


参考文献
[1] Z. Chen, A. Li, X. Qiu, W. Yuan, and Q. Ge, “Survey of environment visual perception for intelligent vehicle and its supporting key technologies,” J. Hebei Univ. Sci. Technol,vol. 40, 15-23, 2019.
[2] Shengbo Eben Li, Reinforcement Learning for Sequential Decision and Optimal Control. Singapore: Springer Verlag, 2023.
[3] J. Lin, S. Sedigh, and A. Miller, “Modeling Cyber-Physical Systems with Semantic Agents,” in IEEE 34th Annual Computer Software and Applications Conference workshops (COMPSAC-W), 2010: 19 - 23 July 2010, Seoul, Korea ; proceedings, 2010,pp. 13–18.
[4] J. Yao, “Digital image compression arithmetic based on the discrete Fourier transform,”Journal of Shaanxi University of Technology, vol. 28, pp. 22–26, 2012.
[5] E. Elharar, A. Stern, O. Hadar, and B. Javidi, “A Hybrid Compression Method for Integral Images Using Discrete Wavelet Transform and Discrete Cosine Transform,” J.Display Technol., vol. 3, no. 3, pp. 321–325, 2007.
[6] H. Zhang and X. Zhang, “Research on arithmetic of the number theorytransformation(NTT) applied in the image compression,” J. China Coal Soc., vol. 25,pp. 158–164, 2000.
[7] W. Zheng and Y. Piao, “Research on integral (3D) image compression technology based on neural network,” in 5th International Congress on Image and Signal Processing (CISP), 2012: 16-18 Oct. 2012, CQUPT, Chongqing, China, 2012, pp. 382–386.
[8] S. G. Mallat, “A theory for multiresolution signal decomposition: the wavelet representation,” IEEE Trans. Pattern Anal. Machine Intell., vol. 11, no. 7, pp. 674–693,1989.
[9] W. M. Lawton, “Tight frames of compactly supported affine wavelets,” Journal of Mathematical Physics, vol. 31, no. 8, pp. 1898–1901, 1990.
[10] L. ChaoFeng et al., “Research on fuzzy image enhancement and restoration effect,” in First International Conference on Electronics Instrumentation & Information Systems (EIIS 2017): June 3-5, Harbin, China, 2017, pp. 1–4.
[11] M. Tico and K. Pulli, “Image enhancement method via blur and noisy image fusion,” in 16th IEEE International Conference on Image Processing (ICIP), 2009: 7-10 Nov. 2009,Cairo, Egypt ; proceedings, 2009, pp. 1521–1524.
[12] L. Chong-Yi, G. Ji-Chang, C. Run-Min, P. Yan-Wei, and W. Bo, “Underwater Image Enhancement by Dehazing With Minimum Information Loss and Histogram Distribution Prior,” IEEE transactions on image processing : a publication of the IEEE Signal Processing Society, vol. 25, no. 12, pp. 5664–5677, 2016.
[13] X. M. Li, “Image enhancement in the fractional Fourier domain,” in 2013 6thInternational Congress on Image and Signal Processing (CISP), 2013, pp. 299–303.
[14] Y. Xian and Y. Tian, “Robust internal exemplar-based image enhancement,” in 2015 IEEE International Conference on Image Processing (ICIP), 2015, pp. 2379–2383.
[15] S. S. Agaian, B. Silver, and K. A. Panetta, “Transform coefficient histogram-based image enhancement algorithms using contrast entropy,” IEEE transactions on image processing : a publication of the IEEE Signal Processing Society, vol. 16, no. 3, pp.741–758, 2007.
[16] S. Song and T. Gao, “Research on image segmentation algorithm based on threshold,” in 2021 13th International Conference on Measuring Technology and Mechatronics Automation: ICMTMA 2021 : proceedings : Beihai, China, 16-17 January 2021, 2021,pp. 306–308.
[17] Y. Zhang and Z. Xia, “Research on the Image Segmentation Based on Improved Threshold Extractions,” in Proceedings of 2018 IEEE 3rd International Conference on Cloud Computing and Internet of things: CCIOT 2018 : October 20-21, 2018, Dalian,China, 2018, pp. 386–389.
[18] N. Zhao, S.-K. Sui, and P. Kuang, “Research on image segmentation method based on weighted threshold algorithm,” in 2015 12th International Computer Conference on Wavelet Active Media Technology and Information Processing (ICCWAMTIP), Dec.2015 - Dec. 2015, pp. 307–310.
[19] A. Troya-Galvis, P. Gançarski, and L. Berti-Équille, “A Collaborative Framework for Joint Segmentation and Classification of Remote Sensing Images,” in Studies in computational intelligence, 1860-949X, volume 732, Advances in knowledge discovery and management. Volume 7, Cham, Switzerland, 2018, pp. 127–145.
[20] D. Fu, H. Chen, Y. Yang, C. Wang, and Y. Jin, “Image Segmentation Method Based on Hierarchical Region Merging's NCUT,” in 2018 15th International Computer Conference on Wavelet Active Media Technology and Information Processing (ICCWAMTIP): Conference venue: University of Electronic Science and Technology of China, Sichuan Province, China, conference dates: Dec. 14-16 2018, 2018, pp. 63–68.
[21] G. Huang and C.-M. Pun, “Interactive Segmentation Based on Initial Segmentation and Region Merging,” in 2013 10th International Conference Computer Graphics, Imaging and Visualization, 2013, pp. 52–55.
[22] X. Li and L. Lu, “An Improved Region Growing Method for Segmentation,” in 2012 International Conference on Computer Science and Service System: CSSS 2012 : 11-13 August 2012 : Nanjing, China : proceedings, 2012, pp. 2313–2316.
[23] P. Sun and L. Deng, “An image fusion method based on region segmentation and wavelet transform,” in 20th International Conference on Geoinformatics (GEOINFORMATICS), 2012, Jun. 2012 - Jun. 2012, pp. 1–5.
[24] S. Qiang, L. Guoying, M. Jingqi, and Z. Hongmei, “An edge-detection method based on adaptive canny algorithm and iterative segmentation threshold,” in ICCSSE:Proceedings of 2016 2nd International Conference on Control Science and SystemsEngineering : July 27-29, 2016, Singapore, 2016, pp. 64–67.
[25] K. Strzecha, A. Fabijanska, and D. Sankowski, “Application Of The Edge-Based Image Segmentation,” in Proceedings of the 2nd International Conference on PerspectiveTechnologies and Methods in MEMS Design, 2006, pp. 28–31.
[26] L. Xiang, W. Xiaoqing, and Y. Xiong, “Remaining edges linking method of motion segmentation based on edge detection,” in 9th International Conference on Fuzzy Systems and Knowledge Discovery (FSKD), 2012, May. 2012 - May. 2012, pp. 1895–1899.
[27] E. Saber, A. M. Tekalp, and G. Bozdagi, “Fusion of color and edge information for improved segmentation and edge linking,” in The 1996 IEEE international conference on acoustics, speech, and signal processing, 1996, pp. 2176–2179.
[28] G. Hao, L. Min, and H. Feng, “Improved Self-Adaptive Edge Detection Method Based on Canny,” in International conference on intelligent human-machine systems and cybernetics, 2013, pp. 527–530.
[29] A. Rosenfeld, “The Max Roberts Operator is a Hueckel-Type Edge Detector,” IEEE transactions on pattern analysis and machine intelligence, vol. 3, no. 1, pp. 101–103,1981.
[30] N. R. Pal and S. K. Pal, “A review on image segmentation techniques,” Pattern Recognition, vol. 26, no. 9, pp. 1277–1294, 1993.
