五月的最后一周有一点热,热到上海破了五月的最高温纪录,热到一周之内三次被那个穿皮衣的老男人刷屏:1)Nvidia的股价单日暴涨30%,老黄身价一夜之间就飙升了约65亿刀;2)黄教主在台大进行了一次演讲,要每个人卷(RUN),不管是为了捕猎还是被猎食;3)英伟达发布的最新一代的超级芯片——Grace Hopper,并造了个E级算力的超算,然后股价又飞了。


这大半年里,各路芯片大厂也有那么点不务正业——纷纷摆了一副“不造E级超算的芯片架构师就不是好CEO”的姿势。
除了英伟达,还有Tesla的Dojo 芯片 (Expod E级超算)
再是AMD的 Instinct MI300 (美国 EL Capitan 2E级超算)

再算上Intel的Sapphire Rapids + Ponte Viechhio (美国 Aurora 2E级超算)
感慨一句——"一桌麻将齐活了!" 今年的TOP500估计又是一番争夺。
这些算力禽兽基本都在500W以上的耗电,5nm上下的工艺,甚至很可能就是孕育某个硅基生命的子宫。而他们的食物(算力的需求),毫无疑问就是那个人工智能的iphone时刻——Transformer大模型。从0.1Billon参数到Trillion级参数的训练,只用了4年。而大模型展示出的智能涌现,其效果也已经让很多人惊掉下巴。试想未来,如果每次google/bing/baidu search,每个Office/WPS Copilot,甚至每个App后面都是一个大模型在默默地奋斗,那将需要多么可怕的算力?
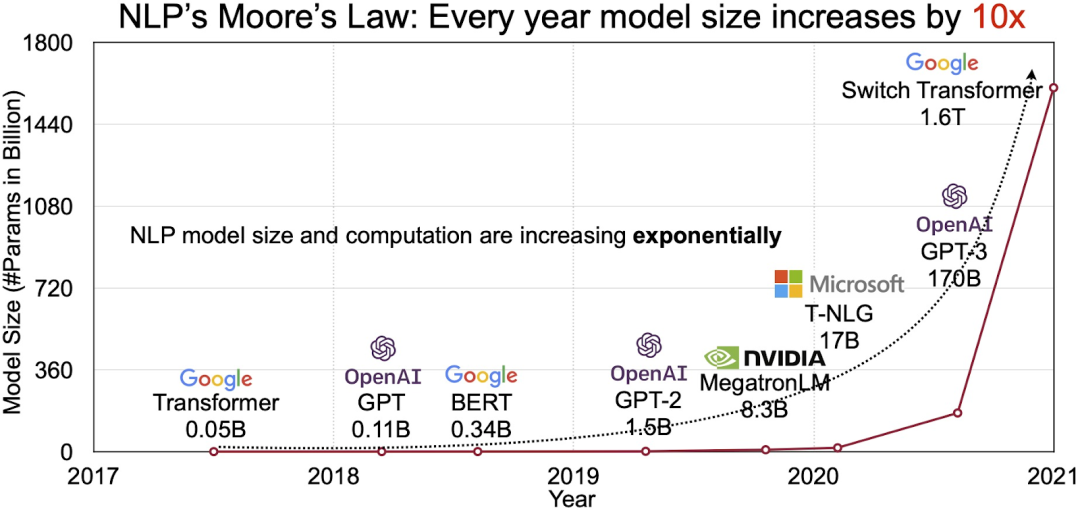
现在的行情,终端芯片倒下了(向ZEKU的战友们致以诚挚的敬意),存储器打贸易战要一片红海了,摩尔定律也要停滞了。然后看不见、摸不着的“算力”却成为了下一个“北上广房价”,开始一路凯歌。
