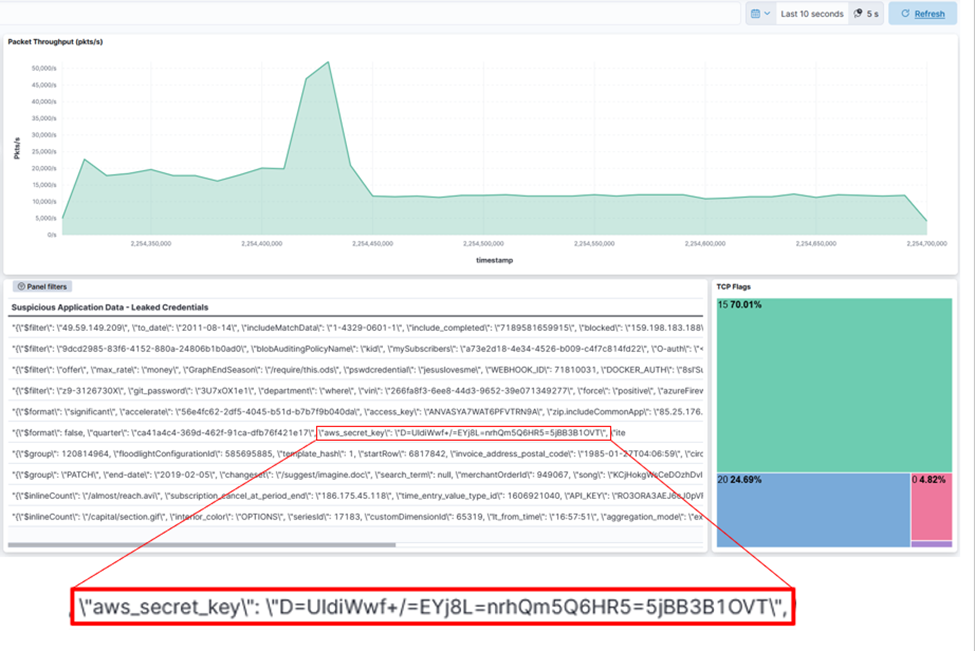
图 4:Kibana 仪表板显示 DOCA GPUNetIO 加上 Morpheus 敏感信息检测的结果,
包括每秒高达 50K 数据包的过滤和处理的网络数据包索引,包括带有泄露密钥的有效负载表
实验设置包括在具有 100Gbps NVIDIA BlueField-2 DPU 的虚拟机上运行的云原生 UDP 多播和 REST 应用程序。这些应用程序通过 SWaP 高效的 NVIDIA Spectrum SN2100 以太网交换机进行通信。数据包生成器将敏感数据注入到由这些应用程序传输的数据包中。网络数据包经过 NVIDIA Spectrum SN2100 上的 SPAN 端口聚合和镜像,然后发送到 NVIDIA A30X融合加速器,为 Morpheus 数据包检查流水线提供支持,实现了令人印象深刻的吞吐量结果。
该流水线包括来自第三方 SIEM 平台(Elasticsearch)中进行 I/O 、数据包过滤、数据包处理和索引的多个组件。DOCA GPUNetIO 主要关注 I/O 方面,使得 Morpheus 能够通过单一接收队列,以高达 100 Gbps 的速度将数据包接收到 GPU 内存中,从而消除了网络数据包处理应用程序中的一个关键瓶颈。
利用阶段级并发,该流水线将 Elasticsearch 索引吞吐量提高了 60%。
在 NVIDIA A30X 融合加速器上运行端到端数据流水线会生成的丰富的数据包,容量约为 Elasticsearch 索引器的 50%。使用两倍数量的 A30X 将使索引器完全饱和,从而提供一种方便扩展的探索方法。
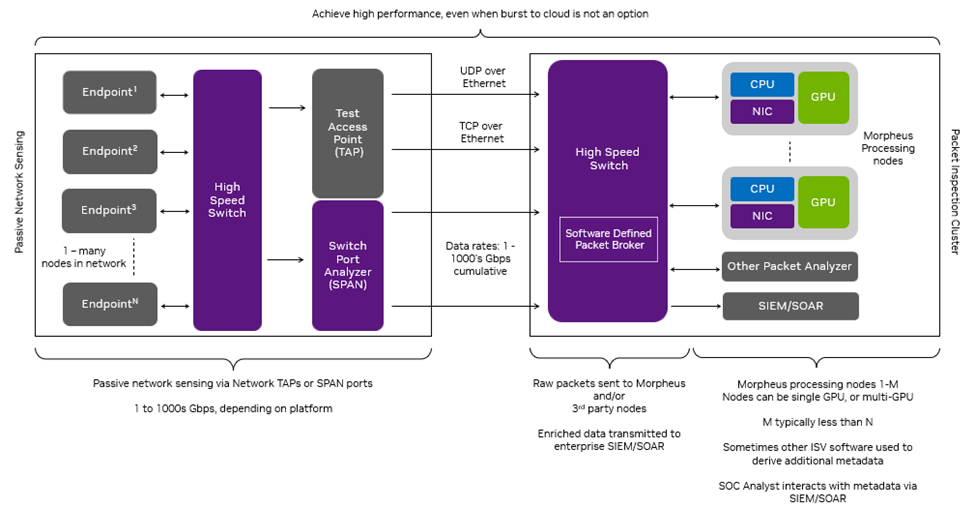
图 5:端到端数据包处理应用程序加速敏感信息的检测
虽然这个用例演示了 Morpheus 的特定应用程序,但它展示了网络数据包处理应用程序的基本组件。Morpheus 加上 DOCA GPUNetIO 共同为大量延迟敏感和计算密集型数据包处理应用程序提供了性能和可扩展性。
线速雷达信号处理
雷达、激光雷达和光学平台等遥感应用依赖于信号处理算法,将从测量环境中收集的原始数据转化为可操作的信息。这些算法通常具有很高的并行性,并且需要很高的计算负载,这使得它们非常适合基于 GPU 的处理。
此外,输入传感器会生成大量的原始数据,这意味着处理解决方案的入口/出口能力必须能够在低延迟下处理非常高的带宽。
