今天和大家一起聊聊--服务器的多处理器架构,什么意思呢?
试想一下,假如一台高性能的服务器有4个CPU,64g的内存,还有一些总线、IO等资源,服务器内部这些资源是如何布局的呢?
本文并不会从逻辑电路、芯片设计、cpu历史等等角度去阐述,水平有限实战第一,通过本文你将了解到以下内容:

图1 英特尔代号为Cooper Lake的至强铂金9200处理器
该系列CPU物理封装长宽尺寸为76.0×72.5毫米,也是目前Intel史上最大的处理器,那CPU里面是什么样子呢?
CPU内部封装1个或者多个物理核,物理核有独立的各级缓存和电路结构,只有1个物理核心就是单核CPU,有多个物理核心就是多核CPU。

图2 4核CPU内部结构简图
对于处理器规格一致的服务器来说,总的物理核心数计算方法为:
物理核心数=总CPU数*单CPU中物理核心数
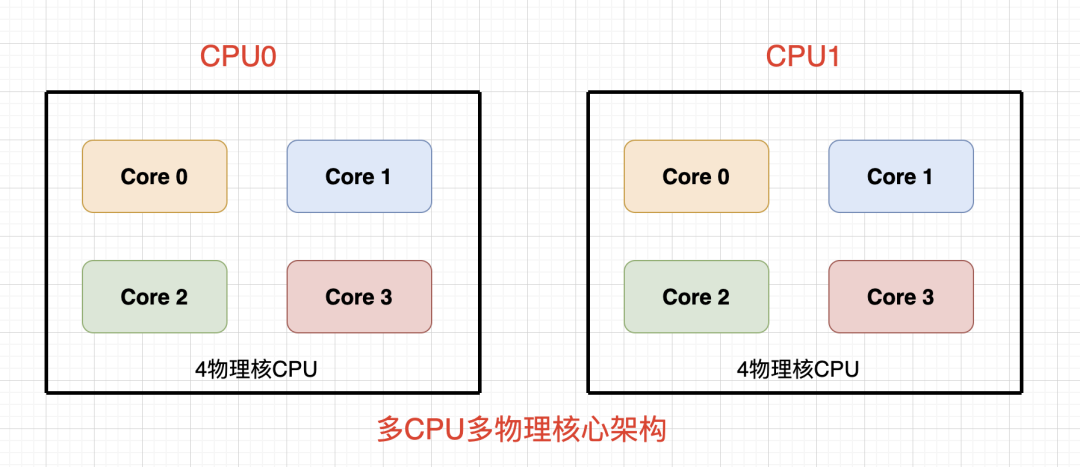
图3 多CPU多物理核简图
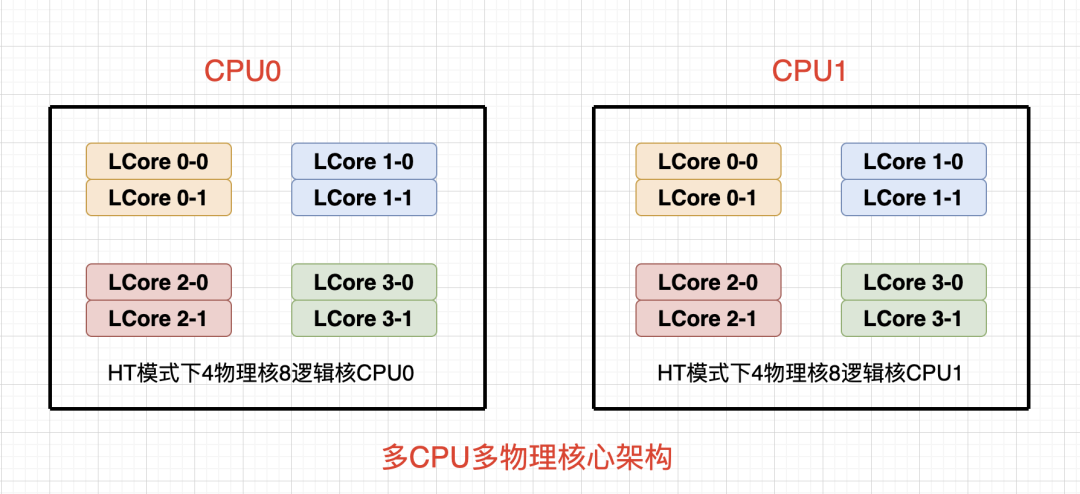
