关注公众号,点击公众号主页右上角“ ··· ”,设置星标,实时关注智能汽车电子与软件最新资讯

来源: 车端
该项目是一个高级驾驶辅助系统的原型,专注于感知算法(目标检测、车道线分割和交通标志分类)。它提供了3个主要功能:
它还提供了「有限的」虚拟硬件访问权限,作为迈向商业产品的一步:
但是,可以使用 GPS 模块或 CAN 转 USB 电缆收集 GPS 和 CAN 信号。我将提供一些关于如何设置这些设备的说明。
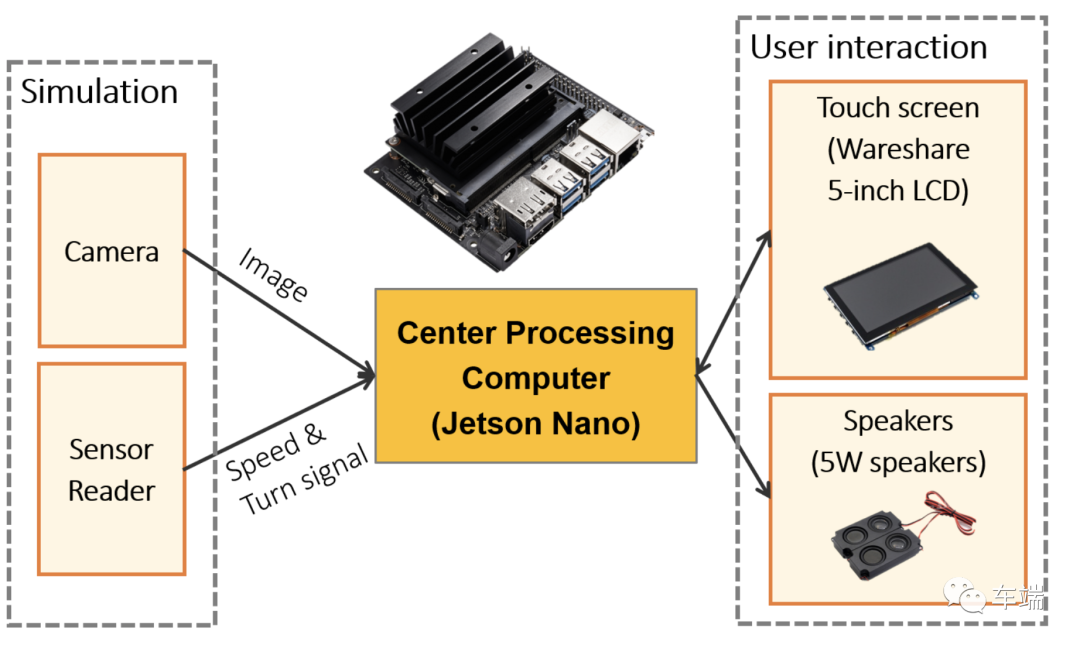
处理该项目所有输入的中心组件是中央处理器。这台计算机接收两个输入:(i) 来自相机的图像,以及 (ii) 汽车底盘数据,例如汽车速度和转向信号。中央处理负责处理这些输入以在需要时发出警告。在这个项目的范围内,由于实验条件有限,我们实施了一个「模拟模块来提供相机和传感器读取器输入的替代方案」。在商业产品中,传感器读取器模块可以通过 GPS 模块和 CAN 总线读取器(例如 CAN 转 USB 电缆)来实现;可以使用 USB 摄像头提供摄像头输入。
「硬件清单:」
「出于开发和教育目的:」
src/sensors/car_gps_reader.cpp并使用此应用程序与您的 Jetson Nano 共享 GPS 信息。这样,我们就可以获取GPS信号,估计车速。「对于商业产品:」
「基本信息」
在这个项目中,我们没有在真车上设置物理 CAN 总线(只是一个使用 socket CAN 的仿真系统)。但是,它可以通过使用 CAN 转 USB 电缆来实现。
