NVIDIA Ampere 架构的结构化稀疏功能
及其在搜索引擎中的应用
深度学习彻底改变了我们分析、理解和处理数据的方式,而且在各个领域的应用中都取得了巨大的成功,其在计算机视觉、自然语言处理、医疗诊断和医疗保健、自动驾驶汽车、推荐系统以及气候和天气建模方面有许多成功案例。
在神经网络模型不断变大的时代,对计算速度的高需求对硬件和软件都形成了巨大的挑战。模型剪枝和低精度推理是非常有效的解决方案。
自 NVIDIA Ampere 架构开始, 随着 A100 Tensor Core GPU 的推出,NVIDIA GPU 提供了可用于加速推理的细粒度结构化稀疏功能。在本文中,我们将介绍此类稀疏模型的训练方法以保持模型精度,包括基本训练方法、渐进式训练方法以及与 int8 量化的结合。我们还将介绍如何利用 Ampere 架构的结构化稀疏功能进行推理。
腾讯机器学习平台部门 (MLPD) 利用了渐进式训练方法,简化了稀疏模型训练并实现了更高的模型精度。借助稀疏功能和量化技术,他们在腾讯的离线服务中实现了 1.3 倍~1.8 倍的加速。
NVIDIA Ampere 架构的结构化稀疏功能
NVIDIA Ampere 和 NVIDIA Hopper 架构 GPU 增加了新的细粒度结构化稀疏功能,该功能主要用于加速推理。此功能是由稀疏 Tensor Core 提供,这些稀疏 Tensor Core 需要 2:4 的稀疏模式。也就是说,以 4 个相邻权重为一组,其中至少有 2 个权重必须为 0,即 50% 的稀疏率。
这种稀疏模式可实现高效的内存访问能力,有效的模型推理加速,并可轻松恢复模型精度。在模型压缩后,存储格式只存储非零值和相应的索引元数据(图 1)。稀疏 Tensor Core 在执行矩阵乘法时仅处理非零值,理论上,计算吞吐量是同等稠密矩阵乘法的 2 倍。
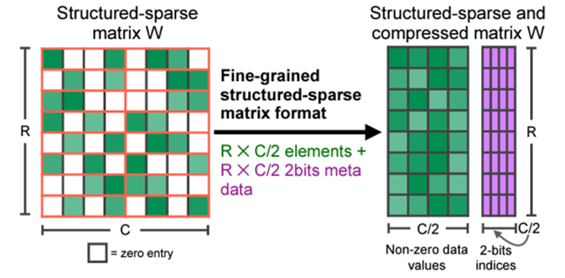
图 1. 2:4 结构化稀疏模式及其压缩格式
(结构化稀疏矩阵具有 2:4 的稀疏模式。在 4 个相邻权重当中,至少有 2 个值为零。在模型压缩后,仅存储非零值和相应的索引元数据。)
结构化稀疏功能主要应用于能够提供 2:4 稀疏权重的全连接层和卷积层。如果提前对这些层的权重做剪枝,则这些层可以使用结构化稀疏功能来进行加速。
训练方法
由于直接对权重做剪枝会降低模型精度,因此在使用结构化稀疏功能的时候,您需要进行训练来恢复模型精度。下面,我们将介绍一些基本训练方法和新的渐进式训练方法。
基本训练方法
基本训练方法可保持模型精度,并且无需任何超参数调优。了解更多技术细节,请参阅论文 Accelerating Sparse Deep Neural Networks(https://arxiv.org/abs/2104.08378)。
基本训练方法易于使用,步骤如下:
训练一个常规稠密模型,不需要稀疏化的特殊处理。
对全连接层和卷积层上的权重以 2:4 的稀疏模式进行剪枝。
按照以下规则重新训练经过剪枝的模型:
a. 将所有权重初始化为第 2 步中的值。
b. 使用与第 1 步相同的优化器和超参数(学习率、调度方法、训练次数等)进行稀疏调优训练。
c. 保持第 2 步中剪枝后的稀疏模式。