超线程是intel于2002年发布的一种技术,全名为Hyper-Threading,简写为HT技术,超线程技术最初只是应用于至强系列处理器中,之后陆续应用在奔腾系列中并将技术主流化,业界对于HT的评价不一,但是官方并未放弃超线程技术。
简单来说,HT技术可使处理器中的1颗物理核,如同2颗物理核那样发挥作用,从而提高了系统的整体性能,但是肯定也不会真的像2颗物理核那样,要不然就违背物理规律了,只是说借助于某些技术将1颗物理核的性能发挥地更好而已。
对于处理器规格一致的服务器来说,总的逻辑核心数计算方法为:
开启HT: 逻辑核心数=物理核心数=总CPU数*单CPU中物理核心数*2
未开启HT: 逻辑核心数=物理核心数=总CPU数*单CPU中物理核心数
掌握CPU&物理核心&逻辑核心三者的关系之后,可以找一台服务器看看相关配置,小试牛刀。
CPU多了就需要考虑如何设计,也就出现了几种不同的多处理器架构。
目前服务器大体可以分为三类:
对于我们来说,SMP和NUMA应该接触的比较多,MPP接触的少一些。
SMP是Symmetric Multi-Processor的缩写。
对称多处理器结构是指多个CPU对称平等,共享相同的物理内存/IO等资源,因此SMP结构属于一致存储器访问结构 UMA。
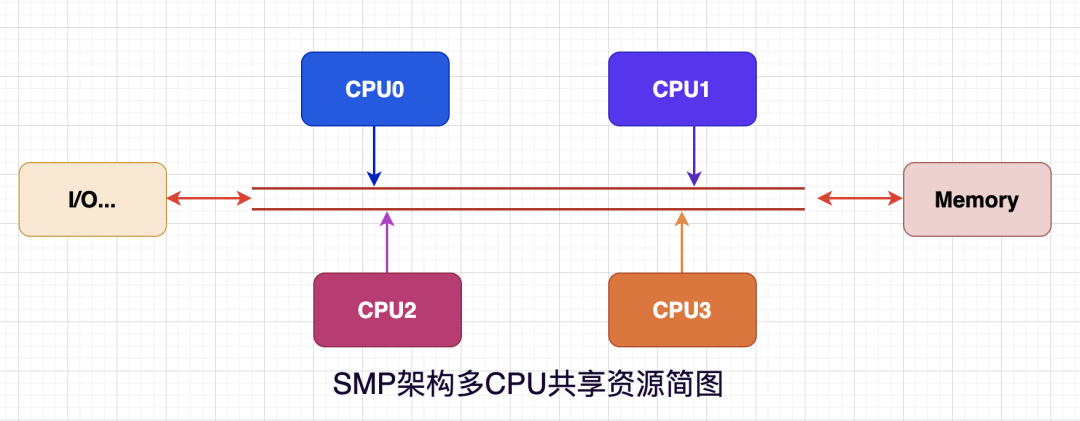
图5 SMP架构简图
共享模式下所有CPU平等地使用资源,模式简单,在CPU数量不多时效率很不错,但是优点也可能变为拦路虎。
试想一种场景如果在SMP模式下为了提高服务器的处理能力,我们水平扩展了CPU数量,这些CPU通过相同的总线访问内存。
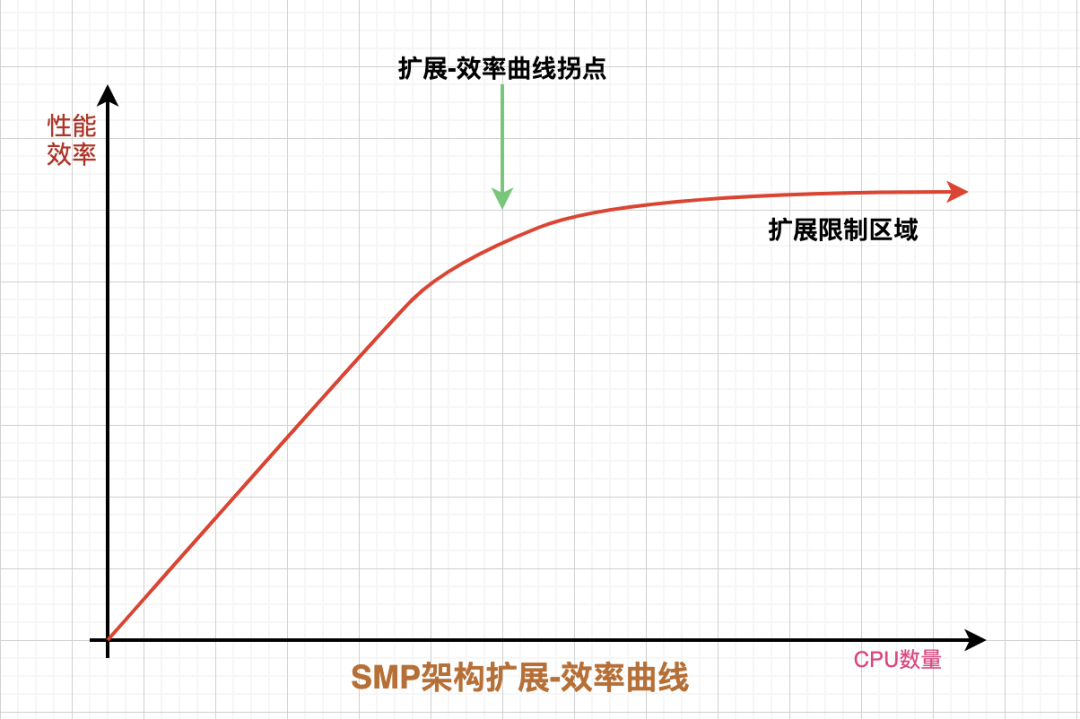
随着CPU数量的增加,相同内存地址访问冲突将明显增加,间接造成了CPU资源浪费,相关实验证明,SMP服务器最好的情况是2-4个CPU。
前面提到的SMP架构是一致存储器访问结构UMA,相对地就有了Non-Uniform Memory Access架构,所以NUMA结构和SMP架构的显著区别在于是否是一致对等访问内存。