[31] T. Sanida, A. Sideris, and M. Dasygenis, “A Heterogeneous Implementation of the Sobel Edge Detection Filter Using OpenCL,” in 2020 9th International Conference on Modern Circuits and Systems Technologies (MOCAST), 2020, pp. 1–4.
[32] L. Pei, Z. Xie, and J. Dai, “Joint edge detector based on Laplacian pyramid,” in 3rd International Congress on Image and Signal Processing (CISP), 2010: 16-18 Oct. 2010,Yantai, China ; proceedings, 2010, pp. 978–982.
[33] Satinder Chopra and Vladimir Alexeev, “Application of texture attribute analysis to 3D seismic data,” SEG Technical Program Expanded Abstracts 2005, vol. 25, no. 8, pp.767–770, 2005.
[34] J. Li, “Application of Various Cameras in L3 Level Autonomous Driving Visual Perception,” Auto Electric Parts, vol. 8, pp. 11–12, 2019.
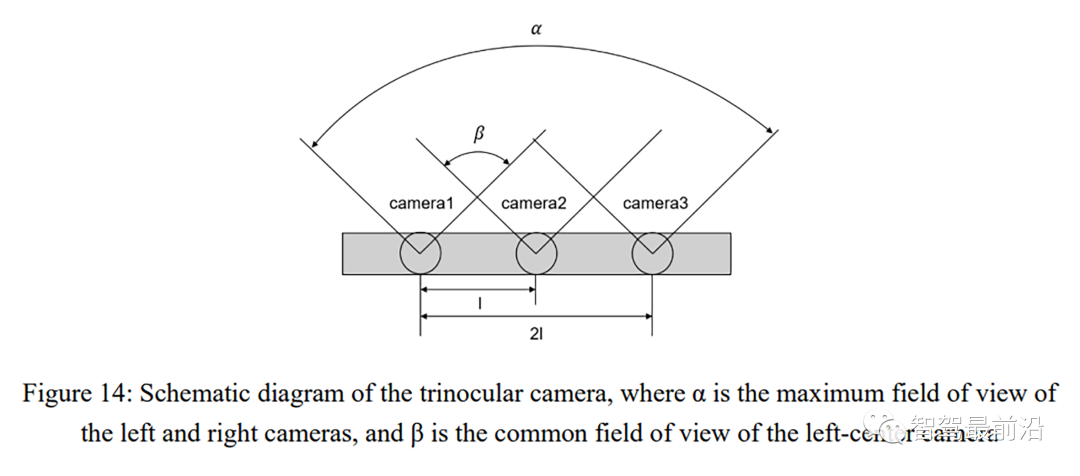
[35] J. Wang and H. Liu, “Vehicle navigation method based on trinocular vision,” Journal of Computer Applications, vol. 34, pp. 1762–1773, 2014.
[36] D. Seo, H. Park, K. Jo, K. Eom, S. Yang, and T. Kim, “Omnidirectional stereo vision based vehicle detection and distance measurement for driver assistance system,” in IECON 2013: 39th annual conference of the IEEE Industrial Electronics Societ ; 10-13 Nov. 2013, Vienna, Austria ; proceedings, 2013, pp. 5507–5511.
[37] J. Niu, J. Lu, M. Xu, P. Lv, and X. Zhao, “Robust Lane Detection using Two-stage Feature Extraction with Curve Fitting,” Pattern Recognition, vol. 59, pp. 225–233,2016.
[38] M. S. Sravan, S. Natarajan, E. S. Krishna, and B. J. Kailath, “Fast and accurate on-road vehicle detection based on color intensity segregation,” Procedia Computer Science,vol. 133, pp. 594–603, 2018.
[39] M. Anandhalli and V. P. Baligar, “A novel approach in real-time vehicle detection and tracking using Raspberry Pi,” Alexandria Engineering Journal, vol. 57, no. 3, pp. 1597–1607, 2018.
[40] A. R. Webb, Statistical pattern recognition. London: Arnold, 1999.
[41] B. W. White and F. Rosenblatt, “Principles of Neurodynamics: Perceptrons and the Theory of Brain Mechanisms,” The American Journal of Psychology, vol. 76, no. 4, p.705, 1963.
[42] L. Chen and K.-H. Yap, “A fuzzy K-nearest-neighbor algorithm to blind image deconvolution,” in System security and assurance, 2003, pp. 2049–2054.
[43] B. D. Maciel and R. A. Peters, “A comparison of neural and statistical techniques in object recognition,” in 2000 IEEE international conference on systems, man and cybernetics, 2000, pp. 2833–2838.
[44] K. Kato, M. Suzuki, Y. Fujita, and F. Y, “Image synthesis display method and apparatus for vehicle camera,” U.S. Patent 7 139 412 B2, Nov 21, 2006.
[45] J. Zhang, Z. Liu, Z. Qi, and Y. Ma, “Development of the Adaptive Cruise Control for Cars,” Vehicle & Power Technology, vol. 2, pp. 45–49, 2003.
[46] C.-L. Su, C.-J. Lee, M.-S. Li, and K.-P. Chen, “3D AVM system for automotive applications,” in 2015 10th International Conference on Information, Communications and Signal Processing (ICICS): 2-4 Dec. 2015, 2015, pp. 1–5.
[47] Z. Zhang, “Flexible camera calibration by viewing a plane from unknown orientations,”in The proceedings of the seventh IEEE international conference on computer vision,1999, 666-673 vol.1.
[48] Y. I. Abdel-Aziz and H. M. Karara, “Direct Linear Transformation from Comparator Coordinates into Object Space Coordinates in Close-Range Photogrammetry,”photogramm eng remote sensing, vol. 81, no. 2, pp. 103–107, 2015.
[49] R. Tsai, “A versatile camera calibration technique for high-accuracy 3D machine vision metrology using off-the-shelf TV cameras and lenses,” IEEE J. Robot. Automat., vol. 3,no. 4, pp. 323–344, 1987.
[50] D. Scaramuzza, A. Martinelli, and R. Siegwart, “A Flexible Technique for Accurate Omnidirectional Camera Calibration and Structure from Motion,” in IEEE International Conference on Computer Vision Systems, 2006: ICVS '06 ; 04 - 07 Jan. 2006, [NewYork, New York], 2006, p. 45.
[51] X. Ren and Z. Lin, “Linearized Alternating Direction Method with Adaptive Penalty and Warm Starts for Fast Solving Transform Invariant Low-Rank Textures,” Int J Comput Vis, vol. 104, no. 1, pp. 1–14, 2013.
[52] D. G. Lowe, “Distinctive Image Features from Scale-Invariant Keypoints,” Int J Comput Vis, vol. 60, no. 2, pp. 91–110, 2004.
[53] L. Zhu, Y. Wang, B. Zhao, and X. Zhang, “A Fast Image Stitching Algorithm Based on Improved SURF,” in 2014 Tenth International Conference on Computational Intelligence and Security, 2014, pp. 171–175.
[54] Q. Liu, “Research on the Around View Image System of Engineering Vehicle,” China University of Mining and Technology, Xuzhou, Jiangsu, 2017.
[55] A. Krizhevsky, I. Sutskever, and G. E. Hinton, “ImageNet classification with deep convolutional neural networks,” Commun. ACM, vol. 60, no. 6, pp. 84–90, 2017.
[56] G. E. Hinton and R. R. Salakhutdinov, “Reducing the dimensionality of data with neural networks,” Science (New York, N.Y.), vol. 313, no. 5786, pp. 504–507, 2006.
