--关注、星标、回复“智驾圈子”--
↓↓查看:「智驾最前沿」智驾圈子资料目录↓↓
AI运算最关键之处是存储而非AI处理器本身,AI运算90%的功耗和延迟都来自存储或者说都来自数据的搬运。90%的工况下,AI处理器都在等待存储系统搬运数据,而运算系统所需要的时间几乎是可以忽略的,所以存储系统的好坏实际决定了真实的算力大小,其中存储带宽基本可以等同于存储系统的好坏,也基本等同真实算力的高低。
在Transformer时代,模型参数至少10亿以上,模型至少1GB大小,存储带宽也决定了能不能运行Transformer。此外,存储还决定了功耗,根据英特尔的研究表明,AI芯片(加速器)当半导体工艺达到 7nm 时,数据搬运功耗高达 35pJ/bit,占总功耗的63.7%。
常见芯片存储带宽统计
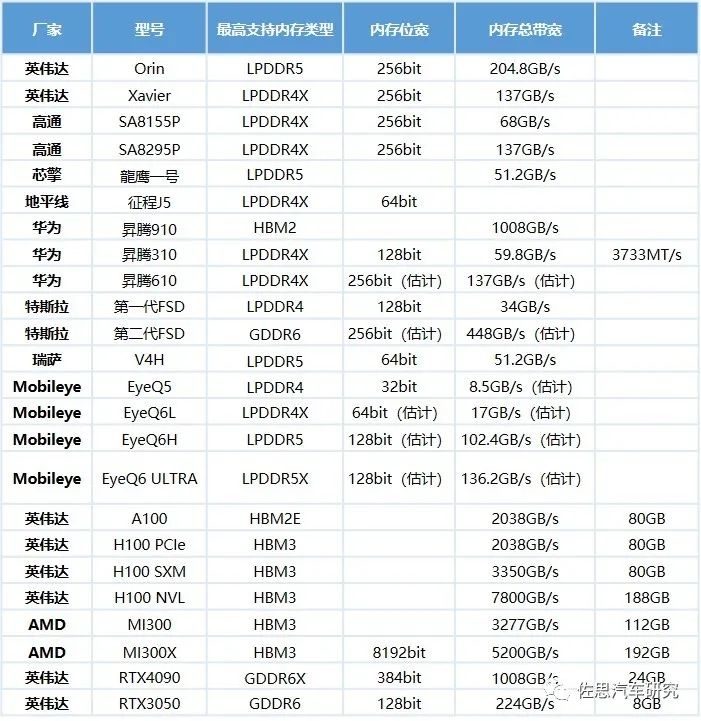
上表中单芯片最强的是AMD的MI300X,英伟达的H100 NVL是双系统并联。Mobileye的EyeQ5垫底,主要是因为其是2016年左右设计的,当时LPDDR4X的标准还未出台。数据中心或者说服务器级别的存储带宽有压倒性的优势,同样成本也是极高,现在HBM3每GB大约30-40美元(据说现在因为AI太火,且HBM3目前是SK hynix独家供应,产能有限,HBM价格涨了4-5倍,那就是120-200美元,应该不大可能,但是涨一倍还是有可能的)。
以AMD的MI300X为例,单单HBM的成本就达到5760-7680美元,这么高的价格在汽车领域是无法承受的。这也反向证明了存储带宽的重要性。HBM不仅带宽高,而且离运算单元的物理距离相比PCB板上的DRAM更近,存储到运算单元的传输时间就更短。
除了HBM,还有一种办法就是在芯片内部大量使用昂贵的SRAM,如特斯拉Dojo D1,354个核心440MB的SRAM,每MB的SRAM成本约15-20美元,仅此一项近9000美元。SRAM带宽大约800GB/s,不过SRAM容量太低,不太适合ChatGPT这样的大模型。Dojo D1的外围还是有32GB的HBM,但特斯拉的HBM带宽只有900GB/s。低带宽加上Dojo D1近似CPU的架构设计,注定其算力很低,但灵活性极高。
还有一点需要注意,上表中有些是纯AI芯片或GPU,类似于显卡,其内存就是显存。有些是SoC,其内存是与CPU共享的,共享DRAM自然不如单独显存带宽。对AI芯片或GPU来说,权重模型读出后就放在显存里,SoC的话,权重模型读出后放在共享DRAM里。
再有,这些带宽都是理论带宽,实际利用效率要看内存控制器和物理层的效率,最高能到98%左右,低的话只有约90%。其次,带宽还因为与计算单元的物理距离再打折扣,芯片内部的SRAM基本可以做到理论带宽,HBM可能还有5%的缩水,PCB板上的可能有10-15%的缩水。
还有一点LPDDR5的带宽反而不如LPDDR4X,这是因为LPDDR5更注重速度,主要服务对象是CPU而非AI芯片。

AMD的MI300X在宣传时特别点出其使用192GB的HBM3(两侧的黑色大方块就是HBM3,总共8块,每块24GB),带宽高达5.2TB/s,Infinity Fabric存储(即CPU共享存储)带宽也高达896GB/s,并且强调MI300X存储带宽是英伟达H100的1.6倍。
为何存储系统决定了实际算力?