NUMA架构的服务器具有多个 CPU 模块,每个 CPU 模块由多个 CPU组成,每个CPU模块具有独立的本地内存Local-Memory、 I/O等资源,可以将CPU模块称为Node。
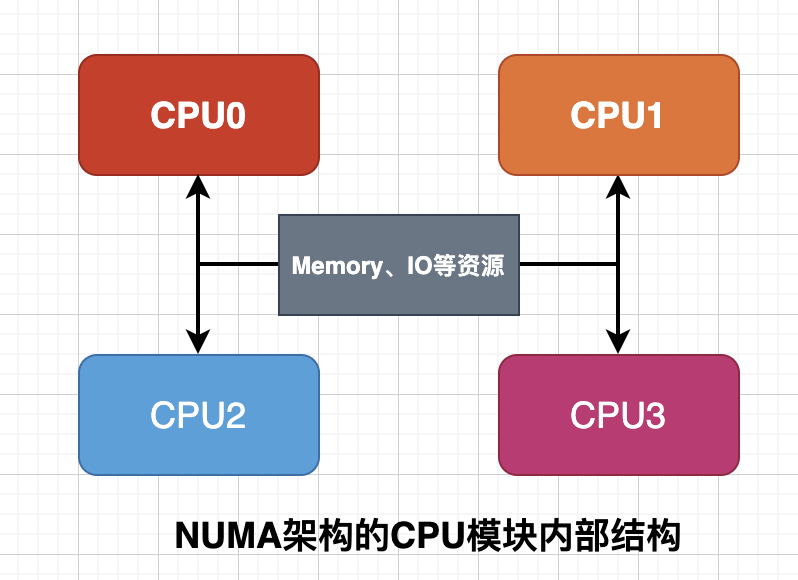
图7 NUMA架构CPU模块内部结构
Node之间可以通过互联模块进行数据交互,因此每个 CPU 模块仍然可以访问整个系统的内存,但是此时的内存有本地和外部之分了,访问速度自然也就不一样。
访问CPU模块的本地内存将远远快于访问其他CPU模块内存,在明确这种架构带来的内存访问差异后,我们在实际开发应用程序时需要尽量减少不同 CPU 模块之间的信息交互。
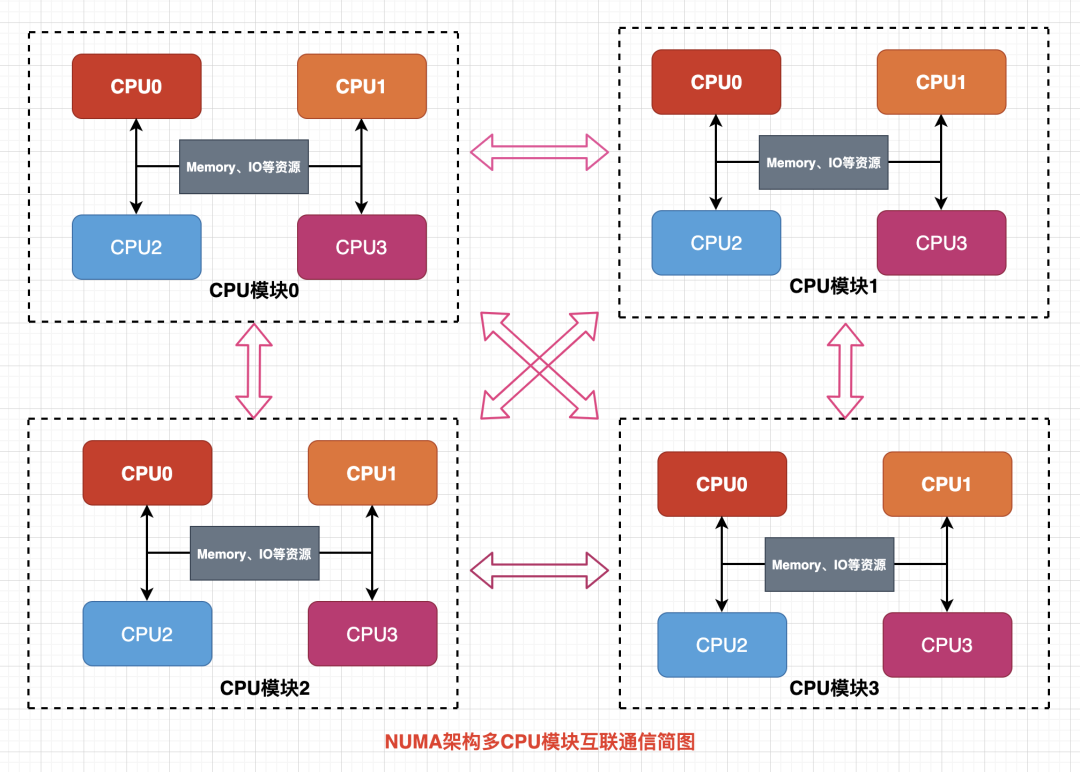
图8 NUMA架构整体简图
NUMA 技术同样有缺陷,由于访问远地内存的延时远远超过本地内存,当 CPU 数量增加时,系统性能无法线性增加,换句话说增加1倍的CPU数量并不能获得1倍的性能提升,因此仍然存在扩展限制区。
