1. 大模型时代,国产AI芯片最新进展!算力集群化是必然趋势
原文:https://mp.weixin.qq.com/s/k-InpBMMJTUltuMcB2hKSg
在刚过去的2023世界人工智能大会上,大模型可以说是其中的大亮点之一,华为盘古、商汤日日新、网易伏羲等30多款国产AI大模型集中亮相。与此同时,各类人工智能芯片公司、算力提供商也针对大模型展示了相应的方案。在这次大会上,瀚博半导体、燧原科技、登临科技、天数智芯等纷纷展示了针对大模型的产品方案,呈现出国产AI芯片在大模型领域的进展情况。瀚博半导体成立于2018年12月,是一家自研GPU芯片及解决方案提供商。在此次大会上,瀚博发布了第二代GPU SG100,并推出南禺系列GPU加速卡VG1600、VG1800、VG14,以及LLM大模型AI加速卡VA1L、AIGC大模型一体机、VA12高性能生成式AI加速卡等6款新品。据介绍,瀚博SG100芯片采用7nm先进制程,具备业界领先的渲染性能,同时兼具低延时高吞吐的AI算力和强大的视频处理能力。值得关注的,针对大模型时代算力需求,瀚博本次首发了LLM大模型AI加速卡VA1L,具备200 TOPS INT8/72 TFLOPS FP16算力,并支持ChatGPT、LLaMA、Stable Diffusion等主流AIGC网络模型。与此同时,瀚博此次还推出了AIGC大模型一体机,共使用8张LLM大模型AI加速卡VA1L,支持512GB显存,进而支持1750亿参数的大模型。另外,作为瀚博VA1和VA10的升级版,VA12是一块通用AI加速卡,支持检测、分类、分割、视频增强、语义理解、BERT、Transfomer和视频编解码等应用。燧原科技在此次大会上发布了燧原曜图文生图MaaS平台服务产品。该产品以燧原科技“邃思”系列芯片为算力支撑,由首都在线提供计算服务,燧原曜图MaaS平台服务产品为用户提供面向AIGC时代的高效易用、安全可靠、企业级的文生图服务。燧原科技表示,它具备开箱即用可用、所想即所见、创意无限的文本生成图像能力,通过软硬一体方案降低大规模AIGC应用的工程难度与算力成本,开启AIGC应用规模化落地时代。燧原科技创始人兼CEO赵立东在某论坛上提到,目前燧原已经为大型科研机构部署了千卡规模的AI训练算力集群,并成功落地;而且与腾讯合作,在OCR文字识别、智能交互、智能会议等方面,性能达到了业界同类产品两倍以上,性价比上具有很高优势。此外,在智慧城市方面,燧原完成2022年成都高新区国产化AI视频基础设施平台项目建设。此次大会上,登临科技展示了最新一代创新通用GPU产品Goldwasser II系列以及基于开源大语言模型可交互界面。据了解,Goldwasser II针对基于Transformer和生成式AI 大模型进行专门优化,在性能有大幅提升,已于2022年流片,目前已开始规模化量产和商业客户验证。据现有客户测试结果,二代产品针对基于transformer类型的模型提供3-5倍的性能提升,大幅降低类ChatGPT及生成式AI应用的硬件成本。天数智芯在此次会上也展示了在大模型训练、推理所取得的显著进展,包括图片识别/以图搜图、3D建模、大模型推理等。在大模型领域,天数智芯今年上半年,搭建了40P算力320张天垓100加速卡算力集群,完成智源研究院70亿参数大模型全量训练,天垓100是天数智芯2018年研发的通用AI训练芯片,据天数智芯董事长盖鲁江介绍,目前天垓100这款产品还已经成功跑通了清华智谱 AI 大模型ChatGLM,Meta研发的LLaMA模型。