
NVMeSSD由于其高吞吐量和超低延迟,已经成为现代数据中心的主要内容。尽管NVMeSSD很受欢迎,但其在大规模部署下的可靠性仍然未知。在本文中,收集了在阿里巴部署的100多万台NVMessd的日志,并进行了广泛的分析。从这项研究中,确定了NVMeSSD的一系列主要的可靠性变化。在好的方面中,NVMeSSD对早期故障和访问模式的变化更有弹性。坏的一面是,NVMeSSD变得更容易受到复杂的相关故障的影响。更重要的是,本文发现超低延迟的特性使NVMeSSD更有可能受到故障-慢速故障的影响。
背景及动机
NVMeSSD现在是现代数据中心的新欢。NVMeSSD具有高达6GB/s的带宽和微秒级延迟,是基于sata的性能提升。除了性能之外,任何大规模部署的硬件的可靠性都是非常值得关注的。虽然在该领域有大量关于SATASSD失效特征的研究,但他们的研究结果可能对NVMeSSD没有决定性意义。首先,使用低延迟接口,NVMeSSD特别容易发生故障-慢故障。简而言之,NVMeSSD故障-慢故障导致驱动器显示异常的性能下降(例如,在正常流量下的高延迟)。与SATASSD不同,故障-慢故障可能被相对较高的延迟(>100µs)所掩盖,NVMeSSD由于其超低延迟特性(∼10µs),很容易受到影响。此外,NVMeSSD不仅仅是带有接口升级的SATASSD。相反,NVMeSSD的内部体系结构经历了相当大的变化。供应商还集成了一系列技术来提高NVMeSSD的整体可靠性,如独立NAND冗余阵列(RAIN)或低密度奇偶校验代码(LDPC)。不幸的是,由于目前还没有大规模的NVMeSSD故障停止研究,最近的进展的影响仍然未知。
一、Data Collection
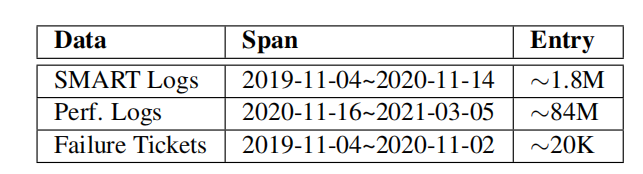
SMART logs. 在本文的集群中,每天都会收集关于SMART属性的报告。这些指标的读数可以是累积的(例如,介质误差数),也可以是瞬时的(例如,温度)。在实践中,供应商可能不一定遵循确切的计数或报告机制。因此,本文会根据制造商手册对数字进行标准化。
Performance logs. 集群的一个主要子集配备了节点级守护进程,以监视和记录Linux内核性能日志,包括存储设备的重要统计数据,如延迟、IOPS和吞吐量。目前,守护进程每天运行3个小时(从晚上9点到12点),并且只记录每个监视窗口的平均值(15秒长)。在三个小时内,流量相对稳定(约70%的峰值流量),主要由内部工作负载和大型外部客户端(即较少的突发流量)主导。