如此高速算力黑洞,光靠隔几年翻一番的摩尔定律肯定是赶不上的。芯片发展的正道,就是 SCALE OUT——可扩展!可扩展!可扩展!Telsa在hot chips上归纳了算力进步的三大贡献因素,可以看到摩尔定律排在了最后,以氪金为本质的可扩展才是是最核心的因素。

然而神奇的是,这些巨大无比的超级芯片却采用了完全不同的技术路线、和封装集成方式,简直是百花齐放的时代,也为未来超级芯片空间的提供了无限的想象空间。首先,简单描述一下共同点:1)大家都使用了通用计算+专用高性能计算的异构架构,只是在耦合的颗粒度上有明显的差别;2)大家都采用了密度远高于substrate的先进封装的集成技术,但是在采用的技术路线上却有不同的选择。我们主要来对比下前三个(谁让Intel负责的技术大佬离职了呢?)。
奇技淫巧最多,也是我最崇拜的当然是苏妈的MI300,独孤九剑天下无敌。AMD的MI300芯片包括了13颗CMOS芯片,其中有4颗是有源硅基板(active interposer base die)。这四颗中有三颗,上面每一颗搭载了两片GPU芯粒,另外有一片上面搭载了三片CPU芯粒。值得注意的是,这里相同的active interposer同时支持了两种不同的配置。也就是说,这个大面积、3D堆叠的巨无霸可以在不同场景的复用了。除此之外,整个封装体内还有八组HBM芯粒,他们通过硅桥技术在substante基板上与active interposer的高密度相连。
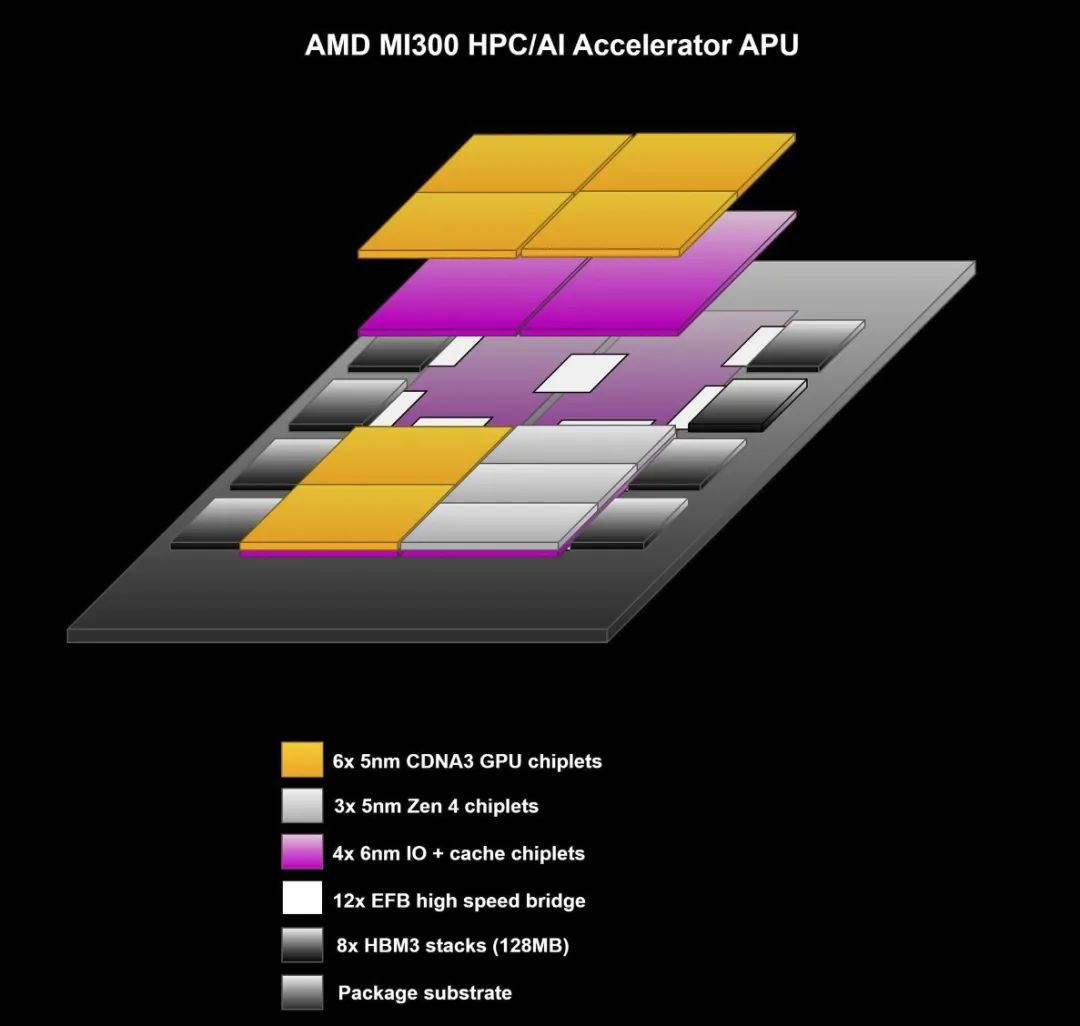
这个架构有两大特点:1)在同一个封装体内完成了通用计算(CPU)和并行高性能计算(GPU)的异构集成,2)active interposer作为一种新型的3D堆叠方案,通常是把占较大面积的last level cache以及多核之间的互连网络(network或者fabric)移到工艺相对不那么先进的下层芯片,而上层芯片采用更最牛逼的工艺,实现最佳性能。(虽然5nm/6nm都是loser们不可企及的工艺)。
