
差不多整整三年前,即2020年5月12日时,我们分享了一篇有关100G开源网卡的文章《业界第一个真正意义上开源100 Gbps NIC Corundum介绍》。随后又陆陆续续分享了多次有关Corundum上板测试及仿真环境搭建的文章:《揭秘:普通电脑换上Xilinx Alveo U50 100G网卡传文件会有多快?》,《开源100 Gbps NIC Corundum环境搭建介绍(一)》和《开源100 Gbps NIC Corundum环境搭建介绍(二)仿真及工程恢复》。三年来,学术界发表了多篇依据该开源架构的论文,工业界也在该开源架构的基础上开发多种产品。我们在使用该开源项目的过程中,发现了该开源工程中也存在不少的问题,本着开源的精神,本文就把发现Corundum中部分问题的过程以及问题解决思路分享给大家,希望能够给大家带来帮助。本文作者是李钊同学,前面提到本公众号有关Corundum环境搭建文章的作者也是李钊。
Corundum是一个基于FPGA的开源NIC原型平台,用于高达100Gbps及更高的网络接口开发。Corundum平台包括一些用于实现实时,高线速操作的核心功能,包括:高性能数据路径,10G/25G/100G以太网MAC,PCIe gen3,自定义PCIe DMA引擎以及本机高精确的IEEE 1588 PTP时间戳。
我们基于Corundum这个灵活且强大的平台开发了一款网络加速器。如图所示,我们的设计(位于APP黄色部分)需要和原生数据流量共用一套DMA IF和主机HOST进行通信。紫色数据路径为用于DMA操作的自定义分段内存接口,连接着Corundum的高性能DMA引擎和分段存储器。

在我们的设计中,需要频繁的进行DMA读写操作。DMA操作大致有两种类型,一种是小数据包的DMA,长度在16B-64B之间,内容为硬件和主机通信的描述符,存放于Desc fetch和Cpl write模块内的描述符分段存储器;一种是大数据包的DMA,长度大于1kB,内容为传输数据,存放于APP下的数据分段存储器。
我们的设计通过了大量仿真,确认开发设计功能无误,随后开始上板测试。
我们的PCIe链路速率gen3 * 8,PCIe理论带宽为64G。在上板时出现了很奇怪的现象。
每次测试发送小数量级的请求时(<10000次,每次代表一次小数据包的DAM和一次大数据包的DMA),估算PCIe带宽在25G-35G左右。这种测试情况下不会发生错误,测试顺利通过。
当测试请求数量进一步增大时(>10万次),预估PCIe带宽在35G~40G。此时测试就会发生问题,整个系统瘫痪。
进一步定位问题,主机和FPGA还可以通过MMIO进行寄存器访问,但是DMA已经完全卡死。
在DMA IF下设置计数器用于统计DMA Read请求的个数和响应:
if( s_axis_read_desc_valid && s_axis_read_desc_ready ) begin
dma_read_req_cnt <= dma_read_req_cnt + 1'b1;
end
if( m_axis_read_desc_status_valid ) begin
dma_read_status_cnt <= dma_read_status_cnt + 1'b1;
end
上板debug信号,每次测试瘫痪后请求的个数总是大于响应的个数。

在Corundum中,DMA引擎是这样工作的:
DMA引擎接收来自用户的DMA Read请求,然后将DMA Read请求转换为PCIe Non-Posted 类型的mem read请求TLP包,然后等待mem read的Cpld返回报文,解析Cpld报文,将数据通过自定义分段内存接口存储至各级模块下的分段存储器中,存储完成后将回复DMA Read响应至用户。
结合对DMA 引擎的理解,可以推测有以下几个可能导致响应个数不够
PCIe IP错误导致rd tlp或cpld丢失;
DMA引擎因返回cpld携带错误而丢弃cpld;
DMA引擎因PCIe流控发生不可预知的错误,随机丢弃数据包;
其他原因;
分析原因:
PCIe IP为Xilinx UltraScale+ Integrated Block(PCIE4C) for PCI Express,成熟的商用IP经过了大规模验证和使用一般不会出现问题,可以暂且排除因素1。
抓取相关的错误信号(rx_cpl_tlp_error、status_error_cor、status_error_uncor),结果表明PCIe并未发生可纠正/不可纠正的错误类型,表示通信双方链路正常,并没有因为错误而丢弃报文导致响应的数量不够,可以排除因素2。
首先Corundum是一款100Gbps速率的网卡设计,经过了大量验证和上板测试;其次测试的PCIe理论带宽为64Gbps。而此时的测试带宽35G~40G远远不足s设计带宽或是链路带宽上限,应该不会触发流控机制。这里因素三也需要被排除。
最了解自己设计的一定是作者本人。我随后在Zulip上求助了作者,希望他可以帮我想一想导致此问题其他有可能的因素。
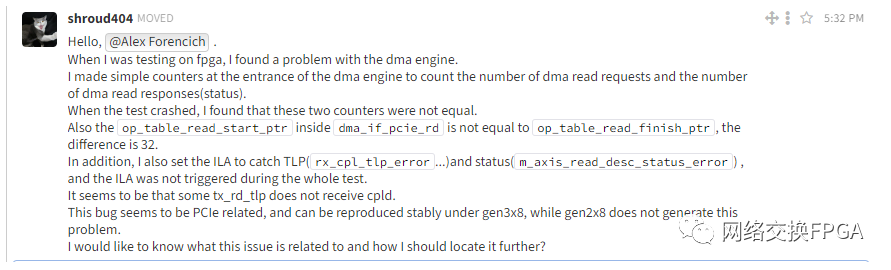
Alex很热心,对每个问题都会做出回复。

