本文来源“智能计算中心创新发展指南(2023)”,智算中心建设通过领先的体系架构设计,以算力基建化为主体、以算法基建化为引领、以服务智件化为依托,以设施绿色化为支撑,从基建、硬件、软件、算法、服务等全环节开展关键技术落地与应用。1、PCI Express一致性测试方法
2、5G IC高速接口设计与测试挑战
3、MIPI D-PHY一致性测试方法
4、MIPI C-PHY一致性测试方法
5、HDMI 1.4_2.0物理层一致性测试方法7、DDR一致性测试方法
8、DDR技术演进与测量挑战
9、SATA一致性测试原理与方法
10、USB2.0/USB3.1一致性测试方法
11、高速数字接口测量的去嵌入和均衡软件使用方法1、PCI Express 3.0 and 4.0测试挑战
2、PCI Express一致性测试方法1、USB 2.0一致性测试方法
2、USB2.0/USB3.1一致性测试方法
3、USB 3.1 Gen2 10G -Gen1 5G Receiver测试《56份GPU技术及白皮书汇总》
《集成电路及芯片知识汇总(1)》
多模态AI研究框架(2023)
大模型算力需求驱动AI服务器行业高景气(2023)
“机器人+” 系列:机器人研究框架(2023)
《人工智能AI大模型技术合集》
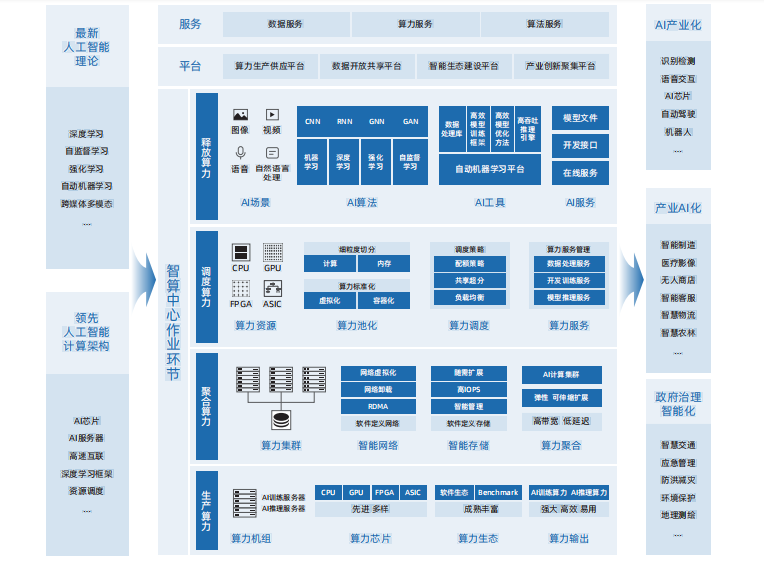
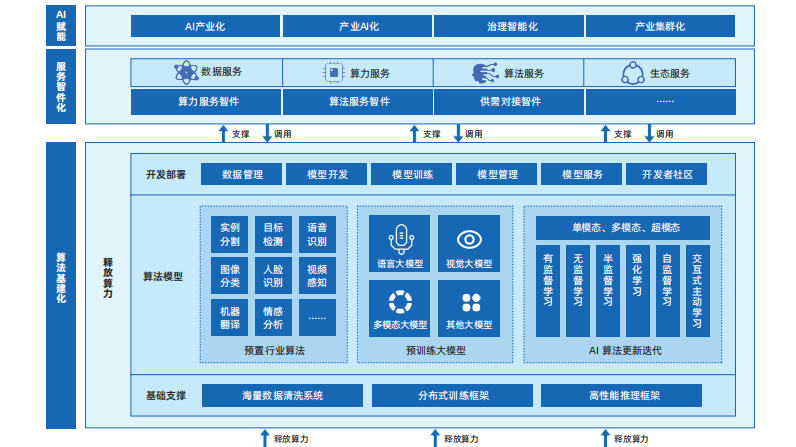
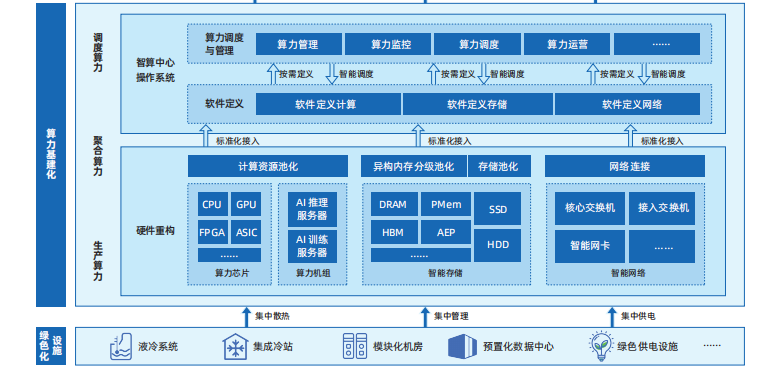
智算中心的发展基于最新人工智能理论和领先的人工智能计算架构,算力技术与算法模型是其中的关键核心技术,算力技术以AI芯片、AI服务器、AI集群为载体,而当前的算法模型发展趋势以AI大模型为代表。在此基础上,通过智算中心操作系统作为智算中心的“神经中枢”对算力资源池进行高效管理和智能调度,使智算中心更好地对外提供算力、数据和算法等服务,支撑各类智慧应用场景落地。而软件生态则是智算中心“好用、用好”的关键支撑。 基于AI芯片的加速计算是当前AI计算的主流模式。AI芯片通过和AI算法的协同设计来满足AI计算对算力的超高需求。当前主流的AI加速计算主要是采用CPU系统搭载GPU、FPGA、ASIC等异构加速芯片。 AI计算加速芯片发端于GPU芯片,GPU芯片中原本为图形计算设计的大量算术逻辑单元(ALU)可对以张量计算为主的深度学习计算提供很好的加速效果。随着GPU芯片在AI计算加速中的应用逐步深入,GPU芯片本身也根据AI的计算特点,进行了针对性的创新设计,如张量计算单元、TF32/BF16数值精度、Transformer引擎(Transformer Engine)等。 近年来,国产AI加速芯片厂商持续发力,在该领域取得了快速进展,相关产品陆续发布,覆盖了AI推理和AI训练需求,其中既有基于通用GPU架构的芯片,也有基于ASIC架构的芯片,另外也出现了类脑架构芯片,总体上呈现出多元化的发展趋势。但是,当前国产AI芯片在产品性能和软件生态等方面与国际领先水平还存在差距,亟待进一步完善加强。总体而言,国产AI芯片正在努力从“可用”走向“好用”。 AI服务器是智算中心的算力机组。