点击上方“C语言与CPP编程”,选择“关注/置顶/星标公众号”
干货福利,第一时间送达!

你好,我是飞宇。
最近跟朋友一起创建了一个学习圈子,如果你是计算机小白新手或者打算学习Linux C/C++技术栈,欢迎了解一二。
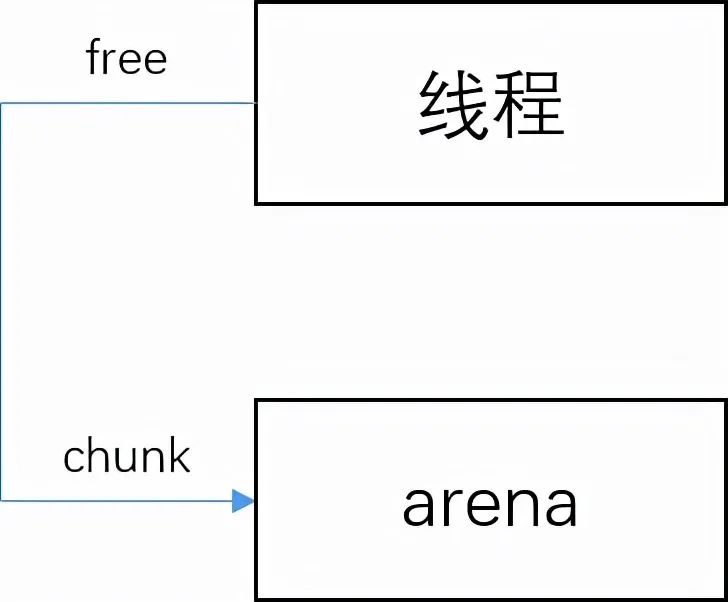
在展开本文之前,先解释一下本文中会提到的三个重要概念:arena,bin,chunk。三者在逻辑上的蕴含关系一般如下图所示(图中的chunk严格来说应该是Free Chunk)。
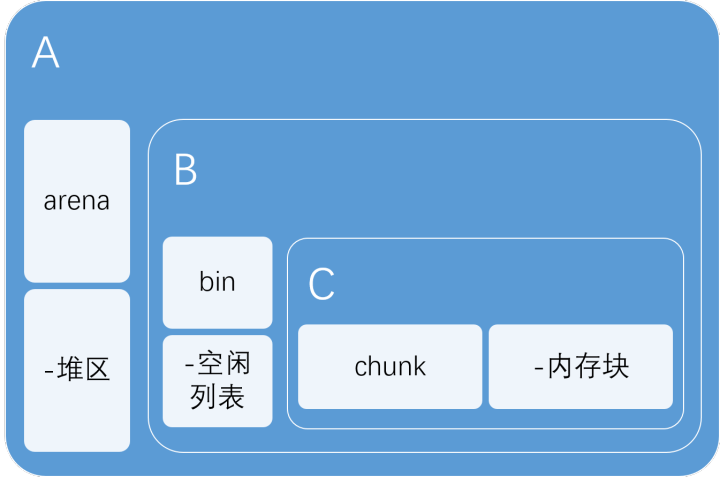
三者概念的解释如下:
arena:通过sbrk或mmap系统调用为线程分配的堆区,按线程的类型可以分为2类:
main arena:主线程建立的arena;
thread arena:子线程建立的arena;
chunk:逻辑上划分的一小块内存,根据作用不同分为4类:
Allocated chunk:即分配给用户且未释放的内存块;
Free chunk:即用户已经释放的内存块;
Top chunk
Last Remainder chunk
bin:一个用以保存Free chunk链表的表头信息的指针数组,按所悬挂链表的类型可以分为4类:
Fast bin
Unsorted bin
Small bin
Large bin
在这里读者仅需明白arena的等级大于bin的等级大于(free)chunk的等级即可,即A>B>C。
tips:
实际内存中,main arena和thread arena的图示如下(单堆段)。
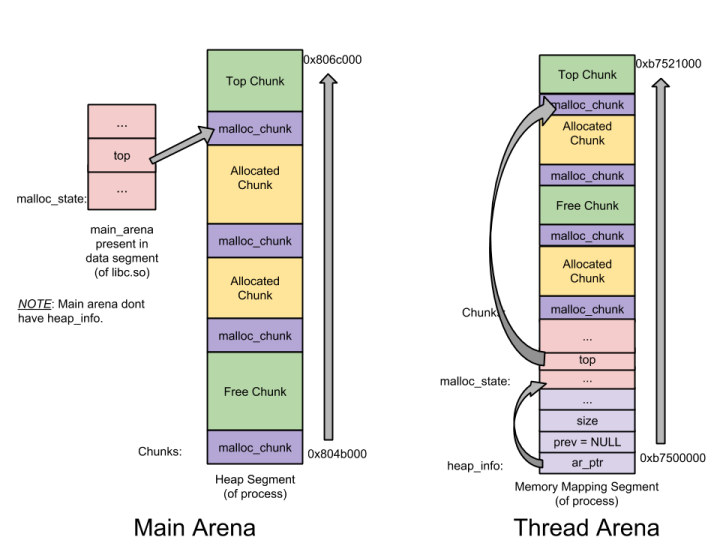
其中malloc_state的数据结构描述在源代码中发现该数据结构中保存着fastbinsY、top、last_remainder、bins这四个分别表示Fast bin、Top chunk、Last Remainder chunk、bins(Unsorted bin、 Small bin、Large bin)的数据。