图 2. 基本训练方法
(基本训练方法就是使用剪枝后的权重和掩码后的优化器重复原始稠密模型的训练过程。)
对于复杂情况,还有一些进阶的方法。
例如,把稀疏训练应用在多阶段式的稠密模型训练当中。比如对于一些目标检测模型,如果下游任务的数据集足够大,您只需做稀疏调优训练。对于像 BERT-SQuAD 等模型,调优阶段使用的数据集相对较小,您则需要在预训练阶段进行稀疏训练以获得更好的模型精度。
此外,通过在稀疏调优之前插入量化节点,您可以轻松将稀疏调优与 int8 量化调优结合起来。所有这些训练以及调优方法都是一次性的,即最终获得的模型只需要经过一次稀疏训练处理。
渐进式稀疏训练方法
一次性稀疏调优(fine-tuning)可以覆盖大多数任务,并在不损失精度的情况下实现加速。然而,就一些对权重数值变化敏感的困难任务而言,对所有权重做一次性稀疏训练会导致大量信息损失。在小型数据集上只做稀疏化调优可能会很难恢复精度,对于这些任务而言,就需要稀疏预训练(pretraining)。
然而稀疏预训练需要更多数据,而且更加耗时。因此,受到卷积神经网络剪枝方法的启发,我们引入了渐进式稀疏训练方法,在此类任务上仅应用稀疏化调优便可以实现模型的稀疏化,同时不会造成明显的精度损失。了解更多细节,请参阅论文 Learning both Weights and Connections for Efficient Neural Networks (https://arxiv.org/pdf/1506.02626.pdf)。

图 3. 渐进式稀疏训练的概念
(渐进式稀疏训练方法将稀疏率分为几个步骤,以轻松恢复精度。渐进式稀疏训练方法的核心思想是将目标稀疏率进行若干次切分。)

如上述公式和图 4 所示,对于目标稀疏率 S,我们将其分为 N 份,这将有助于在稀疏调优过程中快速恢复信息。根据我们的实验,在相同的调优迭代次数内,使用渐进式稀疏训练相比一次性稀疏训练,可以获得更高的模型精度。
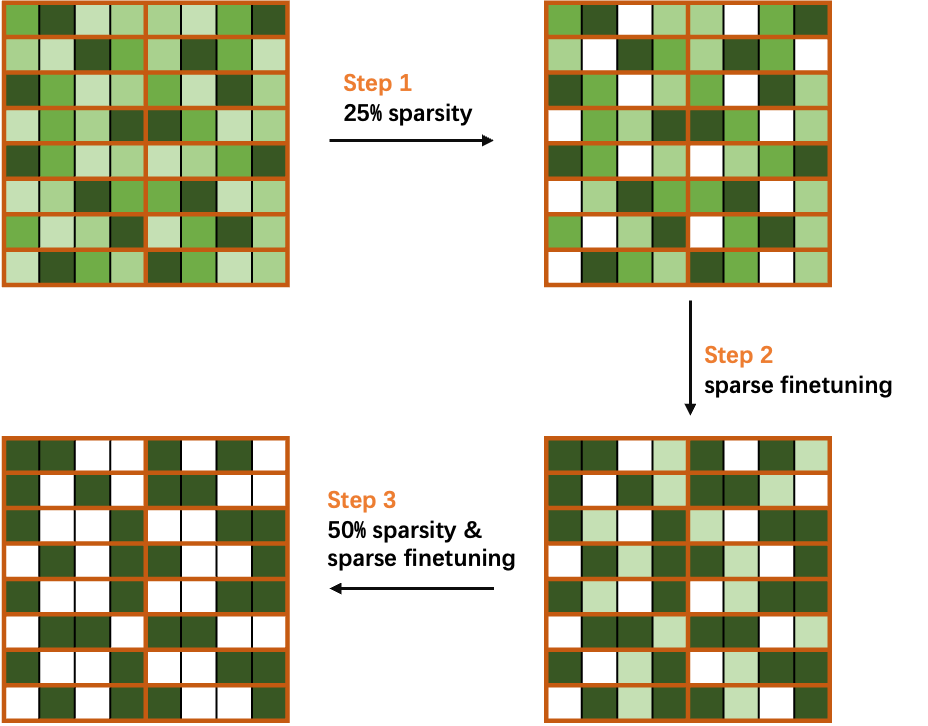
图 4. 渐进式稀疏训练方法 (以 50% 稀疏率的 2:4 结构化稀疏模式为例)
(渐进式稀疏训练方法的示例:计算权重掩码以达到 25% 稀疏率,再进行稀疏调优恢复性能,最后重新计算掩码使之达到 50% 稀疏率并对网络进行调优。)
我们以 50% 稀疏率的 2:4 结构化稀疏为例,将稀疏率分为两份,然后逐步稀疏和调优模型中的权重参数。如图 4 所示,首先计算权重掩码以实现 25% 的稀疏率,然后执行稀疏调优以恢复模型精度。接下来,重新对剩余权重计算权重掩码以达到 50% 的稀疏率,并对网络进行调优,以获得一个精度无损的稀疏模型。
Sparse-QAT:稀疏化与量化、蒸馏相结合
为了获得更轻量的模型,我们进一步将稀疏与量化、蒸馏相结合,即 Sparse-QAT。
量化(PTQ 和 QAT)
下方的公式表示一个通用的量化过程。对于 32 位浮点数值 x,我们使用 Q [x] 表示其具有 K-bits 表示的量化值。