此外,天数智芯正在帮智源研究院跑650亿参数的模型,预计10月份可以跑完。针对于A800芯片在无许可证的情况下将被禁售的话题,盖鲁江谈到,事实上,不管英伟达的产品能不能卖给中国,我们的产品已经能够用起来了。伴随大模型带来的生成式AI突破,人工智能正在进入一个新的时代。算力是人工智能产业创新的基础,大模型的持续创新,驱动算力需求的爆炸式增长。可以说,大模型训练的效率或者是创新的速度,根本上取决于算力的大小。然而,中国的算力已经成为一个越来越稀缺的资源。华为轮值董事长胡厚崑在某论坛上谈到,大模型的研发高度依赖高端AI芯片、集群及生态。高计算性能、高通信带宽和大显存成为大模型训练必不可少的算力底座,单AI芯片进步速度还未跟上大模型对大算力的需求,算力集群化成为不可逆转的发展趋势。在2023世界人工智能大会上,华为宣布昇腾AI集群全面升级,集群规模从最初的4000卡集群扩展至16000卡,拥有更快的训练速度和30天以上的稳定训练周期。胡厚崑表示,华为在各个单点创新的基础上,充分发挥云、计算、存储、网络以及能源的综合优势,进行架构创新,推出了昇腾AI集群,相当于把AI算力中心当成一台超级计算机来设计,使得昇腾AI集群性能更高,并且可靠性更高。据他介绍,昇腾AI集群目前已经可以达到10%以上的大模型训练效率的提升,可以提供10倍以上的系统稳定的提高,支持长期稳定训练。华为昇腾计算业务总裁张迪煊表示,基于昇腾AI,原生孵化和适配了30多个大模型,到目前为止,中国有一半左右的大模型创新,都是由昇腾AI来支持的。除了华为,阿里、腾讯等也打造了较大的算力集群,不过主要还是依靠英伟达的GPU芯片。阿里云表示,其拥有国内最强的智能算力储备,智算集群可支持最大十万卡GPU规模,承载多个万亿参数大模型同时在线训练。腾讯云此前大量采购了英伟达A100/H800芯片,发布新一代HCC高性能计算集群,用于大模型训练、自动驾驶、科学计算等领域。基于新一代集群,腾讯团队在同等数据集下,将万亿参数的AI大模型混元NLP训练由50天缩短到4天。无论是大模型的训练,还是后期的推理部署,对算力的需求都相当大。虽然,当前国产AI芯片与国际领先GPU产品在大模型的训练上有差距,不过可以看到,已经有不少产品,在较大模型的训练上已经取得成绩,后续必然还会有更大的进展。同时,为了满足大模型对大算力的需求,算力集群化将会是未来趋势。2. 大模型加速涌向移动端!ControlNet手机出图只需12秒,高通AI掌门人:LLaMA也只是时间问题
原文:https://mp.weixin.qq.com/s/je05z93KcAIT81NvoyFsuw
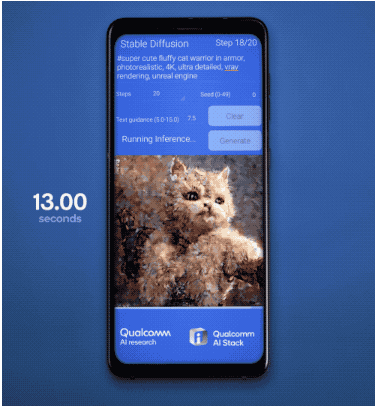
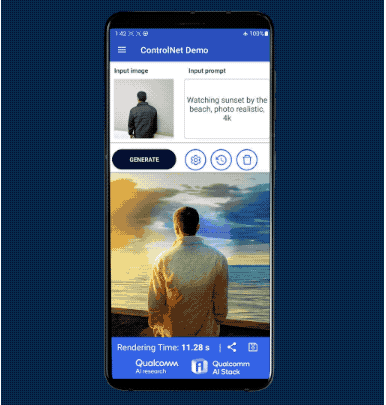
不久前,高通刚在MWC上露了一手纯靠手机跑Stable Diffusion,15秒就能出图的骚操作:3个月后的CVPR 2023上,参数加量到15亿,ControlNet也已在手机端闪亮登场,出图全程仅用了不到12秒:更令人意想不到的速度是,高通技术公司产品管理高级副总裁兼AI负责人Ziad Asghar透露:从技术角度来说,把这些10亿+参数大模型搬进手机,只需要不到一个月的时间。大模型正在迅速重塑人机交互的方式。这会让移动应用的使用场景和使用方式发生翻天覆地的变化。
