由于太理论太低层,学得不咋样,考完试后就完全忘记了。
但我万万没想到,当时刚工作,我居然就要用到cache的知识。。
前言
事情其实是这样的,当时领导交给我一个perf硬件性能监视的任务,在使用perf的过程中,输入命令perf list,我看到了以下信息:
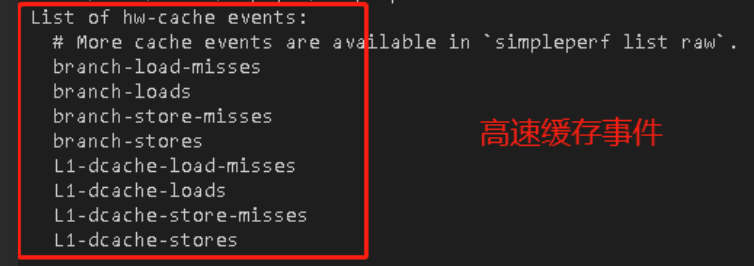
我的任务就要让这些cache事件能够正常计数,但关键是,我根本不知道这些misses、loads是什么意思。
我只知道它们都是cache,但这几个名字十分类似,又有什么区别?
出于此,当时我觉得我有必要去学一下cache的知识了,我对cache、性能等的了解也因此开始。
下面是我当时学习cache总结的一些基本概念知识,对于不了解底层或者不了解cache的人,相信都会有帮助。
基本上是以问答的方式引导大家,因为我曾经也是一堆疑问走过来的。
1、什么是Cache?
首先我们要知道,cpu访问内存,不是直接访问的,而是需要先经过Cache,为什么呢?
原因:cpu内的数据是存储在寄存器中,访问寄存器的速度很快,但是寄存器容量小。而内存容量大,但是速度慢。为了解决cpu和内存之间速度和容量的问题,引入了高速缓存Cache。
Cache位于CPU和主存之间,CPU访问主存时,首先去访问Cache,看Cache中有没有这个数据,如果有,就从Cache中拿数据返回给CPU;如果Cache里没有数据,再去访问主存。
2、多级Cache存储结构
通常来说,Cache不止一个,而是有多个,即多级Cache,为什么呢?
原因:cpu访问cache速度也是很快的。但是我们做不到速度和容量完全兼容,如果cpu访问cache的速度跟cpu访问寄存器的速度差不多,那么就意味着这个cache速度很快,但是容量很小,这么小的cache容量还不足够满足我们的需求,因此引入了多级Cache。
多级Cache将Cache分成多个级别L1、L2、L3等。
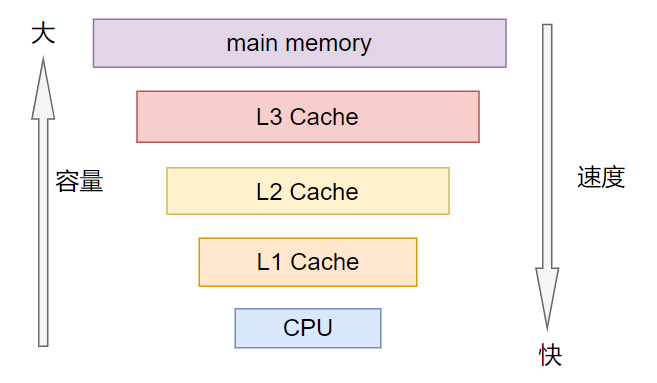
L1最靠近CPU,L3最靠近主存。
通常L1又分为instruction cache(ICache)和data cache(DCache),并且L1 cache是cpu私有的,每个cpu都有一个L1 cache。
3、“命中”和“缺失”是什么意思?
命中:CPU要访问的数据在cache中有缓存,称为“命中”,即cache hit
缺失:CPU要访问的数据在cache中没有缓存,称为“缺失”,即cache miss
4、什么是cache line?
cache line:高速缓存行,将cache平均分成相等的很多块,每一个块大小称之为cache line。
cache line也是cache和主存之间数据传输的最小单位.
