▲ 更多精彩内容 请点击上方蓝字关注我们吧!
PCI-SIG组织官方宣布,已经成立新的光学工作组(Optical Workgroup),研究为PCIe规范引入光学传输接口的可能性,同时有可能开发特定于技术的外形尺寸。Insight 64 研究员 Nathan Brookwood 表示:“光连接将成为 PCIe 架构的重要进步,因为它们将实现更高的性能、更低的功耗、更远的覆盖范围和更低的延迟。许多数据需求旺盛的市场和应用,例如云和量子计算、超大规模数据中心和高性能计算将受益于利用光连接的 PCIe 架构。”
PCI-SIG 总裁兼主席 Al Yanes 表示:“我们看到业界对通过实现应用之间的光学连接来扩大已建立的多代高能效 PCIe 技术标准的覆盖范围表现出浓厚的兴趣。” “PCI-SIG 欢迎业界提出意见,并邀请所有 PCI-SIG 成员加入光学工作组,分享他们的专业知识并帮助制定具体的工作组目标和要求。”
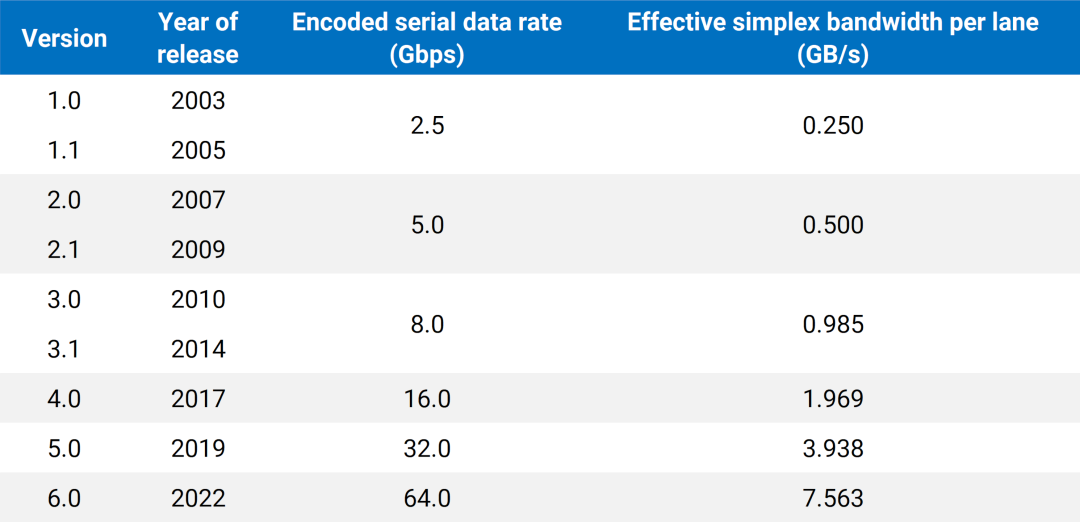
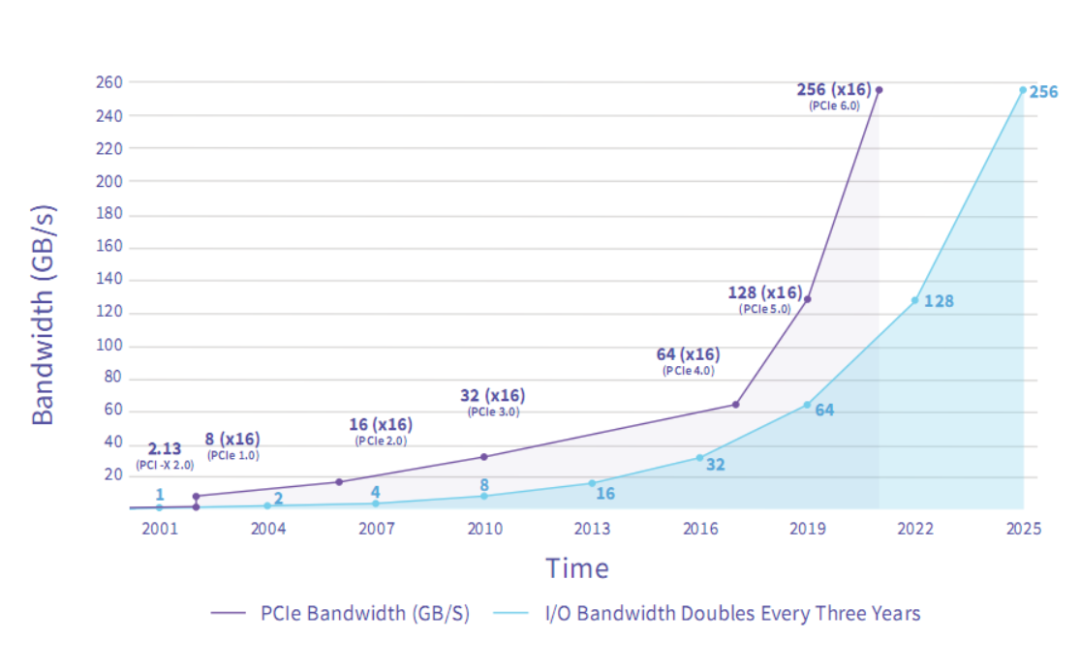
PCIe标准是Intel 2001年提出的,2003年发布1.0版本,数据传输率为2.5GT/s,2022年初发布的PCIe 6.0版本已经达到64GT/s。20年来,PCIe接口的外观形态虽然没有任何变化,而内部技术已经翻天覆地,并始终保持前后兼容。只是受到传统铜线传输机制的制约,PCIe技术的继续提升越来越难,不得不加入越来越多、越来越复杂的辅助机制,控制信号和数据完整性。在开发更新的 PCIe 标准时,PCI-SIG 致力于最大限度地减少这些问题,例如采用不需要更高频率的替代信号发送方式(例如带有 PAM-4 的 PCIe 6),以及使用中途重定时器随着材料的改进,有助于跟上标准所使用的更高频率。但 PCB 内铜走线的频率限制从未完全消除,这就是为什么近年来 PCI-SIG 为基于铜布线的 PCIe 制定了官方标准。PCIe 5.0/6.0 布线标准仍在今年年底进行工作,提供了使用铜电缆在系统内部(内部)和系统之间(外部)传输 PCIe 的选项。特别是,相对较粗的铜电缆比 PCB 走线具有更少的信号损失,克服了高频通信的直接缺点,即通道覆盖范围短(即信号传播距离短)。虽然布线标准旨在作为 PCIe CEM 连接器的替代品,而不是大规模替代品,但它的存在凸显了铜缆高频信号传输面临的问题,一旦 PCIe 7.0 完成,这个问题只会变得更具挑战性。正在开发中的PCIe 7.0继续翻番为128GT/s,x16双向理论带宽高达512GB/s。

光学传输技术的引入将为PCIe规范带来新的突破。然而,这一转变还处于起步阶段,需要经过深入的研究和开发。目前,PCI-SIG的光学工作组将致力于探索光学传输在PCIe中的可行性和潜在优势,并逐步将其纳入到PCIe技术体系中,为未来的计算机通信提供更高效、更稳定的解决方案。20世纪80年代开始,当时计算机主板上集成了数十个芯片和大量用于添加额外卡的特殊扩展槽。对于后者,一种类型主要主导本地场景:IBM 的ISA 总线(行业标准架构)。