文章来源:https://zhuanlan.zhihu.com/p/402567148
本文系转载,仅供分享交流之用,不代表平台观点。
Andrej Karpathy博士说,模型需要数据来驱动,模型决定上限,而数据帮助模型到达这个上限!
有的小伙伴可能会问,不就是标个数据么,有什么好讲的???找几个小学生100块一天,点点鼠标也能干!(小学生OS:我不干,我要忙着上王者!)
Attention!都已经2021年了,L4的自动驾驶都已经开始讨论量产了,中国的空间站都已经上天了,数据标注当然也不再是点点鼠标就OK的了!!
数据标注里面有什么明堂,容我慢慢讲来。做深度学习和计算机视觉的同学可能比较熟悉ImageNet,MS COCO,Cityscapes等著名的公共数据集,这些数据集主要面向于2D图像上的感知任务,也是直接在2D图像上直接标注的,确实是点点鼠标的事。
但是到了自动驾驶时代,所有的感知任务最终都要在现实的3D世界中应用,数据集的规模也不再是几万张,几十万张,或者几百万张图片,与之前的情况已不可同日而语,自然面临了更多更复杂的问题。
这不,前面的感知系统,Andrej Karpathy大佬一个人就可以Handle全场,但是到了数据标注这一块,Tesla上了两个大佬来分别介绍。
两个大佬分别是之前介绍过的Andrej Karpathy博士,给大家介绍人工标注;Autopilot Software主管Ashok Kumar Elluswamy介绍4D自动标注,数据仿真以及数据和模型的迭代。
整个数据标注系统分为三个部分进行介绍,依次为:人工标注,自动标注,数据仿真以及大规模数据生成。
大概四年前,Tesla的数据标注也跟目前的不少CV公司一样,由第三方负责。第三方数据标注机构可以提供比较基础的数据标注和维护,但是当标注需求复杂的时候,往往会出现标注延迟太大的问题,同时标注质量也不够高。