使问题进一步复杂化的是,许多基于边缘的传感器系统具有严格的 SWaP 约束,限制了可能用于其他高通量网络方法(如基于 DPDK 的 GPUDirect RDMA)的可用 CPU 核心的数量和功率。
DOCA GPUNetIO 使 GPU 能够直接处理网络负载以及成功实现了实时传感器流应用程序所需的信号处理。
常用的信号处理算法被用于雷达探测应用中。图 6 中的流程图显示了用于将 I/Q 样本转换为检测的信号处理流水线的图形表示。

图 6:用于在仅测距雷达系统中从反射 RF 波形计算检测的信号处理流水线
MTI 滤波是一种在雷达系统中常用的技术,用于消除反射的 RF 波形中的静止背景杂波(如地面或建筑物)。这里使用的方法被称为 Three-Pulse Canceler(三脉冲消除器),它是在脉冲维度上的 I/Q 数据与滤波器系数 ‘[+1,-2,+1]’ 的卷积。
脉冲压缩使接收波形相对于目标存在的信噪比(SNR)最大化。它是通过计算接收到的 RF 数据与发射波形的互相关来实现的。
恒虚警率(CFAR)检测器计算噪声的经验估计,该噪声被定位于滤波数据的每个距离仓。然后将每个仓的功率与噪声进行比较,并在给定噪声估计和分布的情况下,如果在统计上有可能,则宣布为检测到。
大小为(#波形)x(#信道)x(#样本)的 3D 缓冲区用于保持正在接收组织好的 RF 数据(注意,在数据包接收时应用 MTI 滤波器将脉冲维度的大小减小到 1)。假设 UDP 数据流式传输没有排序,只是大致按照数据包的波形 ID 升序进行流传输。每个数据包传输大约 500 个复杂样本,样本在 3D 缓冲区中的位置取决于波形 ID、信道 ID 和样本索引。
此应用程序持续运行两个 CUDA 内核和一个 CPU 核心。第一个 CUDA 内核负责使用 DOCA GPUNetIO API 将数据包从网卡读取到 GPU。第二个 CUDA 内核基于数据包头部中的元数据将数据包数据放入正确的内存位置,并应用 MTI 过滤器,CPU 核心负责启动处理脉冲压缩和 CFAR 的 CUDA 内核。使用 cuFFT 库进行 FFT。
图 7 显示了应用程序的图形表示。
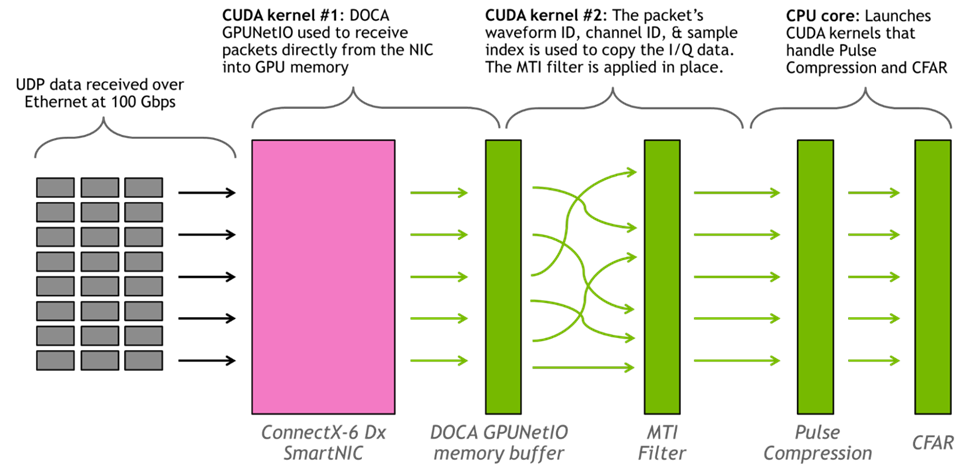
图 7:基于 GPU 的信号处理流水线的工作分配的图形表示