虽然相比之下对技术的改进并不那么成功,但该系统总体上在行业内变得无处不在。到下一个十年到来时,更快的处理器帮助推动了对性能更好的扩展总线的需求,最终产生了两种新格式——英特尔的 PCI 总线(外围组件互连)和来自视频电子标准协会的VLB(VESA 本地总线)。两者在 1992 年同时出现,尽管 PCI 最初看起来是两者中较慢的,因为它被设计为以固定的 33 MHz 运行(后来的规范修订版确实允许 66 MHz,但消费类 PC 从未真正支持这一点) . 相反,VLB 以与 CPU 的前端总线 (FSB:front-side bus) 相同的时钟运行,从而允许 VLB 达到 40 或 50 MHz,具体取决于中央处理器。但是,它并不总是稳定在该速率,并且延迟比 PCI 更差。典型的 VLB 扩展槽也比 PCI 扩展槽大得多。尽管有这些优势,PCI 还是花了一些时间才在主板行业获得关注,尤其是在工作站和服务器市场。当时,家庭 PC 用户通常没有很多扩展卡,也没有任何对总线有很大要求的扩展卡。然而,随着 3D 显卡行业的腾飞,这种情况发生了变化,最好的显卡配备了 PCI 连接器。结果,主板开始偏爱新总线而不是旧总线。随着这些图形加速器功能的增强和游戏利用这一点,PCI 总线的局限性变得显而易见。与之前的 ISA 和 VLB 一样,PCI 是一种并行数据总线——这意味着 PCI 扩展槽中的所有卡都使用相同的总线,并且必须轮流传输和接收数据。对于图形卡,这可能会有问题,因为它们很容易占用总线。英特尔通过在 1997 年开发加速图形端口 (AGP:Accelerated Graphics Port) 解决了这个问题,它为显卡提供了专门的 PCI 总线。随着旧千年向新千年的过渡,对更快总线的需求越来越大。英特尔推出 PCI 总线后不久,它成立了一个特别兴趣小组 ( PCI-SIG ),以支持主板和扩展卡供应商确保其硬件符合规范。到 2000 年代初,这个小组由数百名成员组成,其中五家(康柏、戴尔、惠普、IBM 和微软)与英特尔合作,以替代 PCI。代号为 3GIO(第 3 代 I/O)的PCI-SIG于 2002 年 4 月宣布了其劳动成果,引入了名为PCI Express 的新技术。PCIe也由此而来,它的全称是Peripheral Component Interconnect Express。此后,随着时间的推移PCIe不断改进以适应现代计算机的最新带宽需求。目前,加入PCI-SIG的会员公司超过800家,各自遵循PCI-SIG所订定的规格,研发功能有异但可相互操作沟通的产品。PCI-SIG已经订定的规格有PCI、PCI-X与PCI Express。PCI-SIG现任董事会董事成员也扩充到英特尔、戴尔、AMD、高通、惠普、新思科技(Synopsys)、安捷伦(Agilent Technologies)与英伟达的公司代表。
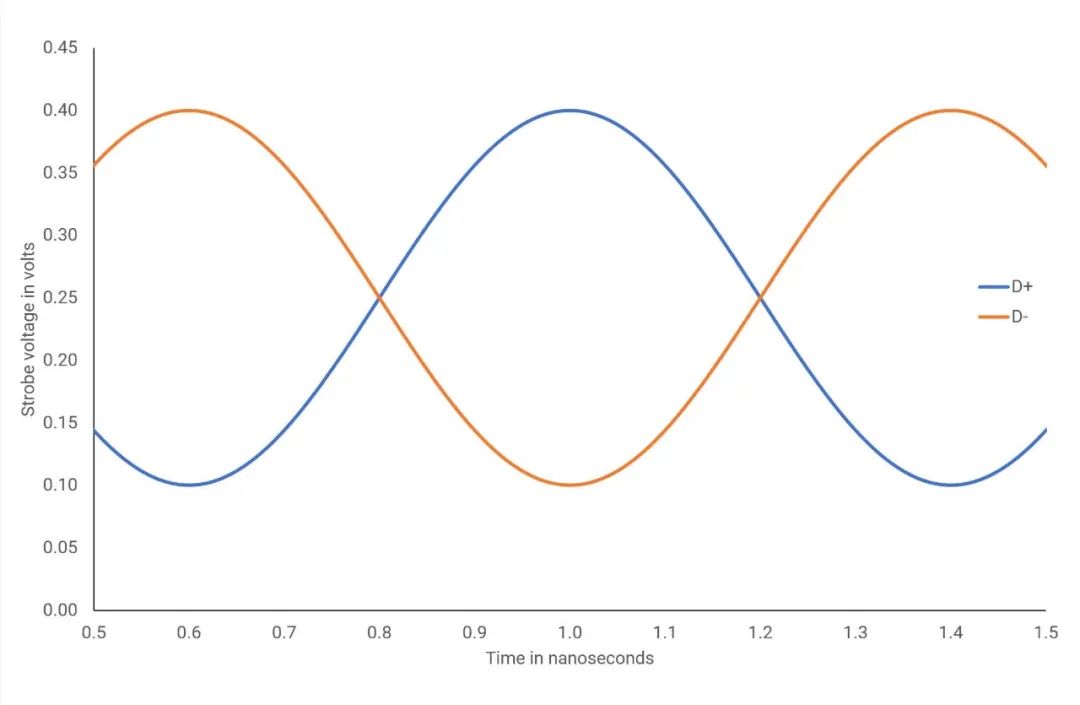
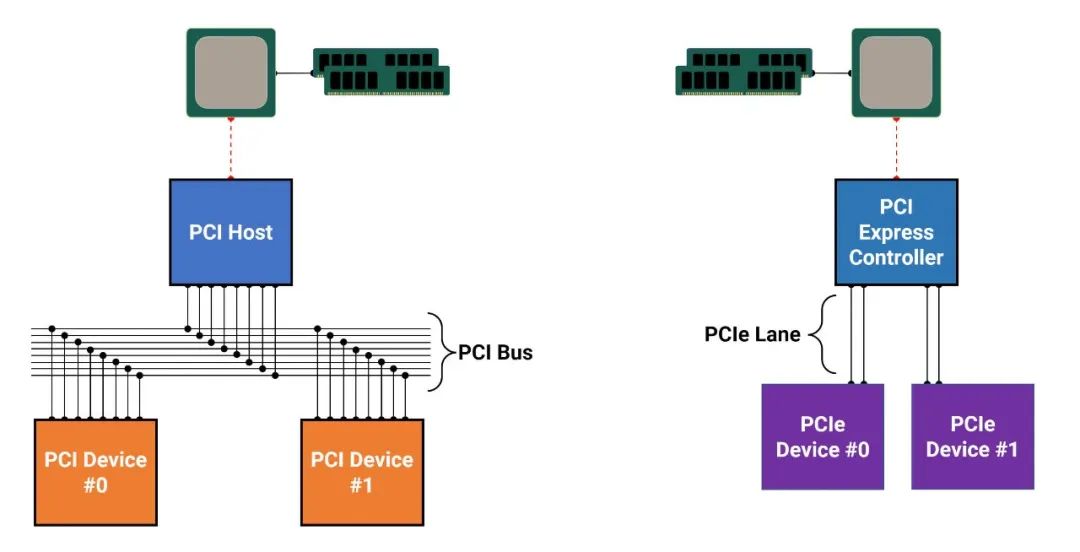