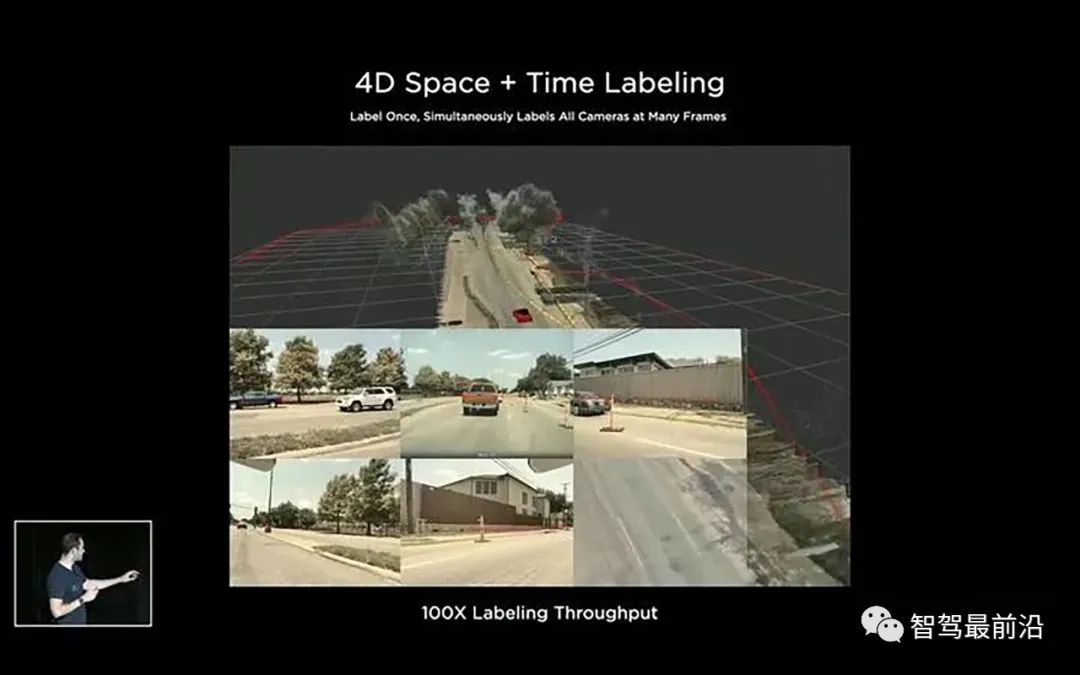
于是Tesla就建立了自己的标注团队,标注人员规模为一千余人(啊……还是有钱)。专业的标注人员和工程师紧密合作在一起,保证高质量的标注。Tesla还为此搭建了专用的数据标注系统,有专业团队维护这个标注框架以及背后的数据,能对标注工作流程中的各项数据做出精确的分析,精确到每个人和每一批数据。最初Tesla的大多数的标注还是在2D图像上进行,但是不久之后,标注开始转移到4D空间(3D空间+时间维度),直接在Vector Space进行标注,数据以一个Clip为最小标注单位。一个Clip由一段路程上的所有相机和传感器数据构成,根据这些数据可以生成一个对应路段的3D重建结果。修改任意图片或是3D重建结果上的标注,都能直接将改变映射到其他数据上。
这样的4D标注相对于2D标注更加接近自动驾驶任务的需要,但是仅仅这样是不够的。Tesla发现,人类标注人员对于语义信息更加擅长,但是计算机对于几何,重建,三角化,跟踪更加擅长;同时,随着数据规模的增长,不可能无限地扩大标注团队的规模(特斯拉也想省钱)。所以,Vector Space下更加精确的数据标注需要标注人员和计算机协作进行。
从自动标注开始,下面的内容由CMU毕业的Ashok Kumar Elluswamy介绍,尽管咖喱味十足,但是东西真是好东西。(歪个题,此处省略一万字……印度英语听力能力Get!推荐各位想学英语er都来感受下咖喱英语的魅力)