当前AI服务器主要采用CPU+AI加速芯片的异构架构,通过集成多颗AI加速芯片实现超高计算性能。 为满足各领域场景和复杂的AI模型的计算需求,AI服务器对计算芯片间互联、扩展性有极高要求。AI服务器内基于特定协议进行多加速器间高速互联通信已成为高端AI训练服务器的标准架构。目前业界以NVLink和OAM两种高速互联架构为主,其中NVLink是NVIDIA开发并推出的一种私有通信协议,其采用点对点结构、串列传输,可以达到数百GB/s的P2P互联带宽,极大地提升了模型并行训练的效率和性能。OAM是国际开放计算组织OCP定义的一种开放的、用于跨AI加速器间的高速通信互联协议,卡间互联聚合带宽可高达896GB/s。浪潮信息基于开放OAM架构研发的AI服务器NF5498,率先完成与国际和国内多家AI芯片产品的开发适配,并已在多个智算中心实现大规模落地部署。 大模型参数量和训练数据复杂性快速增长,对智算系统提出大规模算力扩展需求。通过充分考虑大模型分布式训练对于计算、网络和存储的需求特点,可以设计构建高性能可扩展、高速互联、存算平衡的AI集群来满足尖端的AI计算需求。AI集群采用模块化方法构建,可以实现大规模的算力扩展。AI集群的基本算力单元是AI服务器。数十台AI服务器可以组成单个POD计算模组,POD内部通过多块支持RDMA技术的高速网卡连接。在此基础上以POD计算模组为单位实现横向扩展,规模可多达数千节点以上,从而实现更高性能的AI集群。 AI集群的构建主要采用低延迟、高带宽的网络互连。为了满足大模型训练常用的数据并行、模型并行、流水线并行等混合并行策略的通信需求,需要为芯片间和节点间提供低延、高带宽的互联。另外,还要针对大模型的并行训练算法通信模式做出相应的组网拓扑上的优化,比如对于深度学习常用的全局梯度归约通信操作,可以使用全局环状网络设计,配置多块高速网卡,实现跨AI服务器节点的AI芯片间RDMA互联,消除混合并行算法的计算瓶颈。 超大规模智能模型,简称大模型,是近年兴起的一种新的人工智能计算范式。和传统AI模型相比,大模型的训练使用了更多的数据,具有更好的泛化性,可以应用到更广泛的下游任务中。按照应用场景划分,AI大模型主要包括语言大模型、视觉大模型和多模态大模型等。随着大模型技术在语言、视觉等多个领域的应用,融合多个模态的多模态大模型也逐渐成为了业界关注的重点。基于多模态大模型的以文生图技术也迅速发展,代表性模型有DALLE-2和Stable Diffusion等。由于多模态大模型的快速发展,AI内容生成(AI Generated Content,AIGC)已成为下一个AI发展的重点领域。 智算OS,即智算中心操作系统,是以智算服务为对象,对智算中心基础设施资源池进行高效管理和智能调度的产品方案,可以使智算中心更好地对外提供算力、数据、算法、智件等服务,有效降低算力使用门槛,提升资源调度效率,支撑各类智慧应用场景落地,是智算中心的“中枢神经”。智算OS主要由三层架构构成,分别为基础设施层、平台服务层、业务系统层。基础设施层主要实现将异构算力、数据存储、框架模型等转化为有效的算力与服务资源,算力资源池能够聚合并进行标准化和细粒度切分,以满足上层不同类型智能应用对算力的多元化需求,并通过异构资源管理和调度技术,提升可同时支撑的智算业务规模。