点击左上方蓝色“一口Linux”,选择“设为星标”

结构体的定义
在实际项目中,结构体是大量存在的。研发人员常使用结构体来封装一些属性来组成新的类型。由于C语言无法操作数据库,所以在项目中通过对结构体内部变量的操作将大量的数据存储在内存中,以完成对数据的存储和操作。
//声明一个结构体struct book{char title[MAXTITL];//一个字符串表示的titile 题目 ;char author[MAXAUTL];//一个字符串表示的author作者 ;float value;//一个浮点型表示的value价格;}; //注意分号不能少,这也相当于一条语句;


1、最标准的方式:
#includestruct student //结构体类型的说明与定义分开。声明{int age; /*年龄*/float score; /*分数*/char sex; /*性别*/};int main (){struct student a={ 20,79,'f'}; //定义printf("年龄:%d 分数:%.2f 性别:%c\n", a.age, a.score, a.sex );return 0;}
2、不环保的方式
#includestruct student /*声明时直接定义*/{int age; /*年龄*/float score; /*分数*/char sex; /*性别*//*这种方式不环保,只能用一次*/} a={21,80,'n'};int main (){printf("年龄:%d 分数:%.2f 性别:%c\n", a.age, a.score, a.sex );}
3、最奈何人的方式
#includestruct //直接定义结构体变量,没有结构体类型名。这种方式最烂{int age;float score;char sex;} t={21,79,'f'};int main (){printf("年龄:%d 分数:%f 性别:%c\n", t.age, t.score, t.sex);return 0;}
定义结构体变量
struct book library;看到这条指令,编译器才会创建一个结构体变量library,此时编译器才会按照book模板为该变量分配内存空间,并且这里存储空间都是以这个变量结合在一起的。
struct book s1,s2,*ss;定义两个 struct book 结构体类型的结构体变量,还定义了一个指向该结构体的指针,其 ss 指针可以指向 s1,s2,或者任何其他的book结构体变量。
struct book library;struct book{char …….…..}library;
struct{char title[MAXTITL];char author[MAXAUTL];float value;}library;
typedef int Elem;typedef struct{int date;..........}STUDENT;STUDENT stu1,stu2;

1、先定义结构体类型后再定义结构体变量;
格式为:struct 结构体名 变量名列表;
//注意这种之前要先定义结构体类型后再定义变量;struct book s1,s2,*ss;
2、在定义结构体类型的同时定义结构体变量;
struct 结构体名{成员列表;}变量名列表;//这里结构体名是可以省的,但尽量别省;struct book{char title[MAXTITL];//一个字符串表示的titile 题目 ;char author[MAXAUTL];//一个字符串表示的author作者 ;float value;//一个浮点型表示的value价格;}s1,s2
直接定义结构体类型变量,就是第二种中省略结构体名的情况;
int a = 0;int array[4] = {1,2,3,4};//每个元素用逗号隔开
回忆一下数组初始化问题:

再回到结构体变量的初始化吧
struct book s1={ //对结构体初始化"yuwen", //title为字符串"guojiajiaoyun", //author为字符数组22.5 //value为flaot型};//要对应起来,用逗号分隔开来,与数组初始化一样;
加入一点小知识,关于结构体初始化和存储类时期的问题:如果要初始化一个具有静态存储时期的结构体,初始化项目列表中的值必须是常量表达式;
注意,如果在定义结构体变量的时候没有初始化,那么后面就不能全部一起初始化了;意思就是:
/////////这样是可以的,在定义变量的时候就初始化了;struct book s1={ //对结构体初始化"guojiajiaoyun",//author为字符数组"yuwen",//title为字符串22.5};/////////这种就不行了,在定义变量之后,若再要对变量的成员赋值,那么只能单个赋值了;struct book s1;s1={"guojiajiaoyun",//author为字符数组"yuwen",//title为字符串22.5};//这样就是不行的,只能在定义的时候初始化才能全部赋值,之后就不能再全体赋值了,只能单个赋值;只能:s1.title = "yuwen";........//单个赋值;
对于结构体的指定初始化:

结构体就像一个超级数组,在这个超级数组内,一个元素可以是char类型,下个元素就可以是flaot类型,再下个还可以是int数组型,这些都是存在的。
在数组里面我们通过下标可以访问一个数组的各个元素,那么如何访问结构体中的各个成员呢?
用结构成员运算符点(.)就可以了;
结构体变量名.成员名;
注意,点其结合性是自左至右的,它在所有的运算符中优先级是最高的;
例如,s1.title指的就是s1的title部分;s1.author指的就是s1的author部分;s1.value指的就是s1的value部分。
然后就可以像字符数组那样使用s1.title,像使用float数据类型一样使用s1.value;
注意,s1 虽然是个结构体,但是 s1.value 却是 float 型的。
因此 s1.value 就相当于 float 类型的变量名一样,按照 float 类型来使用;
注意 scanf(“%d”,&s1.value); 这语句存在两个运算符,&和结构成员运算符点。
按照道理我们应该将(s1.value括起来,因为他们是整体,表示s1的value部分)但是我们不括起来也是一样的,因为点的优先级要高于&。
如果其成员本身又是一种结构体类型,那么可以通过若干个成员运算符,一级一级的找到最低一级成员再对其进行操作;
结构体变量名.成员.子成员………最低一级子成员;
struct date{int year;int month;int day;};struct student{char name[10];struct date birthday;}student1;//若想引用student的出生年月日,可表示为;student.brithday.year;brithday是student的成员;year是brithday的成员;
整体与分开
不能将一个结构体变量作为一个整体进行输入和输出;在输入输出结构体数据时,必须分别指明结构体变量的各成员;

typedef struct{char addr;char name;int id;}PERSON;
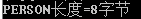
结构体字节对齐
char ss[20]={0x10,0x11,0x12,0x13,0x14,0x15,0x16,0x17,0x18,0x19,0x20,0x21,0x22,0x23,0x24,0x25,0x26,0x27,0x28,0x29};PERSON *ps=(PERSON *)ss;printf("0x%02x,0x%02x,0x%02x\n",ps->addr,ps->name,ps->id);printf("PERSON长度=%d字节\n",sizeof(PERSON));

typedef struct{char addr;int id;char name;}PERSON;


typedef struct{int id;char addr;char name;}PERSON;

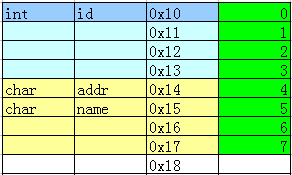
typedef struct{char addr;char name;char id;}PERSON;
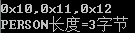