说到自动标注,很容易让人不明觉厉,我下面用一个简单例子让大家秒懂。程序猿对AI说:你已经是个成熟的AI了,要学会自己标数据训练自己...我们都知道,训练数据和训练参数一定的情况下,服务器上能跑的“大模型”,其精度和泛化能力往往强于在车端部署的“小模型”;同时,多个“大模型”做Essemble之后的精度和泛化也往往也强于单个“大模型”。所以,如果可以获得大量“小模型”表现不好的数据,我们就可以用精度和泛化更好的集成模型帮助我们把这些新数据“标一把”,再用标好的数据来训练小模型。完全拟合新数据之后,这个小模型就算再差,在这批新数据上的性能也能够逼近之前的集成模型。
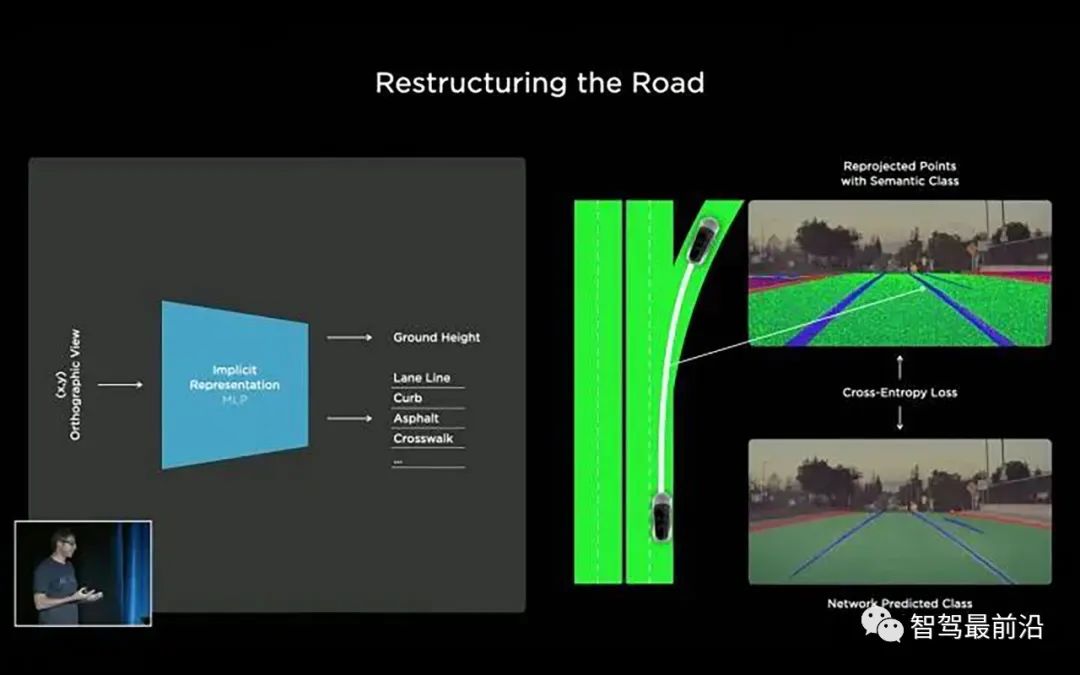
所以,Tesla的自动标注系统本质上干的也就是这么个事,只是一贯的,Tesla将它做到了极致。前面提到过,一个Clip是Tesla标注系统的最小标注单位,回顾一下Clip的概念:Clip由一段路程上的所有相机和传感器数据构成。一个Clip通常包含时长为45秒到1min的路段数据。拿到一个Clip,自动标注系统首先使用各种算法模型对数据进行预测,得到分割,目标检测,深度,光流等结果,然后经过一系列算法处理,产生最终用于训练模型的标注。可选的,人类标注人员可以对机器标好的数据做最后的检查和修改。通常来说我们可以用样条或者是网格来表示路面,但是因为拓扑约束是不可导的,这些表示方式不太好用。为了方便优化,这里选择使用一个神经网络来隐式地对路面建模。
我们query一个路面上的(x, y)点,然后让网络预测路面的高度z,以及一些语义信息,比如车道线,道路边界等。对于每一个(x, y),网络预测一个z,就可以得到一个3D点。我们可以将这个3D点重投影回到各个相机的图像上。做出百万计这样的query,就能够得到大量的点重投影回各个相机。图4右上角显示了这样重投影回图像的点。接下来,我们可以将这些重投影回原图的点与图像空间直接做语义分割的结果进行对比,再在各个相机上,跨过时间和空间维度(across space and time)做联合优化,得到非常高质量的重建结果。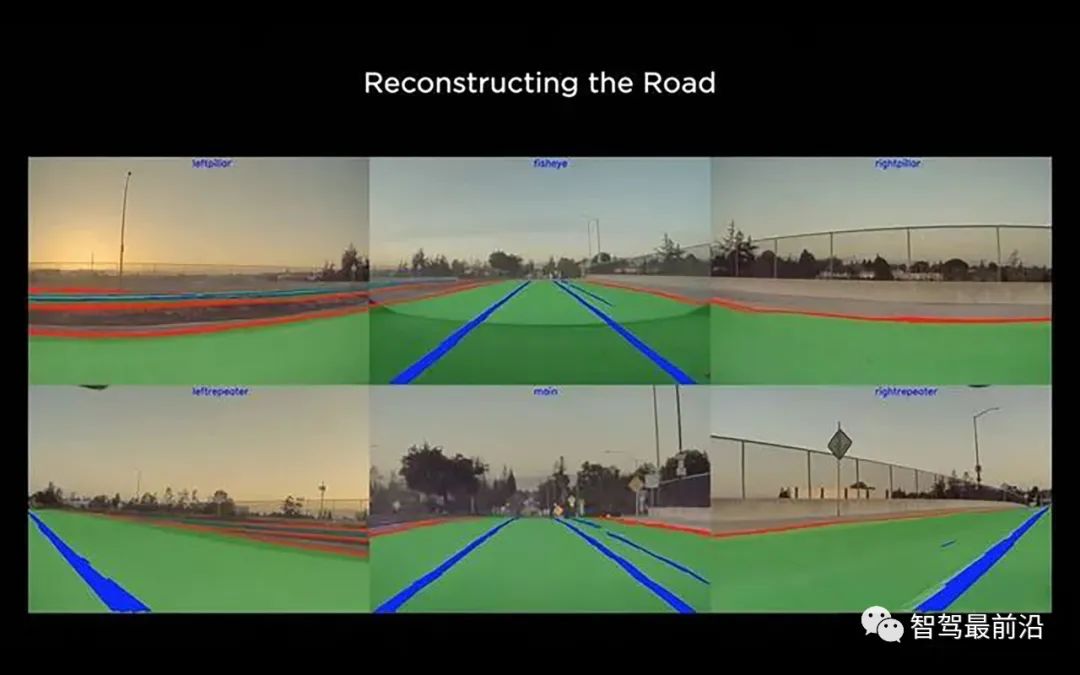