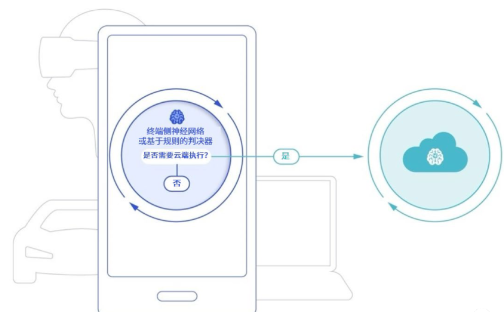
每一个看过《钢铁侠》的人,都很难不羡慕钢铁侠无所不能的助手贾维斯。尽管语音助手早已不是什么新鲜事物,但其现如今的形态多少还是离科幻电影中的智能助手有点差距。这种改变的一种具体的表现,就是all in one。也就是说,通过大模型加持下的数字助手这一个应用入口,人们就可以在手机这样的终端上操控一切:通过自然语言指令,数字助手能自动帮你管理所有手机上的APP,完成办理银行业务、撰写电子邮件、制定旅程并订票等等各种操作。更为关键的是,这样的数字助手还能做到“私人订制”——手机上的个性化数据,与能够理解文字、语音、图像、视频等多模态输入的大语言模型相结合,就能使数字助手更为精准地把握使用者的偏好。并且这样的个性化体验,可以在不牺牲隐私的情况下实现。从技术的角度来说,背后关键,其实就是如今把Stable Diffusion和ControlNet搬进手机的混合AI架构及作为支撑的量化、编译和硬件加速优化等AI技术。混合AI,指的是终端和云端协同工作,在适当场景和时间下分配AI计算的工作负载,以更为高效地利用算力资源。量化、编译和硬件加速优化,则是实现混合AI的关键AI技术,受到高通等终端AI厂商的长期关注和押注。量化,是将更大的模型在精度不变的情况下,从浮点数转变成整数,节省计算时间;又或是在确保模型性能的同时,对其大小进行压缩,使之更容易部署在终端。编译器是AI模型能够以最高性能和最低功耗高效运行的关键。AI编译器将输入的神经网络转化为可以在目标硬件上运行的代码,同时针对时延、性能和功耗进行优化。硬件加速方面,以高通为例,其AI引擎中的关键核心Hexagon处理器,采用专用供电系统,支持微切片推理、INT4精度、Transformer网络加速等,能够在提供更高性能的同时,降低能耗和内存占用。数据显示,Transformer加速大幅提升了生成式AI中充分使用的多头注意力机制的推理速度,在使用MobileBERT的特定用例中能带来4.35倍的AI性能提升。以Stable Diffusion为例,现在,高通的研究人员通过量化、编译和硬件加速优化,已经能够在搭载第二代骁龙8移动平台的手机上,以15秒20步推理的速度运行这一模型,生成出512×512像素的图片。这样一来,整个推理过程可以完全只靠手机实现——开着飞行模式不联网也能做到。这类AI技术的部署并非易事,Ziad表示在相关软件、工具和硬件方面,高通准备了2-3年的时间。但现在,当高通AI模型增效工具包、高通AI软件栈和高通AI引擎等软硬件工具齐备之后,正如前文所言,高通只花了不到一个月的时间,就实现了Stable Diffusion在骁龙平台上的高速运行。也就是说,当基础技术准备就绪,包括大模型在内的生成式AI部署,就会更加容易,原本无法想象的“大模型部署到终端变成数字助手”,现在看来也并非不可能。具体而言,在硬件上混合AI和软件AI技术的“双重”架构下,部署在手机等终端中的大模型,可以在终端侧根据用户习惯不断优化和更新用户画像,从而增强和打造定制化的生成式AI提示。这些提示会以终端侧为中心进行处理,只在必要时向云端分流任务。云不了解你,但终端设备了解你。如果模型可以在设备上进行微调,那它的功能将非常强大。这也是突破大模型幻觉和记忆瓶颈的方式之一。高通可以做到通过一系列技术让大模型在不联网的情况下,借助终端设备数据长时间提供“专属”服务,同时也保护了用户隐私。