结构体嵌套
typedef struct{char addr;char name;int id;}PERSON;typedef struct{char age;PERSON ps1;}STUDENT;
STUDENT *stu=(STUDENT *)ss;printf("0x%02x,0x%02x,0x%02x,0x%02x\n",stu->ps1.addr,stu->ps1.name,stu->ps1.id,stu->age);printf("STUDENT长度=%d字节\n",sizeof(STUDENT));
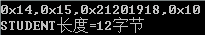
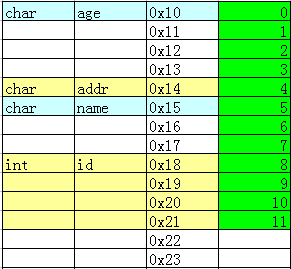
typedef struct{PERSON ps1;char age;}STUDENT;
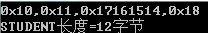
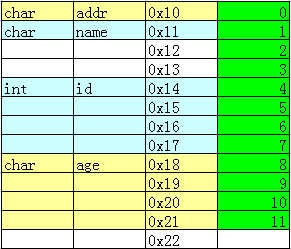
//对于“一锤子买卖”,只对最终的结构体变量感兴趣,其中A、B也可删,不过最好带着struct A{struct B{int c;}b;}a;//使用如下方式访问:a.b.c = 10;
struct A{struct B{int c;}b;struct B sb;}a;
使用方法与测试:
a.b.c = 11;printf("%d\n",a.b.c);a.sb.c = 22;printf("%d\n",a.sb.c);
结果无误。
printf("size of struct man:%d\n",sizeof(struct man));printf("size:%d\n",sizeof(Huqinwei));
struct s{char a;short b;int c;};
相应的,64 位机按 8 字节对齐。不过对齐不是绝对的,用#pragma pack()可以修改对齐,如果改成1,结构体大小就是实实在在的成员变量大小的总和了。
#include//直接带变量名struct stuff{// char job[20] = "Programmer";// char job[];// int age = 27;// float height = 185;};
PS:结构体的声明也要注意位置的,作用域不一样。
C++的结构体变量的声明定义和C有略微不同,说白了就是更“面向对象”风格化,要求更低。
int get_video(char **name, long *address, int *size, time_t *time, int *alg){...}int handle_video(char *name, long address, int size, time_t time, int alg){...}int send_video(char *name, long address, int size, time_t time, int alg){...}
char *name = NULL;long address;int size, alg;time_t time;get_video(&name, &address, &size, &time, &alg);handle_video(name, address, size, time, alg);send_video(name, address, size, time, alg);
struct video_info{char *name;long address;int size;int alg;time_t time;};
int get_video(struct video_info *vinfo){...}int handle_video(struct video_info *vinfo){...}int send_video(struct video_info *vinfo){...}