CAN总线的一些信息:
「我们在哪里可以找到要连接的 CAN 总线?」
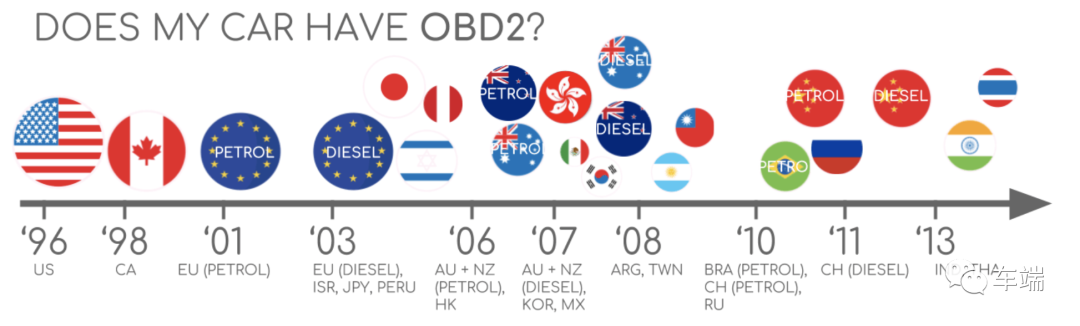
在这个项目中,我们只使用虚拟 CAN 总线,因此项目源代码仍然不支持与汽车 CAN 总线的真实连接。不幸的是,虽然 CAN 总线是汽车行业的标准,但如果您想找到您的 can 线在哪里,您通常需要查看汽车电气图才能找到内部 CAN 总线。自 1996 年以来,有一个名为 OBD2 的汽车标准,可以提供一种方便的方式连接到 CAN 总线。您可以在以下链接中找到有关 OBD2 的信息:
https://www.csselectronics.com/screen/page/simple-intro-obd2-explained/language/en
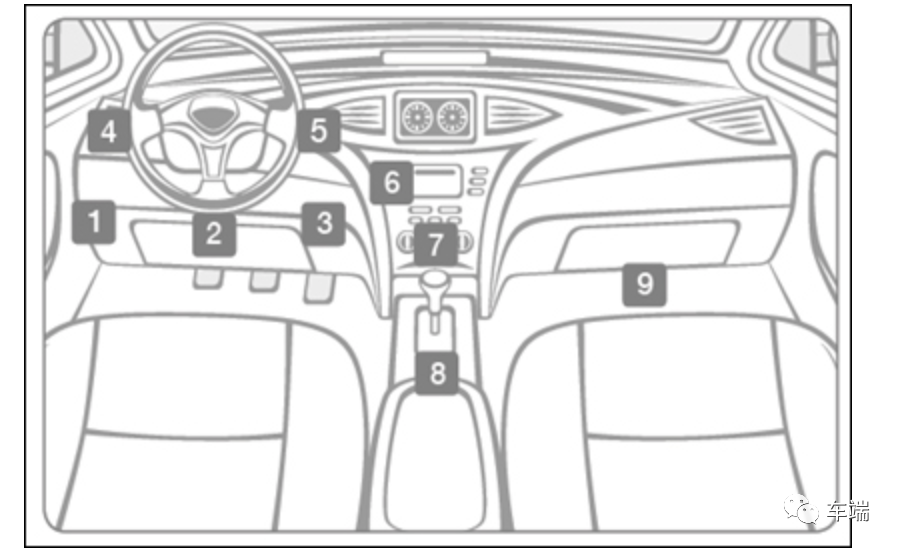
「OBD2接口在哪里?」
OBD-II 端口通常位于仪表板下方,方向盘柱下方(下图中的 1 - 3)。如果端口不在转向柱下方,请在数字 4 - 9 指示的区域中寻找端口。
「我怎样才能反转CAN工程并读取速度?」
「资源:」
您可以使用 Wireshark 或 candump 查找车速和转向灯在哪里。CAN总线是没有加密的,大家可以根据下面的说明尝试查找。
将 USB 摄像头连接到 Jetson Nano 板后,我们需要运行 OpenADAS 软件来校准摄像头。校准实际上是基于透视变换的距离估计。这是为距离计算校准相机的便捷方式。