[57] J. Long, E. Shelhamer, and T. Darrell, “Fully convolutional networks for semantic segmentation,” in Computer Vision and Pattern Recognition (CVPR), 2015 IEEE Conference on: Date, 7-12 June 2015, 2015, pp. 3431–3440.
[58] M. D. Zeiler and R. Fergus, “Visualizing and Understanding Convolutional Networks,”in 2014, pp. 818–833.
[59] C. Szegedy et al., “Going deeper with convolutions,” in Computer Vision and PatternRecognition (CVPR), 2015 IEEE Conference on: Date, 7-12 June 2015, 2015, pp. 1–9.
[60] M. Lin, Q. Chen, and S. Yan, “Network In Network,” 2013. [Online]. Available: https://arxiv.org/pdf/1312.4400
[61] S. S. Saini and P. Rawat, “Deep Residual Network for Image Recognition,” in 2022 IEEE International Conference on Distributed Computing and Electrical Circuits and Electronics (ICDCECE), Apr. 2022 - Apr. 2022, pp. 1–4.
[62] H. Noh, S. Hong, and B. Han, “Learning Deconvolution Network for Semantic Segmentation,” in 2015 IEEE International Conference on Computer Vision: 11-18 December 2015, Santiago, Chile : proceedings, 2015, pp. 1520–1528.
[63] L.-C. Chen, G. Papandreou, I. Kokkinos, K. Murphy, and A. L. Yuille, “DeepLab:Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs,” IEEE transactions on pattern analysis and machine intelligence, vol. 40, no. 4, pp. 834–848, 2018.
[64] G. Huang, Z. Liu, L. van der Maaten, and K. Q. Weinberger, “Densely Connected Convolutional Networks,” in 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Jul. 2017 - Jul. 2017, pp. 2261–2269.
[65] S. Xie, R. Girshick, P. Dollar, Z. Tu, and K. He, “Aggregated Residual Transformations for Deep Neural Networks,” in 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Jul. 2017 - Jul. 2017, pp. 5987–5995.
[66] L.-C. Chen, G. Papandreou, F. Schroff, and H. Adam, “Rethinking Atrous Convolution for Semantic Image Segmentation,” 2017. [Online]. Available: https://arxiv.org/pdf/1706.05587
[67] A. G. Howard et al., “MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications,” 2017. [Online]. Available: https://arxiv.org/pdf/1704.04861
[68] X. Zhang, X. Zhou, M. Lin, and J. Sun, “ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices,” in 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Jun. 2018 - Jun. 2018, pp. 6848–6856.
[69] N. Ma, X. Zhang, H.-T. Zheng, and J. Sun, “ShuffleNet V2: Practical Guidelines for Efficient CNN Architecture Design,” in LNCS sublibrary: SL6 - Image processing,computer vision, pattern recognition, and graphics, 11205-11220, Computer Vision -ECCV 2018: 15th European Conference, Munich, Germany, September 8-14, 2018 :proceedings / Vittorio Ferrari, Martial Hebert, Cristian Sminchisescu, Yair Weiss (eds.),Cham, Switzerland, 2018, pp. 122–138.
[70] K. Han, Y. Wang, Q. Tian, J. Guo, C. Xu, and C. Xu, “GhostNet: More Features FromCheap Operations,” in 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Jun. 2020 - Jun. 2020, pp. 1577–1586.
[71] T. Takikawa, D. Acuna, V. Jampani, and S. Fidler, “Gated-SCNN: Gated Shape CNNs for Semantic Segmentation,” in 2019, pp. 5229–5238.
[72] K. He, X. Zhang, S. Ren, and J. Sun, “Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition,” IEEE transactions on pattern analysis and machine intelligence, vol. 37, no. 9, pp. 1904–1916, 2015.
[73] R. Girshick, “Fast R-CNN,” in 2015 IEEE International Conference on Computer Vision: 11-18 December 2015, Santiago, Chile : proceedings, 2015, pp. 1440–1448.
[74] S. Ren, K. He, R. Girshick, and J. Sun, “Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks,” IEEE transactions on pattern analysis and machine intelligence, vol. 39, no. 6, pp. 1137–1149, 2017.
[75] J. Dai, Y. Li, K. He, and J. Sun, “R-FCN: Object Detection via Region-based Fully Convolutional Networks,” Advances in Neural Information Processing Systems, vol. 29, 2016.
[76] J. Redmon, S. Divvala, R. Girshick, and A. Farhadi, “You Only Look Once: Unified,Real-Time Object Detection,” in 2016, pp. 779–788.
[77] J. Redmon and A. Farhadi, “YOLO9000: Better, Faster, Stronger,” in 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Jul. 2017 - Jul. 2017,pp. 6517–6525.
[78] J. Redmon and A. Farhadi, “YOLOv3: An Incremental Improvement,” 2018. [Online].Available: https://arxiv.org/pdf/1804.02767
[79] A. Bochkovskiy, C.-Y. Wang, and H.-Y. M. Liao, “YOLOv4: Optimal Speed and Accuracy of Object Detection,” Apr. 2020. [Online]. Available: http://arxiv.org/pdf/2004.10934v1
[80] X. Zhu, S. Lyu, X. Wang, and Q. Zhao, “TPH-YOLOv5: Improved YOLOv5 Based onTransformer Prediction Head for Object Detection on Drone-captured Scenarios,” 2021.[Online]. Available: https://arxiv.org/pdf/2108.11539
[81] W. Liu et al., “SSD: Single Shot MultiBox Detector,” in 2016, pp. 21–37.
[82] T.-Y. Lin, P. Goyal, R. Girshick, K. He, and P. Dollar, “Focal Loss for Dense Object Detection,” in 2017, pp. 2980–2988.
[83] M. Tan, R. Pang, and Q. V. Le, “EfficientDet: Scalable and Efficient Object Detection,” in 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR),Jun. 2020 - Jun. 2020, pp. 10778–10787.
[84] N. Shazeer, K. Fatahalian, W. R. Mark, and R. T. Mullapudi, “HydraNets: SpecializedDynamic Architectures for Efficient Inference,” in CVPR 2018: 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition : proceedings : 18-22 June2018, Salt Lake City, Utah, 2018, pp. 8080–8089.
[85] R. Wang, B. Li, J. Chu, and S. Ji, “Study on the Method of Measuring the Leading Vehicle Distance Based on the On-board Monocular Camera,” J. Highw. Transp. Res. Dev. (Chin. Ed.), vol. 18, pp. 94–98, 2001.
[86] C.-F. Wu, C.-J. Lin, and C.-Y. Lee, “Applying a Functional Neurofuzzy Network to Real-Time Lane Detection and Front-Vehicle Distance Measurement,” IEEE Trans. Syst., Man, Cybern. C, vol. 42, no. 4, pp. 577–589, 2012.
[87] R. Adamshuk et al., “On the applicability of inverse perspective mapping for the forward distance estimation based on the HSV colormap,” in Proceedings: Hilton Toronto, Toronto, Canada, 23-25 March, 2017, 2017, pp. 1036–1041.
[88] S. Tuohy, D. O'Cualain, E. Jones, and M. Glavin, “Distance determination for an automobile environment using inverse perspective mapping in OpenCV,” in IET Irish Signals and Systems Conference (ISSC 2010), Jun. 2010, pp. 100–105.
[89] W. Yang, L. Wei, J. Gong, and Q. Zhang, “Research on etection of Longitudinal VehicleSpacing Based on Monocular Vision,” Computer Measurement and Control, vol. 20, pp.2039–2044, 2012.
[90] C. Guan, L. Wei, J. Qiao, and W. Yang, “A vehicle distance measurement method with monocular vision based on vanishing point,” Electronic Measurement Technology, vol.41, pp. 83–87, 2018.