printf("video name: %s\n", vinfo->name);long addr = vinfo->address;int size = vinfo->size;
struct video_info vinfo = {0};get_video(&vinfo);handle_video(&vinfo);send_video(&vinfo);
int handle_video(char *name, long address, int size, time_t time, int alg);int send_video(char *name, long address, int size, time_t time, int alg);
int handle_video(struct video_info *vinfo);int send_video(struct video_info *vinfo);
int handle_video(struct video_info vinfo){...}int send_video(struct video_info vinfo){...}
//data structure except for number structuretypedef struct symbol_struct{uint_32 SYMBOL_TYPE :5; //data type,have the affect on "data display type"uint_32 reserved_1 :4;uint_32 SYMBOL_NUMBER :7; //effective data number in one elementuint_32 SYMBOL_ACTIVE :1;//symbol active statusuint_32 SYMBOL_INDEX :8; //data index in norflash,result is related to "xxx_BASE_ADDR"uint_32 reserved_2 :8;}SYMBOL_STRUCT, _PTR_ SYMBOL_STRUCT_PTR;
看下面运行结果:
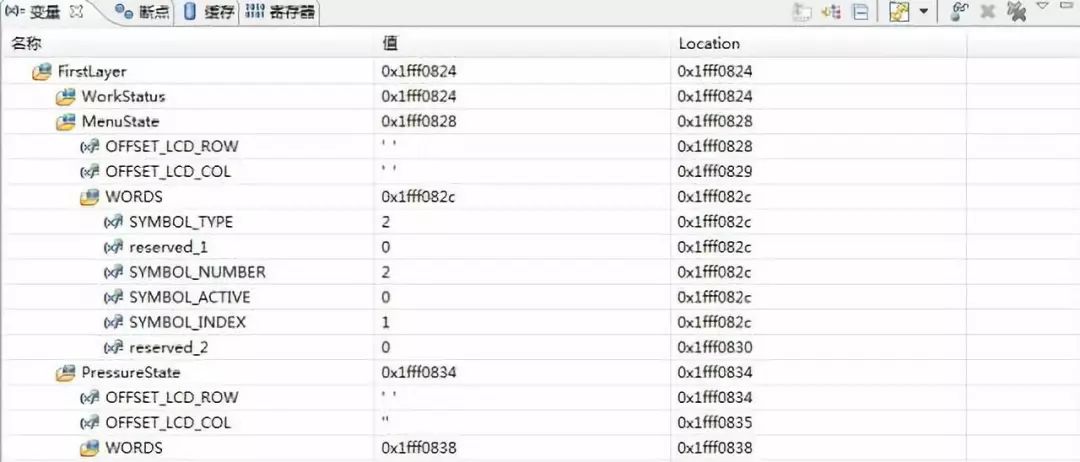
SYMBOL_TYPE 1个;reserved_1 1个;
SYMBOL_NUMBER+SYMBOL_ACTIVE 1个;
uint_32 reserved_2 : 8; 占用4个字节,估计是uint_32在起作用,而这里写的8位,只是我使用的有效位数,另外24位空闲,如果在下面再定义一个uint_32 reserved_3 : 8,地址也是一样的,都是以uint_32为单位取地址。
//data structure except for number structuretypedef struct symbol_struct{uint_8 SYMBOL_TYPE :5; //data type,have the affect on "data display type"uint_8 reserved_1 :4;uint_8 SYMBOL_NUMBER :7; //effective data number in one elementuint_8 SYMBOL_ACTIVE :1; //symbol active statusuint_8 SYMBOL_INDEX :8; //data index in norflash,result is related to "xxx_BASE_ADDR"uint_8 reserved_2 :8;}SYMBOL_STRUCT,_PTR_ SYMBOL_STRUCT_PTR;
地址数据如下:
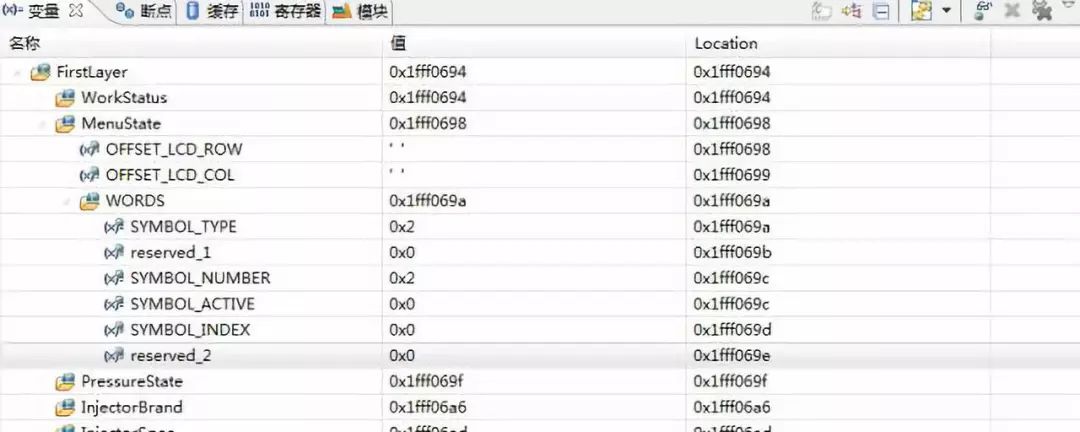
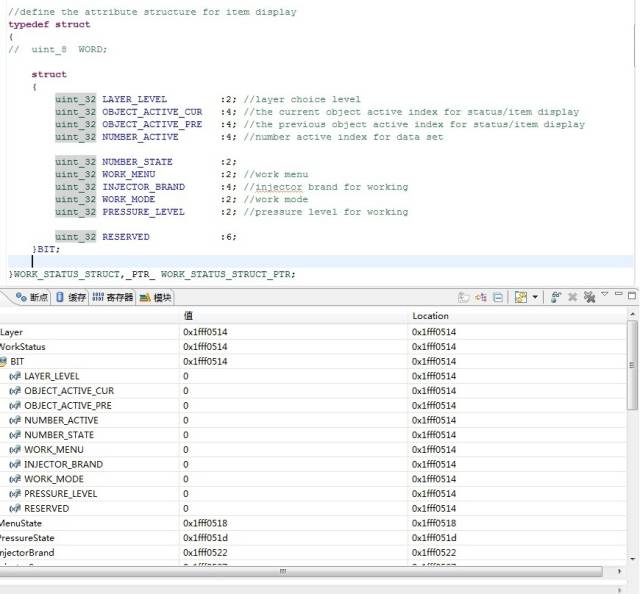
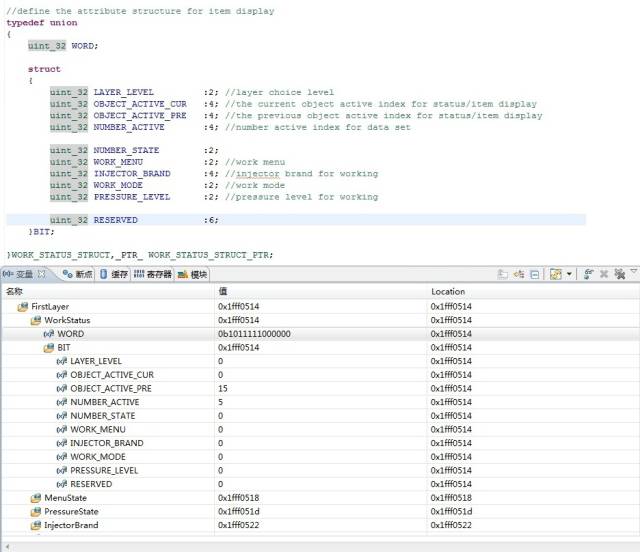
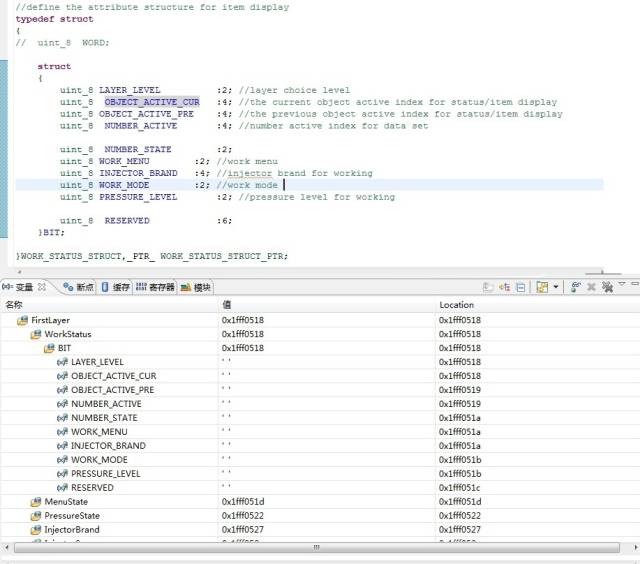