平台服务层主要提供AI训练与推理服务、数据治理服务、运营运维服务等,并通过智算OS实现自动化、智能化,有效摆脱人力束缚,促进算力高效释放并转化为生产力。业务系统层是面向用户端的统一服务入口,向下整合各层级核心功能,为用户提供多元化、高质量的智算服务,满足生产中不同阶段、不同场景的智算需求。 基于业界主流、开源、开放的软件生态建设智算中心,是智算中心能够满足前沿AI计算需求、提升AI创新和生产效率、丰富行业AI应用、促进AI产业快速发展的主要前提。 深度学习的加速计算始于GPU,构建于GPU之上的CUDA软件栈为深度学习的算法开发提供了极大的便利。CUDA软件栈为深度学习的应用开发和计算加速提供了丰富的底层支撑,如张量和卷积计算加速、芯片互联通信加速、数据预处理加速、模型低精度推理加速等。在此基础上,学术界和工业界已经构建庞大的开源、开放、共享的AI软件生态,有力促进和加速全球AI技术与应用的蓬勃发展。在智算中心总体架构的基础上,聚焦智算中心建设与应用中涉及的关键技术,进一步提出智算中心建设架构。智算中心建设架构由四大关键环节组成,分别是算力基建化、算法基建化、服务智件化、设施绿色化,“四化”相互支撑、相互协调,共同构建起智算中心高效运行体系。同时,在总体架构三项服务、三项目标的基础上,进一步拓展丰富智算中心的功能和目标,实现对外提供数据服务、算力服务、算法服务、生态服务四大服务,支撑达成AI产业化、产业AI化、治理智能化、产业集群化四大目标。1、PCI Express一致性测试方法
2、5G IC高速接口设计与测试挑战
3、MIPI D-PHY一致性测试方法
4、MIPI C-PHY一致性测试方法
5、HDMI 1.4_2.0物理层一致性测试方法7、DDR一致性测试方法
8、DDR技术演进与测量挑战
9、SATA一致性测试原理与方法
10、USB2.0/USB3.1一致性测试方法
11、高速数字接口测量的去嵌入和均衡软件使用方法1、PCI Express 3.0 and 4.0测试挑战
2、PCI Express一致性测试方法1、USB 2.0一致性测试方法
2、USB2.0/USB3.1一致性测试方法
3、USB 3.1 Gen2 10G -Gen1 5G Receiver测试9、芯片和芯片设计——集成电路设计科普
10、集成电路EDA设计概述
11、超大规模集成电路设计
12、常用半导体器件讲解
13、半导体制程简介
14、SOC芯片设计
15、ASIC芯片设计生产流程
16、CAN总线详细讲解1、集成电路技术简介
2、芯片设计实现介绍
3、集成电路芯片设计
4、芯片规划与设计
5、数字IC芯片设计
6、集成电路设计的现状与未来
7、集成电路基础知识
8、集成电路版图设计本号资料全部上传至知识星球,更多内容请登录智能计算芯知识(知识星球)星球下载全部资料。
免责申明:本号聚焦相关技术分享,内容观点不代表本号立场,可追溯内容均注明来源,发布文章若存在版权等问题,请留言联系删除,谢谢。
温馨提示:
请搜索“AI_Architect”或“扫码”关注公众号实时掌握深度技术分享,点击“阅读原文”获取更多原创技术干货。