他表示这种问题很难定位,需要精确的定位“案发现场”才有可能定位问题。
我可以确保每次DMA操作的地址和长度都是合理的,并且由于mem read tlp为Non-Posted类型,因此需要等待一定的PCIe链路时延才能得到返回报文。这两项特质决定了很难定位至发生错误的DMA操作,无法恢复到错误发生的那一时刻。
他告诉了我一种定位的手段:
设置足够深的ILA缓冲,用计数器扩展以检测挂起:基本上,在每个周期递增,但如果计数一致或有响应,则重置;然后将该计数器输入ILA;并触发各种计数器值。注意:触发器位置靠近缓冲器末端。
基于此思路,我做出了以下设置:
设置ILA深度至8192,并且调整每次DMA Read的长度为4K,确保能够在ILA深度内抓到完整的DMA操作。
dma_read_cycle_cnt作为需要触发的计数/时器,没收到一个DMA Read请求开始随时钟周期自增,收到DMA Read请求响应清零;dma_read_cycle_max_cnt用来记录正常情况下Non-Posted完成的最大计数值。将触发条件设置为dma_read_cycle_cnt > dma_read_cycle_max_cnt,这样就可以触发到模块出错的时刻。调整dma_read_cycle_max_cnt触发条件,逐步逼近出错时刻。
if(m_axis_read_desc_status_valid)begin
dma_read_cycle_cnt <= 32'b0;
end else if(s_axis_read_desc_valid && s_axis_read_desc_ready)begin
dma_read_cycle_cnt <= 32'b1;
end else if(dma_read_cycle_cnt >= 1'b1)begin
dma_read_cycle_cnt <= dma_read_cycle_cnt + 1'b1;
end else begin
dma_read_cycle_cnt <= dma_read_cycle_cnt;
end
if(m_axis_read_desc_status_valid && (dma_read_cycle_cnt[23:0] > dma_read_cycle_max_cnt))begin
dma_read_cycle_max_cnt <= dma_read_cycle_cnt;
end else begin
dma_read_cycle_max_cnt <= dma_read_cycle_max_cnt;
end
同时,在ILA内抓取一些相关的重要信号:基本的握手信号和相关流控信号。
外加统计read tlp的请求数据长度累计和返回cpld的数据长度累计。
按照触发设置,终于在ILA中捕获到“案发现场”。
某个时刻,握手信号rx_cpl_tlp_ready不再置1,但rx_cpl_tlp_valid还存在。表明DMA引擎出现了问题,无法再接收返回的cpld报文。