尽管名称相同,但 PCI Express(通常简称为 PCIe)和 PCI 总线几乎没有共同之处。最显着的区别是 PCIe 是一个点对点系统——只有一个设备使用总线并且不与其他任何设备共享。在某些方面,这似乎 PCIe 只是升级的 AGP,但在数据传输方式上也存在显著差异。PCI 和 AGP 使用并行数据通信,同时发送和接收多位数据,而 PCIe 使用串行通信,每个周期只发送一位。这种方法消除了并行通信中可能发生并导致问题的时钟偏差问题,最终使 PCIe 能够以更高的时钟速度运行。PCI 有 66 MHz 的绝对限制(扩展版本 PCI-X 可以达到 533 MHz),而 PCI Express 的最慢时钟速度是惊人的 1250 MHz。这种速度是通过使用低压差分选通脉冲 (LVDS:low voltage differential strobes) 实现的——一对信号,相位相差 180 度,工作电压仅为 PCI 和 AGP 使用的电压的一小部分。PCI Express 的串行特性还显著减少了数据传输所需的电线/走线数量,PCI 需要 32 条,PCIe 只需 4 条。从技术上讲,只需要两个,每个选通脉冲一个,但是由于 PCI Express 是全双工的,同时在两个方向上发送信息,所以总是使用双组成对的选通脉冲。这组四根线更广为人知的是PCIe 通道,规范通过乘法器指示使用的通道数,例如,x1 是一个通道,x4 是四个通道,x16 是十六个通道通过LVDS系统的工作方式,单通道 PCIe 总线可以在一个方向上以大约 200 MB/s 的最低速率传输数据。在纸面上,它应该比这更高,但传输的信息被编码并以 8 位数据包的形式发送,每个连续的数据包沿着一个连续的通道发送。结果,由于编码需要额外的位,实际数据速率总是较低。串行通信和基于数据包的数据传输的结合也意味着插槽连接中需要相对较少的引脚来管理所有内容。任何 PCI Express 设备的最小值是 18,尽管不是所有的都需要使用。相比之下,PCI插槽至少需要56个,无论排列多紧凑,都不可避免地占用更多空间。从左到右:PCIe x1、PCIe x16、PCI、PCIe x1、PCIe x16
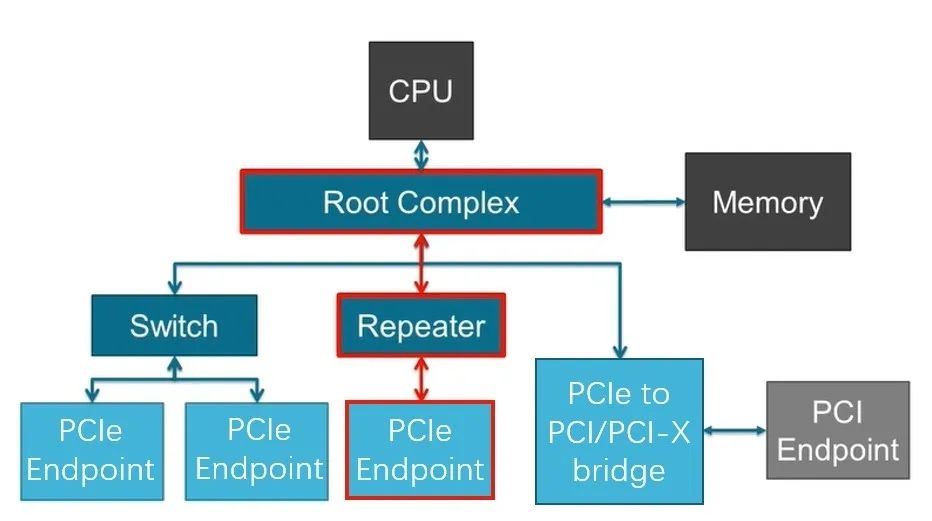
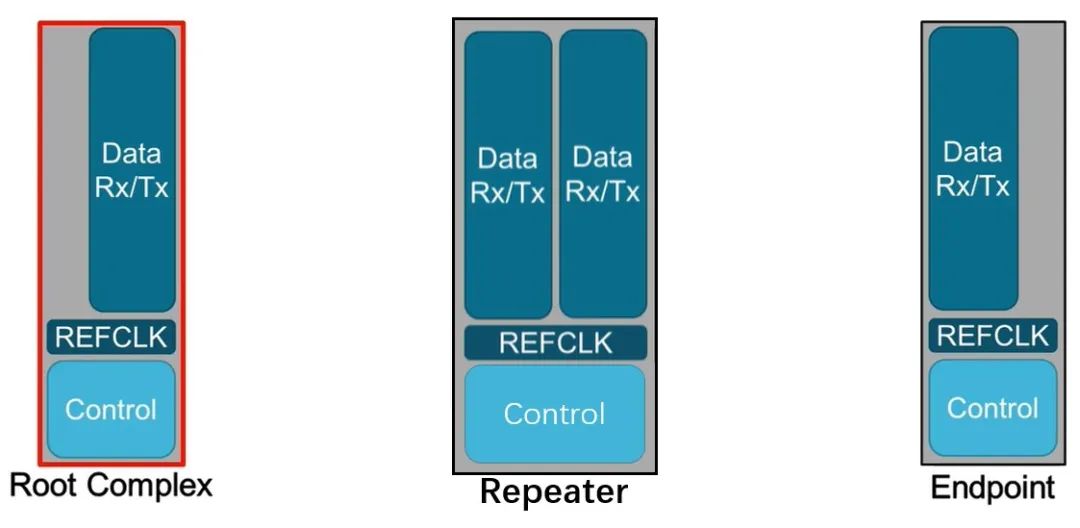
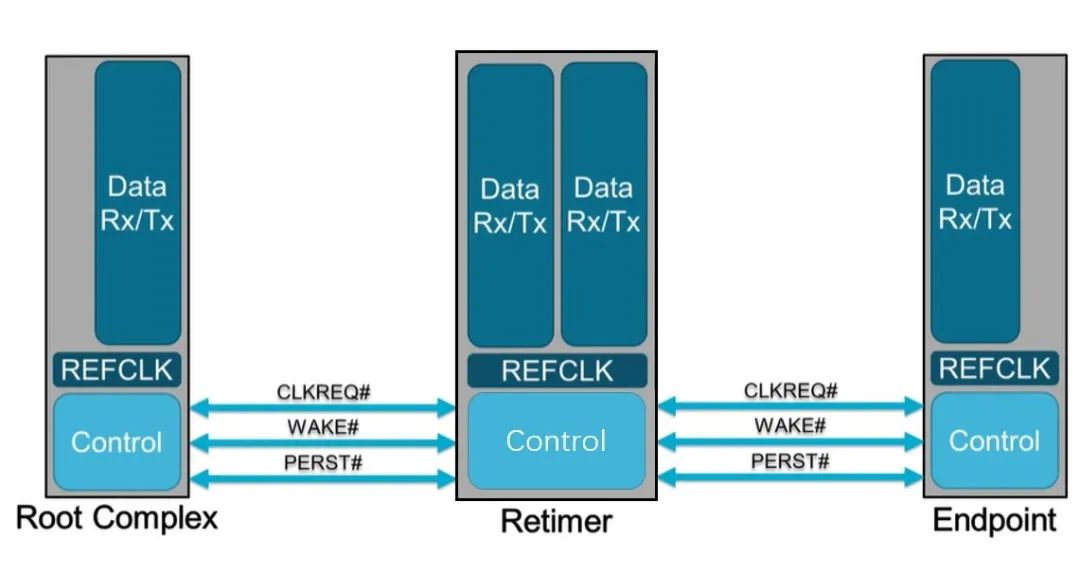
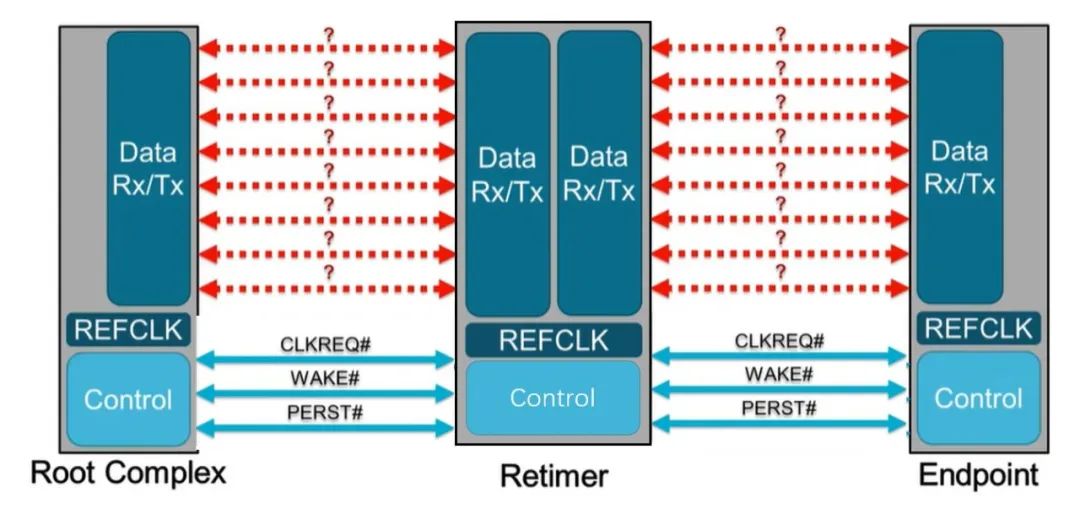
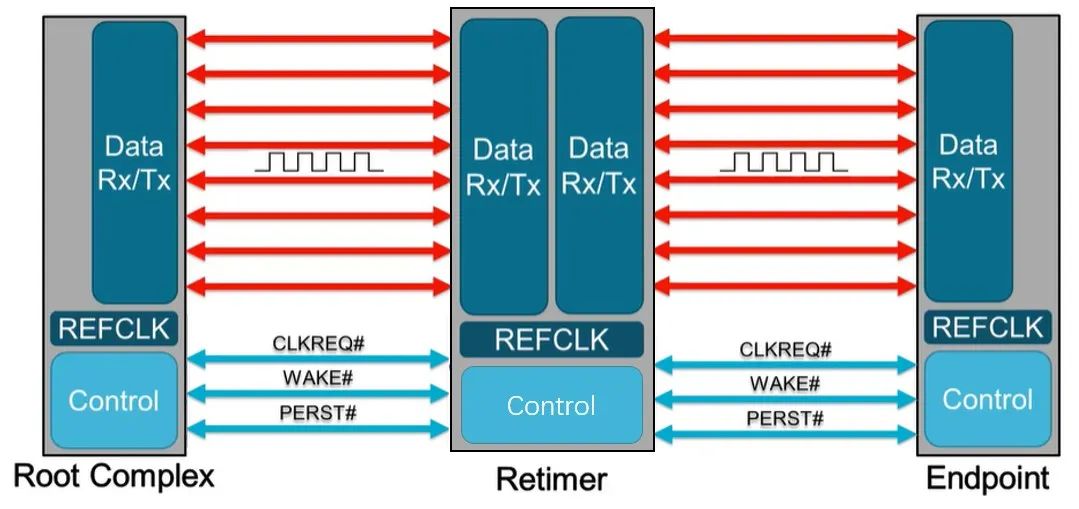
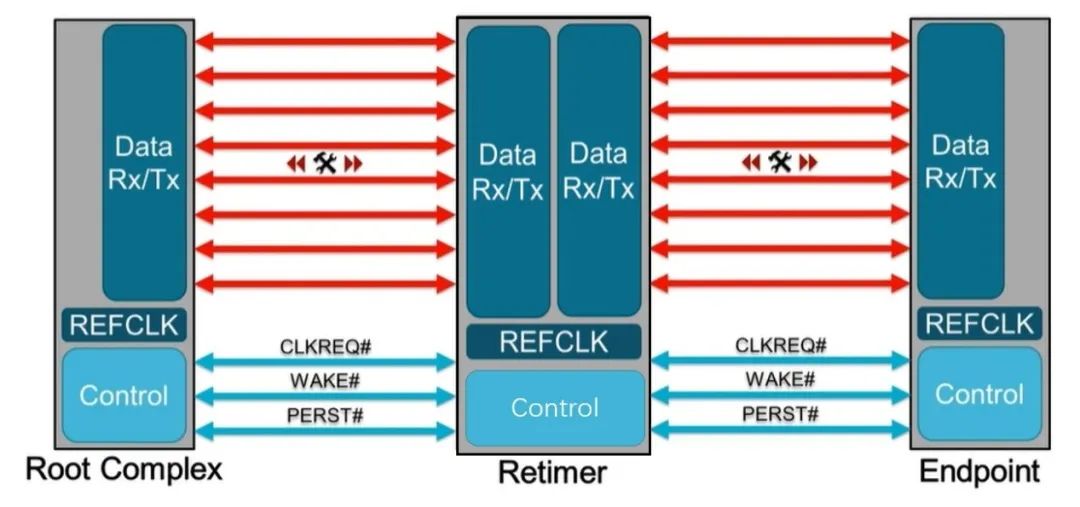
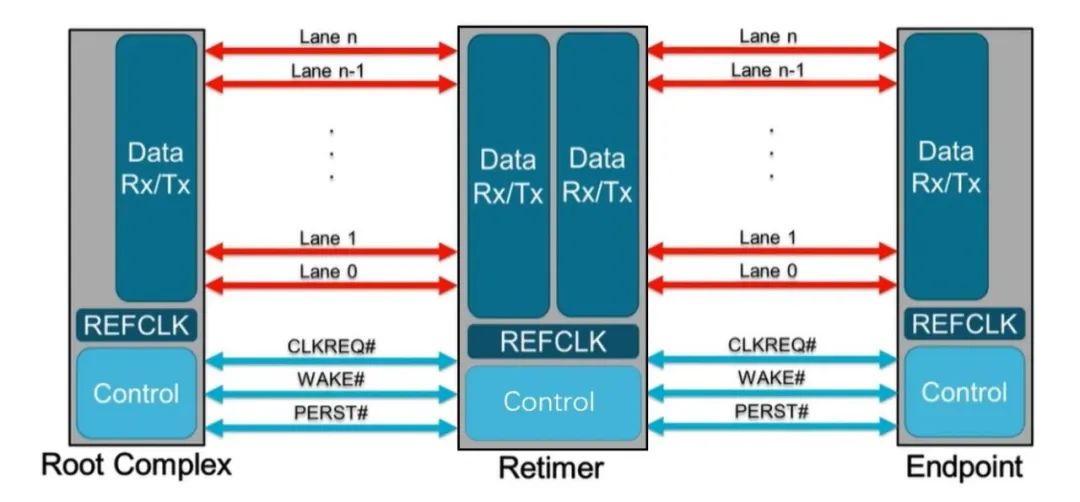
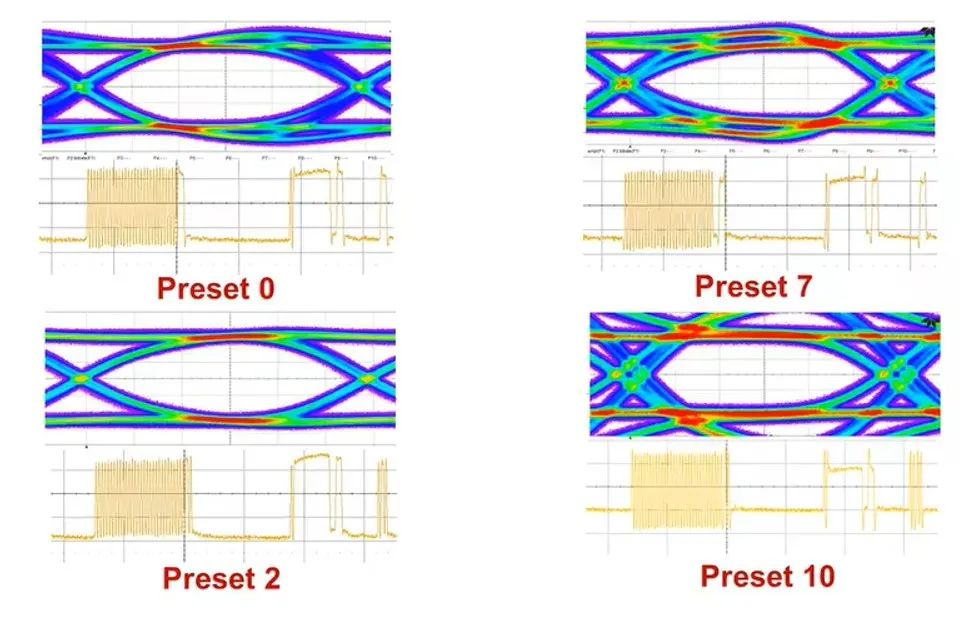
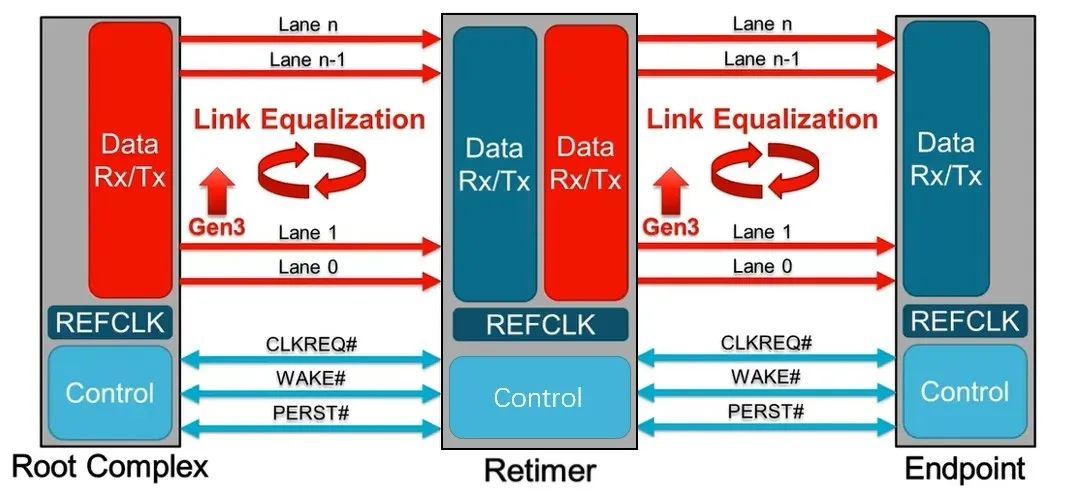
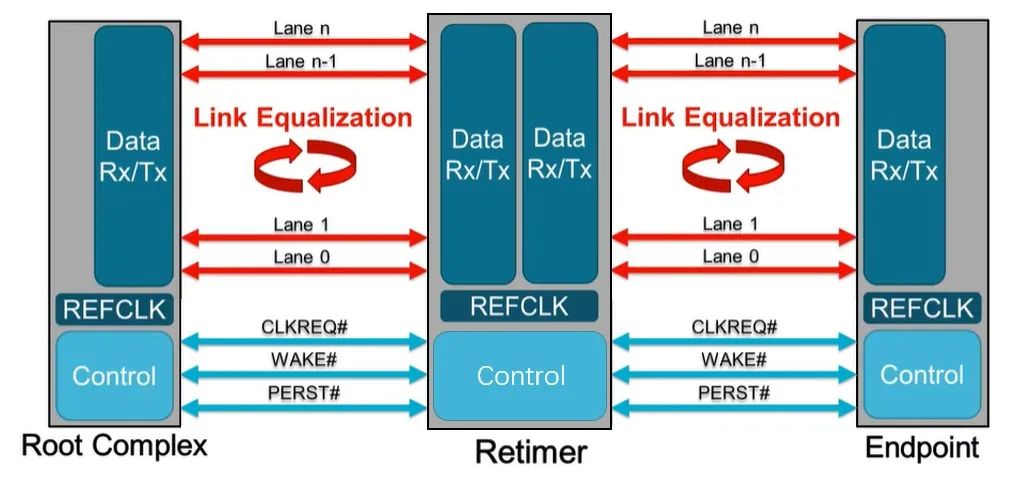
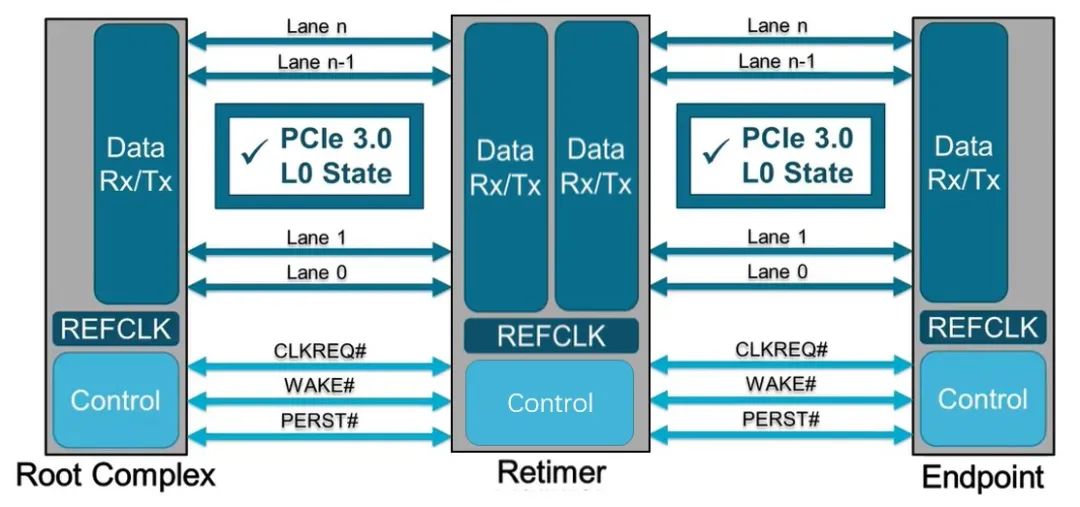
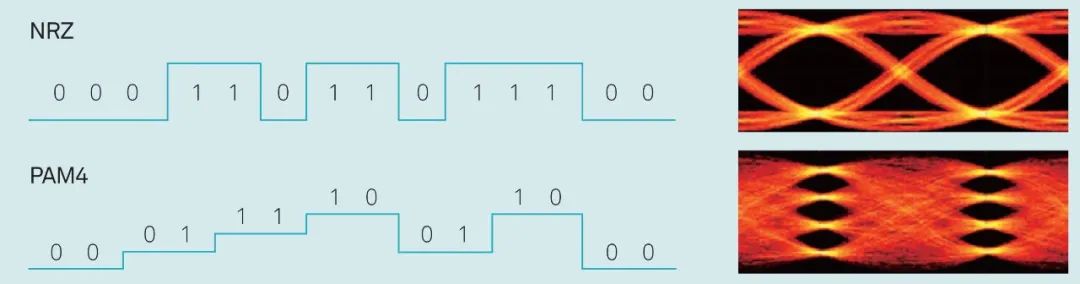