值得关注的是,Ziad还透露,在Stable Diffusion和ControlNet之外,基于高通全栈式的软件和硬件能力,研究人员正在将更多生成式AI模型迁移到手机之中,参数量也正在向百亿级别进发。很快,你就会在终端上看到像LLaMA 7B/13B这样的模型。一切工具已经就绪,剩下的只是时间问题。
而且,虽然目前能在终端侧部署的只是“特定”的大模型,但随着技术的不断应用成熟,能部署的大模型数量、模态类型和部署形式,都会飞速进化。Ziad表示:随着更多更好的AI算法被开源出来,我们也能更快地沿用这套软硬件技术将它们部署到终端侧,这其中就包括文生视频等各种多模态AI。
这样来看,未来用户将自己想用的大模型迁移到手机端,成为超级助手的核心,也并非不可能实现。早在生成式AI、大模型技术爆发之前,在移动互联网时代,AI需求已经呈现出向边缘设备转移的趋势。正如Ziad的观点“终端侧AI是AI的未来”一样,随着以大模型为代表的生成式AI浪潮加速改变人机交互方式,更多终端侧如笔记本电脑、AR/VR、汽车和物联网终端等,也都会因为这场变革迎来重塑,甚至反过来加速AI规模化落地。在这个过程中,不仅硬件会诞生新的衡量标准,软件上以大模型为核心的超级AI应用,更是有可能出现。首先是硬件上,由于终端侧算力会成为延展生成式AI落地应用不可或缺的一部分,对于移动端芯片本身来说,AI处理能力也会日益凸显,甚至成为新的设计基准之一。随着大模型变得更受欢迎、更多应用不断接入其能力,更多潜在的用户也会意识到大模型具备的优势,从而导致这类技术使用次数的迅猛上升。随着AI计算需求的增加,云端算力必然无法承载如此庞大的计算量,从而导致单次查询成本急剧增加。要解决这一问题,就应当让更多算力需求“外溢”到终端,依靠终端算力来缓解这一问题。
为了让更多大模型在终端就能处理甚至运行,从而降低调用成本,必然需要在确保用户体验的同时,提升移动端芯片处理AI的能力。长此以往,AI处理能力会成为衡量硬件能力的benchmark,如同过去手机芯片比拼通用算力和ISP影像能力一样,成为整个移动端芯片的新“赛点”。等多的内容,如果感兴趣,可以直接点击原文,您会收获更多的知识。3. 英特尔AI芯片中国定制版发布!打的就是英伟达A100
原文:https://mp.weixin.qq.com/s/5njVFAcZnMP0rEb5VZcLhA
英特至强CPU,运行扩散模型Stable Diffusion只需5秒就能出图。而在这两天,专门搭载在该CPU上使用的AI加速器更是新鲜出炉。它叫Gaudi2,面向中国市场发布,用于加速AI训练及推理,有了它,大规模部署AI便多了一种新选择。性能上,它在MLPerf最新报告中的多种训练和推理基准测试中都直接超越了英伟达A100,并提供了约2倍的性价比。至于H100,它虽然还不能敌过,但若拉上成本,则也能“扳回一局”。Gaudi2深度学习加速器暨Gaudi2夹层卡HL-225B,以第一代Gaudi高性能架构为基础,加速高性能大语言模型运行。(ps. Gaudi1代处理器诞生于2019年,其背后公司来自以色列,当年年底被英特尔以20亿美元收购,如今成为英特尔“叫板”英伟达的重要底气。)