当CPU试图load一个字节数据的时候,如果cache缺失,那么cache控制器会从主存中一次性的load cache line大小的数据到cache中。例如,cache line大小是8字节。CPU即使读取一个byte,在cache缺失后,cache会从主存中load 8字节填充整个cache line。
CPU访问cache时的地址编码,通常由tag、index和offset三部分组成:
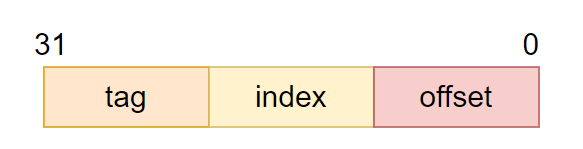
tag(标记域):用于判断cache line缓存的数据的地址是否和处理器寻址地址一致。
- index(索引域):用于索引和查找地址在高速缓存中的哪一行
offset(偏移量):高速缓存行中的偏移量。可以按字或字节来寻址高速缓存行的内容
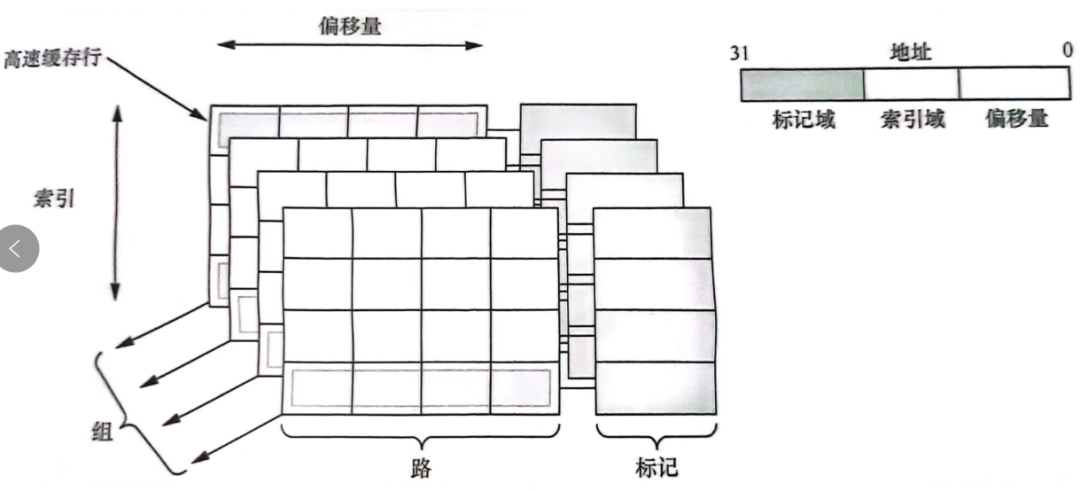
cache line和tag、index、offset等的关系如图:
5、cache访问的是虚拟地址还是物理地址?
我们知道,CPU访问内存不是直接访问的,而是CPU发出一个虚拟地址,然后经过MMU转换为物理地址后,根据物理地址从内存取数据。那么cache访问的是虚拟地址还是物理地址?
答:不一定。既可以是虚拟地址,也可以是物理地址,也可以是虚拟地址和物理地址的组合。
因为cache在硬件设计上有多种组织方式:
VIVT虚拟高速缓存:虚拟地址的index,虚拟地址的tag。PIPT物理高速缓存:物理地址的index,物理地址的tag。VIPT物理标记的虚拟高速缓存:虚拟地址的index,物理地址的tag。
6、什么是歧义和别名问题?
歧义(homonyms):相同的虚拟地址对应不同的物理地址
别名(alias):多个虚拟地址映射到了相同的物理地址(多个虚拟地址被称为别名)。
例如上述VIVT方式就会存在别名问题,那VIVT、PIPT和VIPT那个方式更好呢?
PIPT其实是比较理想的,因为index和tag都使用了物理地址,软件层面不需要任何维护就能避免歧义和别名问题。
VIPT的tag使用了物理地址,所以不存在歧义问题,但index是虚拟地址,所以可能也存在别名问题。
而VIVT的方式,歧义和别名问题都存在。
实际上,现在硬件中使用的基本是PIPT或者VIPT。VIVT问题太多,已经成为了历史了,不会有人用。另外PIVT的方式是不存在的,因为它只有缺点没有优点,不仅速度慢,歧义和别名问题也都存在。
cache的组织方式,以及歧义和别名问题,是比较大块的内容。这里只需要知道cache访问的地址既可以是虚拟地址,也可以是物理地址,也可以是虚拟地址和物理地址的组合。并且不同的组织方式会有歧义和别名问题。
7、Cache分配策略?
指的是发生cache miss时,cache如何分配。
读分配:当CPU读数据时,发生cache缺失,这种情况下都会分配一个cache line缓存从主存读取的数据。默认情况下,cache都支持读分配。
写分配:当CPU写数据发生cache缺失时,才会考虑写分配策略。当我们不支持写分配的情况下,写指令只会更新主存数据,然后就结束了。当支持写分配的时候,我们首先从主存中加载数据到cache line中(相当于先做个读分配动作),然后会更新cache line中的数据。
8、Cache更新策略?