此处从Arena的层次分析内存分配与回收的过程。
main arena中的内存申请的流程如下图所示:
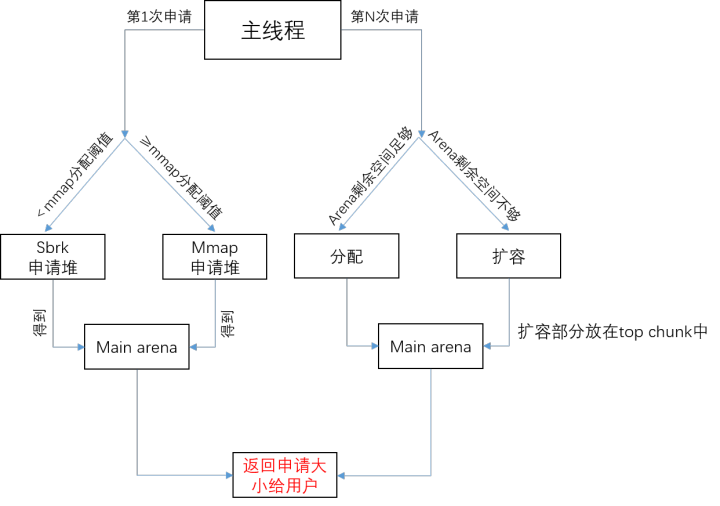
第一次申请
根据申请内存空间大小是否达到mmap这一系统调用的分配阈值,决定是使用sbrk系统调用 还是mmap系统调用申请堆区。一般分配的空间比申请的要大,这样可以减少后续申请中向操作系统申请内存的次数。
举例而言,用户申请1000字节的内存,实际会通过sbrk系统调用产生132KB的连续堆内存区域。
然后将用户申请大小的内存返回。(本例中将返回1000字节的内存。)
后续申请
根据arena中剩余空间的大小决定是继续分配还是扩容,其中包含扩容部分的为top chunk。
然后将用户申请大小的内存返回。
tips:top chunk不属于任何bin!只有free chunk依附于bin!分配阈值具有默认值,但会动态调整;扩容具体过程见库函数sYSMALLOc 。
thread arena中的内存申请的流程如下图所示:
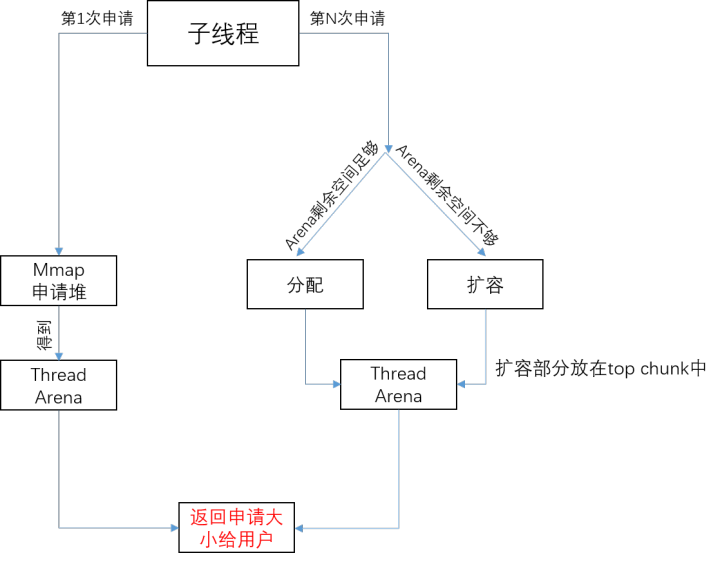
其流程类似于main arena的,区别在于thread arena的堆内存是使用mmap系统调用产生的,而非同主线程一样可能会使用sbrk系统调用。
tips:Arena的数量与线程之间并不一定是一一映射的关系。如,在32位系统中有着“ Number of arena = 2 * number of cores + 1”的限制。
内存回收
线程释放的内存不会直接返还给操作系统,而是返还给’glibc malloc’。
此处从bin的层次分析内存分配与回收的过程。考虑到内存回收的过程比内存分配的过程要复杂,因此这里先分析内存回收的过程,再分析内存分配的过程。
