


介绍
GPU 发起的通信
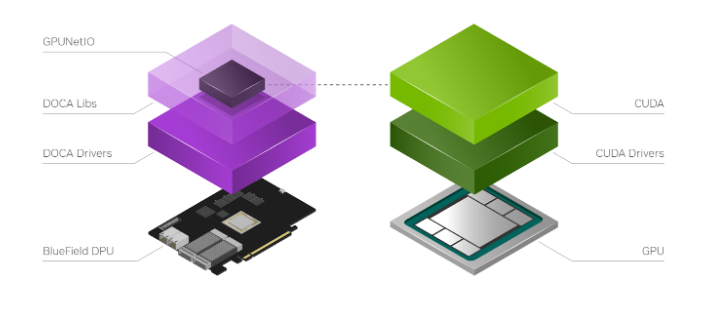
NVIDIA DOCA GPUNetIO 库
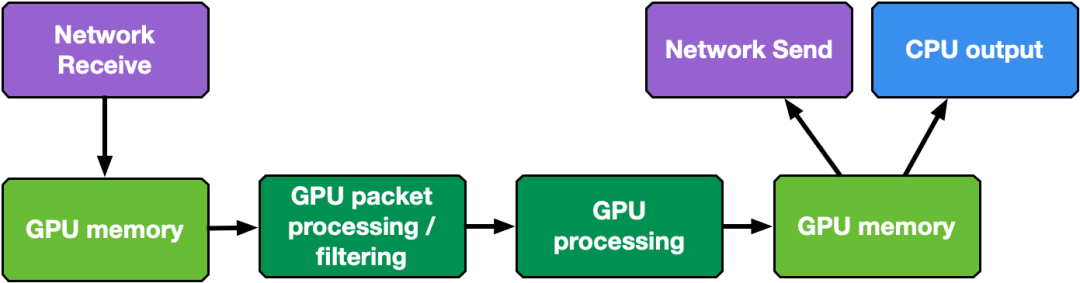
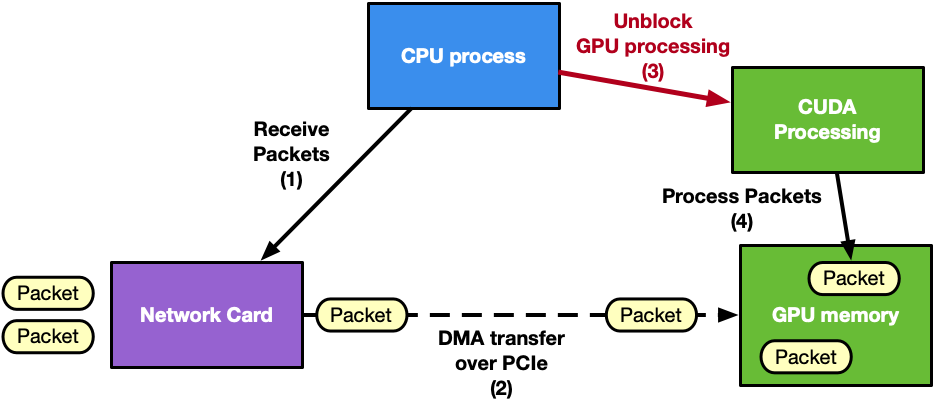