Failure tickets. 集群中的每个节点都设置了一个守护进程来监视和报告停止失败。在报告后,将生成一个故障记录单(并由工程师手动检查),其中包含受害者驱动器的基本信息(例如,模型和主机名)和时间戳。
二、Overview
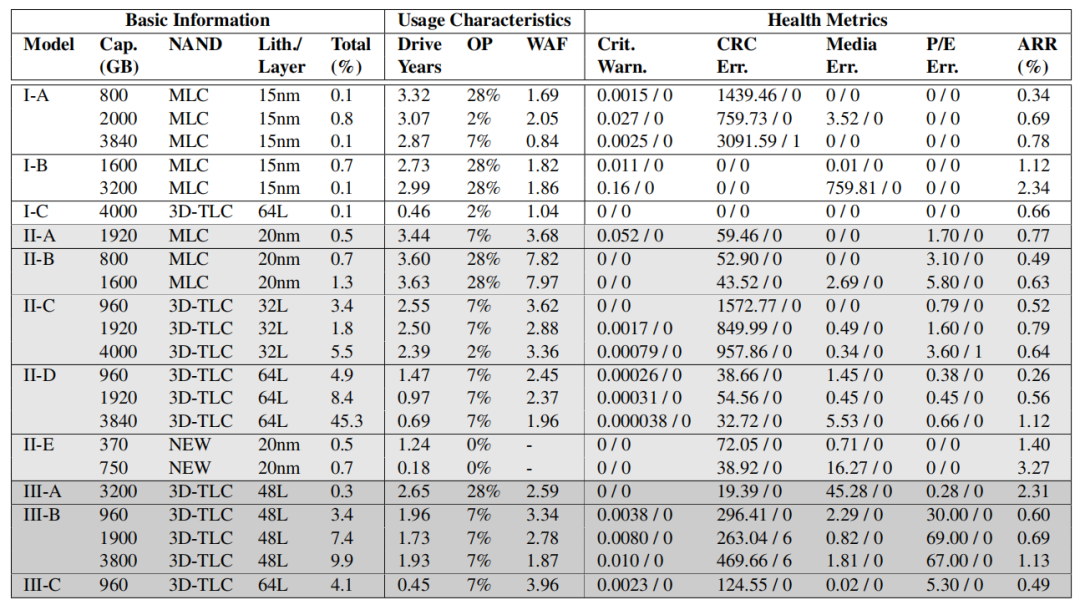
在基本信息中,本文将驱动器型号命名为制造商-型号,并使用字母顺序表示制造商的世代(例如,I-A代表制造商I的最早型号)。每个模型都可以通过容量和NAND体系结构区分。II-E是一种独特的情况,因为它采用了一种新的(既不是平面的,也不是3D堆叠的)单元,因此被命名为NEW(匿名的)。最后,列出了每个模型的相对总体(即总%)。
使用特性描述了高级管理信息。第一列是按年计算的平均通电时间。第二列和第三列分别表示超额配置率(即OP)和计算出的平均写放大因子(即WAF)。
可靠性相关的主要指标有五个。
Critical Warning:由NVM引入的严重警告表明,驱动器可能有严重的介质错误(即,在只读或降级模式下),可能出现硬件故障,或超过温度报警阈值。
CRC Error:传输错误的数量(例如,驱动器和主机之间的故障互连)
Media Error:数据损坏错误的数量(即,无法访问闪存媒体中存储的数据)
Program/Erase Error:闪光单元编程错误的数量(例如,无法从复制过程中即将被垃圾收集的块对闪光单元进行编程)
Annual Replacement Rate (ARR):设备故障数除以设备年数
前四个健康指标的读数有严重的偏差,其中零占有效记录的绝对多数(例如,关键警告的99.97%)。因此,同时列出了平均值和中值(即平均值/中值)。
三、Failure tickets
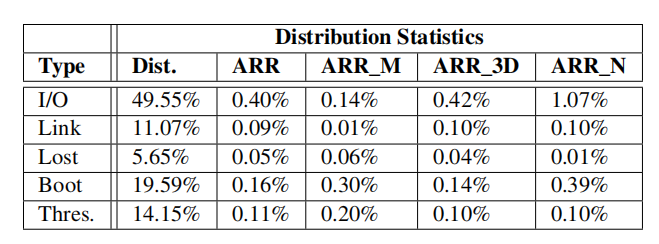
对于每种类型的故障,列出了其分布(Dist)以及所有NVMessd(ARR)、基于mlc的(ARR_M)、3D-TLC(ARR_3D)和NEW-NANDssd(ARR_N)中相应的ARR。
四、NVMe SSD vs. SATA/SAS SSD