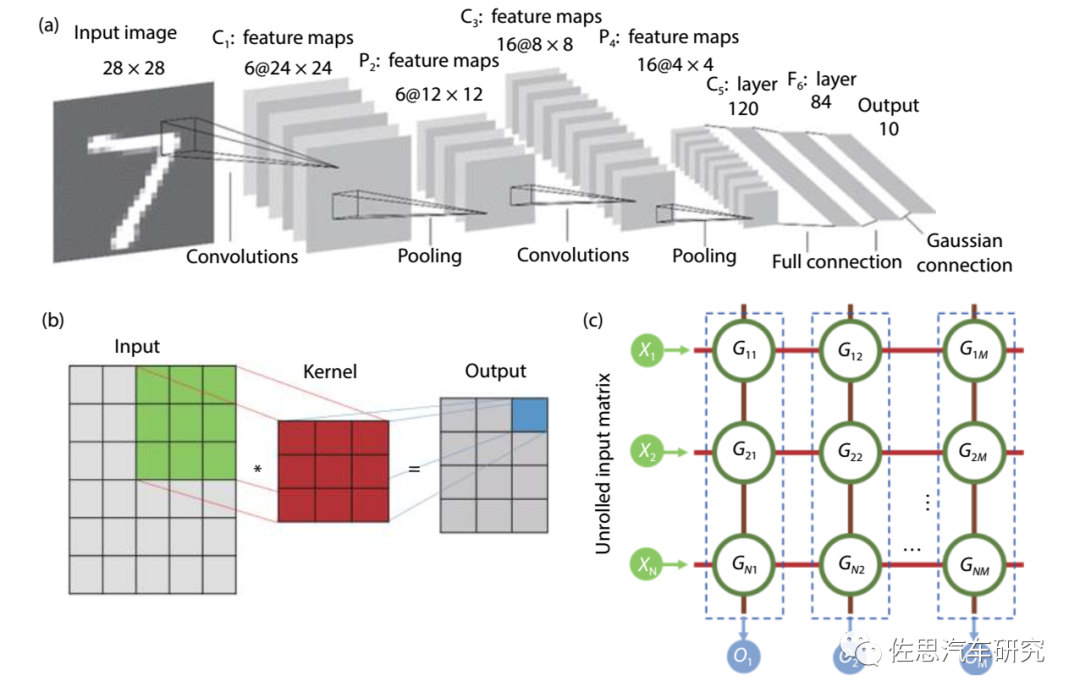
所谓人工智能AI推理部分,其运算量最大的部分是卷积运算,卷积运算分解到最底层就是输入视频序列(或语句序列等矩阵)矩阵与训练好的权重模型矩阵的乘积再累加偏值b。乘积运算所消耗的时间是纳秒级甚至皮秒级,典型Transformer的参数是1GB以上,内存带宽如果是34GB/s,那么仅每次读取模型就要消耗29毫秒,读取的同时还需要写入,与计算单元的速度相比差了千倍以上。
这就是所谓的内存墙,算力数字游戏毫无意义,出现内存墙的原因是内存的带宽与后端计算单元的速度严重不匹配,而不是冯诺依曼架构特有的,哈佛架构一样会有;另外,内存的带宽和速度是完全不同的概念,速度的单位是MHz,比如2133MHz,指内存的响应速度,每秒有2133百万次响应,也是纳秒级。
与个人电脑系统一样,如今的车载计算系统也有硬盘,训练好的权重模型存在硬盘即eMMC或UFS里,UFS 4.0版本的接口带宽是23.2Gbps也就是2.9GB/s,远低于DRAM的带宽,连LPDDR3都不如,eMMC就更低了,只有400MB/s。目前电脑硬盘是M.2接口居多,M.2跑PCIe 4.0的话带宽是64GB/s。所以未来UFS会被M.2 SSD取代。
每次运算的时候,CPU发出指令,权重模型从UFS中被取出暂存在DRAM中,如果有显存的话,就放在显存里,通常显存比共享DRAM带宽要高得多,这样每次运算就无需从UFS中取出,这也是DRAM和显存存在的意义,它的速度比UFS快太多了。
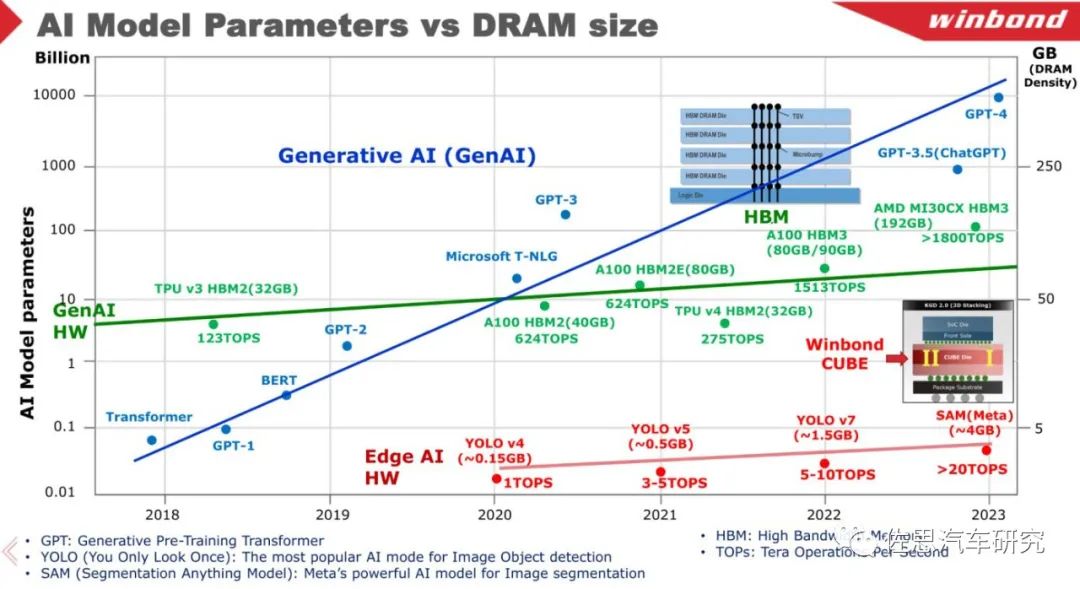
来源:Winbond