CPU 接收和 GPU 处理
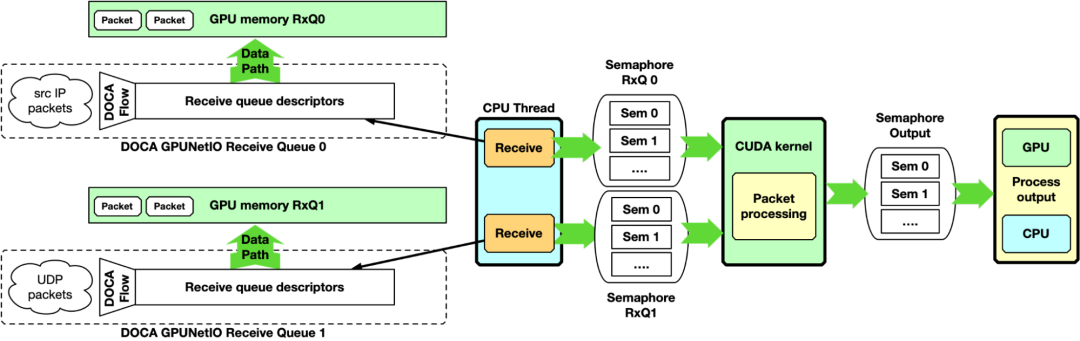
GPU 接收和 GPU 处理
多 CUDA 内核
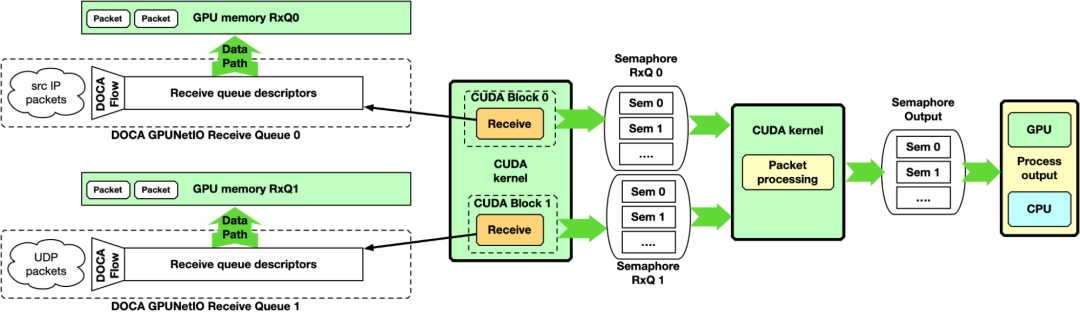
单 – CUDA 内核
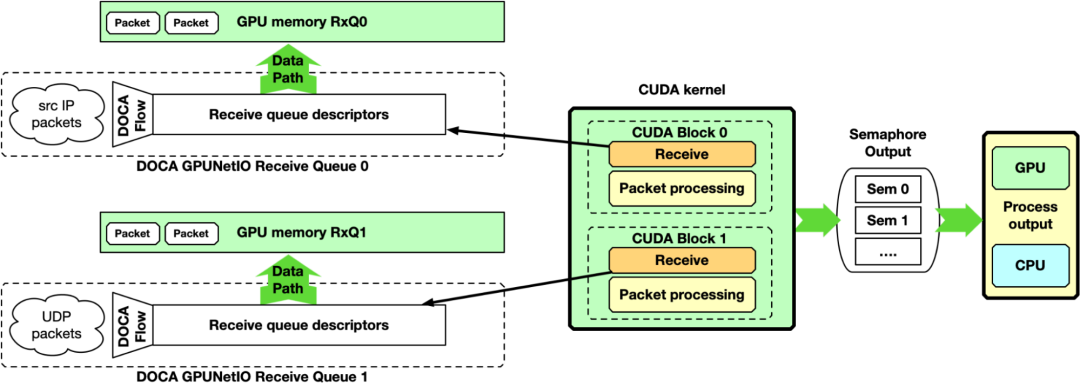