也就是说,PCIe x16 插槽明显比任何标准 PCI 或 AGP 插槽长,但没有那么高。事实上,无论 PCI Express 扩展插槽的长度如何,它们的宽度和高度几乎都是相同的(用于显卡的插槽有时会高一点)——更长的插槽只是容纳更多的传输通道。与电源和系统管理相关的一切都位于插槽的第一部分,塑料槽口之前。PCIe采用的是树型拓扑结构, 一般由根复合体(Root Complex),中继器(Repeater),终端设备(Endpoint)等类型的PCIe设备组成。接下来将讲述PCIe如何通过下图突出显示的典型链路进行初始化和传输。Root Complex: 根复合体是CPU和PCIe总线连接的接口。主要负责存储器域到PCIe总线域的地址转换,随着虚拟化技术的引入,根复合体的功能也越来越复杂。根复合体把来自CPU的request转化成PCIe的4类request(configuration、memory、I/O、message)并发送给下面的设备。Repeater:中继器是一种信号调节装置,可分为两类:Retimers和Redriver,两者都是常用的PCIe组件,Retimer通过内部时钟重构信号,再恢复后发送出去;Redriver则是通过信号均衡化和预加强等技术,重新加强再发送出去。在图示中,我们将使用PCIe 4.0兼容的Retimers举例。PCIe Endponit: PCIe终端设备,是PCIe树型结构的末端节点。比如SSD,网卡、GFX卡等等。在了解PCIe链路是如何建立以及数据如何通过PCIe协议传输之前,我们先了解一下常见PCIe控制信号的功能。PERST#信号为全局复位信号,由处理器系统提供。处理器系统需要为PCIe插槽和PCIe设备提供该复位信号。PCIe设备使用该信号复位内部逻辑,当该信号有效时,PCIe设备将进行复位操作。WAKE#和CLKREQ#信号都用于在本文讨论范围之外的低功率状态之间转换。REFCLK#是PCIe设备开始数据传输的先决条件,PCIe设备通过使用REFCLK#提供的100 MHz外部参考时钟(Refclk),用于协调在两个PCIe设备间的数据传输。PCIe链路在初始状态时,需要检测对端设备是否存在,然后才能进行链路训练。所有PCIe设备通电并提供参考时钟信号后在每个通道上将拥有接收器检测(Receiver Detection)电路,该电路将允许PCIe设备确定是否有要配对的链路伙伴。假设PCIe Rx检测电路检测到另一个设备,则每个通道将开始以2.5 GT/s的速度进行传输串行数据。2.5 GT/s是PCIe 1.0采用的数据速率,另外由于PCIe 1.0与任何PCIe设备兼容,因此每个PCIe链路都以相同的链路初始化过程开始。以下图为例,Root Complex、Retimer和Endpoint都以PCIe 1.0的速度开始传输。在经过PCIe链路初始化后,每个器件开始接收数据并做出响应。PCIe连接开始链路训练过程并进入配置阶段,在该阶段中,由于通道长度变化而导致数据中的任何偏差都能得到校准,PCIe链路的宽度、链路速率、链路翻转和链路极性也在此阶段确定。当存在多条链路时,则PCIe连接称为PCIe分叉。