在本文的数据集中的NVMeSSD的ARR远高于来自Netapp的企业存储系统的SATA/SASSSD。NVMeSSD的平均ARR和中位ARR分别为0.98%和0.69%,分别比SATA/SASSSD高2.77×和2.83×。通过NAND类型和光刻技术进一步分解了SSD种群,并得到了类似的结果。
一、Infant Mortality
发现:婴儿死亡率是硬件早期部署期间的一个的失败趋势,但在NVMeSSD中并不显著。
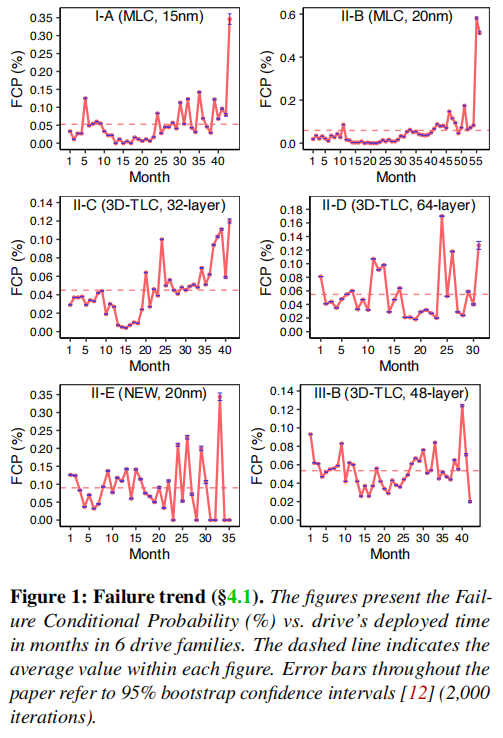
对于这个结论,本文采用每月失效条件概率(FCP)来演示失效趋势(。FCP的计算方法是,当月要更换的驱动器数除以该月存活的驱动器数。如图1所示,选取了六个流行的家族进行统计。从目视检查中,可以发现大多数家族在早期并没有显著的婴儿死亡率。
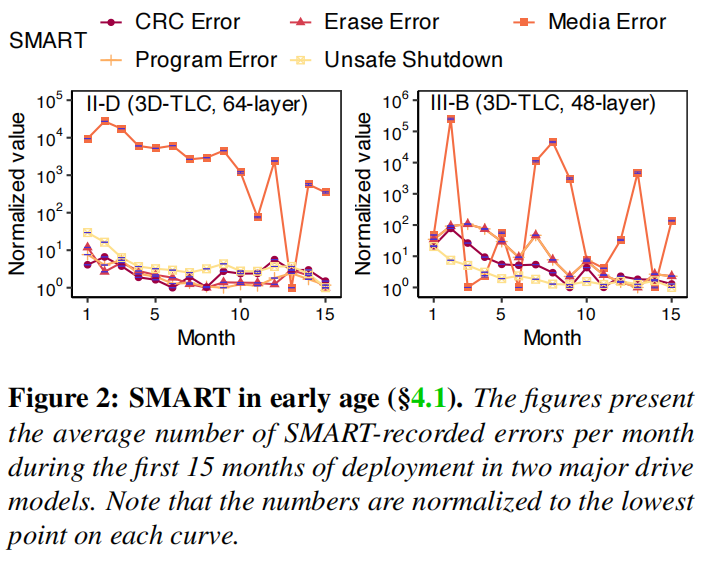
为了进一步探究其原因,本文继续从SMART属性的角度观察内部的健康指标。对于图2中的II-D和III-B,几乎所有与健康相关的指标都经历了婴儿死亡率,因为它们从一个更高的值开始,然后随着时间的推移下降到一个稳定的范围。一般来说,其他家族也遵循这一趋势。这说明即使是NVMe SSD在早期依旧会累积大量的错误,因此,本文假设FTL错误处理的改进很可能使NVMeSSD在早期更有弹性。(本文的作者相信。这可以作为供应链和现场管理员的缓解信号,因为以前的做法通常要求云运营商在初始部署之前存储额外的部件。)
二、WAF
发现:NVMeSSD对于高写放大(WAF>2)变得更加健壮,但极低写放大(WAF≤1)仍然是罕见但致命的。
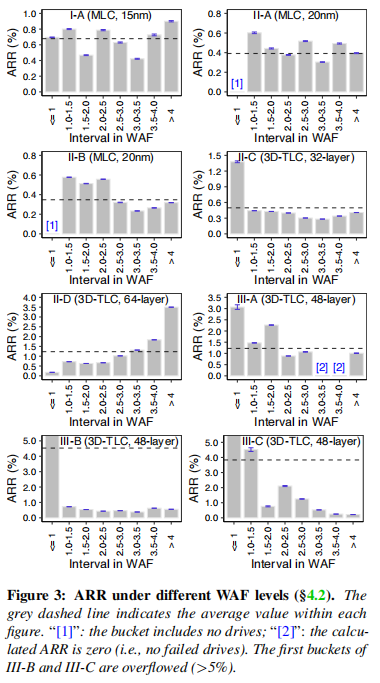
写放大是SSDI/O中常见的现象,由于SSD内部操作(如垃圾收集和对齐),逻辑写会产生额外的写入NAND的数据。为了克服这个缺点,制造商经常使用写压缩技术来组合小的或缓冲区重复写。但是在先前的研究中指出当WAF小于1的驱动器的故障率与高于2的驱动器的故障率相似时,写压缩技术可能会造成破坏。因此,本文对于NVMe SSD做了类似的统计分析。