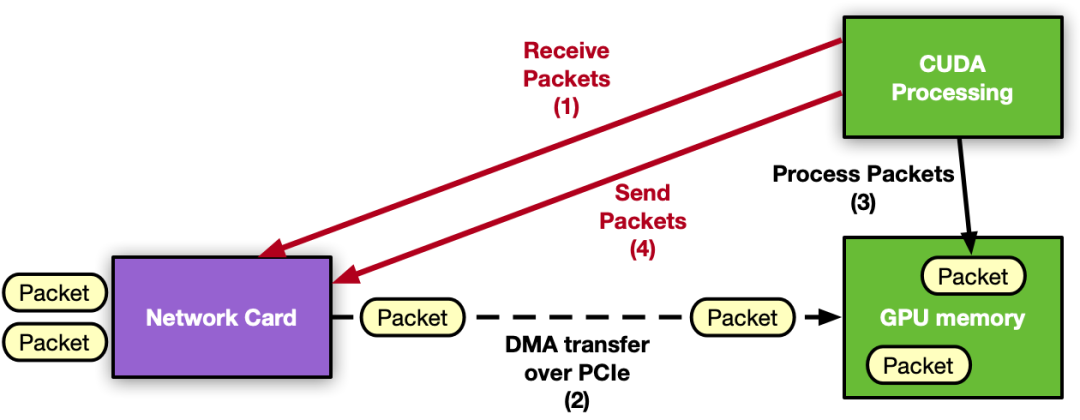
GPU 接收、 GPU 处理和 GPU 发送
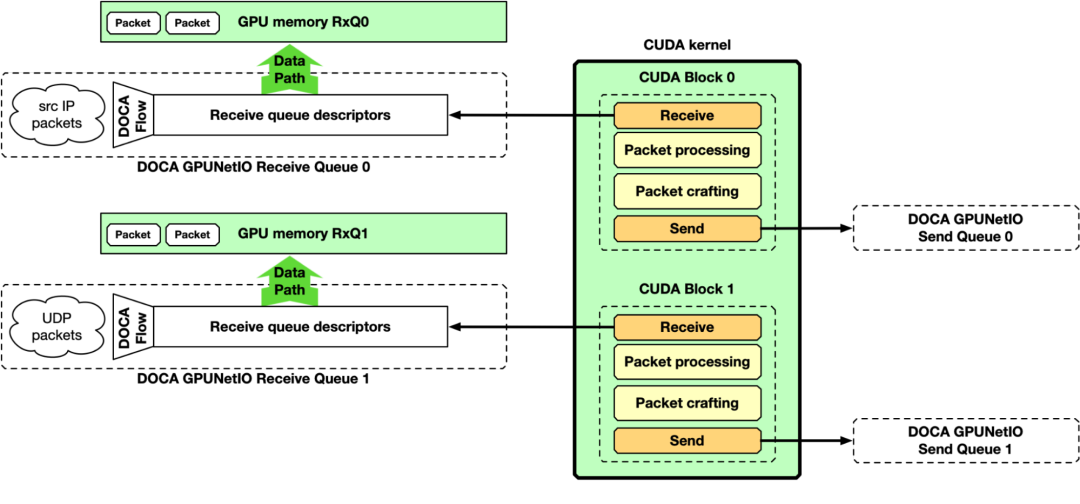
NVIDIA DOCA GPUNetIO 示例应用程序