上图可以看出模型参数飞速增长,而存储带宽增长的异常缓慢。即使在边缘端,YOLO V7的模型大小也有1.5GB大小(INT8),META的语义分割SAM有4GB大小。CNN时代模型参数一般不超过1000万,用INT8格式就是大约10MB大小,芯片内部的SRAM内存勉强可以装下,每MB的SRAM成本大约20-50美元,而Transformer时代,最小都有1GB,即便是特斯拉数据中心Dojo D1这样的芯片其SRAM总容量也不到0.5GB,芯片内部肯定放不下,只能通过外部的内存。
一个系统的存储带宽由两方面决定,一是存储器本身,二是运算芯片的内存通道数。以前作者本人都忽略了后者,犯了不少错误,向大家致以深深的歉意。内存通道数部分可以看成是内存位宽,不过也有例外。

来源:Meta
上图是Meta(FACEBOOK,FACEBOOK在AI界仅次于谷歌,领先微软,CAFFE2和PyTorch仅次于TensorFlow,FAIR也是成果众多,特斯拉的骨干网RegNet就来自FACEBOOK)的第一颗自研芯片MTIA V1,非常老实地标注102.4TOPS的算力,其采用LPDDR5内存,带宽176GB/s,内部采用了64GB的SRAM,带宽800GB/s。其算力较低主要原因是运算频率太低,仅有800MHz,再有就是外部带宽仅176GB/s。之所以频率低可能也是为了对应内存带宽,内存带宽不够,后面频率再高也没用。
看存储带宽也可以看存储器的Datasheet,比如特斯拉的第一代FSD用的存储是LPDDR4,型号是 MT53D512M32D2DS-046 AAT,容量为 16Gb,总共 8 片,I/O 频率2133MHz。

来源:美光
上面是MT53D512M32D2DS-046 AAT的DATASHEET,这是美光的芯片。美光几乎垄断汽车高端DRAM市场,市占率在90%以上,厂家明确指出单die的上限是8.5GB/s(这个已包含了DDR双通道),特斯拉这颗MT53D512M32D2DS-046 AAT是两个Die,即17GB/s,加上特斯拉第一代FSD的存储带宽是128bit,即双通道,就是34GB/s,有人认为两个FSD芯片,应该是68GB/s,不过每个芯片的总线位宽不变,两个芯片即使用PCIe连接,并不等同于存储系统增加了带宽。

