
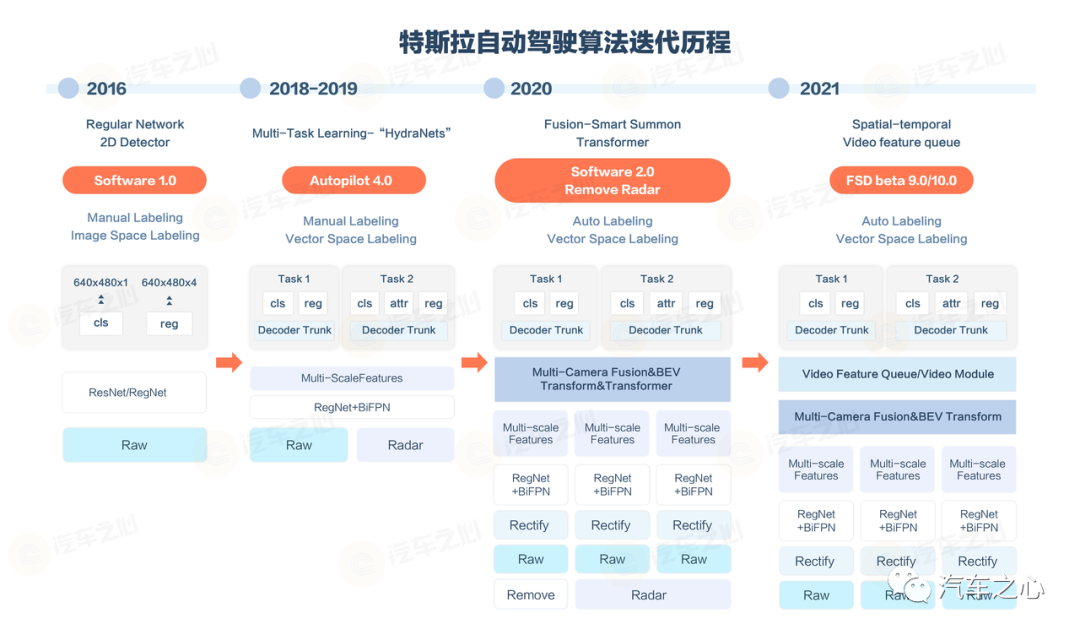
主干网络 backbone 为特征提取网络,主要用于识别图像中的多个对象;
neck 则主要负责提取更为精细的特征;
而在经过特征提取之后,检测头 head 则为提供了输入的特征图表示,比如检测对象,实例分割等。
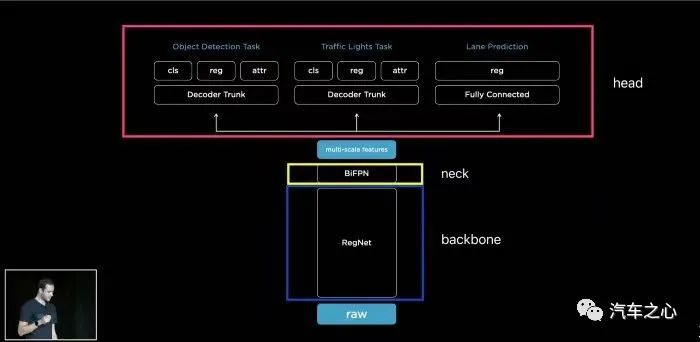
一是将不同视角在 BEV 下统一表达是很自然的描述,有利于后续规划控制模块任务;
二是 BEV 视角解决了图像视角下的尺度和遮挡问题。
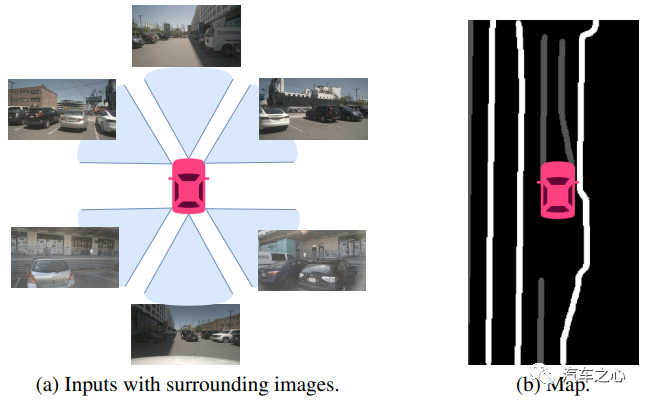

跨摄像头融合和多模融合更易实现。大多数行业公司采用的是异构传感器(摄像头、激光雷达、毫米波雷达等)的感知方案。而 BEV 空间能够统一传感器数据维度,更容易实现特征融合。
时序融合更易实现。
可「脑补」出遮挡区域的目标。
更方便端到端做优化。