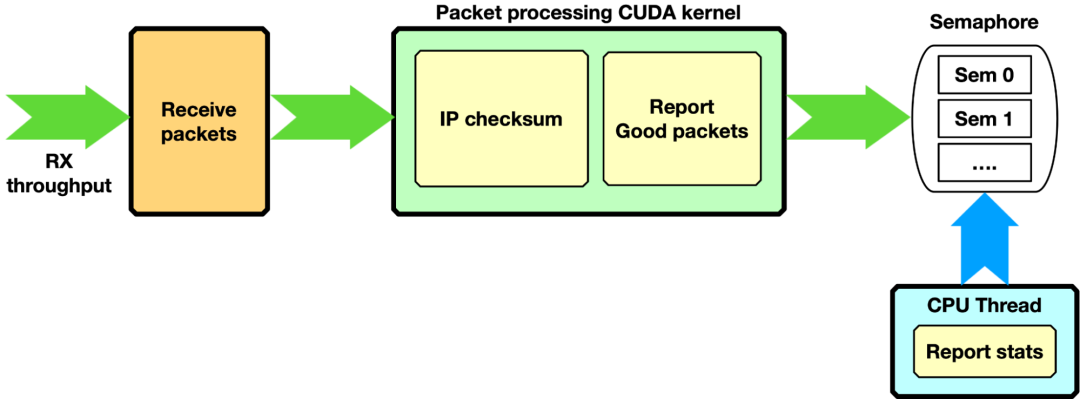
IP 校验和, GPU 仅接收
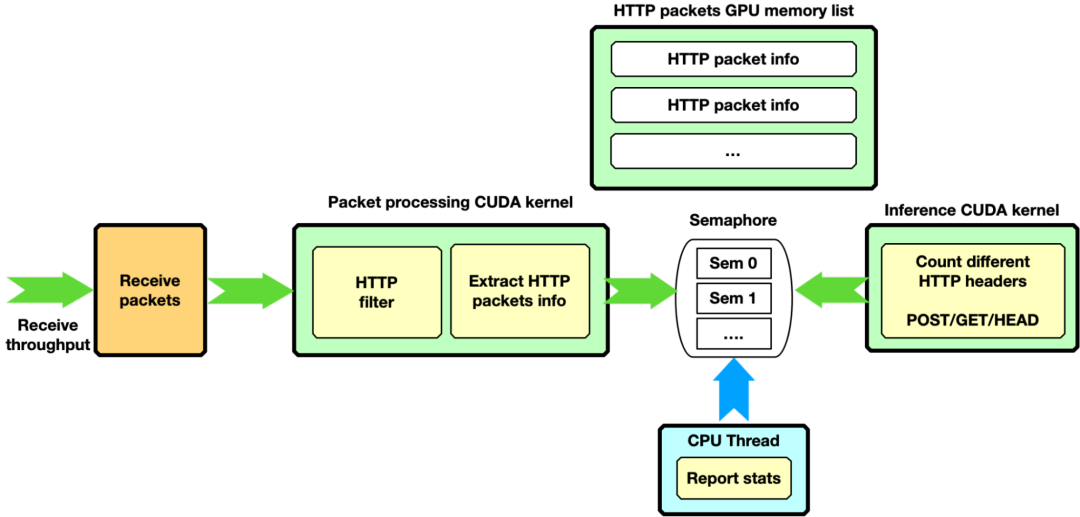
HTTP 过滤, GPU 仅接收
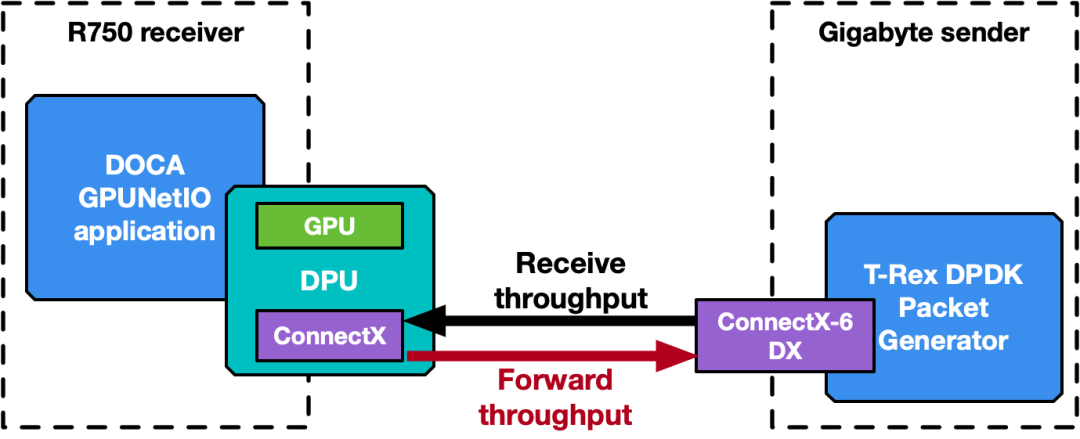