Gaudi2采用7nm制程工艺,具备24个可编程Tensor处理器核心(TPCs),支持面向AI的各类高级数据类型:FP8、BF16、FP16、TF32和FP32。它配备21个100 Gbps(RoCEv2)以太网接口,可通过直接路由实现Gaudi处理器间通信(相比原版少了3个,但英特尔公司执行副总裁Sandra Rivera介绍,这对整体性能影响基本不大)。同时,它还能做到2.4TB/秒的总内存带宽,先进的HBM控制器则针对随机访问和线性访问进行了优化,在各种访问模式下都可以提供这一保证。此外,48MB片上SRAM和集成多媒体处理引擎亦是标配。就在上个月公布的MLCommons® MLPerf®基准测试中,Gaudi2在1750亿参数的GPT-3模型训练上表现出色,使用384个加速器上耗时311分钟就完成了训练。虽然相比之下,英伟达只需61分钟便可,但这样的成绩需要512个H100——由于Gaudi2的成本要远低于H100,所以要论性价比,Sandra Rivera表示,Gaudi2是更具诱惑力的选择。与此同时,Gaudi2在基于8个和64个加速器助力的BERT、8个加速器助力的ResNet-50和Unet3D训练结果上,全部优于A100。此外,Gaudi2也可为大规模的多模态和语言模型提供出色的推理性能。在最近的Hugging Face评估中,其在大规模推理方面的表现,包括在运行Stable Diffusion、70亿以及1760亿参数BLOOMZ模型时,在行业内均保持领先。能耗方面,训练计算机视觉模型时,Gaudi2的每瓦性能是A100的2倍,推理176B参数的BLOOMZ时,功耗则可降低40%。——不仅性能和功耗强大,英特尔还提供了配套的成熟软件支持:SynapseAI。它可以方便开发者轻松构建模型,或将当前基于GPU的模型业务和系统迁移到基于全新Gaudi2服务器。同时,SynapseAI集成了对TensorFlow和PyTorch框架的支持,提供众多流行的计算机视觉和自然语言参考模型,可以满足深度学习开发者的多样化需求。另外,说到Gaudi2服务器,现在,英特尔已与浪潮信息合作,打造并发售基于Gaudi2深度学习加速器的浪潮信息AI服务器NF5698G7。该服务器集成了8颗Gaudi2加速卡HL-225B,还包含双路第四代英特尔至强可扩展处理器,进一步帮助大家高效部署大模型。最后,值得一提的是,在发布会后的交流环节中,当被问及英特尔是否有一个预期,能占领多少AI加速芯片的市场时,Sandra Rivera表示:国内AI产品需求非常大,产品完全不够用。因此市场就在那里,在这种情况下我们不用特别设什么份额的目标,就把最好的产品带出来,满足市场需求,帮助大家创新,这就是我们想要做的事情。
而据量子位现场获悉,明年,能够进一步缩小差距甚至超越英伟达H100的Gaudi3就将问世。与此同时,2025年之时,英特尔还将整合既有的GPU Max产品线和Gaudi系列,取两者之长,推出更加完整的下一代GPU产品。而在这之中,英特尔将对大家最为关心的可持续软件生态做大笔投入。4. 李飞飞「具身智能」新成果!机器人接入大模型直接听懂人话,0预训练就能完成复杂指令
原文:https://mp.weixin.qq.com/s/XleXS_5shzZNiOSxUFZfgQ
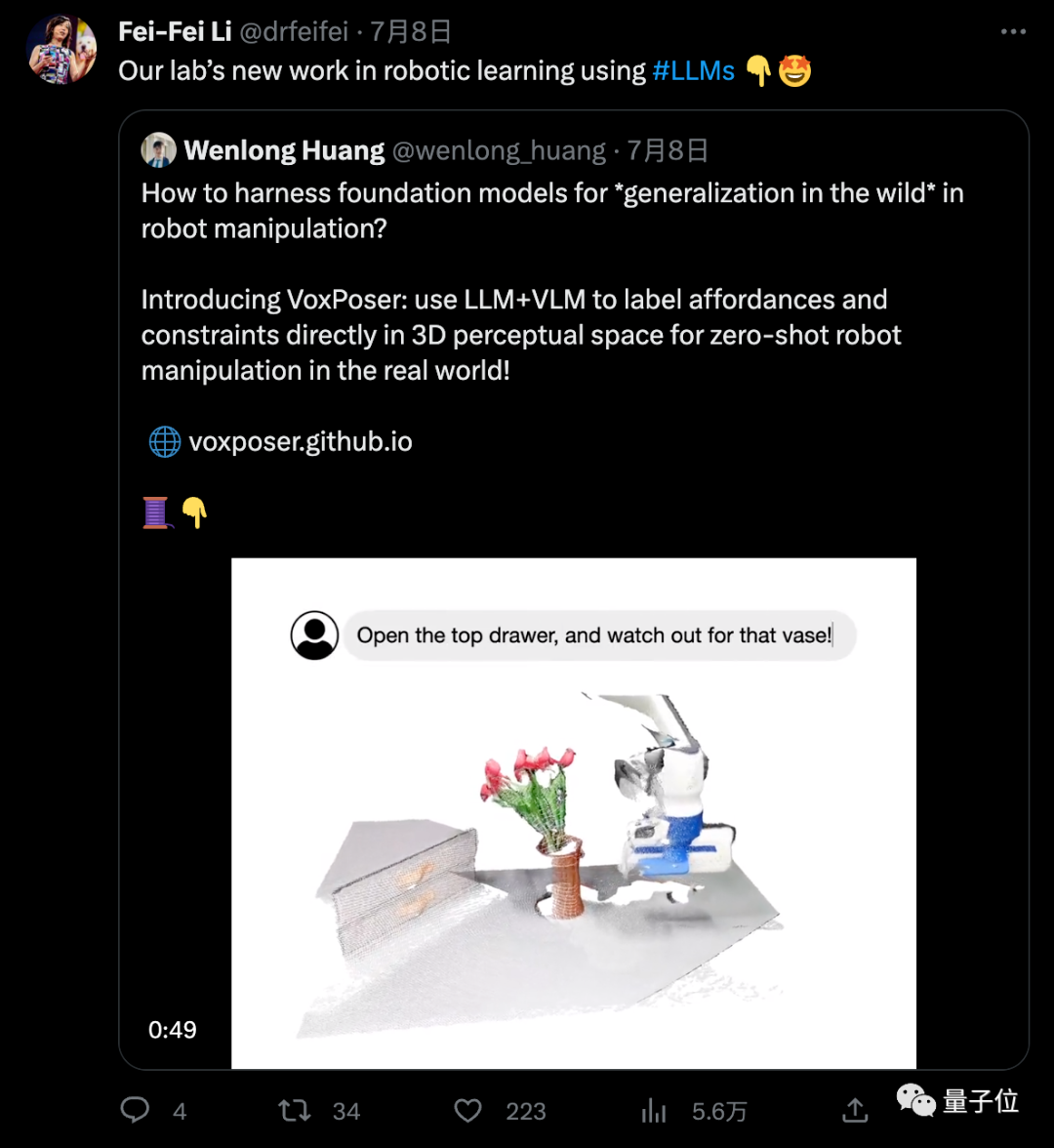