变换参数包括从真实世界距离到鸟瞰图像空间的米到像素映射,以及鸟瞰图像到相机图像之间的透视变换矩阵。为了计算这些参数,我们使用以下解决方案:在汽车前面放一块红地毯,测量距离 W1、W2、L1、L2。地毯应该足够大,并且必须对称地放置在汽车的长轴上。
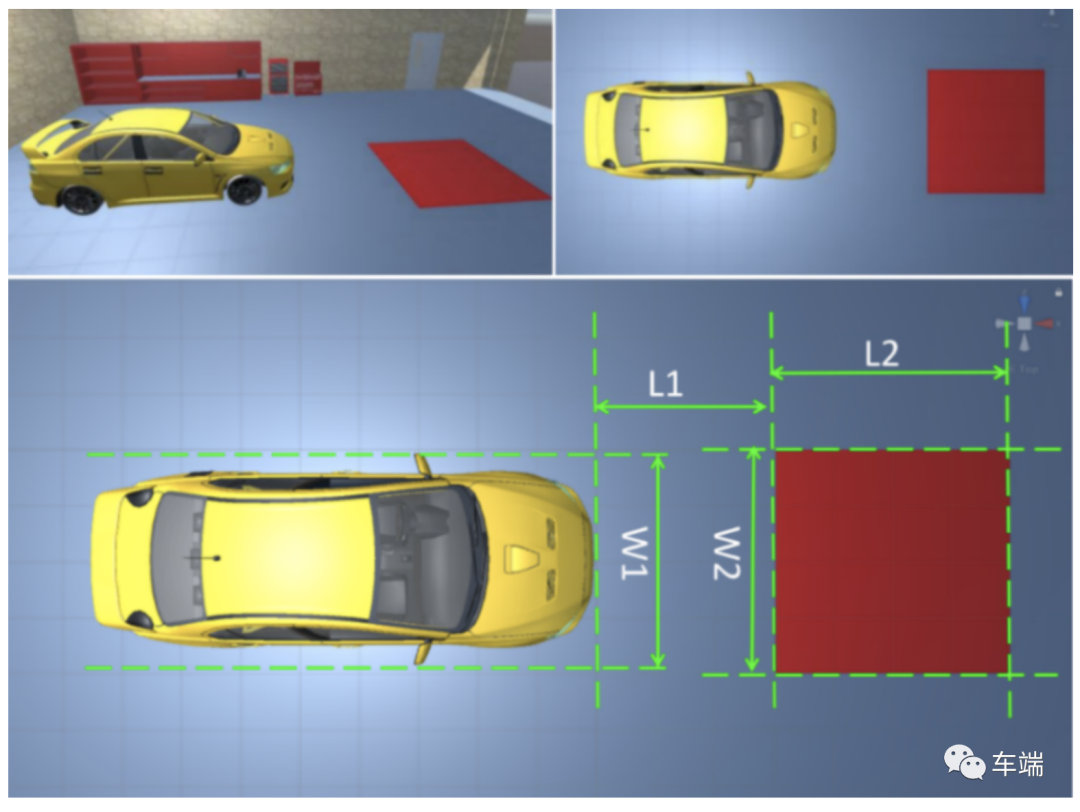
单击设置按钮以打开相机校准。

在 UI 中输入 L1、L2、W1、W2。
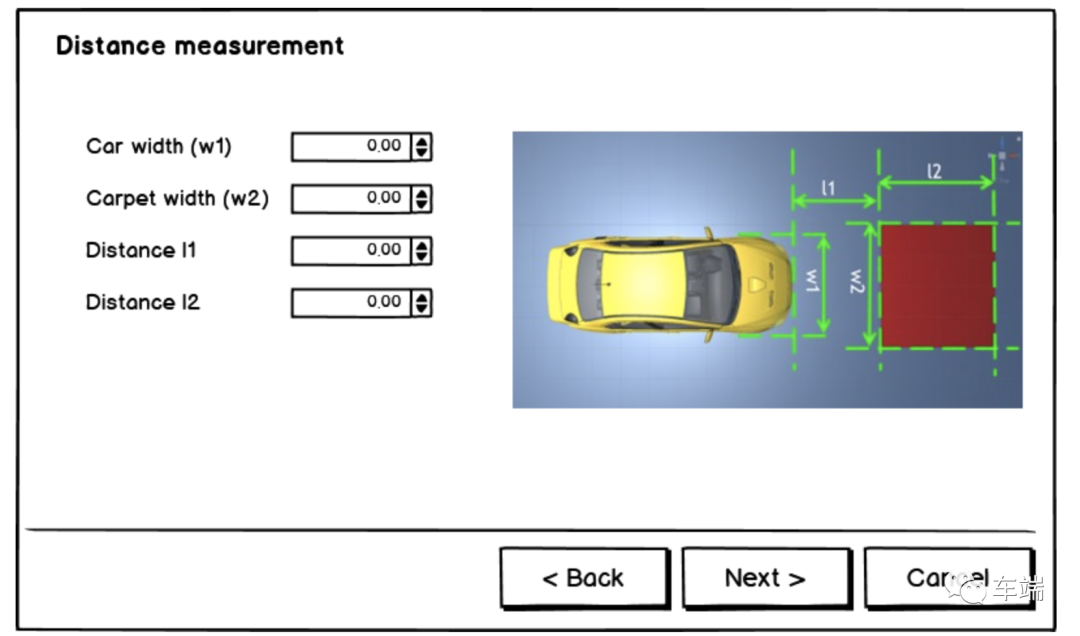
之后,通过单击「重新拍摄照片」选择 4 个点,选择一个点并移动滑块。这些点必须以正确的顺序拾取。相机标定后,标定文件将被保存data/camera_calib.txt并在每次启动程序时加载回来。
该物体检测模块负责检测前方障碍物物体,如其他车辆或行人,以及交通标志。这些结果可用于前方碰撞预警和超速预警。为了提供这些功能,该模块包含两个主要组件:基于 CenterNet 的对象检测神经网络和基于 ResNet-18 的交通标志分类网络。因此,我们将在下图中看到 2 个深度学习模型。
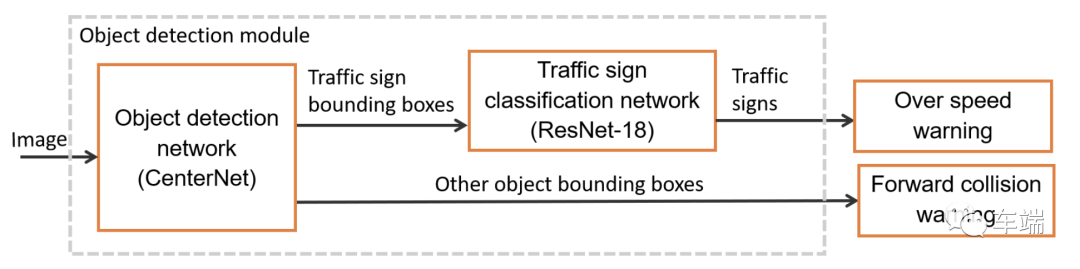
CenterNet 是一种简单但高效的对象检测模型。与其他流行的目标检测模型相比,CenterNet 可以非常有效地适应速度-精度权衡。与其他流行的基于锚框的对象检测网络不同,CenterNet 依靠关键点检测器来检测对象的中心,然后回归其他属性。