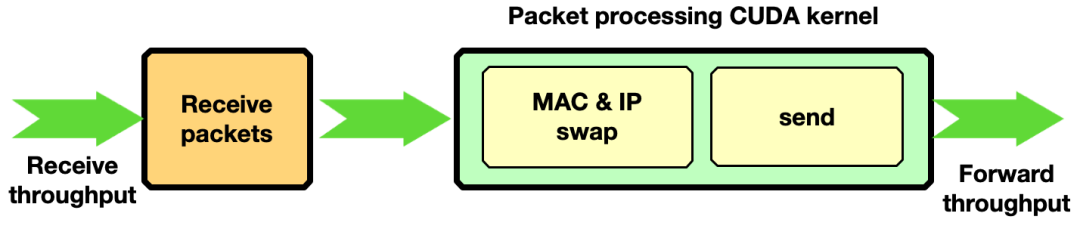
流量转发
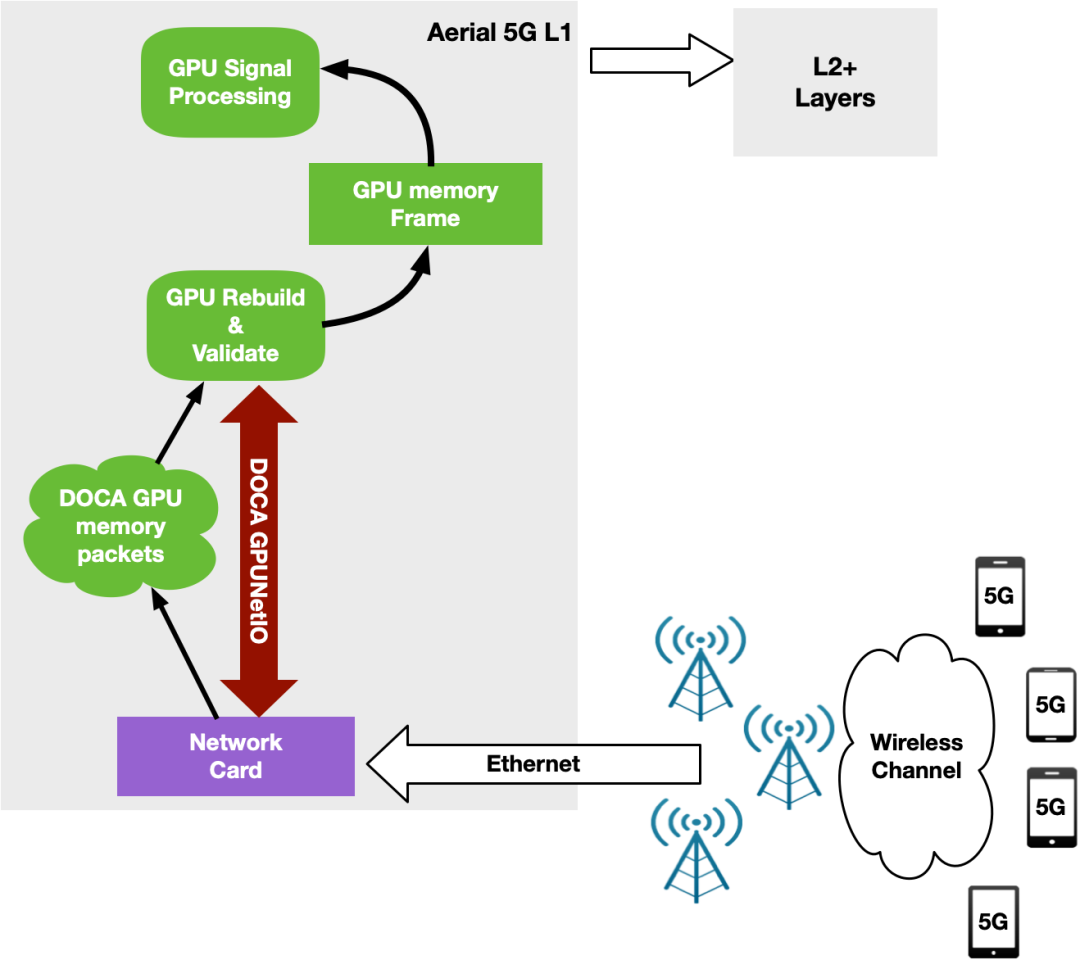
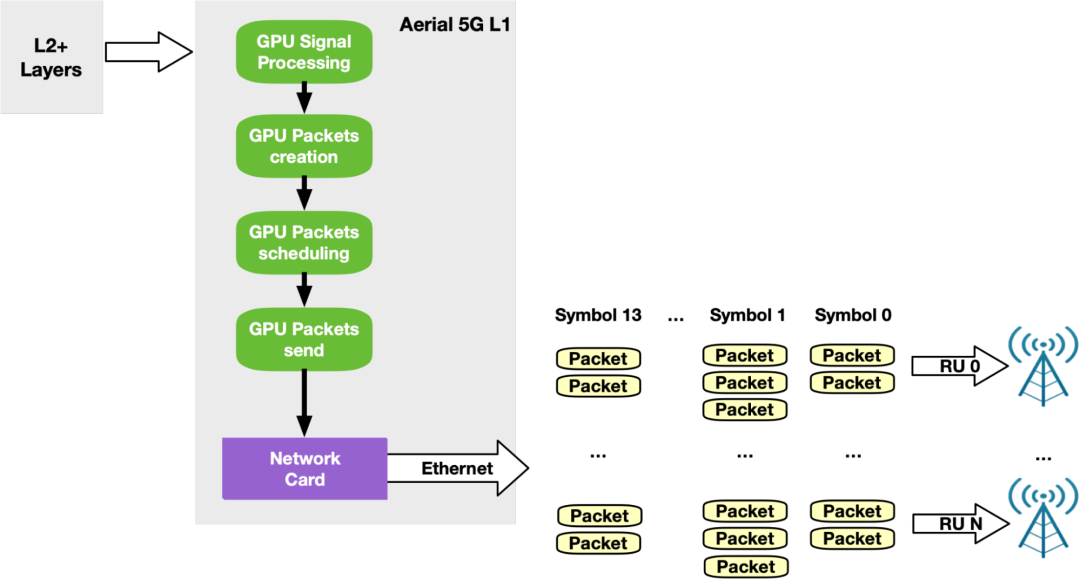
用于 5G 的 NVIDIA Aerial SDK