图5,路面重建结果,满足了各个相机时间和空间上的一致性最后是得到在整个Clip上连续一致的稠密标注结果,如图5所示。这个一致性是指同一个物体的标注在视频序列前后帧,以及不同相机的图像中均保持一致。
使用这样的技术,当数据采集车经过一段路的时候就可以采集并标注附近相关的Clip。更进一步,使用一辆车甚至多辆车多次以不同的方式经过同一个地点,能够获得多个相同地点的Clip进行标注。
图6,可以使用不同车辆多次经过相同地区,得到多个标注结果这些Clip和对应的标注可以放到一起进行更大规模的优化,得到更加精确和更加详细的标注结果。
图7就是16个Clip对齐到一起,保证车道线等多种特征在Vector Space,及各个相机视角观测下的一致性得到的结果。
 图7,叠加多个Clip的结果进行联合优化可以得到更加精确和详细的标注结果这样的标注方式不仅仅是得到了一个高精地图,还顺带标注了相关的各个Clips,已经有点"众包地图"的味道在里面了。自动标注完成之后,如果有需要可以再让专业标注人员对标注结果做校验,顺带去除噪声,或者添加一些其他的标注。所以车跑一遍,模型跑一遍,再进行联合优化,数据就标好了。Tesla的自动标注系统用类似的方式,可以完成一个Clip里面所有要素的自动标注,对于静态物体,给出3D重建结果;对于动态障碍物,给出每一时刻具体的位置,姿态,并计算出3D的运动轨迹。图8展示了由相机生成的高密度3D点云,点云囊括了路面及车辆周边的所有障碍物。前面介绍的方法能够解决静态障碍物的问题,下面介绍一下动态障碍物的处理。