通常情况下,我们首先将原始参数量化到特定范围,并将其近似为整数。然后,可以使用这个量化比例 scale (s) 来恢复原始值。这样就得到了第一种量化方法,即校准,也称为训练后量化(post-training quantization, PTQ)。在校准中,一个关键的因素是要设置一个适当的量化比例(scale)。如果这个比例值过大,量化范围内的数字将不太准确。相反,如果这个比例值过小,会导致大量的数字落在 lmin 到 lmax 的范围之外。因此,为了平衡这两个方面,我们首先获得张量中数值的统计分布,然后设置量化比例以覆盖 99.99% 的数值。许多工作已经证明,这种方法对于在校准过程中找到合适的量化比例非常有帮助。
然而,尽管我们已经为校准设置了一个合理的量化比例,但是对于 8 bit 量化来说,模型精度仍然会显著下降。因此,我们引入量化感知训练(quantization-aware training, QAT),以进一步提高校准后的精度。QAT 的核心思想是以模拟量化的方法来训练模型。
在前向传播过程中,我们将权重量化为 int8,然后将其反量化为浮点数来模拟真实量化。在反向传播过程中,引入 straight through estimation (STE) 的方法来更新模型权重。STE 的核心思想可以用如下公式表示:

由上述公式可知,阈值范围内的值对应的梯度直接反向传播,超出阈值范围的值对应的梯度被裁剪为 0。
知识蒸馏
除了上述方法外,我们还引入了知识蒸馏(knowledge distilation, KD),以进一步确保 Sparse-QAT 模型的精度。我们以原始稠密模型作为教师模型,以量化稀疏模型作为学生模型。在调优过程中,我们采用了 Mini-distillation,这是一种层级别的蒸馏方法。使用 MiniLM,我们只需要使用 Transformer 模型最后一层的输出。引入蒸馏作为辅助工具甚至可以获得比教师模型精度更高的稀疏量化学生模型。了解更多信息,请参阅 MiniLM: Deep Self-Attention Distillation for Task-Agnostic Compression of Pre-Trained Transformers(https://arxiv.org/abs/2002.10957)。
Sparse-QAT 训练流水线
图 5 显示了 Sparse-QAT 的训练流水线。稀疏化、量化、蒸馏以并行的方式执行,最终获得一个稀疏的 int8 量化模型。整个流水线包括如下三条路径:
在稀疏路径中,应用渐进式稀疏化来获取一个稀疏权重张量。
在量化路径中,使用 PTQ 和 QAT 来获取 int8 类型的权重张量。
在知识蒸馏路径中,使用 MiniLM 来进一步保障最终稀疏 int8 模型的精度。

