今日光电

包括了适用于传统图像的数据处理和深度学习的数据处理。

在过去几年从事多个计算机视觉和深度学习项目之后,我在这个博客中收集了关于如何处理图像数据的想法。对数据进行预处理基本上要比直接将其输入深度学习模型更好。有时,甚至可能不需要深度学习模型,经过一些处理后一个简单的分类器可能就足够了。
最大化信号并最小化图像中的噪声使得手头的问题更容易处理。在构建计算机视觉系统时,应考虑使用滤波器来增强特征并使图像对光照、颜色变化等更加稳健。
考虑到这一点,让我们探索一些可以帮助解决经典计算机视觉或基于图像的深度学习问题的方法。相关的代码仓库:https://github.com/bikramb98/image_processing。
在应用最新和最好的深度学习解决问题之前,请尝试经典的计算机视觉技术。特别是在数据可能稀缺的情况下,就像许多现实世界的问题一样。
检查计算图像像素的统计值(例如均值、峰度、标准差)是否会导致不同类别的统计值不同。然后可以在这些值上训练一个简单的分类器,例如 SVM、KNN,以在不同的类之间进行分类。
在将它们输入深度学习模型之前,检查预处理技术是否增强了图像的主要特征并提高了信噪比。这将有助于模型获得更好的准确性。
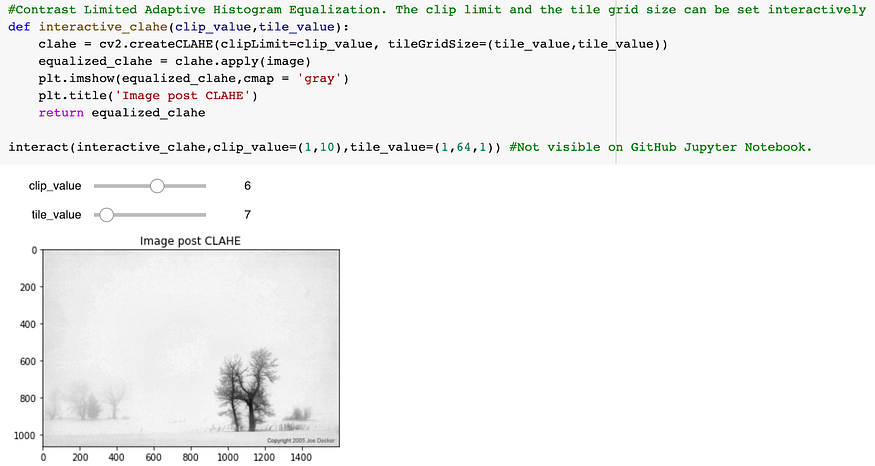
找到滤波器、阈值等不同kernel大小的最佳组合(其组合可能达到数百万!),可以产生产生最佳效果的图像,可以通过构建交互式滑块来帮助找到这些值的理想范围。
增强图像特征的另一种方法是使用直方图均衡化。直方图均衡化提高了图像的对比度。直方图均衡化的目的是使出现频率最高的像素值均匀分布。
让我们看看下面的例子。

可以看出,上图的对比度非常低。在这种情况下,重要的是要提高对比度,使图像的特征更清晰可见。OpenCV 提供了两种这样做的技术 —— 直方图均衡化和对比度受限自适应直方图均衡化 (CLAHE)。
应用直方图均衡化,图像的对比度确实有所提高。但是,它也会增加图像中的噪点,如下图中间所示。
这就是CLAHE 的用武之地。使用这种方法,图像被分成 m x n 网格,然后将直方图均衡应用于每个网格。可以使用交互式滑块找到理想的对比度阈值和网格大小,如下所示。