图3显示了8个流行驱动器系列的WAF和故障率之间的相关性,包括不同类型的NAND和制造商。首先,对于WAF高于1,没有在大多数驱动家族中观察到WAF和ARR之间的强正相关关系(II-D驱动家族被认为是一个例外)。这表明NVMeSSD受随机小写的影响较小(这是高写放大的主要原因)。其次,对于具有低WAF的驱动器(即WAF≤1),它们的故障率仍然相对较高。平均而言,这些低WAF驱动器的ARR率可能比平均水平高2.19×。
因此,可以得出结论,在NVMeSSD中,虽然低WAF可能仍然是致命的,但高WAF不再令人担忧。
二、节点间/机架内故障
发现:空间相关(节点内/机架内)NVMeSSD故障在长期跨度内(即1天至1个月)存在时间相关,但在短跨度内不再普遍。
为了研究这种相关模式是否仍然困扰着NVMeSSD,本文检查了数据集中的节点内/机架故障时间间隔。使用相对失败百分比(RPF)来计算相关失败的可能性。在RPF中,分子是指在特定周期(例如,0到1分钟)之间发生的故障集的数量。分母是一个特定驱动器模型的所有故障之和。
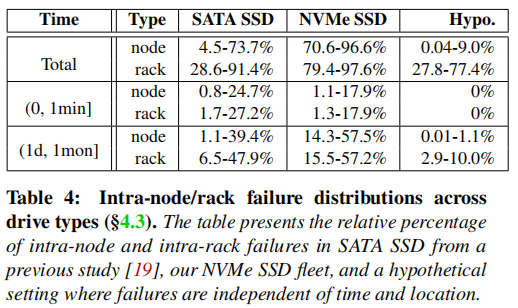
表4和图4列举了NVMeSSD的相关故障模式。首先,所有NVMe驱动器模型的累积rpf(即总行)要高得多,对于节点内和机架内的场景,分别增加了14.69×和1.78×。第二,与SATASSD不同(主要在短时间间隔内相关),NVMeSSD的相关失败通常只在长时间间隔内观察到(即1天至1个月)。同时,为了确保这些故障是由于空间时间相关性导致的,而不是各个机架或是节点内自然的平均故障导致,本文特地进行了验证实验,将数据中的设备到达时间和所处物理位置全部打乱,再次进行测试,结果如表重点Hypo负载所示,节点内的相关故障以及时间间隔内的相关故障均显著下降,这说明这些故障确实存在不平衡性。
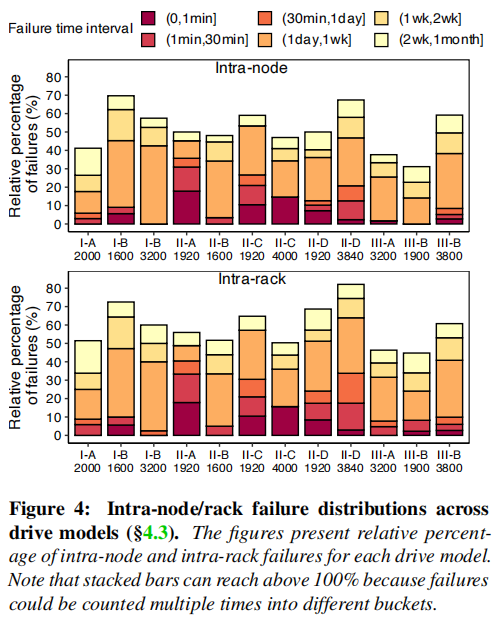
虽然密切相关的故障的下降意味着经历系统级故障的风险较低,但长时间间隔的相关故障的激增仍然构成了一个紧迫的威胁。一个不方便的事实是,修复驱动器故障通常从基于软件的方法开始(例如,数据清理和fsck),而这种在线检查和修复需要时间。事实上,在本文集群中,43.90%、14.36%和10.90%的故障驱动器在一天、一周和两周后得到了修复。基于这个发现,本文改进了操作过程,直接使驱动器下线,以减少遭受长期相关故障的机会。
一、识别fail-slow事件和驱动器
本文使用以下基于阈值的方法来识别故障-慢速驱动器(类似于之前关于SATASSD和HDD尾部延迟的研究)。