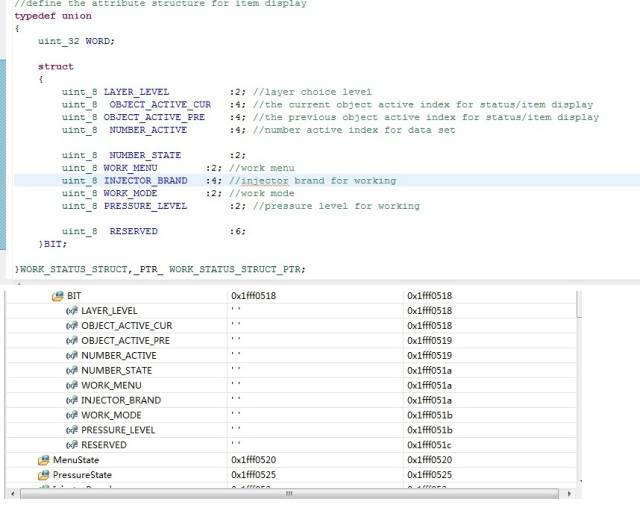
可以看到,系统并没有因为位结构体上面有uint_4的4字节变量或者共用体类型,就改变分配策略把位域都挤到4字节之内,看来他们是没有什么实质性联系的。这里把uint_32改成uint_8,或者把位结构体也替换掉,经我试验证明,都是没有任何影响的。
文章来源于网络,版权归原作者所有,如有侵权,请联系删除。

这是一口君的新书,感谢大家支持!
end
一口Linux
关注,回复【1024】海量Linux资料赠送
精彩文章合集
文章推荐