图7,叠加多个Clip的结果进行联合优化可以得到更加精确和详细的标注结果这样的标注方式不仅仅是得到了一个高精地图,还顺带标注了相关的各个Clips,已经有点"众包地图"的味道在里面了。自动标注完成之后,如果有需要可以再让专业标注人员对标注结果做校验,顺带去除噪声,或者添加一些其他的标注。所以车跑一遍,模型跑一遍,再进行联合优化,数据就标好了。Tesla的自动标注系统用类似的方式,可以完成一个Clip里面所有要素的自动标注,对于静态物体,给出3D重建结果;对于动态障碍物,给出每一时刻具体的位置,姿态,并计算出3D的运动轨迹。图8展示了由相机生成的高密度3D点云,点云囊括了路面及车辆周边的所有障碍物。前面介绍的方法能够解决静态障碍物的问题,下面介绍一下动态障碍物的处理。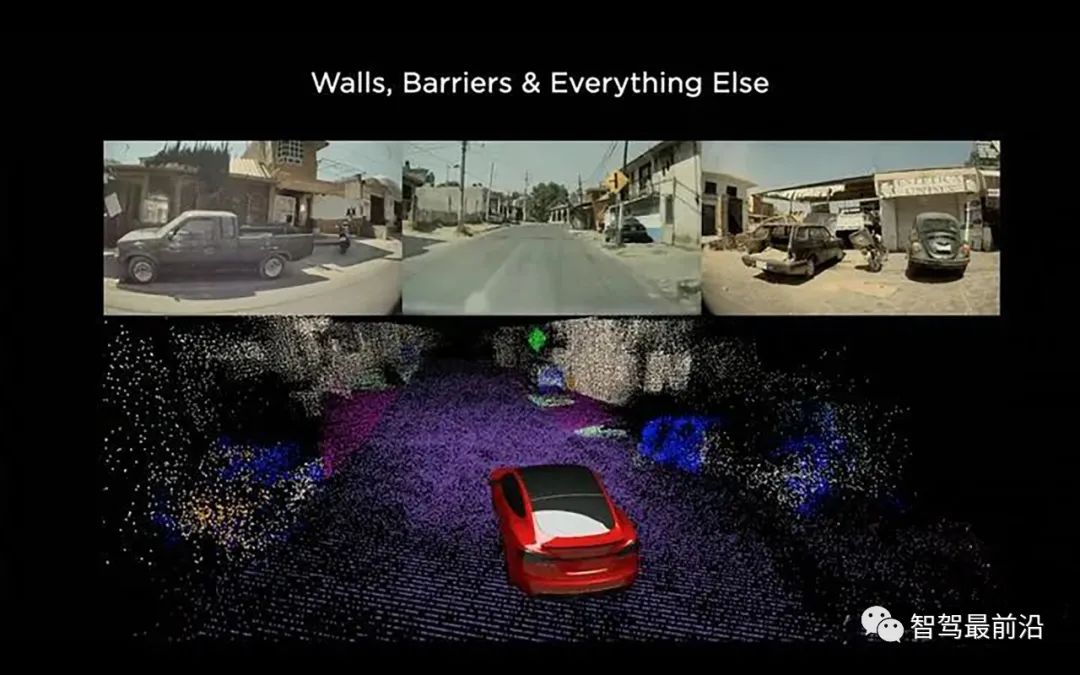
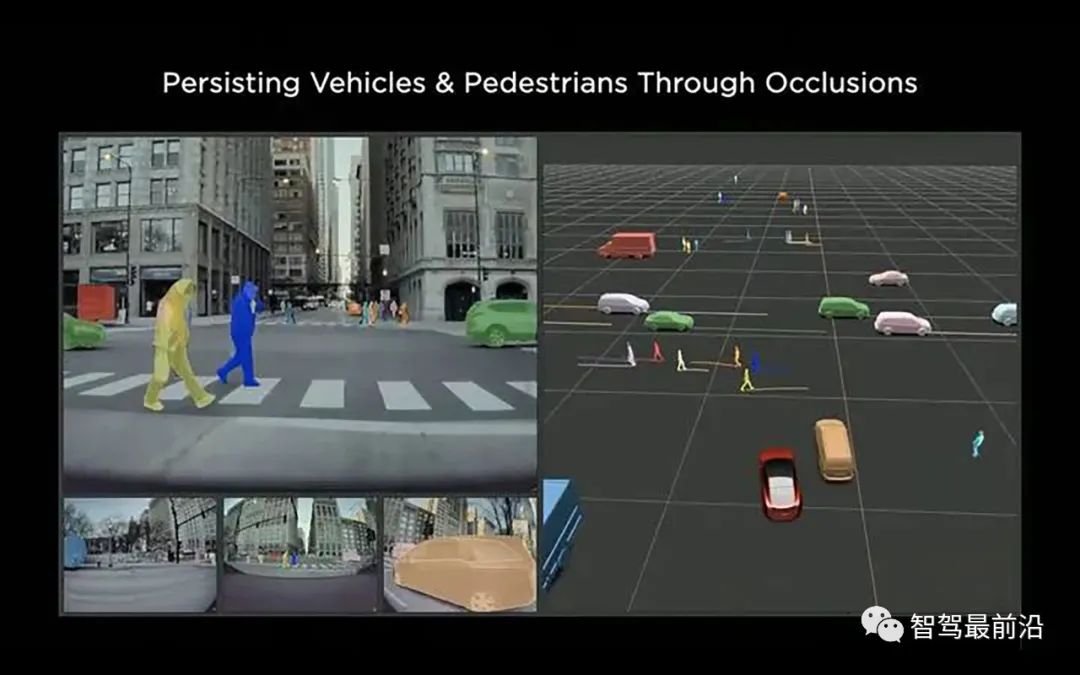
对于动态障碍物,即运动目标,自动驾驶的感知系统需要给规控提供每个目标的位置,朝向,运动速度,过去时刻的运动轨迹,并估计将来的运动轨迹等信息。标注系统知道这些信息的真值就非常重要。在这些Clip里面,每一时刻我们不仅知道过去发生了什么,还知道将来会发生什么,以近乎“作弊”的方式得知正确答案。所以我们可以很精确的给出每个目标"将来"运动轨迹的真值。此外,“上帝视角”还可以解决遮挡问题。因为知道每个运动目标的运动轨迹,所以可以根据目标被遮挡前后的运动轨迹还原出被遮挡状态下的运动轨迹和姿态,因此标注也不再受到遮挡的影响。
以这样的自动标注,Tesla可以轻易地标注百万计的Clips来训练模型。
对于一些模型做的不太好的场景,比如低可视度的恶劣天气,就可以使用大规模的车队采集很多相应场景的数据,然后通过自动标注,迅速地将这些数据用来训练模型,快速提升性能。
自动标注一个星期能够标注1万个clip,纯人工完成相同规模的标注则需要几个月!