[91] J. Liu, S. Hou, K. Zhang, and X. Yan, “Vehicle distance measurement with implementation of vehicle attitude angle estimation and inverse perspective mapping based on monocular vision,” Trans. Chin. Soc. Agric. Eng., vol. 34, pp. 70–76, 2018.
[92] B. Li, X. Zhang, and M. Sato, “Pitch angle estimation using a Vehicle-Mounted monocular camera for range measurement,” in ICSP2014: 2014 IEEE 12th International Conference on Signal Processing proceedings : October 19-23, 2014, HangZhou, China,2014, pp. 1161–1168.
[93] N. Snavely, S. M. Seitz, and R. Szeliski, “Photo tourism: exploring photo collections in 3D,” ACM Trans. Graph., vol. 25, no. 3, pp. 835–846, 2006.
[94] H. Cui, S. Shen, X. Gao, and Z. Hu, “Batched Incremental Structure-from-Motion,” in2017 International Conference on 3D Vision: 3DV 2017 : Qingdao, Canada, 10-12 October 2017 : proceedings, 2017, pp. 205–214.
[95] N. Snavely, S. M. Seitz, and R. Szeliski, “Modeling the World from Internet Photo Collections,” Int J Comput Vis, vol. 80, no. 2, pp. 189–210, 2008.
[96] C. Wu, “Towards Linear-Time Incremental Structure from Motion,” in 3DV 2013: 2013International Conference on 3D Vision : proceedings : 29 June-1 July 2013, Seattle,Washington, USA, 2013, pp. 127–134.
[97] P. Moulon, P. Monasse, and R. Marlet, “Adaptive Structure from Motion with a Contrario Model Estimation,” in LNCS sublibrary: SL 6 - Image processing, computer vision, pattern recognition, and graphics, 7724-7727, Computer vision - ACCV 2012:11th Asian Conference on Computer Vision, Daejeon, Korea, November 5-9, 2012 :revised selected papers / Kyoung Mu Lee, Yasuyuki Matsushita, James M. Rehg, ZhanyiHu (eds.), Heidelberg, 2013, pp. 257–270.
[98] H. Cui, S. Shen, W. Gao, and Z. Wang, “Progressive Large-Scale Structure-from-Motionwith Orthogonal MSTs,” in 2018 International Conference on 3D Vision: 3DV 2018 :Verona, Italy, 5-8 September 2018 : proceedings, 2018, pp. 79–88.
[99] N. Jiang, Z. Cui, and P. Tan, “A Global Linear Method for Camera Pose Registration,”in 2013 IEEE International Conference on Computer Vision: 1-8 December 2013, 2014,pp. 481–488.
[100] Z. Cui and P. Tan, “Global Structure-from-Motion by Similarity Averaging,” in 2015 IEEE International Conference on Computer Vision: 11-18 December 2015, Santiago,Chile : proceedings, 2015, pp. 864–872.
[101] O. Ozyesil and A. Singer, “Robust camera location estimation by convex programming,” in Computer Vision and Pattern Recognition (CVPR), 2015 IEEE Conference on: Date, 7-12 June 2015, 2015, pp. 2674–2683.
[102] C. Sweeney, T. Sattler, T. Hollerer, M. Turk, and M. Pollefeys, “Optimizing the Viewing Graph for Structure-from-Motion,” in 2015 IEEE International Conference on Computer Vision: 11-18 December 2015, Santiago, Chile : proceedings, 2015, pp. 801–809.4577.
[103] S. Zhu et al., “Very Large-Scale Global SfM by Distributed Motion Averaging,” in CVPR 2018: 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition : proceedings : 18-22 June 2018, Salt Lake City, Utah, 2018, pp. 4568–
[104] B. Bhowmick, S. Patra, A. Chatterjee, V. M. Govindu, and S. Banerjee, “Divide and Conquer: Efficient Large-Scale Structure from Motion Using Graph Partitioning,” in Image Processing, Computer Vision, Pattern Recognition, and Graphics, vol. 9004, Computer Vision -- ACCV 2014: 12th Asian Conference on Computer Vision, Singapore, Singapore, November 1-5, 2014, Revised Selected Papers, Part II, Cham, 2015, pp.273–287.
[105] R. Gherardi, M. Farenzena, and A. Fusiello, “Improving the efficiency of hierarchical structure-and-motion,” in Computer Vision and Pattern Recognition (CVPR), 2010 IEEE Conference on: Date, 13-18 June 2010, 2010, pp. 1594–1600.33
[106] M. Farenzena, A. Fusiello, and R. Gherardi, “Structure-and-motion pipeline on a hierarchical cluster tree,” in 2009 IEEE 12th International Conference on Computer Vision Workshops, 2009, pp. 1489–1496.
[107] R. Toldo, R. Gherardi, M. Farenzena, and A. Fusiello, “Hierarchical structure-and-motion recovery from uncalibrated images,” Computer Vision and ImageUnderstanding, vol. 140, pp. 127–143, 2015.
[108] H. Cui, X. Gao, S. Shen, and Z. Hu, “HSfM: Hybrid Structure-from-Motion,” in 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Jul. 2017 - Jul. 2017, pp. 2393–2402.
[109] S. Zhu et al., “Parallel Structure from Motion from Local Increment to Global Averaging,” Feb. 2017. [Online]. Available: http://arxiv.org/pdf/1702.08601v3
[110] S. Vijayanarasimhan, S. Ricco, C. Schmid, R. Sukthankar, and K. Fragkiadaki, “SfM-Net: Learning of Structure and Motion from Video,” 2017. [Online]. Available: https://arxiv.org/pdf/1704.07804
[111] T. Zhou, M. Brown, N. Snavely, and D. G. Lowe, “Unsupervised Learning of Depthand Ego-Motion from Video,” in 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Jul. 2017 - Jul. 2017, pp. 6612–6619.
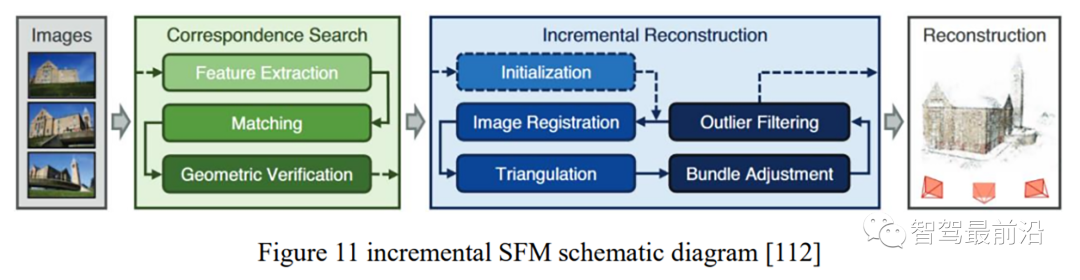
[112] J. L. Schonberger and J.-M. Frahm, “Structure-from-Motion Revisited,” in 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2016, pp. 4104–4113.
[113] Z. Feng, “FCWs Test and Evaluation Based on Monicular Camera,” Special Purpose Vehicle, vol. 9, pp. 50–53, 2021.
[114] S. Bougharriou, F. Hamdaoui, and A. Mtibaa, “Vehicles distance estimation using detection of vanishing point,” EC, vol. 36, no. 9, pp. 3070–3093, 2019.
[115] F. Ma, J. Shi, L. Ge, K. Dai, S. Zhong, and L. Wu, “Progress in research on monocular visual odometry of autonomous vehicles,” J. Jilin Univ., Eng. Technol. Ed.,vol. 50, pp. 765–775, 2020.