内存回收的流程如下图所示:
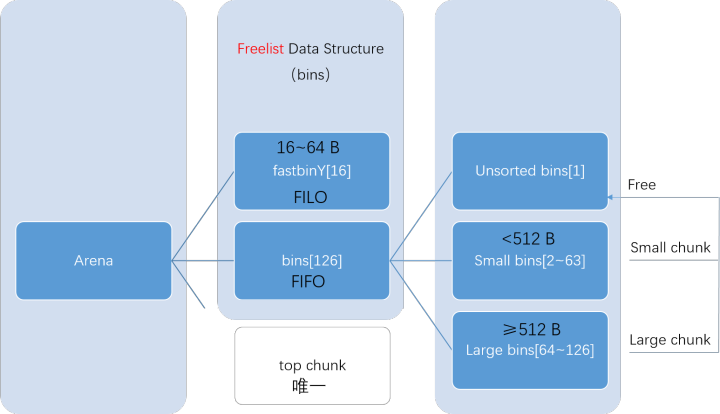
bin可以分为4类:Fast bin、Unsorted bin、Small bin和 Large bin。保存这些bin的数据结构为fastbinsY以及bins:
fastbinsY:用以保存fast bins。(可索引大小16~64B的内存块)
bins:用以保存unsorted、small以及large bins,共计可容纳126个:
Bin 1 – unsorted bin
Bin 2 to Bin 63 – small bin(可索引大小<512B的内存块)
Bin 64 to Bin 126 – large bin(可索引大小≥512B的内存块)
在内存被释放的时候,被释放内存块会根据其大小而被添加入对应的bin中:
16~64B的内存块会被添加入fastbinY中
samll及large的会添加在bins中的unsorted bins中。
tips:small bins和large bins中索引的内存块是在内存分配的过程中被添加在相应的bin中的。
内存分配的流程如下图所示:
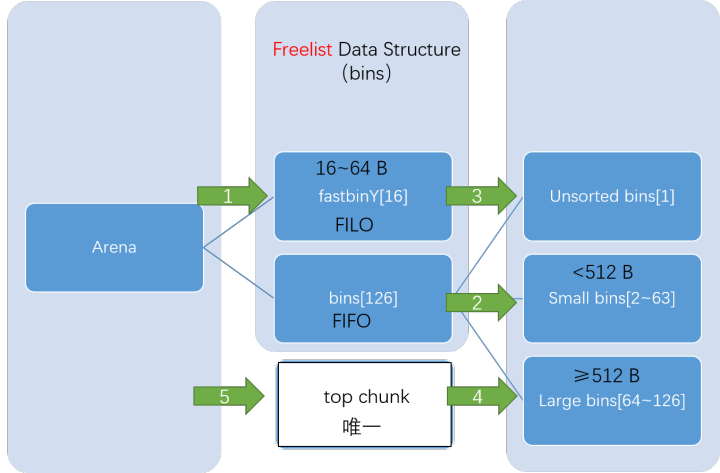
我们知道,内存分配的最终目的在于分配出合适大小的内存块返回给用户。在实现中即为在bin或top chunk中找到(并分割出)所需内存块,其检索的优先级从高到低分别是:
fastbinY
small bins
unsorted bins
large bins
top bins
tips: Fast bin、Unsorted bin、Small bin和 Large bin中保存的都是用户曾经释放的内存块(可能经过合并);top chunk包含Arena扩容的部分,不属于任何bin!