大模型接入机器人,把复杂指令转化成具体行动规划,无需额外数据和训练。从此,人类可以很随意地用自然语言给机器人下达指令,如:大语言模型+视觉语言模型就能从3D空间中分析出目标和需要绕过的障碍,帮助机器人做行动规划。然后重点来了, 真实世界中的机器人在未经“培训”的情况下,就能直接执行这个任务。新方法实现了零样本的日常操作任务轨迹合成,也就是机器人从没见过的任务也能一次执行,连给他做个示范都不需要。可操作的物体也是开放的,不用事先划定范围,开瓶子、按开关、拔充电线都能完成。目前项目主页和论文都已上线,代码即将推出,并且已经引起学术界广泛兴趣。大约一年前,李飞飞在美国文理学会会刊上撰文,指出计算机视觉发展的三个方向:- 场景理解(Scene Understanding)
李飞飞认为,具身智能不单指人形机器人,任何能在空间中移动的有形智能机器都是人工智能的一种形式。正如ImageNet旨在表示广泛且多样化的现实世界图像一样,具身智能研究也需要解决复杂多样的人类任务,从叠衣服到探索新城市。遵循指令执行这些任务需要视觉,但需要的不仅仅是视觉,也需要视觉推理理解场景中的三维关系。最后机器还要做到理解场景中的人,包括人类意图和社会关系。比如看到一个人打开冰箱能判断出他饿了,或者看到一个小孩坐在大人腿上能判断出他们是亲子关系。5. 国产7nm全功能GPU上海发布!还有大模型加速卡、AIGC大模型一体机等6款新品
原文:https://mp.weixin.qq.com/s/MhFOeWOowpk_j0CB9zcFQQ
7月6日下午,瀚博半导体在2023世界人工智能大会上正式发布第二代GPU SG 100。一并推出的还有南禺系列GPU加速卡 VG1600、VG1800、VG14以及LLM大模型AI加速卡VA1L、AIGC大模型一体机、VA12高性能生成式AI加速卡等6款新品,为AI大模型、图形渲染和高质量内容生产提供完整解决方案。本次发布会以“智渲同芯,共生未来”为主题,瀚博半导体创始人兼CTO张磊在发布会上发表了《从像素到杰作:国产芯片加速AI大模型和元宇宙》主题演讲,吸引众多行业伙伴、知名媒体以及投资机构到场。张磊以AGI时代的算力需求与挑战为引,全面展示了瀚博针对人工智能与元宇宙行业的最新产品研发成果,此次瀚博半导体新品发布会赋能大模型创新应用,联合上下游企业共同打造国产大模型生态圈,以全新姿态把握时代机遇,开启人工智能+元宇宙的瀚博算力序章。第二代GPU SG100: 集渲染、AI、视频于一体的7nm全功能GPU瀚博此次重磅推出了集成高性能渲染、超低延时AI和强视频处理能力的7nm全功能GPU芯片产品SG100。瀚博SG100芯片采用7nm先进制程,具备业界领先的渲染性能,同时兼具低延时高吞吐的AI算力和强大的视频处理能力。搭载瀚博自研GPU软件栈,业界一流的SR-IOV硬件虚拟化技术,支持Windows/Linux下的DirectX 11、OpenGL、Vulkan等API接口,支持H.264、H.265、AV1等多种视频编解码格式,可广泛支持数字孪生、数字人、云桌面、云手机、云游戏、云渲染、工业软件等多领域应用,助力打造元宇宙产业算力底座。演讲中,张磊也通过实际案例展示了瀚博产品基于Windows/Linux下的渲染实例效果、教育云电脑、工业软件、多路高画质云游戏以及超写实数字人等应用场景,为现场观众直观展示了瀚博第二代全功能GPU SG100的强大算力。