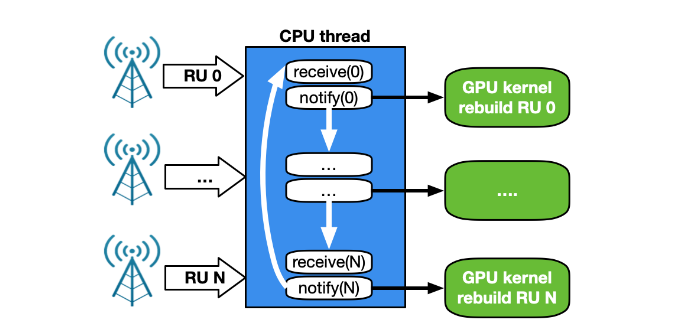
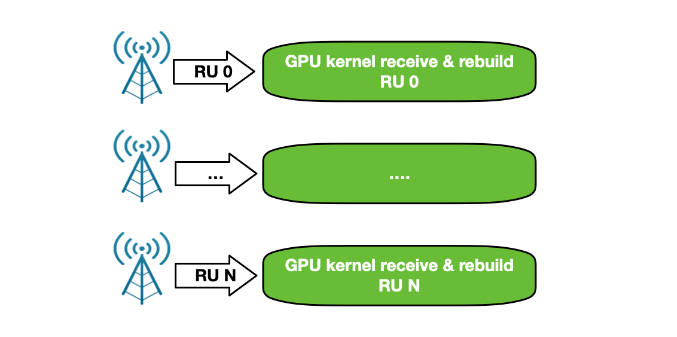
尽早访问 NVIDIA DOCA GPUNetIO
《算力时代关键技术报告汇总》
1、算力感知网络CAN技术白皮书
服务器基础知识全解PPT(终极版)
服务器基础知识全解PDF(终极版)