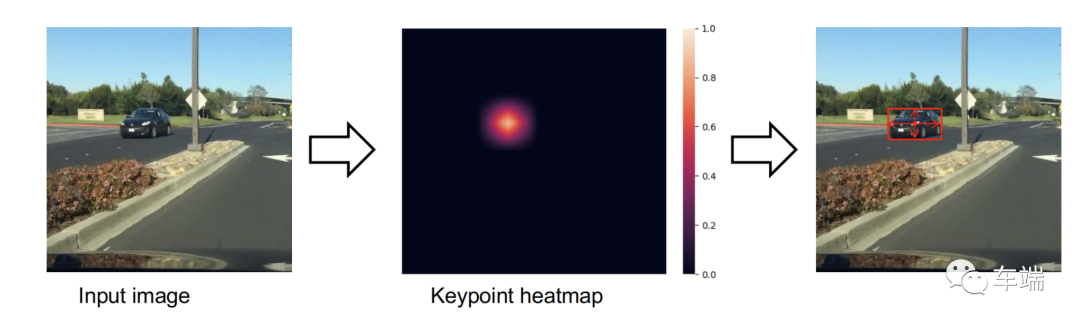
「训练」
我使用 CenterNet 作者的官方存储库来训练对象检测器(进行了一些修改)。请阅读此处的安装步骤以安装培训所需的环境。
「笔记:」
我修改了官方存储库以使用 Berkeley DeepDrive (BDD) 数据集](https://bdd-data.berkeley.edu/)。您可以在此处克隆源代码以开始训练。在我的存储库中,我用10个类训练了 CenterNet :person、、、、、、、、、和。ridercarbustruckbikemotortraffic lighttraffic signtrain
「使用 TensorRT 进行模型优化」
使用 PyTorch 框架训练 CenterNet 后,我们获得 PyTorch 模型格式(.pth)的模型文件。为了优化 NVIDIA Jetson Nano 上的推理速度,我们需要将这些模型转换为 TensorRT 引擎文件。转换是通过称为 ONNX(开放式神经网络交换)的中间格式完成的。首先使用 PyTorch ONNX 模块将 PyTorch 模型转换为 ONNX 格式(步骤 1)。之后,我们将 ONNX 模型转换为每个推理平台的 TensorRT 引擎(步骤 2)。因为从ONNX到TensorRT引擎的转换时间比较长,所以在我的实现中,我将TensorRT引擎转换后序列化到硬盘,每次程序启动时加载。在此步骤中,我们必须注意 TensorRT 引擎在不同计算机硬件上的构建方式不同。所以,