[116] A. Saxena, S. Chung, and A. Ng, “Learning Depth from Single Monocular Images,”Advances in Neural Information Processing Systems, vol. 18, 2005.
[117] D. Eigen, C. Puhrsch, and R. Fergus, “Depth Map Prediction from a Single Image using a Multi-Scale Deep Network,” Jun. 2014. [Online]. Available: http://arxiv.org/pdf/1406.2283v1
[118] D. Eigen and R. Fergus, “Predicting Depth, Surface Normals and Semantic Labels with a Common Multi-scale Convolutional Architecture,” in 2015 IEEE International Conference on Computer Vision: 11-18 December 2015, Santiago, Chile : proceedings,2015, pp. 2650–2658.
[119] D. Bao and P. Wang, “Vehicle distance detection based on monocular vision,” in Proceedings of the 2016 IEEE International Conference on Progress in Informatics and Computing: PIC 2016 : December 23-25, 2016, Shanghai, China, 2016, pp. 187–191.
[120] H. Fu, M. Gong, C. Wang, K. Batmanghelich, and D. Tao, “Deep Ordinal Regression Network for Monocular Depth Estimation,” Proceedings. IEEE Computer Society Conference on Computer Vision and Pattern Recognition, vol. 2018, pp. 2002–2011,2018.
[121] Y. Wang, W.-L. Chao, D. Garg, B. Hariharan, M. Campbell, and K. Q. Weinberger,“Pseudo-LiDAR from Visual Depth Estimation: Bridging the Gap in 3D ObjectDetection for Autonomous Driving,” Dec. 2018. [Online]. Available:http://arxiv.org/pdf/1812.07179v6
[122] Zengyi Qin, Jinglu Wang, and Yan Lu, “MonoGRNet: A Geometric Reasoning Network for Monocular 3D Object Localization,” AAAI, vol. 33, no. 01, pp. 8851–8858,2019.
[123] I. Barabanau, A. Artemov, E. Burnaev, and V. Murashkin, “Monocular 3D ObjectDetection via Geometric Reasoning on Keypoints,” 2019. [Online]. Available: https://arxiv.org/pdf/1905.05618
[124] Y. Kim and D. Kum, “Deep Learning based Vehicle Position and Orientation Estimation via Inverse Perspective Mapping Image,” in 2019 IEEE Intelligent Vehicles Symposium (IV 2019): Paris, France 9-12 June 2019, 2019, pp. 317–323.
[125] d. xu, E. Ricci, W. Ouyang, X. Wang, and N. Sebe, “Monocular Depth Estimation Using Multi-Scale Continuous CRFs as Sequential Deep Networks,” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 41, no. 6, pp. 1426–1440, 2019.
[126] A. Kundu, Y. Li, and J. M. Rehg, “3D-RCNN: Instance-Level 3D ObjectReconstruction via Render-and-Compare,” in CVPR 2018: 2018 IEEE/CVF Conferenceon Computer Vision and Pattern Recognition : proceedings : 18-22 June 2018, Salt Lake City, Utah, 2018, pp. 3559–3568.
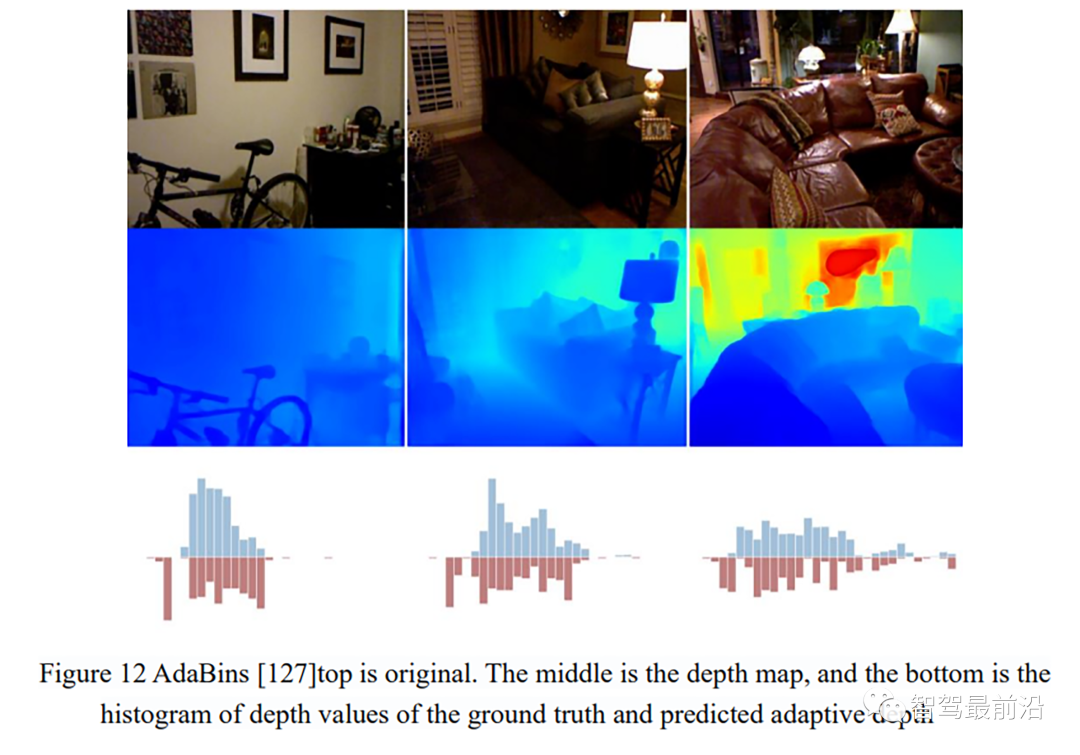
[127] S. F. Bhat, I. Alhashim, and P. Wonka, “AdaBins: Depth Estimation Using AdaptiveBins,” in 2021, pp. 4009–4018.
[128] C. Shen, X. Zhao, Z. Liu, T. Gao, and J. Xu, “Joint vehicle detection and distance prediction via monocular depth estimation,” IET Intelligent Transport Systems, vol. 14,no. 7, pp. 753–763, 2020.
[129] A. Hu et al., “FIERY: Future Instance Prediction in Bird's-Eye View From SurroundMonocular Cameras,” in 2021, pp. 15273–15282.
[130] Y. Cao, Z. Wu, and C. Shen, “Estimating Depth From Monocular Images as Classification Using Deep Fully Convolutional Residual Networks,” IEEE Transactions on Circuits and Systems for Video Technology, vol. 28, no. 11, pp. 3174–3182, 2018.
[131] B. Li, Y. Dai, H. Chen, and M. He, “Single image depth estimation by dilated deepresidual convolutional neural network and soft-weight-sum inference,” 2017. [Online]. Available: https://arxiv.org/pdf/1705.00534
[132] I. Laina, C. Rupprecht, V. Belagiannis, F. Tombari, and N. Navab, “Deeper Depth Prediction with Fully Convolutional Residual Networks,” in 2016 Fourth International Conference on 3D Vision (3DV), 2016, pp. 239–248.
[133] J.-H. Lee, M. Heo, K.-R. Kim, and C.-S. Kim, “Single-Image Depth Estimation Based on Fourier Domain Analysis,” in CVPR 2018: 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition : proceedings : 18-22 June 2018, Salt Lake City, Utah, 2018, pp. 330–339.
[134] A. Chakrabarti, J. Shao, and G. Shakhnarovich, “Depth from a Single Image by Harmonizing Overcomplete Local Network Predictions,” Advances in Neural Information Processing Systems, vol. 29, 2016.