完成自动标注之后,尝到了自动化甜头的马老板甚至连数据采集车的电费都不想出了,于是开始琢磨数据仿真。
哈哈,开个玩笑,数据仿真的好处并不仅仅是省钱,还可以解决很多难题,比如很多具有长尾效应的Corner Case就可以用数据仿真采集到数据。想象一下,如果高速路上突然出现一头牛或是一群大象,让自动驾驶汽车怎么处理?
这样的数据显然非常难以采集,我们不可能真的让一群大象冲到高速路上,然后再开着采集车过去采数据。但如果现实生活中真的遇到了这样的情况,我们依然希望自动驾驶汽车能够处理,所以相应的数据是必须的。为了解决类似问题,Tesla的下一个撒手锏就是数据仿真。相对于真实数据,仿真数据有以下几方面的优点:(1)仿真数据可以提供完美的标注,很多难以标注的场景可以使用仿真数据。(2)仿真数据可以在真实数据难以采集的情况下提供优质的数据。看样子,仿真数据是真香,不过要搞出能用的仿真数据还是要费一番功夫的。做数据仿真,就是要让虚拟的数据要尽可能真实,Tesla团队为此做出了以下几方面的努力:1)准确的传感器模拟:数据仿真的第一要务就是让模拟器产生的数据尽可能接近真实相机拍摄的数据。所以Tesla团队从多个方面做出相应的努力,包括对于相机传感器噪声,运动模糊,光学畸变,以至于挡风玻璃上的衍射斑的仿真。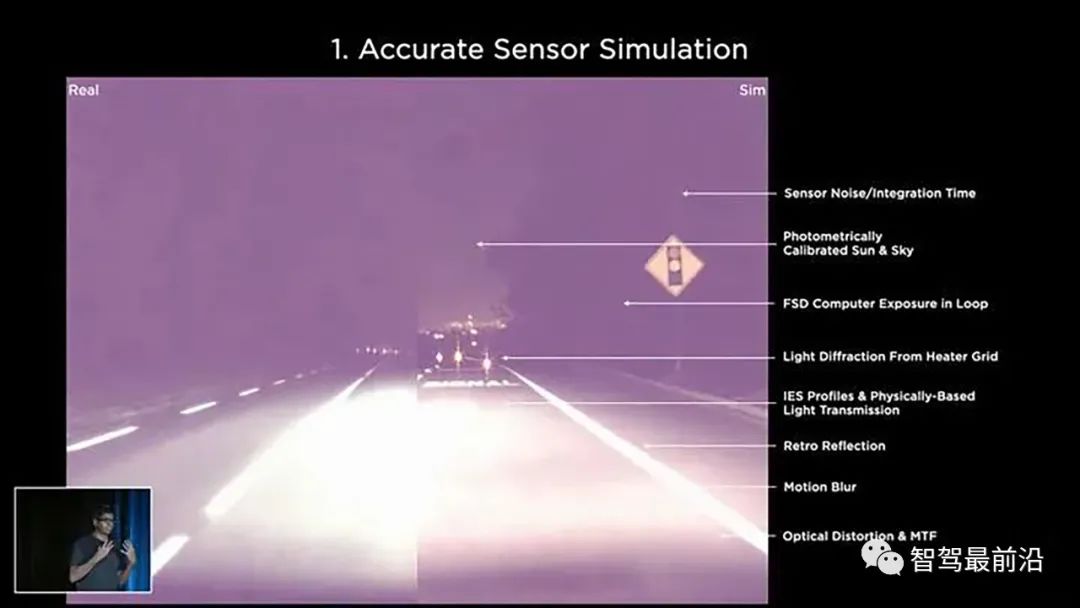
2)逼真的渲染:仿真需要实现接近真实的渲染,不能出现类似于游戏中的那种虚假画面。为此,Tesla团队用上了神经渲染(Neural Rendering)来保证渲染效果;用光线追踪(ray tracing)来保证逼真的光照效果。
3)丰富的场景及演员。为了防止感知模型过拟合到几种车型或是单一的场景,Tesla团队设计了很多的“演员”以及“道具”放到虚拟的世界中,包括形形色色的汽车和穿着各异的行人。同时还设计了总里程超过2000Miles的虚拟道路,里程相当于美国东西海岸之间的距离。马老板果然大手笔,有没有感觉像是一个活生生的“西部世界”!4)大规模场景生成。前面提到的虚拟数据只是冰山一角,Ashok说到,真实用来训练模型的数据是由这些素材按照一定章程,使用算法生成的。道路的曲率,树木的形状和分布,雪糕筒的摆放,电线杆,以及以各种速度前进的车辆等等各种交通参与物都可以根据需要设置,像天气和光照条件什么的更不在话下。