图 5. Sparse-QAT 流水线
(将稀疏、量化和知识蒸馏相结合,以获得最终的稀疏 int8 模型。)
使用 NVIDIA Ampere 架构的
结构化稀疏功能进行推理
在训练好稀疏模型后,您可以使用 NVIDIA TensorRT 和 cuSPARSELt 库来加速基于 NVIDIA Ampere 架构结构化稀疏功能的推理。
使用 NVIDIA TensorRT 进行推理
自 8.0 版本开始,TensorRT 可以支持稀疏卷积,矩阵乘法 (GEMM) 需要用 1x1 的卷积替代来进行稀疏化推理。在 TensorRT 中启用稀疏化推理非常简单。在导入 TensorRT 之前,模型的权重应具有 2:4 的稀疏模式。如果使用 trtexec 构建引擎,只需设置 -sparity=enable 标志即可。如果您正在编写代码或脚本来构建引擎,只需按如下所示设置构建配置:
对于 C++:
config->setFlag(BuilderFlag::kSPARSE_WEIGHTS)对于 Python:
config.set_flag(trt.BuilderFlag.SPARSE_WEIGHTS)使用 NVIDIA cuSPARSELt 库增强 TensorRT
在某些用例中,TensorRT 可能因为输入尺寸不同而无法提供最佳性能。您可以使用 cuSPARSELt 进一步加速这些用例。
解决方案是使用 cuSPARSELt 编写 TensoRT 插件,我们可以为不同的输入尺寸初始化多个描述符以及多个 cuSPARSELt 稀疏矩阵乘法 plan,并根据输入尺寸选择合适的 plan。
假设您在实现 SpmmPluginDynamic 插件,该插件继承自 nvinfer1:: IPluginV2DynamicExt,您可以使用一个私有结构来存储这些 plan。
struct cusparseLtContext {cusparseLtHandle_t handle;std::vectorplans; std::vectormatAs, matBs, matCs; std::vectormatmuls; std::vectoralg_sels; }
TensorRT 插件应实现 configurePlugin方法,该方法会根据输入和输出类型及尺寸设置插件。您需要在这个函数当中初始化 cuSPARSELt 的相关结构。
cuSPARSELt 的输入尺寸有一些限制,应为 4、8 或 16 的倍数,具体取决于数据类型。在本文中,我们将其设置为 16 的倍数。了解该限制条件的相关信息,请查看此文档(https://docs.nvidia.com/cuda/cusparselt/functions.html#cusparseltdensedescriptorinit)。
for (int i = 0; i < size_num; ++i) {m = 16 * (i + 1);int alignment = 16;CHECK_CUSPARSE(cusparseLtStructuredDescriptorInit(&handle, &matBs[i], n, k, k, alignment, type, CUSPARSE_ORDER_ROW,CUSPARSELT_SPARSITY_50_PERCENT))CHECK_CUSPARSE(cusparseLtDenseDescriptorInit(&handle, &matAs[i], m, k, k, alignment, type, CUSPARSE_ORDER_ROW))CHECK_CUSPARSE(cusparseLtDenseDescriptorInit(&handle, &matCs[i], m, n, n, alignment, type, CUSPARSE_ORDER_ROW))CHECK_CUSPARSE(cusparseLtMatmulDescriptorInit(&handle, &matmuls[i], CUSPARSE_OPERATION_NON_TRANSPOSE,CUSPARSE_OPERATION_TRANSPOSE, &matAs[i], &matBs[i], &matCs[i], &matCs[i], compute_type))CHECK_CUSPARSE(cusparseLtMatmulAlgSelectionInit(&handle, &alg_sels[i], &matmuls[i], CUSPARSELT_MATMUL_ALG_DEFAULT))int split_k = 1;CHECK_CUSPARSE(cusparseLtMatmulAlgSetAttribute(&handle, &alg_sels[i], CUSPARSELT_MATMUL_SPLIT_K, &split_k, sizeof(split_k)))int alg_id = 0;CHECK_CUSPARSE(cusparseLtMatmulAlgSetAttribute(&handle, &alg_sels[i], CUSPARSELT_MATMUL_ALG_CONFIG_ID, &alg_id, sizeof(alg_id)))size_t ws{0};CHECK_CUSPARSE(cusparseLtMatmulPlanInit(&handle, &plans[i], &matmuls[i], &alg_sels[i],ws))CHECK_CUSPARSE(cusparseLtMatmulGetWorkspace(&handle, &plans[i], &ws))workspace_size = std::max(workspace_size, ws);}
在 enqueue 函数中,您可以检索适当的 plan 来执行矩阵乘法。
int m = inputDesc->dims.d[0];int idx = (m + 15) / 16 - 1;float alpha = 1.0f;float beta = 0.0f;auto input = static_cast<const float*>(inputs[0]);auto output = static_cast<float*>(outputs[0]);cusparseStatus_t status = cusparseLtMatmul(&handle, &plans[idx], &alpha, input,weight_compressed, &beta, output, output, workSpace, &stream, 1);
搜索引擎中的应用
在本部分中,我们将展示在搜索引擎中应用了稀疏化加速的四个应用案例:
第一是搜索中的相关性预测,旨在评估输入文本和数据库中视频之间的相关性。
第二是查询性能预测,用于文档召回交付策略。
第三是用于召回最相关文本的召回任务。
第四是文生图任务,该任务根据输入的提示词自动生成相应的图片。
搜索相关性案例
我们使用 PNR (Positive Negative Rate,正负率) 或 ACC (accuracy,精度) 标准来评估稀疏化加速在这些应用案例的效果。在相关性案例 1 中,我们运行 Sparse-QAT 获得了一个稀疏 int8 模型,该模型在两个重要的 PNR 评估指标均优于在线 int8 模型。
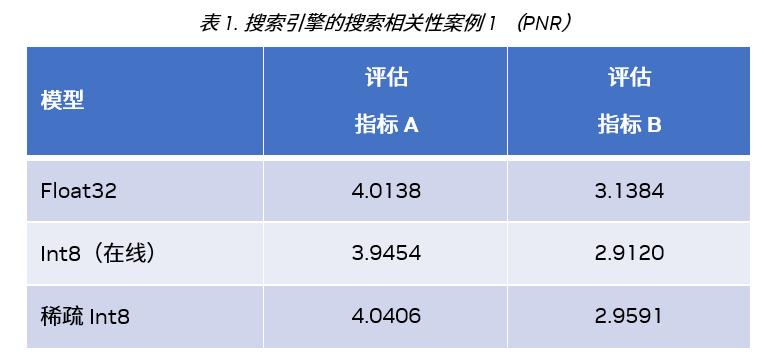
在相关性案例 2 中,稀疏 int8 模型可以获得与 float32 模型接近的 Acc 分数,相比稠密 int8 模型,其获得了 1.4 倍的推理加速。

