

英特尔、AMD、英伟达这三大“芯片巨头”在GPU市场上的格局悄然发生变化。
英特尔已经涉足GPU领域数十年,从其首款 iGPU 到该公司如今在市场上推出当前专用显卡。它比其竞争对手 AMD 和英伟达领先多年,目前主要在低价格范围内与竞争对手竞争。
英特尔、AMD、英伟达三大GPU架构有何不同?

众所周知,英伟达使用所谓的 SM 或流式多处理器,而 AMD 称其为 CU 或计算单元。在英特尔的架构中,它可以在某些架构或矢量引擎上显示为执行单元或 EU 。
要了解 英特尔GPU 与其对手在组织或架构上的差异,有必要从这些执行单元开始,它们将是基本的着色器单元。这些单元被设计为小型处理器或矢量 FPU 单元以添加传输线脉冲发生器(TLP)。
也就是说,它们不仅仅是一个简单的计算单元,它们还有一些额外的组件,比如它们自己的控制单元,它们自己的寄存器,以及它们对应的执行单元。最终,它们更像是一个 CPU 内核,而不是一个简单的 FPU。事实上,我们可以看到在英特尔的架构中使用了4个FP32 FPU,即单精度浮点或32位,作为SIMD或向量单元工作。我们还有其他 4 个用于整数交换的 ALU,它们支持 SIMD over register。
由于它对寄存器进行操作,即计算单元被细分,因此每个时钟周期可以处理两倍的操作数。例如,可以使用 FP32,但也可以同时使用两个 FP16 或每个周期使用四个 FP8。这就是 Shader 程序的运行方式。
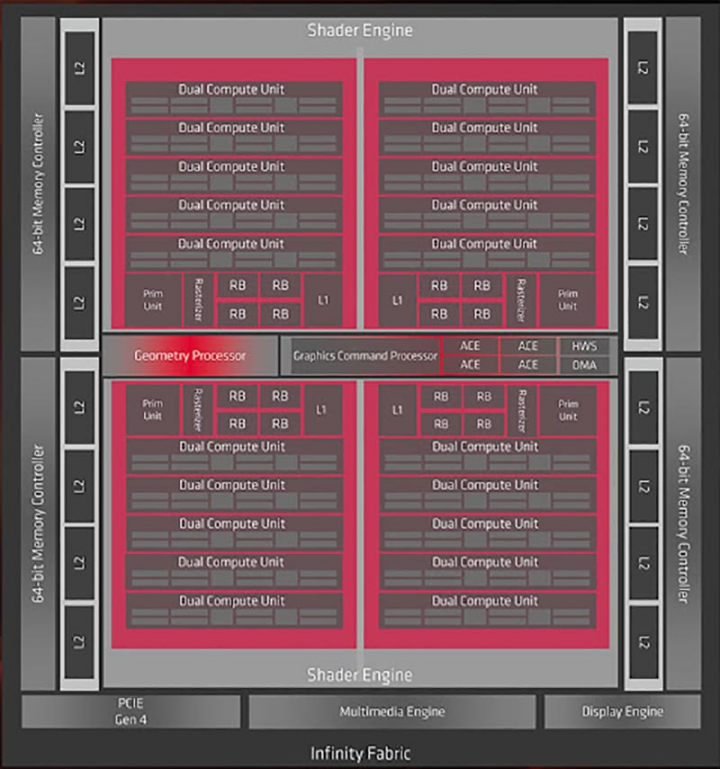
另一方面,Raja Koduri 对 英特尔Xe 的影响也很受欢迎。前者来自 AMD 的图形部门,在执行单元方面采用了与英特尔类似的理念,因为它们是双重的,并且每两个 EU 共享相同的控制单元。也就是说,与我们在 AMD 的 RDNA 架构中看到的非常相似,正如您在上一张图片中看到的那样。
至于英伟达,它的CUDA核心分别比英特尔和AMD的EUs和CUs简单得多,但包含了更多这样的单元。在英伟达的情况下,CUDA 基本上是着色器单元,基本上是 32 位浮点和整数单元:

正如我们在上一节中看到的,专门用于处理着色或着色器的执行单元被划分为子切片,它们在 英特尔Xe GPU 的 EU 内分组。
英特尔所说的子切片由内部的 16 个 EU 组成,对于 FP32 总共转换为 64 个 FPU,对于 32 为整数总共转换为 64 个 ALU。这使得这些子部分在原始功率方面类似于 AMD 计算单元。然而,它们并不完全是副本,英特尔GPU 处理的 ISA 将与 Radeon 的不同。