来源:英伟达
英伟达官方资料,4个Orin并联,内存带宽还是204GB/s。
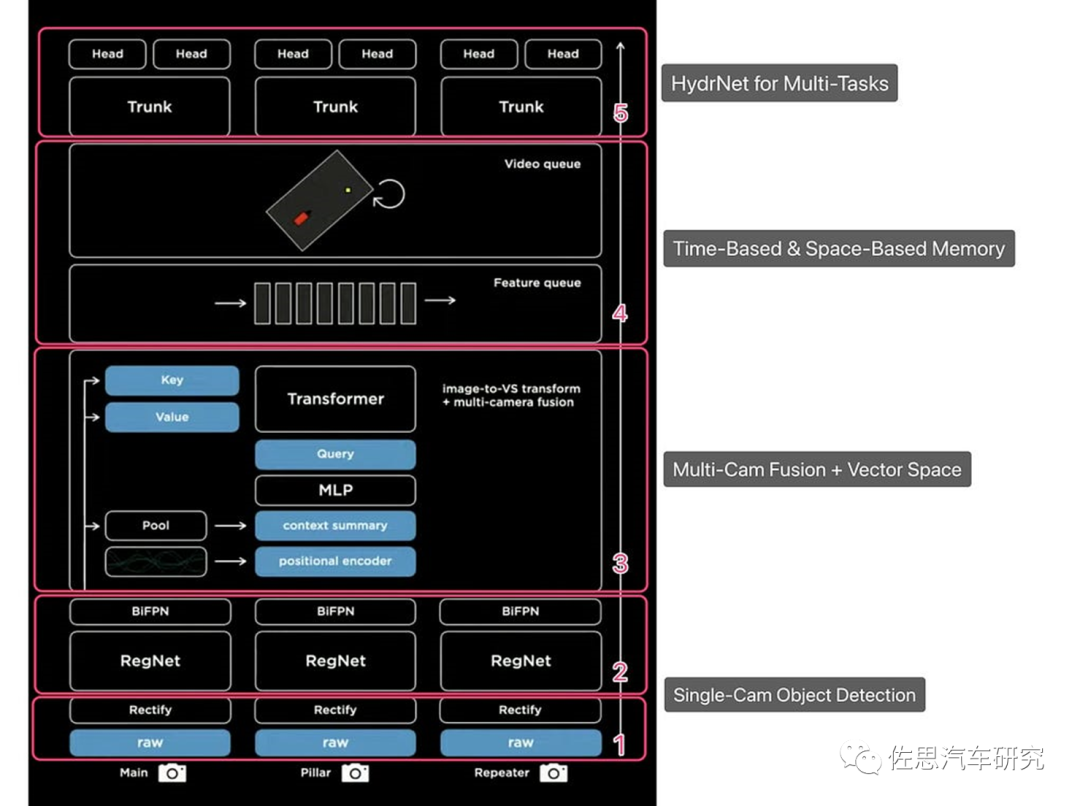
来源:特斯拉
上图是特斯拉AI日上展示的视觉架构,注意这仅仅是视觉特征提取与语义分割以及多头注意力,不包含特斯拉所谓的矢量空间转换(实际就是NeRF主导的BEV算法,加了道路模型),也不包含决策控制部分,根据特斯拉的介绍,其决策控制部分是蒙特卡洛树搜索算法。
这个视觉架构里实际不止一个Transformer,HydraNet的多任务也是用的Transfomer。除了Transfomer,RegNet和BiFPN的权重模型也不会太小,大概有0.5GB大小,如果要流畅地运行,读取权重模型的速度至少要做到每秒200次,那么存储带宽至少得400GB/s以上,600GB/s以上运行起来会比较流畅,第一代FSD的存储带宽只有34GB/s,根本做不到,即使翻倍也做不到。
所以特斯拉才在第二代FSD芯片选择了支持GDDR6,支持GDDR6需要几个条件,首先是要购买GDDR6物理层的IP;其次是要购买GDDR6的控制器IP;然后是PCB板可能需要增加层数或者用低介电常数材料;最后是CPU也要加强。第一代HW3.0即使换上GDDR6也是毫无作用,第一代FSD芯片只支持LPDDR4。需要指出目前没有车规级GDDR6,因为GDDR6本来是针对显卡市场开发的,没有考虑车载,特斯拉用的GDDR6是美光提供的D9PZR,当然也没过车规,它的最低工作温度下限是零度,而非车规级的是零下40度,不过特斯拉从来也不在乎车规。特斯拉不仅用了昂贵的GDDR6,容量相比HW3.0也增加了一倍,达到32GB,数量达到16片。