[135] F. Liu, C. Shen, and G. Lin, “Deep convolutional neural fields for depth estimation from a single image,” in Computer Vision and Pattern Recognition (CVPR), 2015 IEEE Conference on: Date, 7-12 June 2015, 2015, pp. 5162–5170.
[136] D. Xu, E. Ricci, W. Ouyang, X. Wang, and N. Sebe, “Multi-scale Continuous CRFs as Sequential Deep Networks for Monocular Depth Estimation,” in 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Jul. 2017 - Jul. 2017, pp. 161–169.
[137] D. Xu, W. Wang, H. Tang, H. Liu, N. Sebe, and E. Ricci, “Structured Attention Guided Convolutional Neural Fields for Monocular Depth Estimation,” in CVPR 2018: 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition :proceedings : 18-22 June 2018, Salt Lake City, Utah, 2018, pp. 3917–3925.
[138] C. Godard, O. M. Aodha, and G. J. Brostow, “Unsupervised Monocular Depth Estimation with Left-Right Consistency,” in 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2017, pp. 6602–6611.
[139] J. Watson, M. Firman, G. Brostow, and D. Turmukhambetov, “Self-Supervised Monocular Depth Hints,” in 2019 IEEE/CVF International Conference on Computer Vision (ICCV), 2019, pp. 2162–2171.
[140] Y. Luo et al., “Single View Stereo Matching,” in CVPR 2018: 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition : proceedings : 18-22 June 2018, Salt Lake City, Utah, 2018, pp. 155–163.
[141] R. Garg, V. K. B.G., G. Carneiro, and I. Reid, “Unsupervised CNN for Single View Depth Estimation: Geometry to the Rescue,” in 2016, pp. 740–756.
[142] W. Kay et al., “The Kinetics Human Action Video Dataset,” 2017. [Online]. Available: https://arxiv.org/pdf/1705.06950
[143] V. Casser, S. Pirk, R. Mahjourian, and A. Angelova, “Depth Prediction Without the Sensors: Leveraging Structure for Unsupervised Learning from Monocular Videos,”2018. [Online]. Available: https://arxiv.org/pdf/1811.06152
[144] Y. Tan, S. Goddard, and L. C. Pérez, “A prototype architecture for cyber-physical systems,” SIGBED Rev., vol. 5, no. 1, pp. 1–2, 2008.
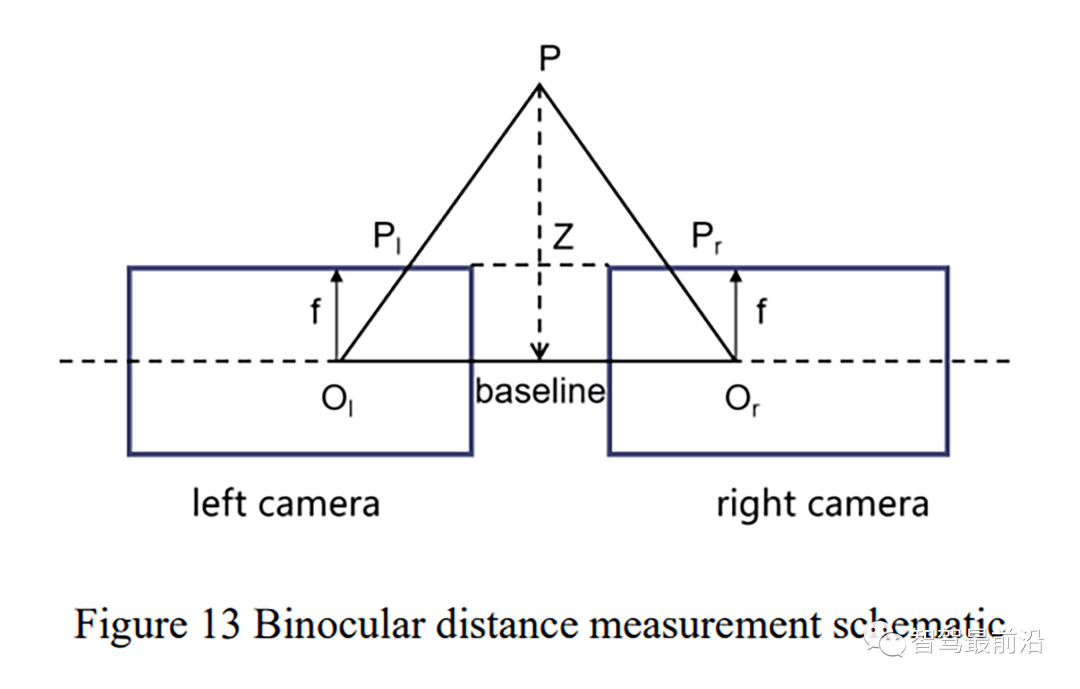
[145] A. L. Hou, J. Chen, Z. J. Jin, Q. Liao, and Y. Geng, “Binocular Vision Measurement of Distance Based on Vehicle Logo Location,” AMM, 229-231, pp. 1154–1157, 2012.
[146] ZHANG Z B, LIU S S, XU G, et al., “A Vehicle Distance Measurement Based on Binocular Stereo Vision,” JATIT, vol. 44, pp. 179–184, 2012.
[147] J. j. LI, “Analysis of Pixel-level Remote Sensing Image Fusion Methods,” Geo-information Science, vol. 10, no. 1, pp. 128–134, 2008.
[148] N. Shao, H.-G. Li, L. Liu, and Z.-L. Zhang, “Stereo Vision Robot Obstacle Detection Based on the SIFT,” in 2010 Second WRI Global Congress on Intelligent Systems, Dec.2010 - Dec. 2010, pp. 274–277.
[149] Y. Pan and C. Wu, “Research on Integrated Location with Stereo Vision and Map for Intelligent Vehicle,” Journal of Hubei University of Technology, vol. 32, pp. 55–59,2017.
[150] X. Huang, F. Shu, and W. Cao, “Research on Distance Measurement Method of Front Vehicle Based on Binocular Vision,” Automobile Technology, vol. 12, pp. 16–21, 2016.
[151] Y. Wei et al., “SurroundDepth: Entangling Surrounding Views for Self-Supervised Multi-Camera Depth Estimation,” 2022. [Online]. Available: https://arxiv.org/pdf/2204.03636
[152] Jure Žbontar and Yann LeCun, “Stereo matching by training a convolutional neural network to compare image patches,” J. Mach. Learn. Res., vol. 17, no. 1, pp. 2287–2318, 2016.
[153] A. Kendall et al., “End-to-End Learning of Geometry and Context for Deep StereoRegression,” in 2017 IEEE International Conference on Computer Vision: ICCV 2017 :proceedings : 22-29 October 2017, Venice, Italy, 2017, pp. 66–75.
[154] J. -R. Chang and Y. -S. Chen, “Pyramid Stereo Matching Network,” in 2018IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2018, pp. 5410–5418.
[155] Y. Yao, Z. Luo, S. Li, T. Fang, and L. Quan, “MVSNet: Depth Inference for Unstructured Multi-view Stereo,” in LNCS sublibrary: SL6 - Image processing,computer vision, pattern recognition, and graphics, 11205-11220, Computer Vision -ECCV 2018: 15th European Conference, Munich, Germany, September 8-14, 2018 :proceedings / Vittorio Ferrari, Martial Hebert, Cristian Sminchisescu, Yair Weiss (eds.),Cham, Switzerland, 2018, pp. 785–801.