使用此存储库将预训练模型转换为 ONNX 格式:https: //github.com/vietanhdev/centernet-bdd-data-onnx-conversion。
「笔记:」
convert_to_onnx_mobilenet.py中阅读(对于 MobileNetv2 主干)和convert_to_onnx_rescdn18.py(对于 ResNet-18 主干)中的一些转换示例源代码。src/configs/config_object_detection.h. 您还可以使用此存储库进行转换。由于「BDD 数据集」的限制——它只包含 1 类交通标志(未指定标志类型),我不得不训练另一个神经网络来识别标志类型。由于速度和准确性高,因此也选择了「ResNet-18来完成这项任务。」我使用 Tensorflow 和 Keras 框架训练了模型。
「数据集」
在这个项目中,我只设计了对最大速度标志进行分类的系统,并将每个速度级别视为一个单独的对象类。为了收集足够的训练数据,我使用了 2 个数据集:Mapillary Traffic Sign Dataset (MTSD) 和 German Traffic Sign Recognition (GRSRB) 数据集。由于 MTSD 是一个交通标志检测数据集,我使用标志边界框来裁剪它们以进行分类任务。裁剪后,我合并了 2 个数据集,得到 18,581 个最高限速交通标志图像分为 13 个类别,以及 879 个末端限速标志(将所有末端限速标志仅视为 1 类)。此外,我使用来自其他交通标志和物体的 20,000 张裁剪图像作为“未知”类别。该数据集中共有 15 个类别:最大速度标志(5km/h、10km/h、20km/h、30km/h、40km/h、50km/h、60km/h、70km/h、80km/h , 90 公里/小时, 100 公里/小时, 110km/h、120km/h)、限速终点(EOSL)等标志(OTHER)。之后,这个数据集被分成 3 个子集:训练集(80%)、验证集(10%)和测试集(10%)。每个交通标志类别的分布是随机的。
「训练步骤」
使用此存储库中的源代码来训练交通标志分类器:https://github.com/vietanhdev/traffic-sign-classification-uff-tensorrt。
创建anaconda环境:
conda create --name
激活创建的环境并安装所有要求:
pip install requirements.txt
准备如下结构的数据集:
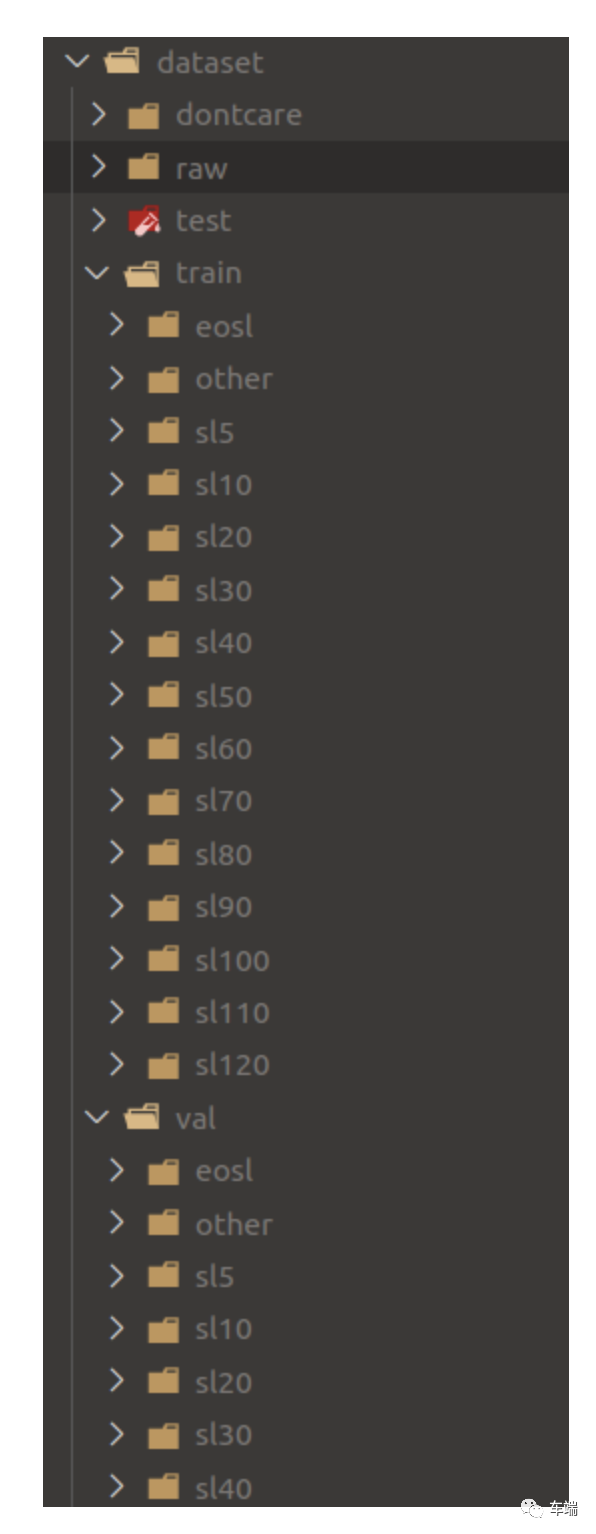
使用以下命令训练模型:
python train.py
「使用 TensorRT 进行模型优化」
转换为 UFF
convert_h5_to_pb.py修改和中的模型路径convert_pb_to_uff.py。
将.h5模型转换为.pb, 最后.uff:
pip install requirements-h5-to-uff.txt
python convert_h5_to_pb.py
python convert_pb_to_uff.py
src/configs/config_sign_classification.h.车道线检测模块负责检测车道线和车道偏离情况。然后将该结果用于车道偏离警告。我使用深度神经网络和霍夫变换线检测器进行车道线检测。下面介绍车道线检测的流程。
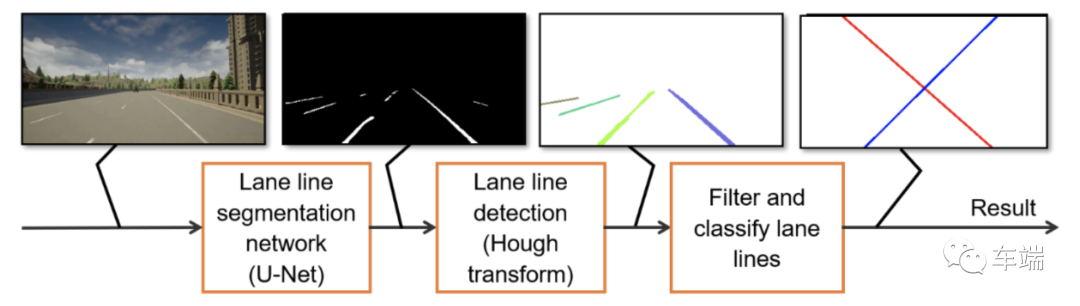
车道线检测流水线
U-Net 是一种在生物医学图像分割中表现良好的全卷积网络,它可以用较少的训练图像数据展示高精度的分割结果。我将 U-Net 应用于车道线分割问题,并结合霍夫变换以线方程的形式找到车道线。
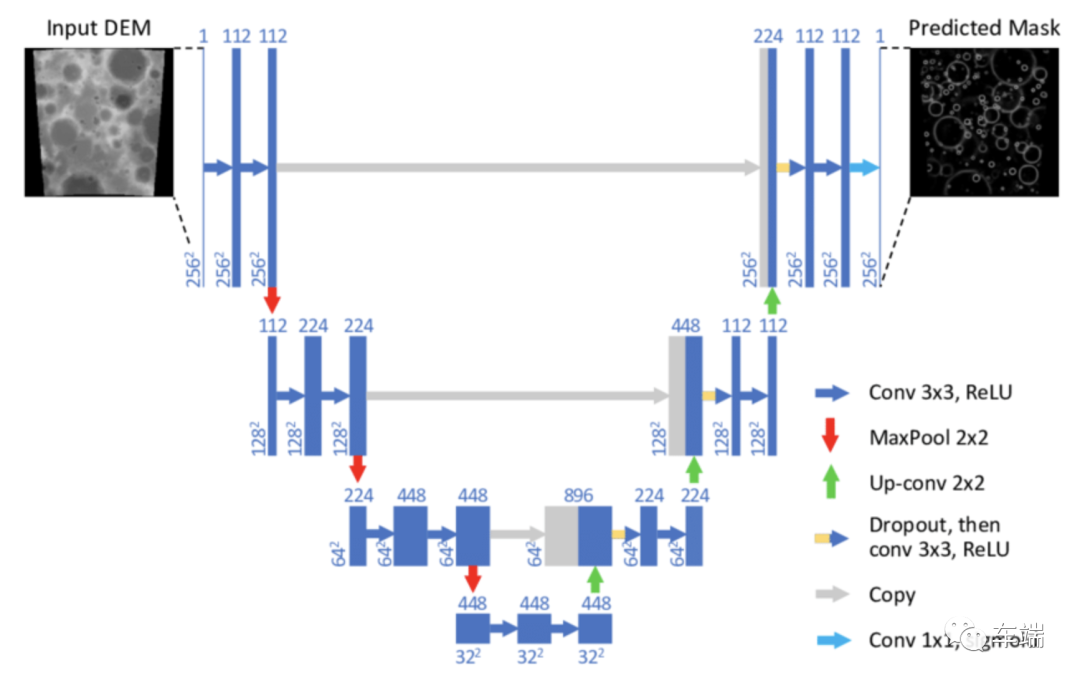
U网模型
为了在嵌入式硬件上运行轻量级分割模型,我对原始 U-Net 模型进行了两次修改:
(1) 将decoder filters的数量调整为128, 64, 32, 16, 8个filters,从decoder的顶部到网络的输出;
(2) 用 ResNet-18 主干替换原来的主干。
这些修改减少了 U-Net 中的参数数量,并为我们提供了一个可以超过 200 帧每秒 (FPS) 运行的轻量级模型(模型 U-Net ResNet-18 输入大小 384x382,RTX 2070 GPU 上的 TensorRT float 16 ).