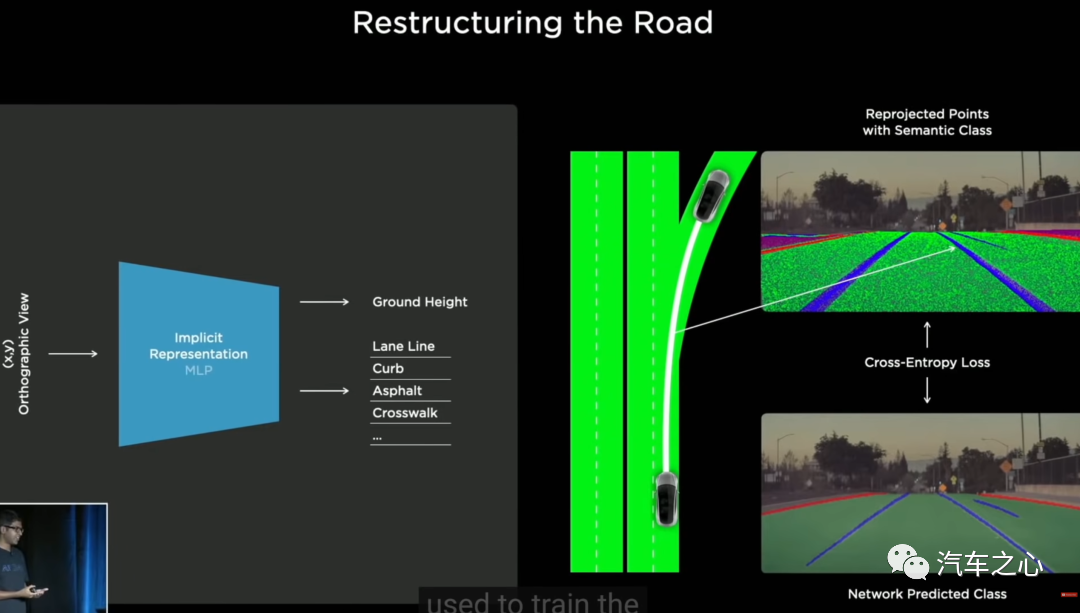



计算效率不高,HEAD 部分不够用?开发了九头蛇网络结构;
小模型无法实行并行计算,泛化能力不强,BEV 无法精确实现?引入大模型 Transfomer,逆向开发;
现有芯片的构成冗余,不适配纯视觉路线需求,且成本高?自研 FSD 芯片;
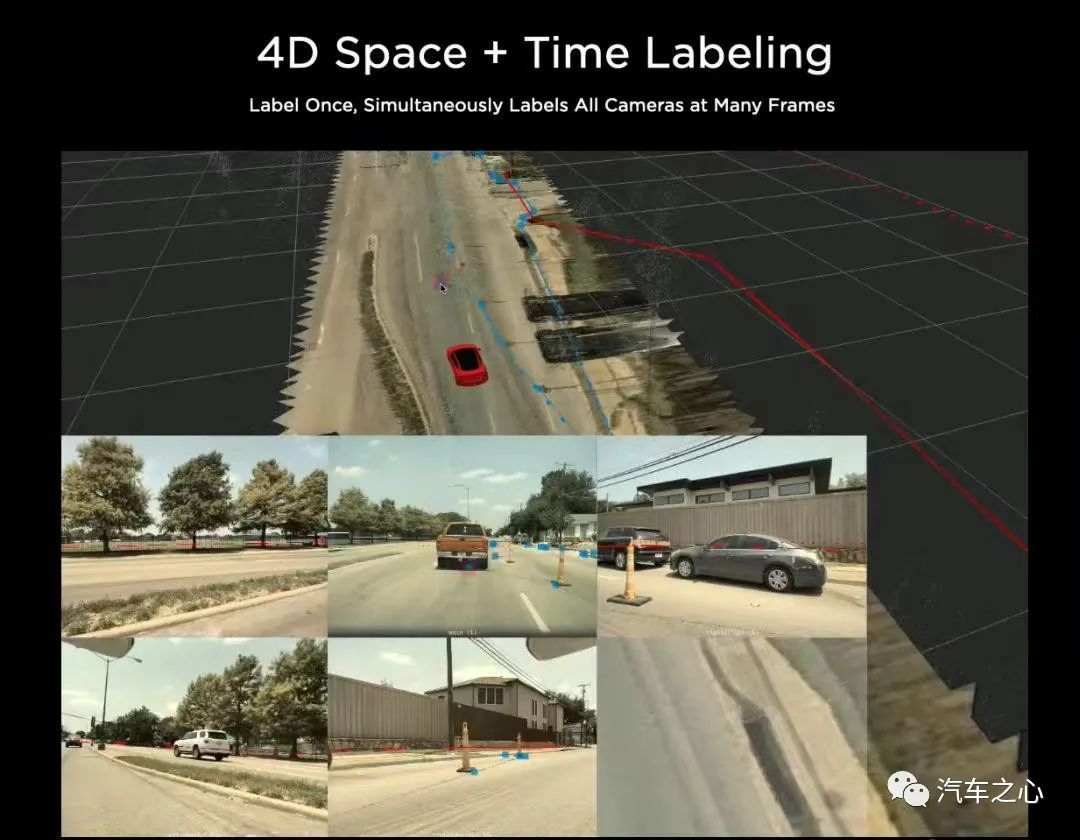
数据标注成本高,数据训练量不足?建设超算中心 DOJO,实现数据自我标注,同时虚拟场景训练算法,提高自动驾驶能力等等。
需要图商采集更新,无法实时更新;
制图资质受到严格管理,信息采集面临一定法规风险;
成本昂贵高昂。
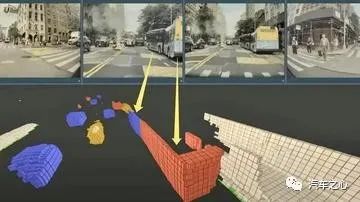
引入 BEV 架构,实现异构传感器的融合,生成活地图;
具备超算中心,或离线服务器的大模型,能够实现自动标注及仿真训练;


END