随机地使用这些素材生成训练数据固然可以,但是大多数生成的场景下模型都可以表现的很好了,所以Tesla团队会使用一些基础的机器学习算法,让模型找到容易出错的场景,然后根据相应的场景生成跟多数据,再来训练模型。
这样,数据和模型的闭环完成了,随着不断迭代,性能会一路提升。
5)场景重建。Tesla还希望能够重建真实场景的自动驾驶任务中的Failure Case,这样能够方便在模拟器中进行复现,找到并解决问题。
如图15,左图表示一辆真实的汽车采集的数据,经过自动标注系统得到3D重建后的结果。用这些重建后的结果结合视觉信息,可以重建出完全一样的虚拟场景。
在这个虚拟场景中,就可以做各种实验,找到并解决之前的问题。 图15,可以从真实数据中生成虚拟数据,帮助Debug当前,Tesla车端部署的模型早已用上了虚拟数据做训练,虚拟数据的规模为37.1亿张图片,4.8亿标注。这样的数据,用"核燃料库"来比喻毫不为过。看到这一数字,苦苦等数据的新生代民工已经哭晕在厕所……
图15,可以从真实数据中生成虚拟数据,帮助Debug当前,Tesla车端部署的模型早已用上了虚拟数据做训练,虚拟数据的规模为37.1亿张图片,4.8亿标注。这样的数据,用"核燃料库"来比喻毫不为过。看到这一数字,苦苦等数据的新生代民工已经哭晕在厕所……
Tesla的数据标注系统经历了这样由人工标注到自动标注,再到仿真的过程,确实给我们提供了很好的借鉴,不仅仅能应用在自动驾驶领域,也能应用到在其他CV相关的方方面面!通过这套系统可以看到Tesla拿掉毫米波雷达,坚持纯视觉的底气。
Tesla的方案除了可供学习之外也启迪我们:在CV算法已经比较成熟的今天,单一算法的提升并不能带来太多改变,但是算法系统级别的研究还有很大潜力可以挖掘,硬件,数据和算法应该融合到一起进行设计和迭代。
学习之余,我们也不必“长他人志气,灭自己威风”。其实Tesla并不是一枝独秀,国内不少公司也早已在相关领域进行了摸索并有了不错的积累。
接下来,一起加油呀,让AI的星星之火烧成燎原之势!