在示例中,有一个非分叉连接,即所有通道都分配给编号为0的链路。由于Retimer链路分为两部分,其两侧的链路分别进行链路初始化。在确定链路和通道号后,PCIe链路可以进入多种状态。以进入L0状态举例,这是发送和接收数据与数据包的正常操作状态。到达L0后Root Complex和Endpoint可相互通信,PCIe链路也可转换为多种低功耗状态或另一种链路训练状态。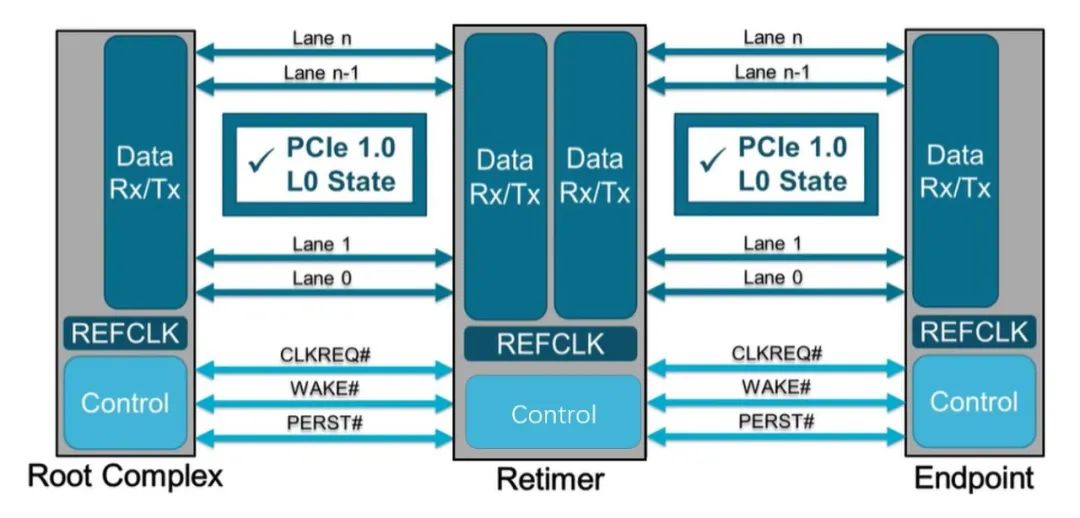 当PCIe设备支持PCIe Gen2时,链路速度也会随之提高。如果数据速率为PCIe Gen3或以上,PCIe链路将需要经历额外链路优化过程(称为链路均衡)。链路均衡以建立设备间稳定的连接为目的。通过调节Tx (传输端)和Rx (接收端)的设置,提高信号质量,使PCIe链路以最稳定且更快的速率传输。由于PCIe在Gen3及以上的每一代均需优化连接,因此链路均衡过程可能发生多次。例如:若所有PCIe设备为Gen5,则有3次链路均衡过程(第1次:Gen1-Gen3;第2次:Gen3-Gen4;第3次:Gen4-Gen5)。链路均衡通过PCIe 规范中定义的preset值来实现,preset指不同的预过冲(Preshoot)和去加重(De-emphasis)的组合。对于Gen3和Gen4,有11个preset值,即preset0-preset10。对于不同的链路情况,系统要求Rx端发送Tx EQ preset设置请求给Tx端,让其做对应的preset均衡设置;Tx端发送Rx EQ均衡设置,要求Rx端做相应的设置,最终获得一个最优的均衡组合和Rx端的眼图。Phase0:第1阶段链路均衡涉及上游端口(Upstream port)和下游端口(Downstream port)之间的精确动态协商,下游端口通过向上游设备发送每个通道所需的发送器preset值来开始链路均衡,被称为第0阶段链接均衡。在接收到下游端口的请求后不久,上游端口增加到第3代(Gen3)链路数据速率,并开始使用所需preset将训练序列发送回下游端口。链路速度增加至Gen3(8 GT/s)后,链路均衡过程通过来回发送preset值来协商每个端口的preset配置,从而继续优化链路。Phase1:为了充分优化链路,以便能够交换训练序列(Training Sequences)并且完成用于精调目的的剩余链路均衡阶段,尽管有出现链路质量差的可能性,相同的训练序列依然会被重复发送,来确保下游端口接收到正确的preset值。Phase2:在第1阶段链路的误码率实现BER≤10e-4后,进入到Phase 2,随后进一步优化上游端口的preset值,直至获得最优设置,链路的误码率应满足BER ≤ 1E-12。Phase3:到第3阶段对下游端口执行相同的协商。上游端口通过训练序列发送均衡请求去调整下游端口的preset值,直至获得最优设置,链路的误码率应满足BER ≤ 1e-12。当Phase3完成后,链路均衡也已完成,此时链路以Gen3的速率进入L0状态,并在该速率进行稳定通信。对于更高的传输速率,PCIe设备必须进行多次链路均衡过程。