查询性能预测案例
在这部分,我们展示了查询性能预测 (query performance prediction, QPP) 的四个用例,其效果使用 NDCG(normalized discounted cumulative gain, 标准化折扣累积增益)评估。如表 3 所示,这些稀疏 float16 模型甚至可以获得比原始 float32 模型更高的 NDCG 分数,同时推理速度相比于 float32 模型提高了 4 倍。

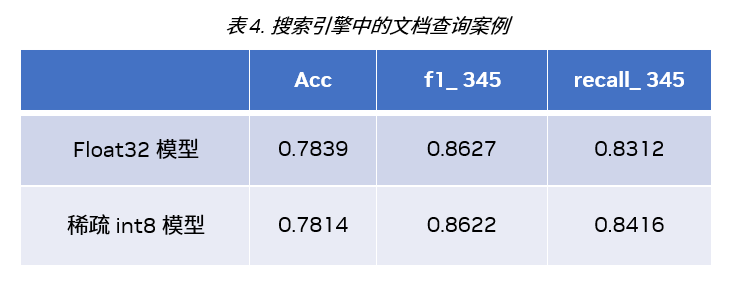
文档查询案例
表 4 显示了搜索引擎中文档查询案例的结果,与稠密 int8 模型相比,使用我们推荐的 Sparse-QAT 训练流水线,稀疏 int8 模型可以实现 1.4 倍的推理加速,准确度损失可忽略不计。
文生图案例
图 6 展示了文生图模型的结果,上面四张图片是用稠密 float32 模型输出,下面四张图片是用稀疏 float16 模型输出。
从结果中您会发现,输入相同的提示,稀疏模型可以输出与稠密模型相当的结果。而且引入模型稀疏化和额外的渐进式稀疏调优使得模型从数据中学习到了更多内容,因此部分稀疏模型的输出结果看起来更为合理。

图 6. 搜索引擎中的文生图案例
(在文生图的案例中,稀疏模型可能会产生比密集模型更合理的结果。)
总结
NVIDIA Ampere 架构中的结构化稀疏功能可以加速许多深度学习工作负载,并且易于结合 TensorRT 和 cuSPARSELt 稀疏加速库一起使用。
如需了解更多信息,请观看 GTC 演讲:NVIDIA Ampere(https://www.nvidia.com/en-us/on-demand/session/gtcspring23-s51299/) 架构的结构化稀疏功能及其在腾讯微信搜索中的应用(https://www.nvidia.com/en-us/on-demand/session/gtcspring23-s51299/)。
下载最新的 TensorRT 和 cuSPARSELt:
TensorRT 下载:
(https://developer.nvidia.cn/zh-cn/tensorrt)
cuSPARSELt 下载:(https://developer.nvidia.com/cusparselt-downloads)。

