
似乎每次看到来自Google Research的论文都挺清新的,这一次也不例外。老实讲,有关提升覆盖率的论文至少有20年以上的历史了,但可惜的一点是,它们要么是躺在论文里,要么就是对使用者具备用于较深的设计相关知识,总是不方便落地的。
这篇论文先是回顾了两种之前的典型方法。


第一种是基于要测试的目标设计,构建并且维护一个准确的模型。我至今还记得大概7、8年前查阅这些论文时,总能遇到一些关键词,比如"biased"、"bayesian"、"automatic"、"convergency"等。也有印象这一批论文其中要根据设计构建的模型也颇为复杂。另外,它们多数都是project specific,以至于在过去的20年,EDA公司并没有基于这些论文开发出什么对应的工具。
第二种被称为数据驱动(data-driven)的CDG(coverage directed generation)。因为这是将(线上采集的)覆盖率数据反馈给了激励端,通过智能化的方式对覆盖率数据进行分析,再影响激励端。这个主意是在过去几年人工智能发展的背景下,引入到了EDA公司,而且也已经有对应产品或者特性了。
比如Cadence公司的Xcelium ML特性,即可以根据通过已经执行的regression数据,结合machine learning技术帮助提升随机约束的生成效率,最多可以提升5倍的随机测试regression效率,帮助更快达到100%的覆盖率目标。
https://www.cadence.com/zh_CN/home/company/newsroom/press-releases/pr/2020/cadence-delivers-machine-learning-optimized-xcelium-logic-simula.html


但这种方法也如论文中评论道,整体效果如何严重依赖其用于训练的数据规模,这也意味着前期必须有相当规模的回归测试数据交给算法模型,以便让它学习覆盖率和激励之间的联系。