指的是cache命中时,写操作应该如何更新数据。
写直通:当CPU执行store指令并在cache命中时,我们更新cache中的数据并且更新主存中的数据。cache和主存的数据始终保持一致。
写回:当CPU执行store指令并在cache命中时,我们只更新cache中的数据。并且每个cache line中会有一个bit位记录数据是否被修改过,称之为dirty bit。我们会将dirty bit置位。主存中的数据只会在cache line被替换或者显示的clean操作时更新。因此,主存中的数据可能是未修改的数据,而修改的数据躺在cache中。cache和主存的数据可能不一致。
最后
关于cache的内容,还有TLB、MESI、内存一致性模型等等,是一个需要沉淀和总结才能真正掌握的东西。
但可能很多人都用不上,只有涉及到性能问题,当你需要提高cache命中率时,才知道这些知识的重要性。
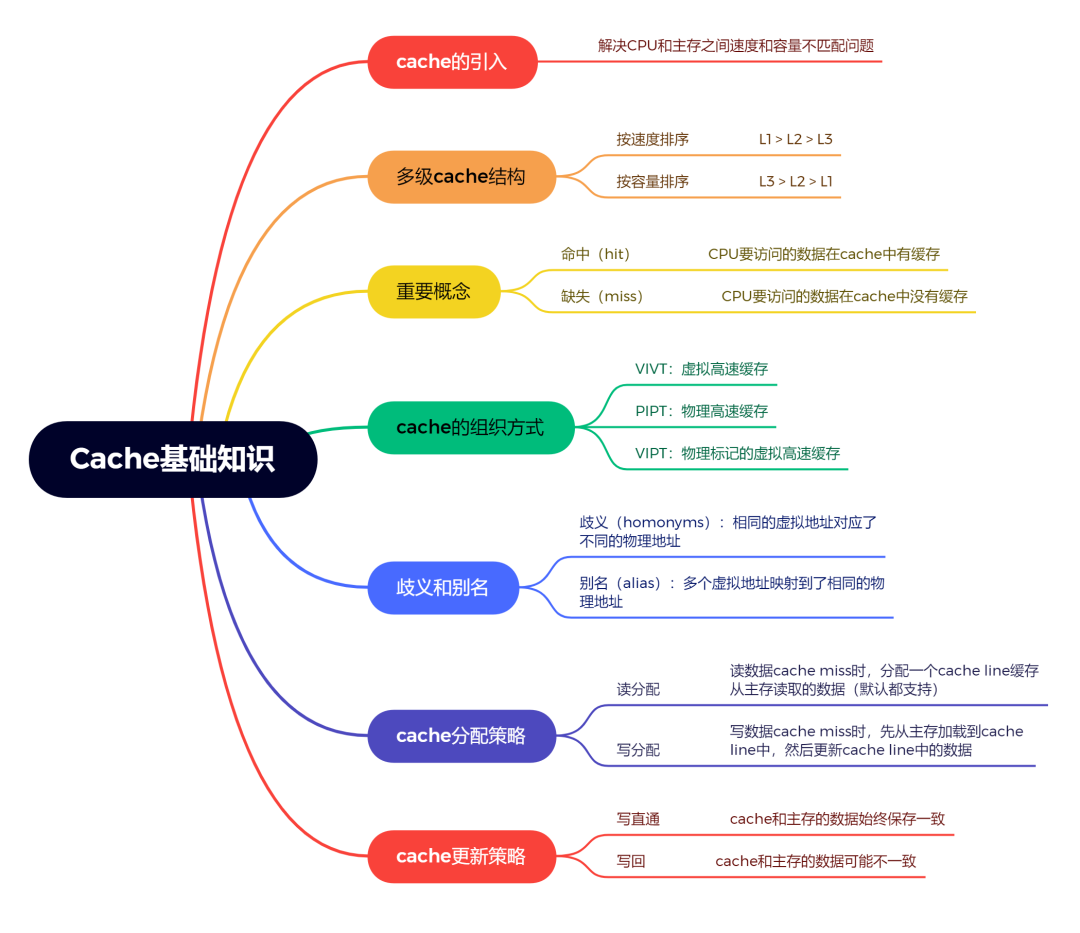
关于本文讲的知识,总结了一份cache基础知识的思维导图:

这是一口君的新书,感谢大家支持!
关注,回复【1024】海量Linux资料赠送
精彩文章合集
文章推荐