Tesla的 Dojo芯片采用了完全不同的路径。在架构上,它采用了非常紧耦合的方式。其计算节点是把并行计算的专用指令集和通用处理器的超标量架构进行了融合,做成了以此为最小单位的计算核心。然后就拼呀拼呀拼,每个D1芯片上包括了354个计算核心和440MB的SRAM。
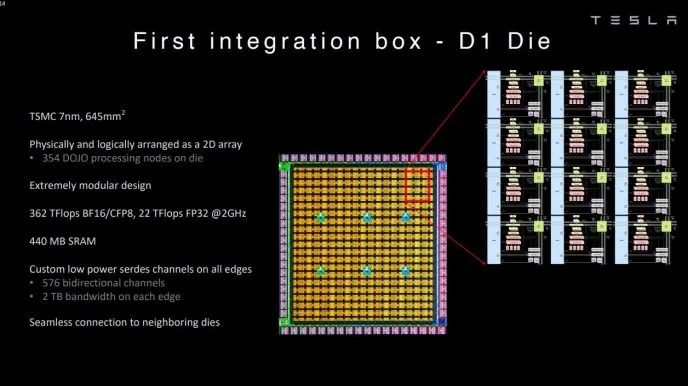
封装上,D1采用了较3D集成稍保守一点的2.xD Fanout 扇出集成技术,但是用了一个system on wafer (晶上系统)的名字。它并不是像celebras那样简单粗暴的将一个wafer裁边以后就当一整个芯片了。而是将每个芯片经过KGD测试以后,将合格的die挑选除了再集成在一个封装体内。一个Dojo晶上系统的封装中包含了25个D1的芯片。

最后,英伟达的GH200。老实讲,Grace Hopper并不是一个让人感到exciting的架构,因为他本质上就是是在PCB板上实现了连了一个CPU和一个GPU。就是最粗粒度的耦合模式,当然从电路上来讲,在板级走900GBps高带宽nvlink c2c,可以说是一笔浓墨重彩的模拟电路。他的先进封装体现在GPU芯片里面,采用了标准GPU+HBM+passive interposer的2.5D集成技术,把6组HBM紧紧围绕在一个超大的GPU芯片外。但是,单单是从架构上来说,这种粗粒度的连接和我们在一个机箱内集成了CPU加GPU的模式并没有太大的差别。
不过兴许,这就是老黄的魅力吧。大力出奇迹,管tm的花里胡哨的新技术。
上述三家的架构与集成方案大相径庭,很容易的有一个问题:如何能够客观公正地判断这三种架构和集成技术路线的优劣?跑benchmark?然而,有什么样的土豪能够同时拥有三个巨无霸算力妖孽,然后再去跑相同的benchmark呢?
跪求土豪。(不过这几个芯片应该都不让卖吧。)其实,我更好奇的是每个大厂的架构师是如何最后确定这种形态的。