以上的两种方法中,第一种需要用户手动在覆盖率和模型之间建立准确的关系,无法做到让工具去实现更大场景的应用;第二种虽然无需自己去阐述激励和覆盖率之间的关系,但也需要前期给算法模型“投喂”足够数量的回归数据,才能帮助其更有效地产生随机数据。
于是这篇论文提出了一种(在我看来可能有EDA工具化可能的)既能实现可能快速提升覆盖率,也能在早期投入较少运算资源(比如准备大量的回归数据)的方法,论文称该方法为CDG(coverage dependency graph)。
由于论文中牵扯到具体的算法描述,在这里就不做描述。我们只说它的思路和实际效果如何。因为它既想实现更广阔的的应用(就不能针对特定设计建模),也不想在早期投喂回归覆盖数据(不采取在激励和覆盖率之间的模糊探寻联系的算法策略),于是它希望在开始测试前,就可以分析出来覆盖率和可能引起覆盖率变化的变量之间的关系。
整个工作的开题就落在了上面这句话。这里我再举个例子来说说它的意义。Siemens的PSS工具inFact,该工具有2个核心特性,除了支持PSS以外,它还能够分析sequence item的变量与对应的function covergroup,帮助它们自动完成映射,并且将inFact engine与Questa同时启动仿真,显著加速该覆盖率的提升速率。这是由于sequence item的变量一旦与covergroup形成关联,那么Questa的RNG(random number generator)在每次随时产生数据时就能够做到足够高效,它的目标就是为了提升覆盖率而只去产生有效的随机数据组合。
https://verificationacademy.com/verification-horizons/november-2020-volume-16-issue-3/increasing-functional-coverage-by-automation-for-zetta-hz-high-speed-cdma-transceiver