Sub-Slice或基本着色器单元内部是 GPU 中通常存在的部分,尽管英特尔使用与其竞争对手不同的命名法。例如,我们发现:
- 3D 采样器——这是一个经典的纹理操作和过滤单元,自第一个 3D 加速器出现以来就一直在使用。
- 媒体采样器——这个单元是英特尔 GPU 独有的,由固定功能计算单元组成。
- 视频运动引擎——该单元提供像素运动的估计,是视频编码的关键。
- Adaptive Video Scalar——是负责处理滤波器以使图像平滑的单元。
- 去噪/去隔行——在这种情况下,它是专注于降低图像噪声并将视频从隔行模式转换为逐行模式的单元。
在英特尔Xe中,GPU 架构的图片中可以看出,Media Sampler已经完全移除,成为一个单独的单元。这与英伟达和AMD的设计完全不同。在上图中,您可以看到英伟达将其许多 CUDA 内核捆绑到一个 SM 中,并将多个 SM 捆绑到它所谓的GPC中。也就是说,它们是图形处理集群。另一方面, AMD 将几个 CU 的分组称为Shader Engine,或着色引擎。但英特尔在其 Xe GPU 中打破了这一点,并使用了术语切片,这将是等价的。里面是英伟达和AMD通用的子切片和一些固定功能单元。但区别不仅在于英特尔使用的命名法,还有另一个细节将它们与英伟达和AMD区分开来。而且就是这两家公司用的是raster unit 和生成统一深度buffer的,在raster阶段,用的是common unit。相反,英特尔将这些驱动器解耦并单独放置。Pixel Dispatch 和 Pixel Back-End 也会发生类似的情况。在英特尔 GPU 的情况下,英伟达和 AMD架构的ROP 单元的这些功能也被分离为两个不同的元素。但是功能是一样的。最后,我们还必须详细介绍英特尔GPU缓存的层次结构。这也大大区分了英特尔 GPU 架构与英伟达和AMD的架构。众所周知,AMD 在 RDNA 2 中为 Radeon RX 6000 系列引入了 Infinity Cache,而英伟达在其 GeForce RTX 中也遵循了自己的理念。就AMD而言,如你所知,使用了三个缓存级别,一个L0,或者0级,一个L1,一个L2。在英伟达的情况下,我们有一个 L1 用于每个核心,然后是一个共享的 L2,不用多说,简化了这个内存的层次结构,虽然这既不好也不坏,每个核心都只是根据自己的特定架构进行修改。就英特尔而言,在这方面有所不同。在英特尔子段中,我们有 L1 数据缓存和共享本地内存。但是添加了一个额外的 L2 缓存,可以从 3D 采样器和媒体采样器访问它。这使得 L3 真正成为该 GPU 的顶级缓存。另一方面,用于为 EU 提供数据的 L1 缓存和用于纹理的 L2 缓存之间通常存在差异。与竞争对手相比,现在英特尔保持了完全标准的配置,这在英特尔之前推出的 GPU 架构中并非如此。LLC,在这种情况下是3 级或 L3 缓存,也与该公司以前的架构有所不同。如您所知,当前的 GPU 支持一种称为 Tiled Caching 的技术,该技术包括按图块或部分图像进行光栅化。这是在缓存的最后一级完成的,这就是英特尔选择显著扩展它的原因,但这是我们在 AMD 和英伟达上看不到的。当然,英特尔与 AMD 和英伟达也有其他细微差别,例如构建 GPU 芯片的节点、明显的晶体管数量、PCB、TDP、总线宽度等。但从广义上讲,它与竞争对手也有很多相似之处。在外部,我们看到 英特尔GPU板没有像英伟达和AMD那样的 AIB,但它们本身提供了一个独特的参考 PCB。另一方面,在这些独立显卡中集成的VRAM显存芯片,与AMD并没有太大的区别,因为使用了相同的GDDR6,以及其移动版中的英伟达独立GPU,因为PC的它们搭载GDDR6X。PCB 层面的组件也大同小异,除了 GPU 和 VRAM 芯片外,我们还发现了图形 BIOS等其他必不可少的单元。当然,使用的端口也是标准的,将卡连接到主板的接口也是标准的,也是 PCIe。来源:算力基建
免责声明:本文版权归原作者所有。本文所用视频、图片、文字如涉及作品版权问题,请第一时间告知,我们将根据您提供的证明材料确认版权并按国家标准支付稿酬或立即删除内容!本文内容为原作者观点,并不代表本公众号赞同其观点和对其真实性负责。