[156] K. Luo, T. Guan, L. Ju, H. Huang, and Y. Luo, “P-MVSNet: Learning Patch-WiseMatching Confidence Aggregation for Multi-View Stereo,” in 2019 IEEE/CVFInternational Conference on Computer Vision (ICCV), 2019, pp. 10451–10460.
[157] R. Chabra, J. Straub, C. Sweeney, R. Newcombe, and H. Fuchs, “StereoDRNet:Dilated Residual StereoNet,” in Proceedings of the IEEE/CVF Conference, 2019, pp.11786–11795.
[158] D. Garg, Y. Wang, B. Hariharan, M. Campbell, K. Q. Weinberger, and W.-L. Chao,“Wasserstein Distances for Stereo Disparity Estimation,” Advances in NeuralInformation Processing Systems, vol. 33, pp. 22517–22529, 2020.
[159] Y. Chen, W. Zuo, K. Wang, and Q. Wu, “Survey on Structured Light PatternCodification Methods,” Journal of Chinese Computer Systems, vol. 31, pp. 1856–1863,2010.
[160] J.L. Posdamer and M.D. Altschuler, “Surface measurement by space-encodedprojected beam systems,” Computer Graphics and Image Processing, vol. 18, no. 1, pp.1–17, 1982.
[161] E. Horn and N. Kiryati, “Toward optimal structured light patterns,” in Internationalconference on recent advances in 3-D digital imaging and modeling, 1997, pp. 28–35.
[162] T. P. Koninckx and L. van Gool, “Real-time range acquisition by adaptive structuredlight,” IEEE transactions on pattern analysis and machine intelligence, vol. 28, no. 3,pp. 432–445, 2006.
[163] J. Pages, J. Salvi, and J. Forest, “A new optimised De Bruijn coding strategy forstructured light patterns,” in Proceedings of the 17th International Conference onPattern Recognition: ICPR 2004, 2004, 284-287 Vol.4.
[164] P. M. Griffin and S. R. Yee, “The use of a uniquely encoded light pattern for rangedata acquisition,” Computers & Industrial Engineering, vol. 21, 1-4, pp. 359–363, 1991.
[165] A. K.C. Wong, P. Niu, and X. He, “Fast acquisition of dense depth data by a new structured light scheme,” Computer Vision and Image Understanding, vol. 98, no. 3, pp. 398–422, 2005.
[166] J. Tajima and M. Iwakawa, “3-D data acquisition by Rainbow Range Finder,” in Pattern recognition: 10th International conference : Papers, 1990, pp. 309–313.
[167] G. Grisetti, C. Stachniss, and W. Burgard, “Improved Techniques for Grid Mapping With Rao-Blackwellized Particle Filters,” IEEE Trans. Robot., vol. 23, no. 1, pp. 34–46,2007.
[168] T. Yap, M. Li, A. I. Mourikis, and C. R. Shelton, “A particle filter for monocular vision-aided odometry,” in 2011 IEEE International Conference on Robotics and Automation: (ICRA) ; 9-13 May 2011, Shanghai, China, 2011, pp. 5663–5669.
[169] A. J. Davison, I. D. Reid, N. D. Molton, and O. Stasse, “MonoSLAM: real-time single camera SLAM,” IEEE transactions on pattern analysis and machine intelligence, vol. 29, no. 6, pp. 1052–1067, 2007.
[170] R. Sim, P. Elinas, and J. J. Little, “A Study of the Rao-Blackwellised Particle Filter for Efficient and Accurate Vision-Based SLAM,” Int J Comput Vis, vol. 74, no. 3, pp. 303–318, 2007.
[171] M. Montemerlo, S. Thrun, D. Koller, and B. Wegbreit, “FastSLAM 2.0: an improved particle filtering algorithm for simultaneous localization and mapping that provably converges,” proc.int.conf.on artificial intelligence, 2003.
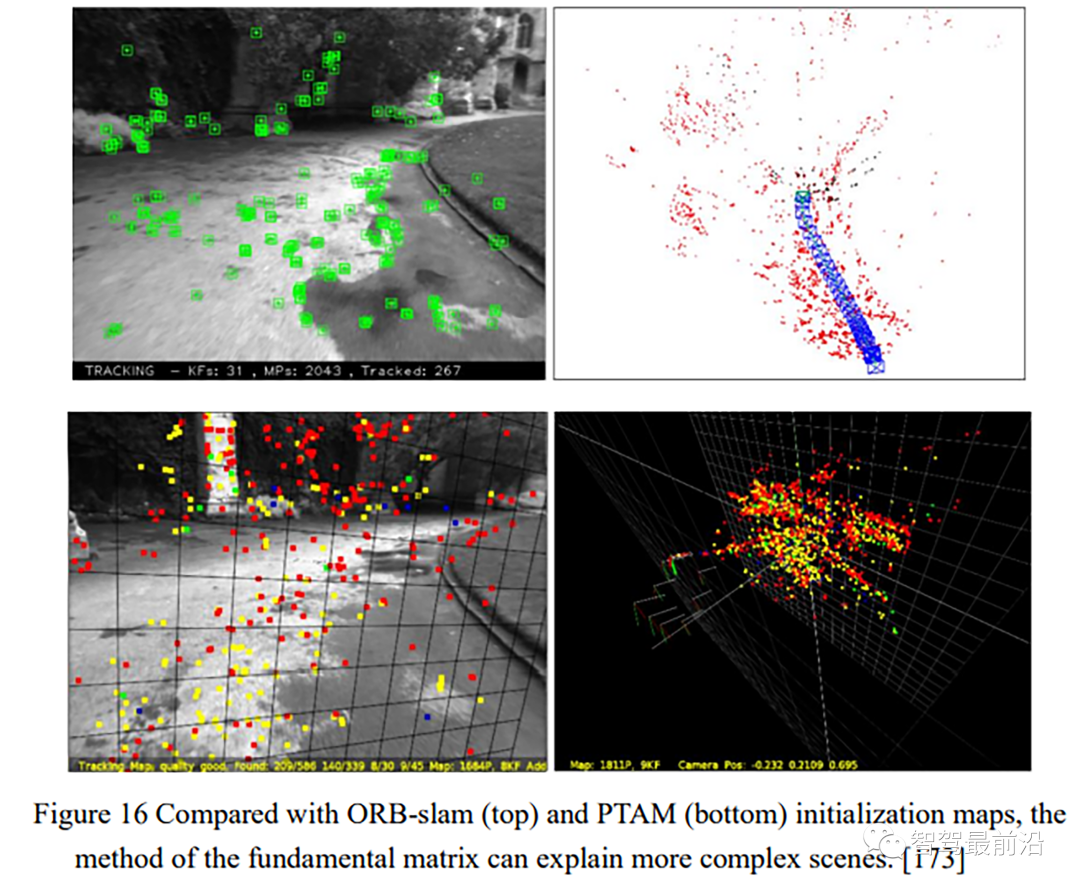
[172] G. Klein and D. Murray, “Parallel Tracking and Mapping for Small AR Workspaces,” in 2007 6th ieee & acm international symposium on mixed and augmented reality, 2008, pp. 1–10. [173] R. Mur-Artal, J. M. M. Montiel, and J. D. Tardos, “ORB-SLAM: A Versatile and Accurate Monocular SLAM System,” IEEE Trans. Robot., vol. 31, no. 5, pp. 1147– 1163, 2015.
[174] R. Mur-Artal and J. D. Tardos, “ORB-SLAM2: An Open-Source SLAM System for Monocular, Stereo, and RGB-D Cameras,” IEEE Trans. Robot., vol. 33, no. 5, pp. 1255– 1262, 2017.