第一步是选择具有高延迟的可疑驱动器。观察到集群内的性能记录(例如,延迟、IOPS和吞吐量)记录通常遵循一个正偏态分布。例如,在一个集群中,中位延迟仅为49.19µs,而平均延迟为667.85µs。因此,我们可以使用延迟阈值(−∞,3rd_quartile+2IQR)来识别异常值(即慢驱动器),其中IQR(四分位数范围)是通过从第三个四分位数减去第一个四分位数来计算的。如果驱动器的3小时平均延迟超过标准,我们将此驱动器标记为可疑的慢驱动器,同时将大流量的情况进行排除,保证尽可能少的假阳性情况出现。
然后,我们通过检查是否存在一致的减速来确定所选择的驱动器是否确实是故障慢的。识别可疑的故障-慢速驱动器。这部分需要考虑对等点的情况,简单来说就是,在事件中,受害者的速度至少比同类速度慢两倍。则被认为是故障-慢速驱动器。其次,将4个最小跨度设置为5、15、30和60分钟,这意味着计算这四个时间间隔内与同类驱动器速度的比较。如表5中的slowdown ratio。此外,表5还展示了该模型中被识别为故障慢速的驱动器的百分比。事件的频率。描述每小时每1000个驱动器的事件数,反映了一个中等大小的集群中故障变慢的严重程度。以下两列(持续时间和事件延迟)显示了平均故障-慢速事件持续时间和平均事件延迟。每个子象限的最后一行是每个类别(例如,SSD或HDD)的平均值
二、SSD vs. HDD
发现:与HDD相比,NVMeSSD的故障更广泛、更频繁,会降低到SATASSD甚至HDD级别的性能。
比较每个象限的平均行,发现ssd中慢驱动器为6.05×(即5分钟象限为1.41%至0.20%)到51×(60分钟象限为0.52%至0.01%)。类似地,也可以观察到失败-慢的发生(即事件频率)。在ssd中更为常见,范围从18.59×(5分钟)到68.50×(60分钟)。此外,尽管像II-D-1920和III-B-1900这样的模型仍然提供相对令人满意的性能,故障慢的NVMessd通常降低到sata-ssd级延迟(平均在160µs左右)。更糟糕的是,在几个NVMeSSD模型中,最慢的1%事件恶化到平均延迟约22 ms,即使是HDD的性能也不令人满意。
根本原因。本文作者已经将100个最慢的ssd(大约是已识别的慢速驱动器的前2%,平均事件延迟为4.4 ms)送回供应商进行修复。结果表明,其中33个电容器不良,导致缓冲区故障,延迟高。其中46个芯片含有坏芯片,其余芯片的根本原因尚不清楚。