发布会上,瀚博也针对不同的应用场景推出了三款南禺系列全新GPU加速卡产品。三款新品分别针对云游戏、云桌面与工作站提供相应算力支持,也为高质量内容生产提供了高效的算力支撑。此次最新发布的南禺系列GPU加速卡 VG1600完美结合渲染与视频处理,打造出沉浸式云游戏体验,为玩家创造更真实的游玩场景。其次,VG1800 也为远程工作带来全面升级,可流畅支持各类办公软件、教育APP和工业设计软件等,提供出色的云桌面用户体验。更有支持Windows 操作系统下DirectX与 OpenGL等API接口的国产工作站显卡VG14,能够胜任多任务处理、大型专业软件运行等多元办公场景。LLM大模型AI加速卡及一体机方案:大模型应用最低门槛今年,以大模型等应用为典型代表打开了人工智能的广阔前景。未来,具有并行计算能力的GPU芯片作为大模型计算的“大脑”将为大模型生成学习提供源源不断的算力支撑。针对大模型时代算力需求,瀚博本次首发了LLM大模型AI加速卡VA1L,具备200 TOPS INT8/72 TFLOPS FP16算力,并支持ChatGPT、LLaMA、Stable Diffusion等主流AIGC网络模型。与此同时,瀚博更重磅推出AIGC大模型一体机,共使用8张LLM大模型AI加速卡VA1L,支持512GB显存,进而支持1750亿参数的大模型。本次大模型一体机解决方案拥有业内最低门槛,也是目前针对AI大语言模型最低价格的大模型一体机方案。此外,新品还提供两个特殊选配:具有对话功能的2卡单独运行语音转文字或者文字转语音版本以及使用SG 100做云端实时渲染的2U 11卡版本,提供大模型会话数字人实时渲染,使大模型推理更高效,服务于大模型行业发展。发布会上,张磊也为观众展示了AI大模型“智能对话”、“文生图”等应用示例,生动展现了瀚博大模型新品支撑的广泛应用场景。针对生成式AI应用和其他通用AI应用,瀚博本次也推出全新高性能智能加速卡VA12。作为250W板卡,VA12有512 TOPS的INT 8的算力和160 TFLOPS的FP16算力,更高效支持StableDiffusion。与此同时,作为瀚博VA1和VA10的升级版,VA12也是一块通用AI加速卡,支持检测、分类、分割、视频增强、语义理解、BERT、Transfomer和视频编解码等应用。VA 12的发布将为未来AIGC平台的发展构筑算力底座,让未来的数字内容生产拥有更高效的计算能力与更多元的可能性。6. 人工智能在日常生活中的十大应用
原文:https://mp.weixin.qq.com/s/HqVbMOBwpIaHt1eQz3C2Cg
7月6日下午,瀚博半导体在2023世界人工智能大会上正式发布第二代GPU SG 100。一并推出的还有南禺系列GPU加速卡 VG1600、VG1800、VG14以及LLM大模型AI加速卡VA1L、AIGC大模型一体机、VA12高性能生成式AI加速卡等6款新品,为AI大模型、图形渲染和高质量内容生产提供完整解决方案。本次发布会以“智渲同芯,共生未来”为主题,瀚博半导体创始人兼CTO张磊在发布会上发表了《从像素到杰作:国产芯片加速AI大模型和元宇宙》主题演讲,吸引众多行业伙伴、知名媒体以及投资机构到场。今年,人工智能在公众使用方面取得了惊人的新进展。