不过可惜的一点是,如果在sequence item的变量与covergroup中监测的变量无法做到直接关联的话,inFact的工具在这时就会失效(以2020年该工具的版本做参考)。它还无法做到进一步分析,将covergroup的变量与sequence item中的rand variable之间做分析。这中间缺少一个环节,那就是相关变量的驱动分析。
加入covergroup中关心的变量varC是由varB影响的,而varB变量的驱动是由varA影响的,而varA变量是由验证环境的sequence item的rand varR影响的,那么这种驱动关系就可以帮助建立起来,即varR-->varC的间接关联。
而这个主意恰恰是这篇论文要带来的,它通过Verific(verific.com)公司的SV/VHDL/UPF parser解析工具,可以很快对设计构建起来模型,并且利用C++/Python/Perl等API接口,获得以上的变量之间的关联。
一旦可以通过模型,获得例如varR与varC之间关联,那就相当于在inFact基础上又进了一步(inFact在使用过程中,并没有在pre-process过程中做类似的变量关联分析,这一点较为可惜),使得具备了基本的条件,可以在更为明确的rand变量和关联的各个covergroup之间引导生成更为合理的随机数据。
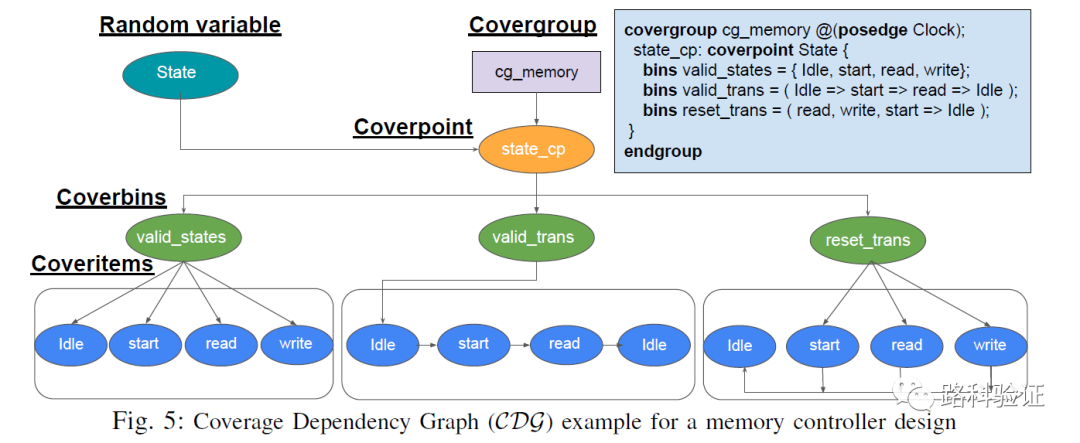
一旦分析出coverage dependency graph,接下来就是需要在动态的过程中调整随机约束的分布(constraint distribution),这里使用了MLE(maximum likelihood estimate)公式。