也就是从此刻开始,DMA Read请求的个数在一直增加,但是DMA Read响应的个数却不再增长。

定位到了出错时刻,此时便可以对模块内的重点信号展开分析。
前文已经去除掉了面向HOST的种种因素,因此最有可能出问题的地方只能是面向用户的用于DMA操作的自定义分段内存接口。
这里的分段内存接口是Corundum独特的体系结构的一种,对于PCIe上的高性能DMA,Corundum使用自定义分段存储器接口。该接口被分成最大512位的段,并且整体宽度是PCIe硬IP内核的AXI流接口宽度的两倍。例如,将PCIe Gen 3 x16与PCIe硬核中的512位AXI流接口一起使用的设计将使用1024位分段接口,该接口分成2个段,每个段512位。与使用单个AXI接口相比,该接口提供了改进的“阻抗匹配”,从而消除了DMA引擎中的对齐和互连逻辑中的仲裁,从而消除了背压,从而提高了PCIe链路利用率。具体地说,该接口保证DMA接口可以在每个时钟周期执行全宽度,未对齐的读取或写入。此外,使用简单的双端口RAM(专用于在单个方向上移动的流量)消除了读写路径之间的争用。
在自定义分段内存接口中,使用ram_wr_cmd_sel路由和复用。基于单独的选择信号而不是通过地址解码进行路由的。此功能消除了分配地址的需要,并允许使用可参数化的互连组件,这些组件以最少的配置适当地路由操作。
output wire [RAM_SEG_COUNT*RAM_SEL_WIDTH-1:0] ram_wr_cmd_sel,
output wire [RAM_SEG_COUNT*RAM_SEG_BE_WIDTH-1:0] ram_wr_cmd_be,
output wire [RAM_SEG_COUNT*RAM_SEG_ADDR_WIDTH-1:0] ram_wr_cmd_addr,
output wire [RAM_SEG_COUNT*RAM_SEG_DATA_WIDTH-1:0] ram_wr_cmd_data,
output wire [RAM_SEG_COUNT-1:0] ram_wr_cmd_valid,
input wire [RAM_SEG_COUNT-1:0] ram_wr_cmd_ready,
input wire [RAM_SEG_COUNT-1:0] ram_wr_done,
DMA Read引擎使用分段内存的写入接口,将获取的cpld数据写入分段存储器中。使用ram_wr_cmd_sel决定写入哪个分段存储器,使用ram_wr_cmd_addr决定写入分段存储器的地址,使用ram_wr_done判断写入操作完成。
同样为分段内存接口设置计数器,用于统计分段内存接口的写入和写入完成操作。
if(ram_wr_cmd_valid[0] && ram_wr_cmd_ready[0])begin
dpram_wr_cmd_cnt0 <= dpram_wr_cmd_cnt0 + 1'b1;
end
if(ram_wr_cmd_valid[1] && ram_wr_cmd_ready[1])begin
dpram_wr_cmd_cnt1 <= dpram_wr_cmd_cnt1 + 1'b1;
end
if(ram_wr_done[0])begin
dpram_wr_done_cnt0 <= dpram_wr_done_cnt0 + 1'b1;
end
if(ram_wr_done[1])begin
dpram_wr_done_cnt1 <= dpram_wr_done_cnt1 + 1'b1;
end
问题就出现在这里:

在“案发时刻”之后,分段内存接口处不再有写入完成信号ram_wr_done。可以证明问题就出在这里,不再有内存写入完成信号,导致DMA IF迟迟无法确认数据操作完成,进而导致无法接收新的Cpld报文数据(防止数据覆盖)。
进一步分析“案发时刻”之前分段内存接口的所有波形,终于在某个时刻找到了异样。在此时刻,分段存储器的地址不再是线性增加,发生了跳变,执行完0地址的写入之后再恢复正常。