然而在某些主板设计中,尤其是那些具有长通道链路的主板,这种信号质量无法实现,可能需要另外的信号调节。在这种情况下,中继器(如Redriver,Retimer)则被用来做信号调节,并在PCIe设备和根复合体之间提供高质量信号。多年来,硬件变得越来越强大,应用程序和游戏对硬件的要求也越来越高。自然地,PCI Express 从一开始就定期更新以满足带宽要求。对更新的一个重要限制是对完全向后兼容性的要求。例如,PCIe 3.0 设备必须能够在 PCIe 5.0 插槽中工作。自 2003 年首次发布以来,PCI-SIG 已对规范进行了八次更新,主要修订版具有更快的数据传输速率,以及对所采用的编码方案(以减少带宽损失)和信号完整性的改进。次要修订侧重于改进电源管理、控制系统和其他方面。在每次修订的开发过程中,PCI-SIG 的相关成员都会进行可行性研究,以确定哪些速度和功能可以在保持低成本的情况下切实进行大规模生产。这就是为什么对于 3.0 版,选通脉冲的时钟速率仅增加了 60%,而不是像以前的版本那样加倍。3.0 版引入了更有效的编码方案(具体来说,8b/10b 用于 1.0 和 2.0,而 128b/130b 用于 3.0 到 5.0),这就是有效带宽相对于时钟速度更高的原因。如果不需要编码,PCIe 1.0 的有效带宽将达到 0.313 GB/s。对于 6.0 版,信号方法从NRZ 切换到 PAM4 (在GDDR6X内存中使用),并且放弃了编码以支持各种纠错系统。从带宽数据来看,单根 DDR4-3200 RAM 的峰值吞吐量为 25 GB/s,因此 PCIe 6.0 的四通道可以与之匹配。这听起来可能不是特别令人印象深刻,但对于日常 PC 和世界各地其他计算机器中使用的通用通信总线来说,这是一个显著的改进。但是,为什么 PC 现在才刚刚采用 PCIe 4.0 和 5.0,前者的规范早在 2017 年就发布了(而 5.0 是在那之后的两年)?它归结为需求和成本问题。按照目前的情况,个人电脑有足够的带宽来在内部移动数据,除了视频游戏之外,家用电脑还没有太大的空间需要 PCIe 6.0 之类的东西。然而,在服务器领域,系统设计人员会很乐意使用他们可以获得的所有带宽,而且正是在该领域,我们可能会看到最先使用的最新规范。
当PCIe设备支持PCIe Gen2时,链路速度也会随之提高。如果数据速率为PCIe Gen3或以上,PCIe链路将需要经历额外链路优化过程(称为链路均衡)。链路均衡以建立设备间稳定的连接为目的。通过调节Tx (传输端)和Rx (接收端)的设置,提高信号质量,使PCIe链路以最稳定且更快的速率传输。由于PCIe在Gen3及以上的每一代均需优化连接,因此链路均衡过程可能发生多次。例如:若所有PCIe设备为Gen5,则有3次链路均衡过程(第1次:Gen1-Gen3;第2次:Gen3-Gen4;第3次:Gen4-Gen5)。链路均衡通过PCIe 规范中定义的preset值来实现,preset指不同的预过冲(Preshoot)和去加重(De-emphasis)的组合。对于Gen3和Gen4,有11个preset值,即preset0-preset10。