二、SSD型号之间的差异。
发现:制造商是NVMe故障缓慢的主要影响因素。
对于慢速驱动器百分比,在四个象限上有一个明确的顺序(即制造商I之后是III和II)。即使是III的最高值(例如,III-b-1900在5分钟象限内的3.04%)也远远落后于I的模型(即I-A-2000的4.44%),这也适用于III和II之间的比较。然而,我们没有观察到事件持续时间、事件延迟和减速比率的可见模式。
发现:较高的故障-慢速驱动器数量并不总是会导致较高的故障-慢速事件频率。
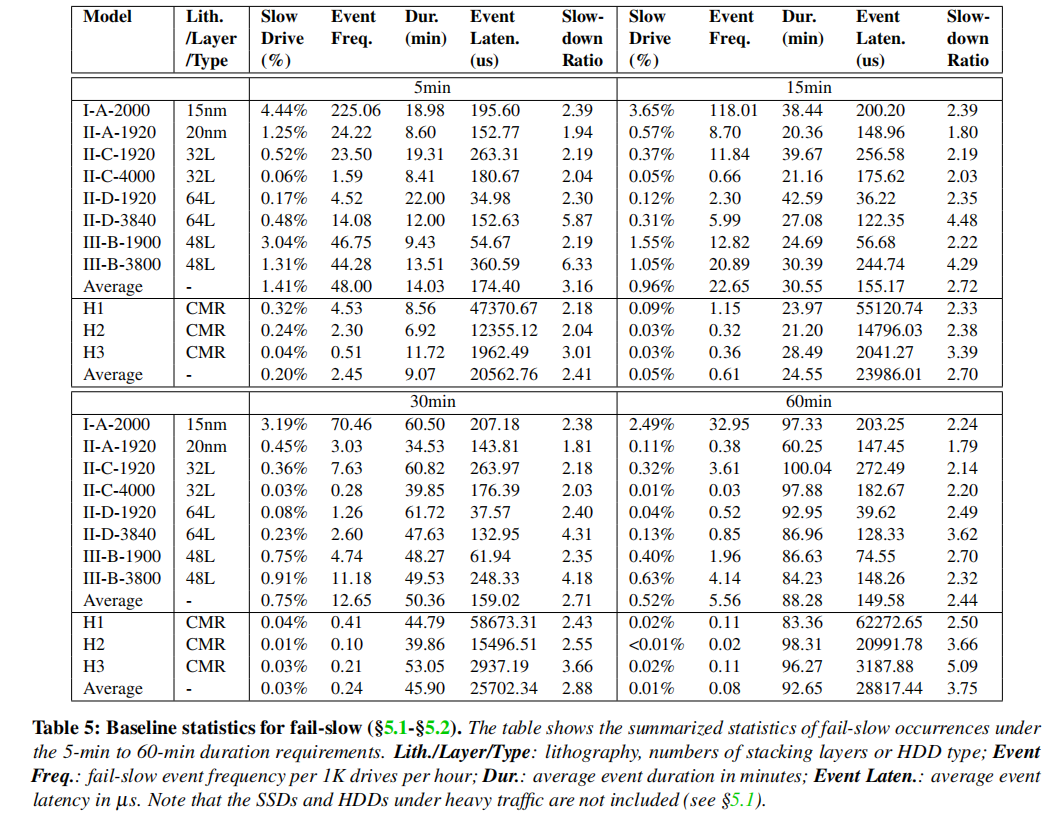
人们可以假设较高的故障-慢驱动器百分比会导致较高的事件频率。虽然这一假设适用于最长的持续时间要求(60分钟象限),但在较短的象限中发现了许多反例(例如,5分钟象限中的II-A-1920和II-C-1920)。一种可能的解释是,在较短的持续时间要求下,有更多的驱动器有多个事件,导致一个小的慢驱动器比例和高的事件频率。在这里,可以通过图5进一步验证了这一假设,这是不同持续时间要求下每个驱动器事件的CDF。可以清楚地看到,持续时间较短的驱动器比持续时间较长的驱动器积累更多的事件。
三、fail-slow的相关因素
1、驱动器年龄
发现:fail-slow驱动数量和事件频率与年龄密切相关,但仅针对老年(通电时间>41个月)NVMessd。
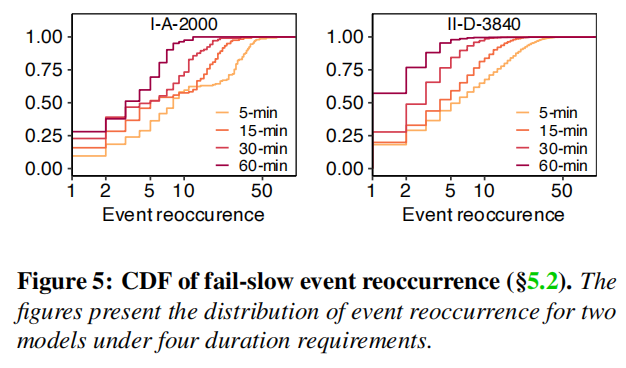
图6展示了在5分钟(左)和60分钟(右)要求下的种群随时间的方差,其中水平虚线是平均值。可以看到,在这两种情况下,种群数量最初都在平均值左右振荡,然后在最后几个月开始激增。在15分钟、30分钟和60分钟的要求时也存在类似的趋势。
2、工作负载
发现:工作负载可能会显著影响各种故障慢速特性,而繁重的流量工作负载可能会对故障-慢速的发生产生长期的影响。
本文通过研究四种具有截然不同访问模式的代表性云存储服务,即块存储、缓冲、对象存储和查询,来评估工作负载的影响,如图6所示,通过年龄和PE周期进行分组。
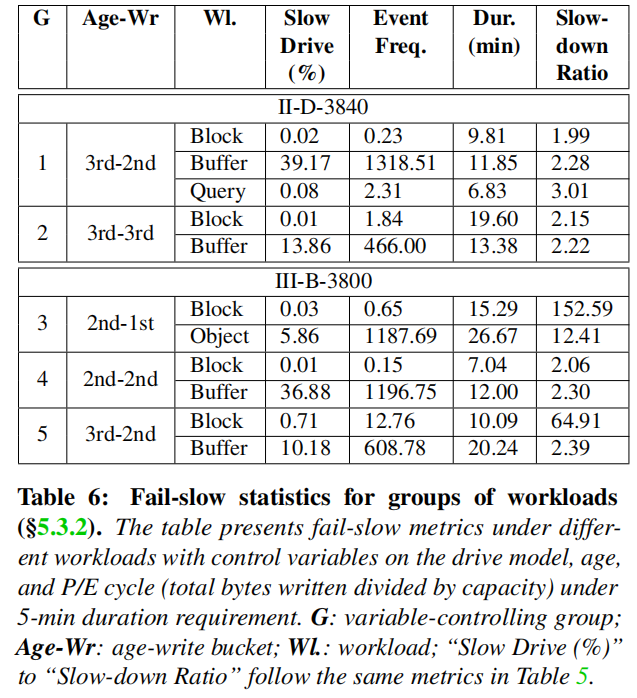