一张人工智能生成的图像甚至在与人类艺术家竞争时获得了艺术奖(https://www.nytimes.com/2022/09/02/technology/ai-artificial-intelligence-artists.html)。它被用来帮助筛查癌症,打击偷猎濒危大象的行为,并能够从太空探测考古遗址。但人工智能并不局限于科学前沿。事实上,人工智能无处不在。“人工智能技术渗透到了我们生活的方方面面,这几乎是潜移默化的,”IEEE高级会员Guangjie Han说,“它为我们的设备提供动力,同时通过分析我们在这些设备上产生的数据而不断进行改进。”1. 智能助理:智能手机或智能家居设备上的语音助手由人工智能支持。有时,请求可以在手机上处理。有时请求会被发送到云服务器进行处理。2. 智能家居设备:通过人工智能,智能恒温器可以自动调整家中的暖通空调系统,而摄像头可以提醒消费者有人、车或包裹到达。3. 电子商务:人工智能在网上购物中无处不在。值得注意的应用程序扩展包括了产品建议,可以帮助管理销售和退货的聊天机器人,以及定制的购物体验。4. 零售业的趋势识别:在线商店不仅仅是在你购物时提供推荐,他们还积极使用商店和竞争对手的销售数据来识别趋势。通过使用人工智能进行设计和制造,以便满足公众的需求。5. 内容推荐:人工智能支持的内容推荐引擎使用产品目录和消费者数据进行培训,以提供更个性化的推荐。6. 导航和旅行:纸质地图已经成为过去。人工智能生成的路线可以优化旅行时间或减少油耗。7. 药物研究:通过识别其潜在危险和作用机制,人工智能系统能够帮助寻找新的药物应用。这项技术帮助建立了几个药物发现平台,使企业能够重复使用当前的药物和生物活性物质进行研究。8. 面部识别解锁手机:看向手机即可解锁。这些功能得到了人工智能的支持,它利用相机和传感器技术来准确测量你的面部。9. 金融欺诈检测:人工智能非常擅长模式分析,事实证明,我们大多数人使用信用卡的方式相当可预测。这使得它非常适合确定哪些信用卡交易可能是非法的。如果你曾经接到银行的电话,询问你是否进行了交易,那很可能是人工智能算法的结果。10. 自动更正:人工智能系统使用机器学习、深度学习和自然语言处理来识别文字处理器、短信应用程序和其他文本媒体中的错误语言使用,并提供更正和建议。在可预见的未来,人工智能系统的大部分工作将集中在构建更大、更少偏见的数据集上,用于训练模型。“这些系统的训练在很大程度上取决于人工智能模型训练的数据,”IEEE会士(Fellow)Karen Panetta说,“它可以体验的场景越多,效果就越好,但这需要精心策划、注释的数据集。这些数据集必须多样化,以减少偏差,并动态更新,以反映新的条件和现实世界应用中出现的场景。”同时,这也在提醒人们,在某些改变生活的环境中不要过度依赖人工智能系统。Panetta说:“人工智能需要被解释。例如,许多公司正在销售评估人们表现并确定薪酬的产品。然而,这些系统做出的决定无法解释人工智能是如何决定结果的。人工智能不应该影响某人的生计。”———————End———————
RT-Thread线下入门培训
7月 - 南京
1.免费 2.动手实验+理论 3.主办方免费提供开发板 4.自行携带电脑,及插线板用于笔记本电脑充电 5.参与者需要有C语言、单片机(ARM Cortex-M核)基础,请提前安装好RT-Thread Studio 开发环境
报名通道

立即扫码报名
(报名成功即可参加)

👇 点击阅读原文进入官网