对于不同的链路情况,系统要求Rx端发送Tx EQ preset设置请求给Tx端,让其做对应的preset均衡设置;Tx端发送Rx EQ均衡设置,要求Rx端做相应的设置,最终获得一个最优的均衡组合和Rx端的眼图。Phase0:第1阶段链路均衡涉及上游端口(Upstream port)和下游端口(Downstream port)之间的精确动态协商,下游端口通过向上游设备发送每个通道所需的发送器preset值来开始链路均衡,被称为第0阶段链接均衡。在接收到下游端口的请求后不久,上游端口增加到第3代(Gen3)链路数据速率,并开始使用所需preset将训练序列发送回下游端口。链路速度增加至Gen3(8 GT/s)后,链路均衡过程通过来回发送preset值来协商每个端口的preset配置,从而继续优化链路。Phase1:为了充分优化链路,以便能够交换训练序列(Training Sequences)并且完成用于精调目的的剩余链路均衡阶段,尽管有出现链路质量差的可能性,相同的训练序列依然会被重复发送,来确保下游端口接收到正确的preset值。Phase2:在第1阶段链路的误码率实现BER≤10e-4后,进入到Phase 2,随后进一步优化上游端口的preset值,直至获得最优设置,链路的误码率应满足BER ≤ 1E-12。Phase3:到第3阶段对下游端口执行相同的协商。上游端口通过训练序列发送均衡请求去调整下游端口的preset值,直至获得最优设置,链路的误码率应满足BER ≤ 1e-12。当Phase3完成后,链路均衡也已完成,此时链路以Gen3的速率进入L0状态,并在该速率进行稳定通信。对于更高的传输速率,PCIe设备必须进行多次链路均衡过程。然而在某些主板设计中,尤其是那些具有长通道链路的主板,这种信号质量无法实现,可能需要另外的信号调节。在这种情况下,中继器(如Redriver,Retimer)则被用来做信号调节,并在PCIe设备和根复合体之间提供高质量信号。多年来,硬件变得越来越强大,应用程序和游戏对硬件的要求也越来越高。自然地,PCI Express 从一开始就定期更新以满足带宽要求。对更新的一个重要限制是对完全向后兼容性的要求。例如,PCIe 3.0 设备必须能够在 PCIe 5.0 插槽中工作。自 2003 年首次发布以来,PCI-SIG 已对规范进行了八次更新,主要修订版具有更快的数据传输速率,以及对所采用的编码方案(以减少带宽损失)和信号完整性的改进。次要修订侧重于改进电源管理、控制系统和其他方面。在每次修订的开发过程中,PCI-SIG 的相关成员都会进行可行性研究,以确定哪些速度和功能可以在保持低成本的情况下切实进行大规模生产。这就是为什么对于 3.0 版,选通脉冲的时钟速率仅增加了 60%,而不是像以前的版本那样加倍。3.0 版引入了更有效的编码方案(具体来说,8b/10b 用于 1.0 和 2.0,而 128b/130b 用于 3.0 到 5.0),这就是有效带宽相对于时钟速度更高的原因。如果不需要编码,PCIe 1.0 的有效带宽将达到 0.313 GB/s。对于 6.0 版,信号方法从NRZ 切换到 PAM4 (在GDDR6X内存中使用),并且放弃了编码以支持各种纠错系统。