通过比较每一组内的指标,可以看到工作负载可以显著影响所有四个fail-slow的指标。例如,在组1和组2中,缓冲工作负载的失败缓慢种群和事件频率可能是块存储的数千倍(例如,组1中的39.17%vs.0.02%)。在组3中,在块存储和对象存储之间,或者在组5中,在块存储和缓冲之间,在事件持续时间和减速比率之间可以观察到类似的差异。
在实践中,缓冲工作负载下的驱动器通常经常有大量的流量(例如,存储大数据工作负载的中间结果)。但实际上已经考虑排除了大流量的ssd。因此,一种可能的解释是,繁忙的流量可能会产生长期的影响(例如,使数据更加分散),使驱动器更容易发生故障-慢速故障。
3、SMART属性
发现:SMART属性与失败-慢速指标的相关性可以忽略不计。
本文评估了WEFR中自动特征选择的有效性,并将其与使用固定百分比的被选择特征(从10%线性增加到100%)进行比较。图2显示,当确定6个驱动器模型的所选特性的百分比时,WEFR的F0.5-score始终高于或等于最高的F0.5-score。具体来说,WEFR自动确定的MA1、MA2、MB1、MB2、MC1、MC2所选择的特征的百分比分别为31%、34%、28%、26%、63%和28%,在确定所选特征的百分比时,与最高F0.5-score对应的所选特征的百分比接近。请注意,使用自动特性选择也比调优生产中选定特性的适当百分比更灵活。
三、Fail-slow向故障转移
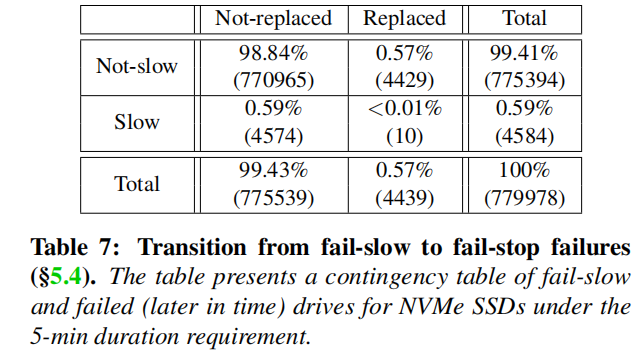
发现:从fail-slow到fail-stop的过渡很少被观察到,至少在短时间间隔内(5个月内)没有观察到。
表7是一个示例列联表,记录基于两个类别的驱动器的频率计数:出现在故障记录单(替换列)或未存在(未替换列),至少有一个故障慢事件(慢行)(非慢行)。结果是相当令人惊讶的,因为在故障停止故障之前,只有10个驱动器出现故障-慢故障,在慢驱动器(约0.22%)和替换(约0.23%)驱动器中产生相对较小的数量。平均和中位数过渡时间分别为73天和67天。一个可能的原因是,故障很少慢或可能需要很长时间过渡到故障停止故障。因此,我们得出结论,慢故障不太可能过渡为故障停止故障,至少在几个月内不会。
The End
致谢
感谢本次论文解读者,来自华东师范大学的硕士生梁宇炯,主要研究方向为SSD故障预测。
![]() 点一下“阅读原文”获取论文
点一下“阅读原文”获取论文