雷达探测流水线的吞吐量大 100Gbps。以 100Gbps 的线速运行 100 万个 16 信道波形,没有丢弃任何数据包,信号处理从未落后于数据流的吞吐量。从接收到独立波形 ID 的最后一个数据包开始测量的延迟大约为 3 毫秒。使用 NVIDIA ConnectX-6 Dx 智能网卡和 NVIDIA A100 80GB GPU 。数据是通过以太网上的 UDP 数据包发送的。
未来的工作将评估该架构仅在具有集成 GPU 的 BlueField DPU 上运行时的性能。
GPU 上的实时 DSP 服务
模拟信号无处不在,既有人工信号(例如 Wi-Fi 无线电),也有自然信号(例如太阳辐射和地震)。为了以数字方式捕获模拟数据,声波必须使用数模转换器进行转换,该转换器由采样率和采样位深度等参数控制。数字音频和视频可以使用 FFT 进行处理,使声音设计师能够使用均衡器(EQ)等工具来改变信号的一般特性。
此示例说明了 NVIDIA 产品和 SDK 是如何通过网络使用 GPU 执行实时音频 DSP 的。为此,该团队构建了一个客户端,该客户端用于解析 WAV 文件,将数据封装成多个以太网数据包,并通过网络将其发送到服务器应用程序。该应用程序负责接收数据包、应用 FFT、操纵音频信号,并最终发回修改后的数据。
客户端的责任是识别哪个部分应该发送到信号处理链的“服务器”,以及在从服务器接收到处理后的样本时如何处理它们。这种方法支持多种 DSP 算法,如重叠相加和各种采样窗口选择。
服务器应用程序使用 DOCA CUDANetIO 从 GPU 内核接收 GPU 内存中的数据包。当已经接收到数据包的子集时,CUDA 内核通过 cuFFTDx 库并行将 FFT 应用于每个数据包的有效负载。同时,不同的 CUDA 线程对每个数据包应用频率滤波器,从而降低低频或高频的幅度。基本上,它采用低通或高通滤波器。
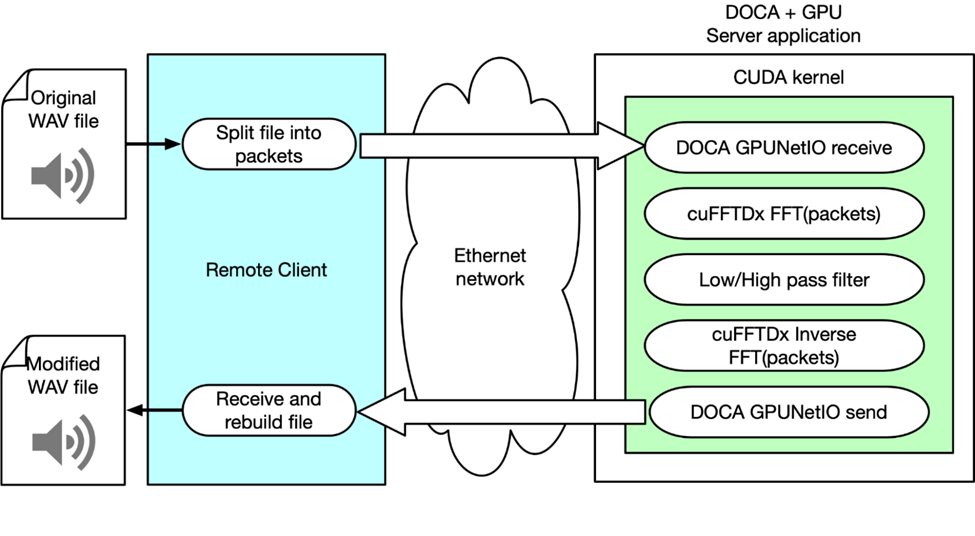
图 8:客户端 – 服务器体系结构旨在演示如何通过网络使用 GPU 执行实时 DSP 服务
对每个数据包应用逆 FFT。通过 DOCA GPUNetIO,CUDA 内核将修改后的数据包发送回客户端。客户端重新排序数据包并重新构建它们,以重新创建应用了音效的可听且可再现的 WAV 音频文件。
使用该客户端,该团队可以调整参数以优化音频输出的性能和质量。可以将流和多路复用流分离到它们的处理链中,从而将许多复杂的计算卸载到 GPU 中。通过挖掘该解决方案的潜力,它可以为云 DSP 服务提供商打开新的市场机会。
总结