通过以上两个关键步骤(设计分析得出驱动关联,以及根据覆盖率报告和分布权重产生新的随机约束),就可以将论文中的CDG4CDG流程植入到已有的验证环境中。在这种情况下,每一轮回归测试前就可以重新调整随机分布,继而在下一轮回归时获得更为有效的随机数据,继而提供覆盖率。
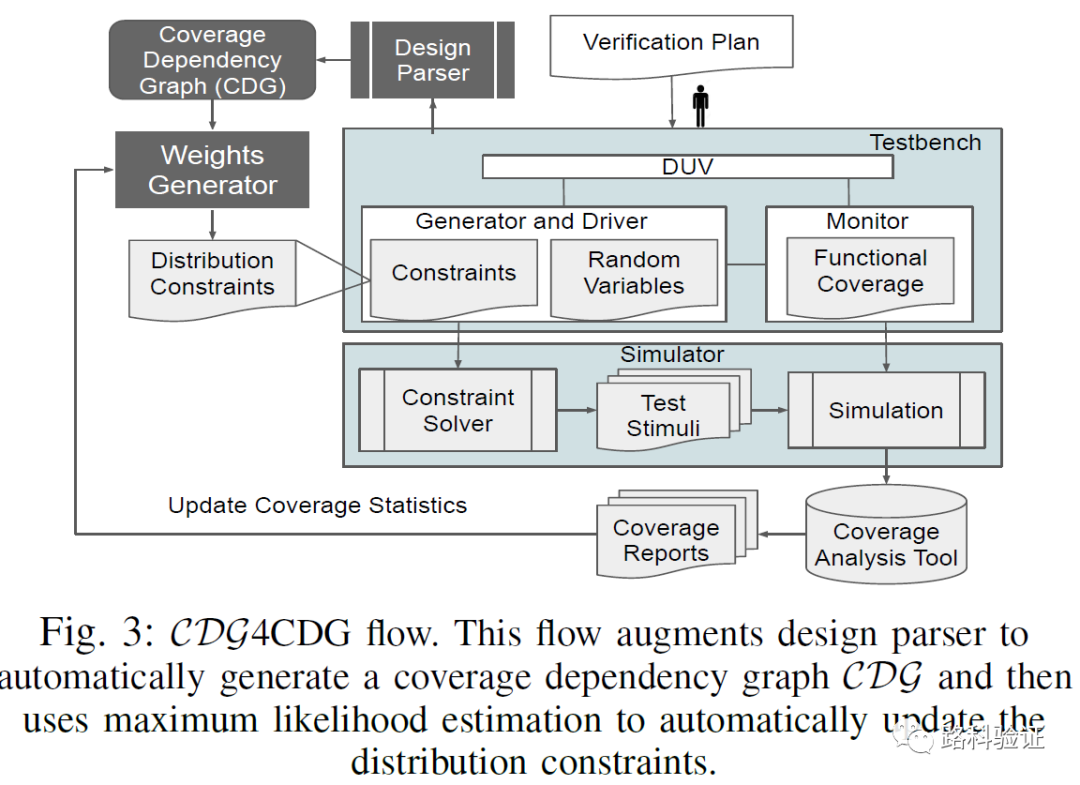
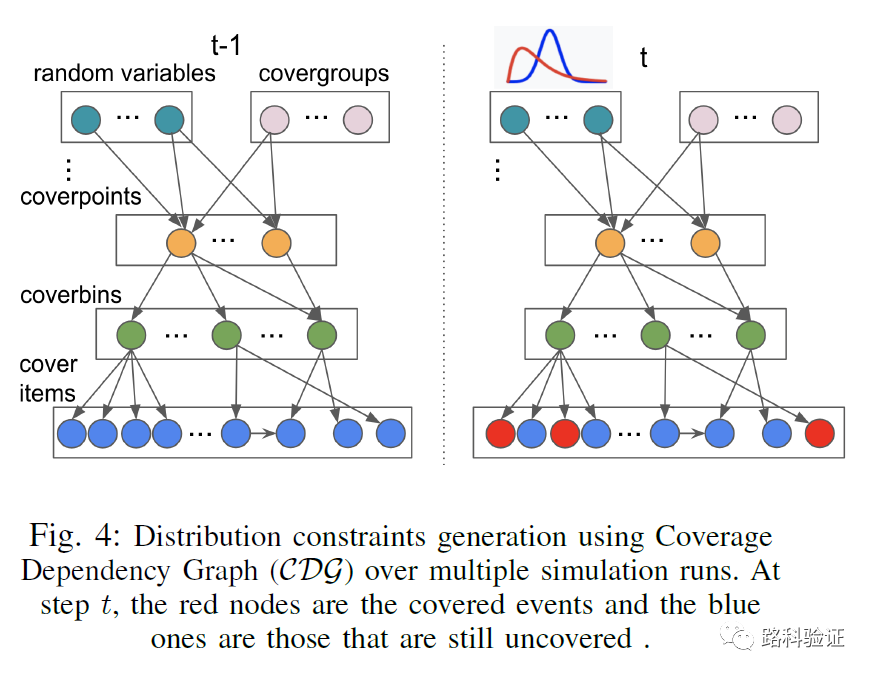
这个流程有广泛应用的场景,因为对于EDA公司而言,它们有自己内部的parser工具和编译好的设计模型,只需要做适当处理即能够在sequence item rand variable和covergroup sampled variable之间找到关联,而论文中的有关调整权重的算法也有机会得到进一步优化。这么看起来,这个方法更适合嵌入到inFact中,使得这个工具得到进一步提升。
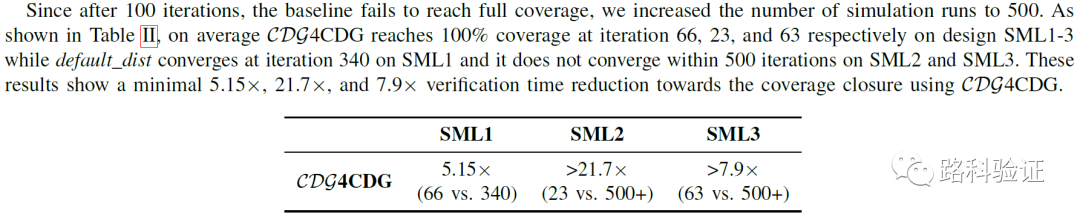
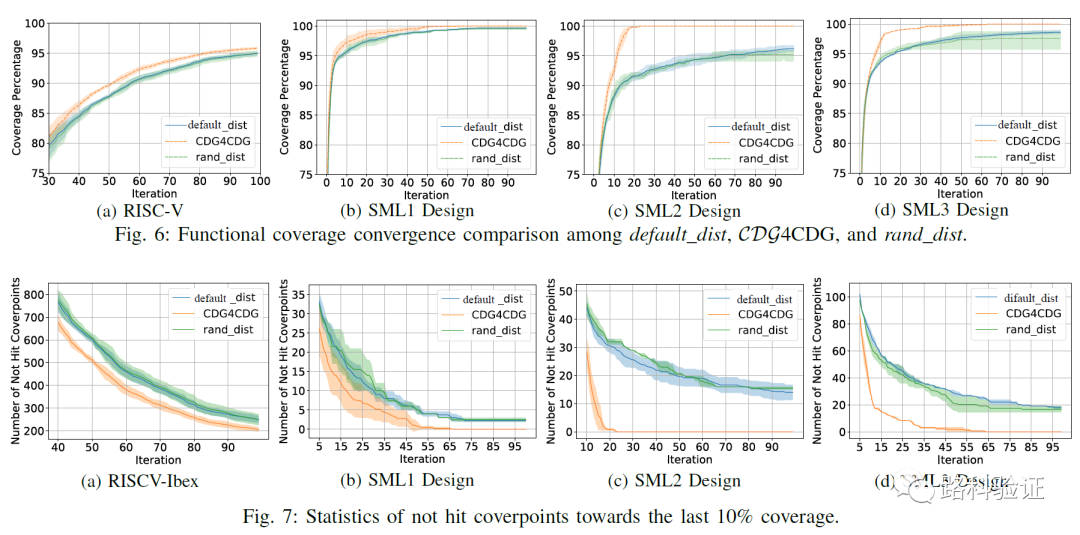
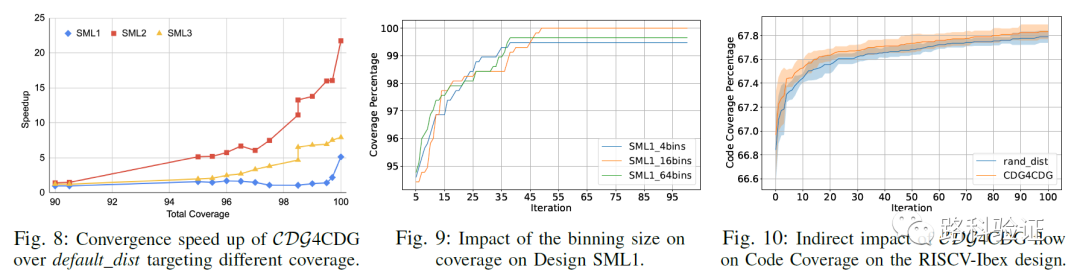
从最后的数据来看,CDG4CDG这个方法对最终覆盖率收敛(尤其是在最后的90%-100%之间的提升效率)尤为明显。以覆盖率达到100%为目标,CDG4CDG要比固定约束分布的效率提升在5倍-20倍之间。而且在这中间,并不意味着要先生成大量的回归数据,像machine learning要求的那样学习大量数据,这也节省了相当一部分的运算资源。
纵观全文,我很同意文中的一个词"harness"(给马套上马具,表示利用的意思),即在我们有限的知识、能力的前提下,尽量把它们用好,即便脚下开的车不是阿斯顿马丁,马自达也能够有出色发挥。

往期精彩:
DVCon文赏-2023w13 一种智能网卡的形式验证流程
DVCon文赏-2023w14 一种用于AI视觉处理芯片的验证加速方案