从带宽数据来看,单根 DDR4-3200 RAM 的峰值吞吐量为 25 GB/s,因此 PCIe 6.0 的四通道可以与之匹配。这听起来可能不是特别令人印象深刻,但对于日常 PC 和世界各地其他计算机器中使用的通用通信总线来说,这是一个显著的改进。但是,为什么 PC 现在才刚刚采用 PCIe 4.0 和 5.0,前者的规范早在 2017 年就发布了(而 5.0 是在那之后的两年)?它归结为需求和成本问题。按照目前的情况,个人电脑有足够的带宽来在内部移动数据,除了视频游戏之外,家用电脑还没有太大的空间需要 PCIe 6.0 之类的东西。然而,在服务器领域,系统设计人员会很乐意使用他们可以获得的所有带宽,而且正是在该领域,我们可能会看到最先使用的最新规范。提供电流的引脚都在最左边,缺口之前
不过,并非每个更新版本都一帆风顺,供电一直是系统的一个长期问题。无论设备使用何种尺寸的 PCIe 插槽,它们都带有少量 +3.3 V 和 +12 V 引脚,用于提供运行设备所需的电流。从第一个 PCIe 版本开始,+3.3V 引脚的组合电流限制为 3 A,并且根据插槽中使用的附加卡尺寸,+12 V 引脚的电流限制高达 5.5 A。这意味着对于全长 x16 卡,该设备的功耗限制为 75.9 W,这对于当时绝大多数显卡来说已经足够了。当然也有例外,例如2004 年夏季发布的Nvidia GeForce 6800 Ultra 。它的最大功率需求略高于 80 W,超出了插槽所能提供的功率,解决方案采用 AMP 1-480424-0 的形式——更广为人知的名称是 Molex 连接器。根据零件的制造商和所用电缆的质量,这可以提供额外的 130 W 功率。然而,这一添加并不是 PCIe 规范的一部分,因此 PCI-SIG 以两种设计的形式创建了自己的解决方案——一种包含 75 W 的 6 针脚,另一种包含 150 W 的 8 针脚。最近,PCI-SIG 批准了 16 针设计,其中大部分开发来自 Nvidia(目前只有他们使用),它有 600 W 的限制。12VHPWR 连接器并非没有争议,AMD 和英特尔是否会采用该机制还有待观察。随着时代发展,PCIe也在不断迭代,不断完善,更加适应时代的需求。正因为如此,PCI-SIG决定更换赛道,借助光学传输的力量,寻求继续提升速度、降低功耗和延迟。
当然,一切都还在起步阶段,说不定要到PCIe 9.0才能真正拥抱光学传输呢。https://www.anandtech.com/show/19990/pcisig-forms-optical-workgroup-lighting-the-way-to-pcies-futurehttps://www.businesswire.com/news/home/20220621005137/enhttps://www.techspot.com/article/2664-pci-express-explained/在公众号内回复您想搜索的任意内容,如问题关键字、技术名词、bug代码等,就能轻松获得与之相关的专业技术内容反馈。快去试试吧!如果您想经常看到我们的文章,可以进入我们的主页,点击屏幕右上角“三个小点”,点击“设为星标”。