[175] C. Campos, R. Elvira, J. J. G. Rodriguez, J. M. M. Montiel, and J. D. Tardos, “ORB-SLAM3: An Accurate Open-Source Library for Visual, Visual–Inertial, and Multimap SLAM,” IEEE Trans. Robot., vol. 37, no. 6, pp. 1874–1890, 2021.
[176] E. Mouragnon, M. Lhuillier, M. Dhome, F. Dekeyser, and P. Sayd, “Monocular Vision Based SLAM for Mobile Robots,” in ICPR 2006: The 18th International Conference on Pattern Recognition : 20-24 August 2006, Hong Kong : [conference proceedings], 2006,pp. 1027–1031.
[177] H. M. S. Bruno and E. L. Colombini, “LIFT-SLAM: A deep-learning feature-based monocular visual SLAM method,” Neurocomputing, vol. 455, pp. 97–110, 2021.
[178] J. Engel, J. Stuckler, and D. Cremers, “Large-scale direct SLAM with stereo cameras,” in 2015 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS): Sept. 28, 2015 - Oct. 2, 2015, Hamburg, Germany, 2015, pp. 1935– 1942.
[179] G. Liu, W. Zeng, B. Feng, and F. Xu, “DMS-SLAM: A general visual SLAM system for dynamic scenes with multiple sensors,” Sensors, vol. 19, no. 17, p. 3714, 2019.
[180] R. Gomez-Ojeda, F. -A. Moreno, D. Zuñiga-Noël, D. Scaramuzza, and J. Gonzalez-Jimenez, “PL-SLAM: A Stereo SLAM System Through the Combination of Points andLine Segments,” IEEE Transactions on Robotics, vol. 35, no. 3, pp. 734–746, 2019.
[181] S. Bultmann, K. Li, and U. D. Hanebeck, “Stereo Visual SLAM Based on Unscented Dual Quaternion Filtering,” in 2019 22th International Conference on Information Fusion (FUSION), 2019, pp. 1–8.
[182] I. Cvišić, J. Ćesić, I. Marković, and I. Petrović, “SOFT-SLAM: Computationally efficient stereo visual simultaneous localization and mapping for autonomous unmanned aerial vehicles,” J. Field Robotics, vol. 35, no. 4, pp. 578–595, 2018.
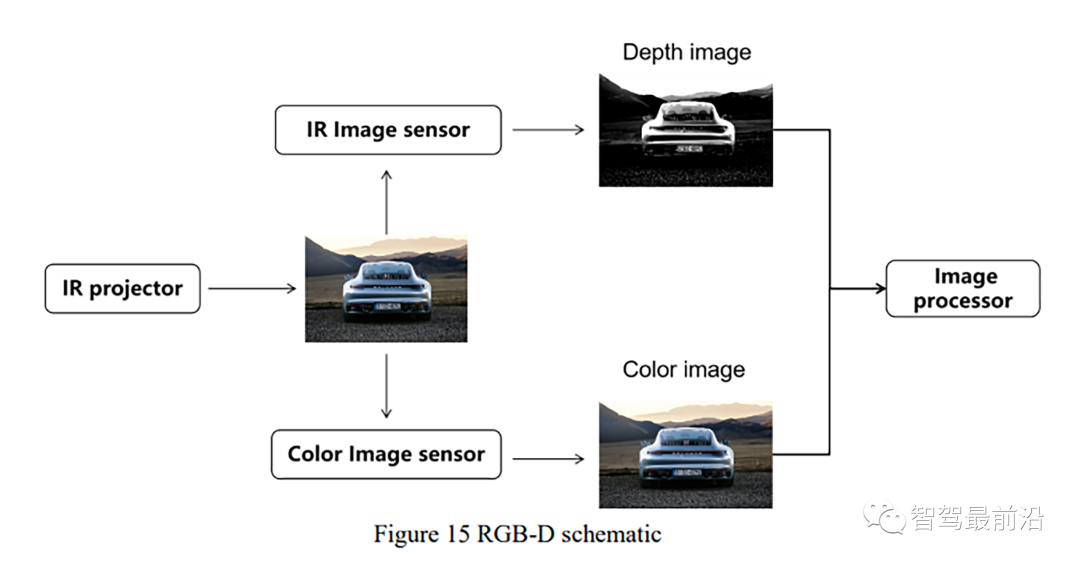
[183] P. Henry, M. Krainin, E. Herbst, X. Ren, and D. Fox, “RGB-D mapping: Using Kinect-style depth cameras for dense 3D modeling of indoor environments,” The International Journal of Robotics Research, vol. 31, no. 5, pp. 647–663, 2012.
[184] L. Furler, V. Nagrath, A. S. Malik, and F. Meriaudeau, “An Auto-Operated Telepresence System for the Nao Humanoid Robot,” in 2013 International Conference on Communication Systems and Network Technologies: Proceedings, 6-8 April, 2013,Gwalior, India ; [edited by Geetam S. Tomar, Manish Dixit, Frank Z. Wang], 2013, pp.262–267.
[185] R. A. Newcombe et al., “KinectFusion: Real-time dense surface mapping and tracking,” in 10th IEEE International Symposium on Mixed and Augmented Reality (ISMAR), 2011: 26 - 29 Oct. 2011, Basel, Switzerland, 2011, pp. 127–136.
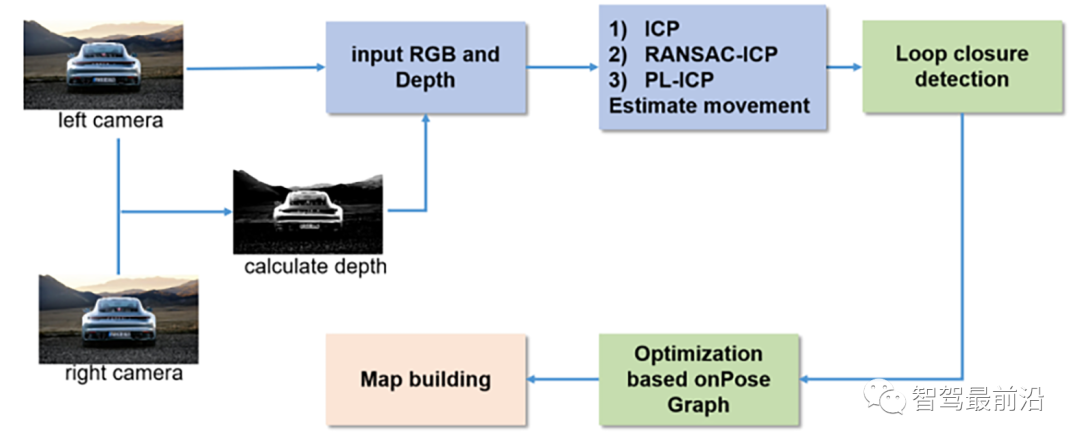
[186] F. Endres, J. Hess, J. Sturm, D. Cremers, and W. Burgard, “3-D Mapping With an RGB-D Camera,” IEEE Trans. Robot., vol. 30, no. 1, pp. 177–187, 2014.
[187] M. Yang, “Influence of Weather Environment on Drivers' Hazard Perception Characteristics Based on Simulated Driving,” Beijing Automotive Engineering, vol. 2,pp. 11–13, 2017.
[188] F. N. Iandola, S. Han, M. W. Moskewicz, K. Ashraf, W. J. Dally, and K. Keutzer,“SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and <0.5MB model size,” 2016. [Online]. Available: https://arxiv.org/pdf/1602.07360.
下滑查看更多参考文献
转载自自动驾驶之心,文中观点仅供分享交流,不代表本公众号立场,如涉及版权等问题,请您告知,我们将及时处理。
-- END --