数据集是从Mapillary Vista 数据集准备的,并进行了一些修改。原始数据集包含训练集中约 18000 张图像和验证集中约 2000 张图像。我合并这些集合,删除一些不包含车道线或有太多噪音的图像。最终数据集有 15303 张图像。我将这个集合随机分成三个子集:10712 张图像用于训练(~70%),2296 张图像用于验证(~15%)和 2295 张图像用于测试(~15%)。因为 Mapillary Vista 的标签包含很多对象类,所以我只保留车道线类来生成二值分割掩码作为新标签。

Mapillary Vistas 数据集预处理——图像 A、B 来自 Mapillary Vitas
使用我的存储库训练 U-Net 进行车道线分割:https://github.com/vietanhdev/unet-uff-tensorrt。
创建anaconda环境:
conda create --name
激活创建的环境并安装所有要求:
pip install requirements.txt
在目录中创建新的配置文件list_config请不要修改旧的配置文件,以便我们更好地观察,模型和训练历史将自动保存到saved_models文件夹中。
对于培训,只需运行:
python model/train.py
或者
./train.sh
转换为 UFF
为此任务创建另一个虚拟环境。
convert_h5_to_pb.py修改和中的模型路径convert_pb_to_uff.py。
.h5将模型转换为.pb,并最终使用这些命令(请更新和.uff中模型的正确路径)convert_h5_to_pb.pyconvert_pb_to_uff.py
pip install requirements-h5-to-uff.txt
python convert_h5_to_pb.py
python convert_pb_to_uff.py
src/configs/config_lane_detection.h.霍夫变换是一种在图像处理中非常有效的线检测算法。该算法的总体思想是创建从图像空间(A)到新空间(B)的映射,空间(A)中的每条线对应空间中的一个点(B),空间中的每个点(A)对应空间中的正弦曲线 (B)。将 (A) 中的所有点投影到空间 (B) 中的正弦曲线后,我们找到交点密度最高的地方。然后将这些位置投影到 (A) 成线。通过这种方式,霍夫线变换算法可以在图像空间(A)中找到线。
寻找候选车道线的过程如下图所示。从线分割网络产生的分割掩码,车道线检测模块使用概率霍夫变换来检测原始线段(1)。之后,使用由 Bernard A. Galler 和 Michael J. Fischer 在 1964 年反转的不相交集/联合查找森林算法将这些线划分为组。我们使用线之间的空间距离和角度差将属于一个线段分组同一条线。经过步骤(2),我们可以看到不同的线组被绘制成不同的颜色。步骤 (3) 接收这些线组作为输入,并使用具有 L2 距离的最大似然估计在每个组中拟合一条线。

线候选检测
该系统将车道分割模型与上述车道检测算法相结合,可以检测不同环境下的车道线,判断车道偏离情况。它为车道偏离警告模块创建可靠的输入。
该系统使用基于规则的警告算法。请在以下博客文章和源代码中查看一些警告规则:
https://aicurious.io/posts/adas-jetson-nano-software/#iii-software-implementation
关注公众号,点击公众号主页右上角“ ··· ”,设置星标,实时关注智能汽车电子与软件最新资讯