GDDR6最高带宽是672GB/s,也就是384位宽。目前还有GDDR6x,最高1008GB/s,追平HBM2,但由于物理距离远大于HBM,还是无法与HBM2相比。

来源:Cadence
想不到吧,存储第一大厂三星的GDDR6物理层是购买自CADENCE的,另外一家能供应GDDR6物理层的是RAMBUS,RAMBUS的主要收入来自存储物理层IP,每年也有大概1.4亿美元的收入。
随着权重模型的持续膨胀,存储成本会飞速增加,为了真正流畅运行大模型,单单存储方面就需要增加3000-5000美元的成本,这在汽车领域完全无法想象。
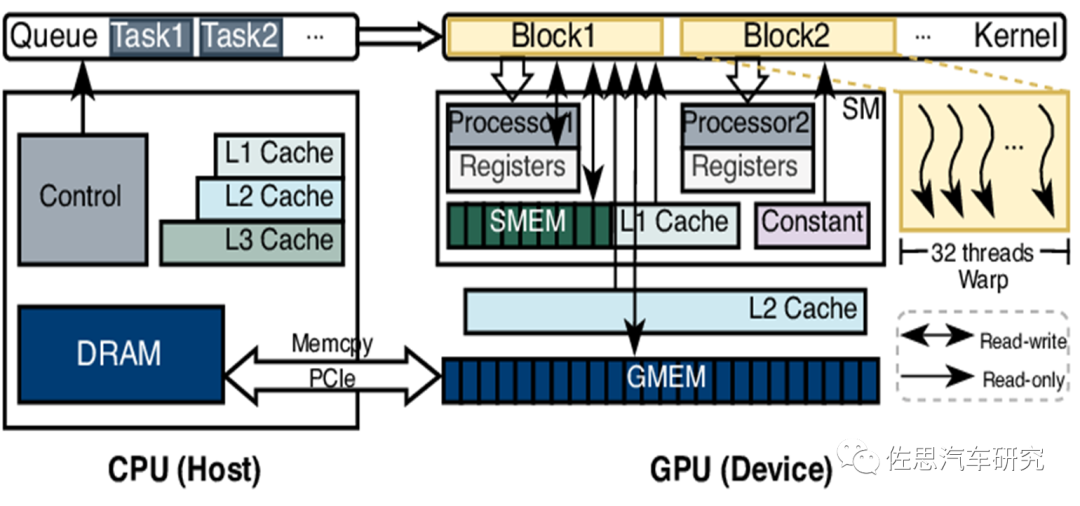
增加存储带宽也要加强CPU,这是因为GPU和AI芯片都是协处理器,也就是Device。CPU才是Host主机,GPU和AI芯片和鼠标键盘显示器打印机一样都算是外设,任务的分派和调度,数据流的控制以及数据的读取和写入均受CPU控制,上图就是CPU如何控制GPU工作的流程。数据首先是在CPU指令调度下才读取的,数据整形(如果AI芯片或GPU内部有标量运算单元也可以做)后再交给GPU,计算完后再传输给CPU写入内存。某些系统会有DMA(Direct Memory Access, 即直接存储器访问)如MCU,DMA是指无需经过CPU的直接存储,但需要经过数据总线,数据总线带宽未必有内存宽,DMA主要是缓解CPU的工作压力,因为MCU内部的CPU性能很弱。数据中心也有一些基于通讯协议的DMA,通常只用于数据中心的多显卡系统。
算力数字是浮云,唐代李白有诗句“总为浮云能蔽日,长安不见使人愁”,明白了存储带宽就不愁算力数字浮云,可以学王安石《登飞来峰》“飞来山上千寻塔,闻说鸡鸣见日升。不畏浮云遮望眼,自缘身在最高层”。
转载自佐思汽车研究,文中观点仅供分享交流,不代表本公众号立场,如涉及版权等问题,请您告知,我们将及时处理。
-- END --