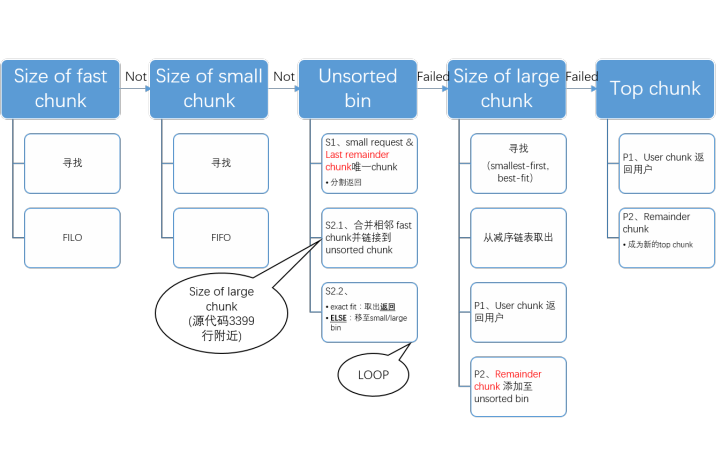
本文不过度关注操作细节,因此有关内存回收的过程就不赘述了。下图即内存分配的详细过程图:
tips:保存或新窗口打开图片可以查看原图。
具体分配说明参见下列引用内容:
1、获取分配区的锁,为了防止多个线程同时访问同一个分配区,在进行分配之前需要取得分配区域的锁。线程先查看线程私有实例中是否已经存在一个分配区,如果存在尝试对该分配区加锁,如果加锁成功,使用该分配区分配内存,否则,该线程搜索分配区循环链表试图获得一个空闲(没有加锁)的分配区。如果所有的分配区都已经加锁,那么ptmalloc会开辟一个新的分配区,把该分配区加入到全局分配区循环链表和线程的私有实例中并加锁,然后使用该分配区进行分配操作。开辟出来的新分配区一定为非主分配区,因为主分配区是从父进程那里继承来的。开辟非主分配区时会调用mmap()创建一个sub-heap,并设置好top chunk。
2、将用户的请求大小转换为实际需要分配的chunk空间大小。
3、判断所需分配chunk的大小是否满足chunk_size <= max_fast (max_fast 默认为 64B),如果是的话,则转下一步,否则跳到第5步。
4、首先尝试在fast bins中取一个所需大小的chunk分配给用户。如果可以找到,则分配结束。否则转到下一步。
5、判断所需大小是否处在small bins中,即判断chunk_size < 512B是否成立。如果chunk大小处在small bins中,则转下一步,否则转到第6步。
6、根据所需分配的chunk的大小,找到具体所在的某个small bin,从该bin的尾部摘取一个恰好满足大小的chunk。若成功,则分配结束,否则,转到下一步。
7、到了这一步,说明需要分配的是一块大的内存,或者small bins中找不到合适的 chunk。于是,ptmalloc首先会遍历fast bins中的chunk,将相邻的chunk进行合并,并链接到unsorted bin中,然后遍历unsorted bin中的chunk,如果unsorted bin只有一个chunk,并且这个chunk在上次分配时被使用过,并且所需分配的chunk大小属于small bins,并且chunk的大小大于等于需要分配的大小,这种情况下就直接将该chunk进行切割,分配结束,否则将根据chunk的空间大小将其放入small bins或是large bins中,遍历完成后,转入下一步。
8、到了这一步,说明需要分配的是一块大的内存,或者small bins和unsorted bin中都找不到合适的 chunk,并且fast bins和unsorted bin中所有的chunk都清除干净了。从large bins中按照“smallest-first,best-fit”原则,找一个合适的 chunk,从中划分一块所需大小的chunk,并将剩下的部分链接回到bins中。若操作成功,则分配结束,否则转到下一步。
9、如果搜索fast bins和bins都没有找到合适的chunk,那么就需要操作top chunk来进行分配了。判断top chunk大小是否满足所需chunk的大小,如果是,则从top chunk中分出一块来。否则转到下一步。
10、到了这一步,说明top chunk也不能满足分配要求,所以,于是就有了两个选择: 如果是主分配区,调用sbrk(),增加top chunk大小;如果是非主分配区,调用mmap来分配一个新的sub-heap,增加top chunk大小;或者使用mmap()来直接分配。在这里,需要依靠chunk的大小来决定到底使用哪种方法。判断所需分配的chunk大小是否大于等于 mmap分配阈值,如果是的话,则转下一步,调用mmap分配,否则跳到第12步,增加top chunk 的大小。
11、使用mmap系统调用为程序的内存空间映射一块chunk_size align 4kB大小的空间。然后将内存指针返回给用户。
12、判断是否为第一次调用malloc,若是主分配区,则需要进行一次初始化工作,分配一块大小为(chunk_size + 128KB) align 4KB大小的空间作为初始的heap。若已经初始化过了,主分配区则调用sbrk()增加heap空间,分主分配区则在top chunk中切割出一个chunk,使之满足分配需求,并将内存指针返回给用户。
原文:https://blog.csdn.net/maokelong95/article/details/52006379
文章来源于网络,版权归原作者所有,如有侵权,请联系删除。
你好,我是飞宇,本硕均于某中流985 CS就读,先后于百度搜索以及字节某电商部门担任Linux C/C++后端研发工程师。
同时,我也是知乎博主@韩飞宇,日常分享C/C++、计算机学习经验、工作体会,欢迎点击阅读原文围观我分享的学习经验
我组建了一些社群一起交流,群里有大牛也有小白,如果你有意可以一起进群交流。
欢迎你添加我的微信,我拉你进技术交流群。此外,我也会经常在微信上分享一些计算机学习经验以及工作体验,还有一些内推机会。

扫描上方二维码,加我微信
我的私人微信

👇点击阅读原文查看你错过的宝藏