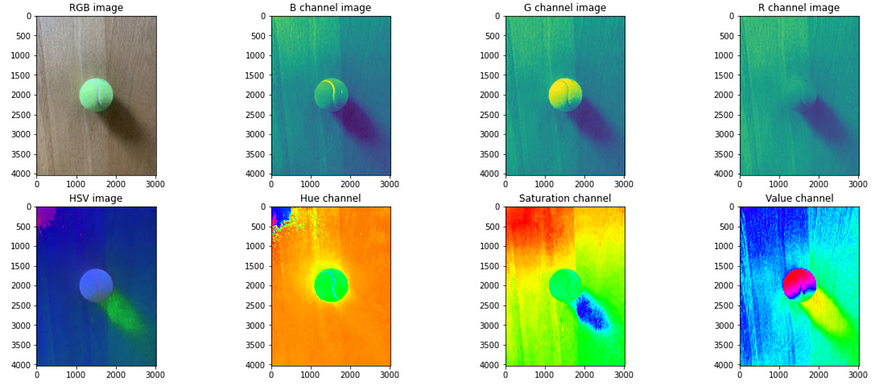
将图像转换到不同的颜色空间,例如 HSV,通常可以提供更好的信息来分割目标,用于目标跟踪等情况。通常,RGB 颜色空间对阴影、光照的轻微变化(影响目标的颜色)不稳健。对于使用经典计算机视觉进行目标跟踪等任务,由于上述原因,在稍有不同的环境中使用时,RGB 空间中经过调试的mask通常会失败。此外,一旦将图像转换为不同的空间(例如 HSV),分离通道通常有助于分割感兴趣的区域并消除噪声。如下图所示,一旦将图像转换为 HSV 空间并拆分通道,就可以更轻松地去除阴影并分割网球。
如果将图像输入深度学习模型,则必须使用批归一化等技术对图像进行归一化,这将有助于标准化网络的输入。这将有助于网络学习得更快、更稳定。批量归一化有时也会减少泛化误差。
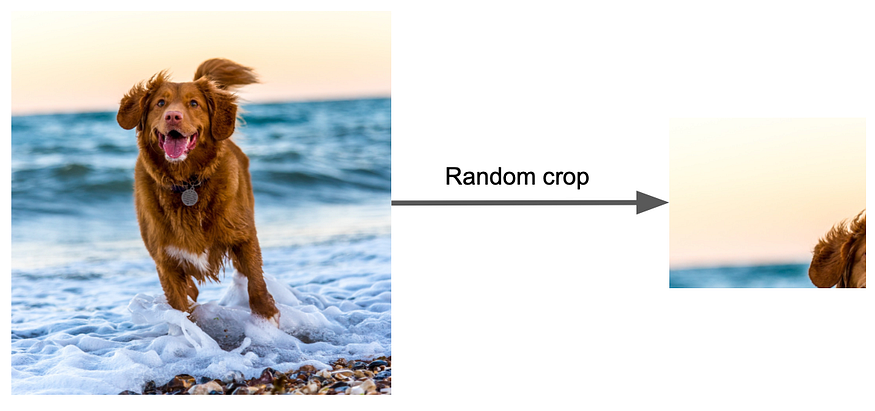
在增强图像时,确保应用的增强技术保留图像的类别并且类似于现实世界中遇到的数据。例如,对狗的图像应用裁剪增强可能会导致增强后的图像不像狗。在某些目标使用旋转和翻转进行增强的情况下也是如此。在增强时更改图像属性(例如颜色)时要非常小心。此外,请确保扩充数据不会更改图像的标签。
始终检查增强图像是否有意义并反映现实世界。
确保相同的图像(比如原始图像和增强图像)不在训练集和验证集中同时出现是很重要的。这通常发生在训练验证集拆分之前就执行数据增强。忽略这一点可能会导致给出错误的模型指标,因为它会在训练期间从非常相似的图像中学习,这些图像也存在于验证集中。
确保测试集和验证集包含所有标签样本。这样模型指标反映的才是模型的真实表现。
以其中一个标签的样本数量明显较少的情况为例。执行随机训练集测试集拆分可能会导致更少标签的类根本不会出现在验证/测试集中。当训练好的模型被测试时,它不会在那个特定的类上被测试,模型指标也不会反映其性能的真实表现。
模型训练好之后,执行一些完整性检查也很重要:
来源:机械视觉沙龙
申明:感谢原创作者的辛勤付出。本号转载的文章均会在文中注明,若遇到版权问题请联系我们处理。

----与智者为伍 为创新赋能----

联系邮箱:uestcwxd@126.com
QQ:493826566