与DMA Read操作关联起来,并且充分考虑到Non-Posted操作的PCIe链路时延,从“案发时刻”之前的13次DMA Read删选出出错的那一次DMA Read操作。
首先进行了一个4kB的大DMA Read操作;
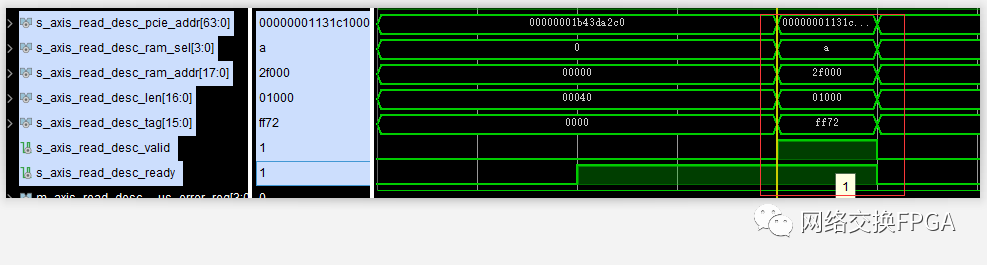
随后便是一个64B的小DMA Read操作:
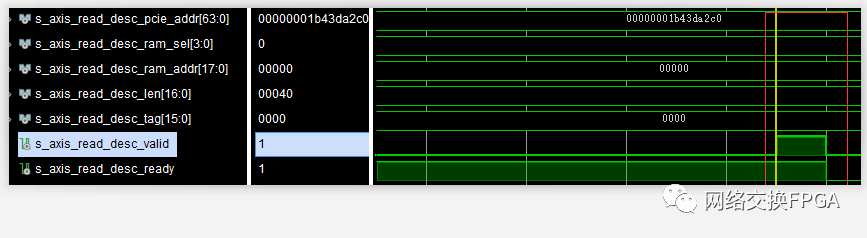
所以按理来说,分段内存应该先执行完4kB的数据写入操作之后,再进行64B的数据写入操作。
但抓取到的波形却显示数据写入操作地址发生了跳变,0x5fc -> 0x000 -> 0x5fd。
而这正是触发测试错误的条件:两次mem rd tlp的cpld碰巧发生了交织,或者说发生了乱序。小数据包的cpld超越了部分大数据包的cpld,先一步通过PCIe链路传送至硬件。这种完成报文之间的乱序恰巧是PCIe协议所允许的,用于保证生产者/消费者模型的正确运转,防止死锁的发生。
如果完成报文与之前的完成报文的Transaction ID不同,该报文可以超越之前的完成报文;如果相同,则不能超越。这里恰巧是两个连续的不同DMA Read操作,Transaction ID的tag必不相同,所以乱序是会发生的。
在仿真中,将“案发时刻”前后的波形文件csv导入仿真环境,或者直接使用force-release强制激励即可恢复案发现场。
通过在仿真中检查,很快便定位到是最近一级的dma_mux模块出现了问题,它会在这种情况下丢弃1-2个ram_wr_done。这有可能是每个分段存储器的写入路径时延不同,导致done信号同时到达mux模块或者是mux模块因为被占用而无法处理某一个分段存储器的写入完成,导致done信号丢失。

随后询问了Alex我的想法是否正确:
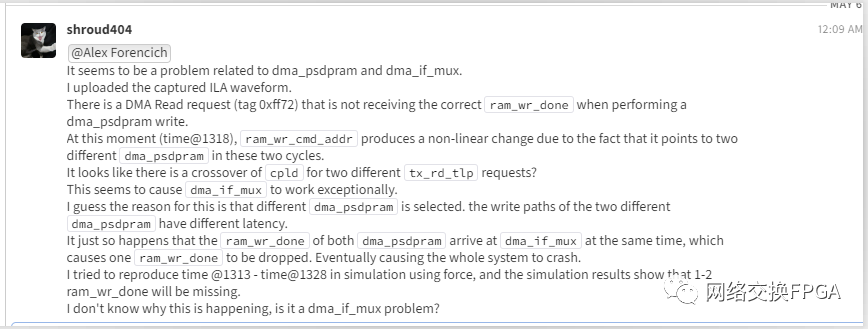
他表示编写mux时使用fifo和计数器来捕获所有的done脉冲信号,并按正确的顺序转发,但似乎存在一个bug。
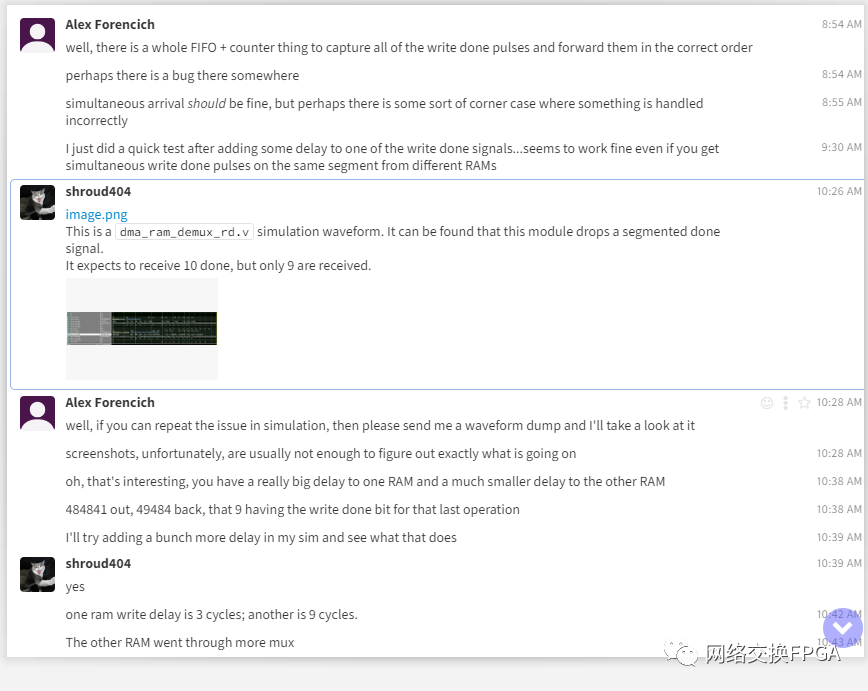
随后也证明确实是dma_ram_demux_wr这个模块存在问题:

Alex随后进行了BUG修改。对输入dma_ram_demux_wr的完成的done信号加入双向确认机制,确保不会遗漏任何done信号。
将修改完的代码进行了仿真测试,随后也通过了FPGA上板测试。
错误的触发条件:两次mem rd tlp的cpld发生乱序。小数据包的cpld超越了部分大数据包的cpld,先一步通过PCIe链路传送至硬件。
错误原因:dma_ram_demux_wr因为ram_wr_done输入拥塞而丢失了分段内存接口的写入完成信号ram_wr_done。
进一步分析:为什么Corundum跑到100G带宽下都不会出现此问题?
Corundum下DMA的自定义分段内存接口拓扑如图所示:
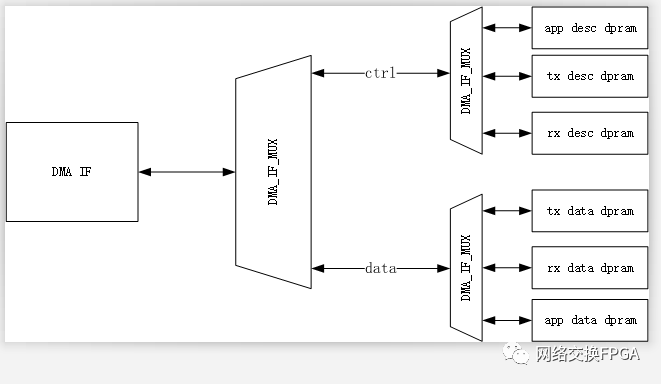
在Corundum的架构下,DMA IF 到所有分段存储器的写入路径延迟是一致的,因此即使发生了cpld乱序,dma_ram_demux_wr也不会因为ram_wr_done输入拥塞而丢失done个数。
在我们的设计中,在APP下仍会进行若干级的DAM MUX将DMA引擎进一步复用。
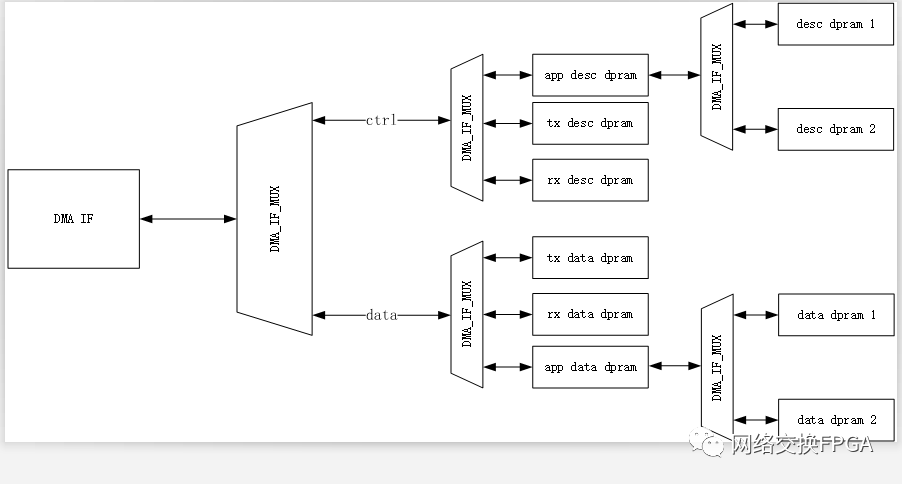
这样就会导致存在两个分段存储器的写入路径延迟不一致,进一步导致在dma_ram_demux_wr写入完成接口处发生争用导致ram_wr_done丢失。
补充:修改完此BUG之后,每级dma_if_mux会引入一拍额外的时延(用于双向确认),因此会对DMA引擎的性能造成一定影响。为消除此影响,可以将dma_if_pcie_rd模块下的参数STATUS_FIFO_ADDR_WIDTH和OUTPUT_FIFO_ADDR_WIDTH由5扩大为6,使用更多资源来抵消额外的时延影响。
作者:李钊
责任编辑:潘伟涛