MPP是Massive Parallel Processing的缩写,MPP 是另外一种系统扩展的方式,它由多个 SMP 服务器通过一定的节点互联网络进行连接,完成相同的任务,可以看作是SMP的水平扩展。
在MPP结构中多个 SMP 服务器是一种完全无共享Share Nothing)结构,因而扩展能力最好,典型的就是刀片服务器,有的文章说MPP架构很像MapReduce模式,多个SMP服务器节点之间通过互联网络实现,目前并没有统一的数据通信协议,并且这部分交互协议对用户是无感知的。
MPP架构有点像刀片服务器的感觉,每一片都是独立的,片与片直接由特定的协议进行数据交互。
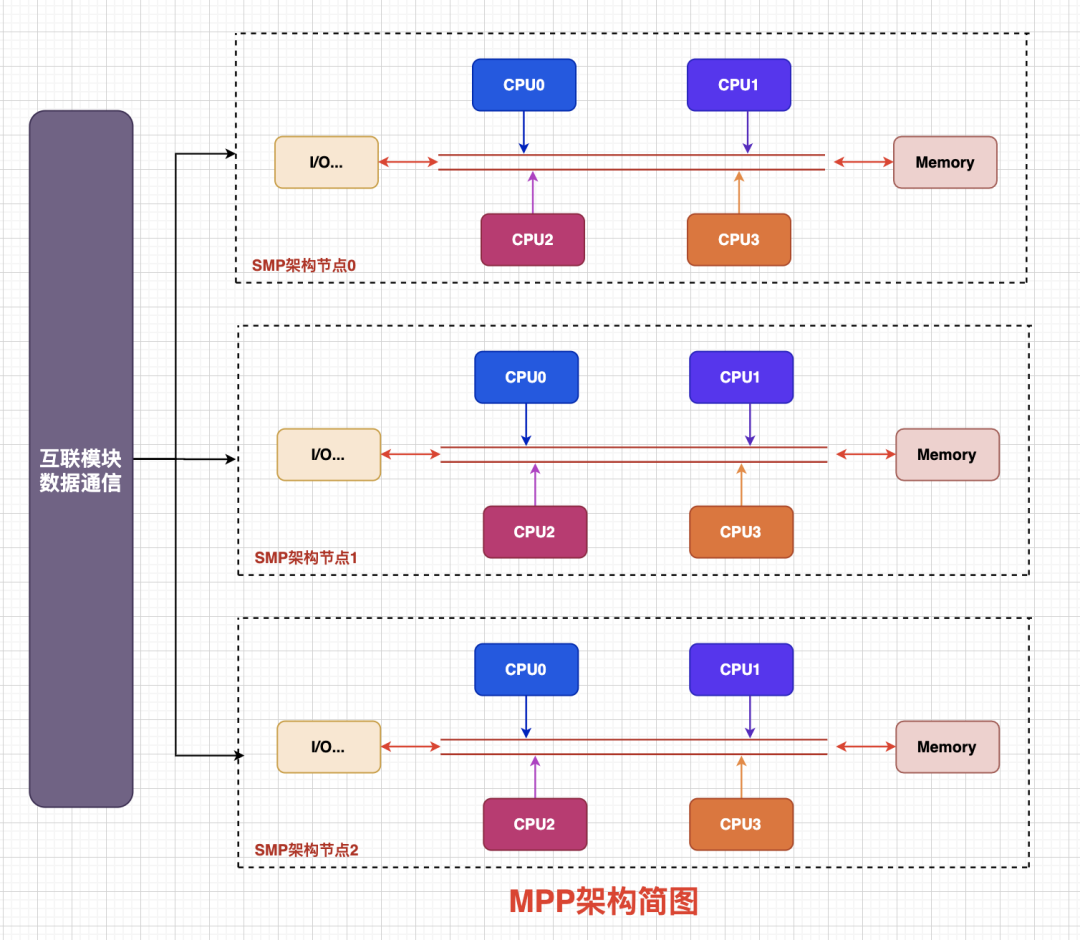
图9 MPP架构简图
本文的内容并不多,先阐述了一些关于CPU&物理核&逻辑核的常识,然后对多处理器服务器的常见的三种架构,每种架构都有不同的特定和使用场景,建议重点关注NUMA。
水文一篇,先到这里,感谢各位的倾情阅读。
END
→点关注,不迷路←
