
目录:
最近又过了一遍海明码,就想着给大家分享分享。在写作的过程中,同时又解决了很多疑惑。真应了教学相长这句话。文章内容较多,建议先收藏,空闲时在观看。
在数据通讯方面,要求信息传输具有高度的可靠性,即要求误码率足够低。然而实际会有各种干扰对信号造成不良的影响,致使数据在传输过程中出错。
为了满足通讯要求,减少误码出现,一方面要提高硬件的质量,另一方面可以采用差错控制编码。
差错控制编码的基本思想是:在发送端被传送给的信息码序列的基础上,按照一定的规则加入若干"监督码元"后进行传输,这些加入的码元与原来的信息码序列之间存在着某种确定的约束关系。在接收数据时,如果既定的约束关系遭到破坏,则在接收端可以发现传输中的错误,乃至纠正错误。
使用这种方式虽然提高了数据可靠性,但是却增加了信息量的冗余,降低了系统的效率。
根据码组的分类,可以分为检错码和纠错码两类。
检错码是指能自动发现差错的码。
纠错码是指不仅能发现差错而且能自动纠正错误。
这是一种简单的检错码,是在传输数据后附加一位监督位,使该组码连同监督位在内的码组中的"1"的个数为偶数(称为偶校验)或奇数(称为奇校验)。
奇偶校验码的这种监督关系可以用公式表示。设该组码长度为n,表示为(, , , ,),其中前n-1位为信息码元,第n位为监督位。
在偶校验时有:⊕⊕······⊕ = 0
在奇校验时有:⊕⊕······⊕ = 1
海明码(Hamming Code)是一个可以有多个校验位,具有检测并纠正一位错误代码的纠错码,所以它也仅用于信道特性比较好的环境中,如以太局域网中,因为如果信道特性不好的情况下,出现的错误通常不是一位。
一般来说,若信息长为n,信息位数为k,则监督位数r=n-k,如果希望用r个监督位构造除r个监督关系式来指示一位错误码的n中可能位置。则要求:
推导并使用信息长度为k位的码字的海明码,所需步骤如下:
如果发现有一个或多个错误,则错误的位由这些检查的结果来唯一地确定。
从理论上讲,校验位可放在任何位置,但习惯上校验位被安排在1、2、4、8、…的位 置上。当 k=4,r=3 时,信息位和校验位的分布情况如下表所示(其中,、、为校验位,,…,为信息位)。
| 码字位置 | B1 | B2 | B3 | B4 | B5 | B6 | B7 |
|---|---|---|---|---|---|---|---|
| 校验位 | x | x | x | ||||
| 信息位 | x | x | x | x | |||
| 复合码字 | P1 | P2 | D1 | P3 | D2 | D3 | D4 |
r 个校验位是通过对 k+r 位复合码字进行奇偶校验而确定的。校验位置在位置上,例如:1、2、4、8...
第n位校检码校检的起始位置为,并从当前位置开始校验位,每隔位在校检位。
当n=1时,第1位校检码校检的起始位置为1,并从当前位置开始校验1位,每隔1位在校检1位。
当n=2时,第2位校检码校检的起始位置为2,并从当前位置开始校验2位,每隔2位在校检2位。
当n=3时,第3位校检码校检的起始位置为4,并从当前位置开始校验4位,每隔4位在校检4位。
所以有以下结果:
| 复合码字 | P1 | P2 | D1 | P3 | D2 | D3 | D4 |
|---|---|---|---|---|---|---|---|
| 校验的位 | x | x | x | x | |||
| 校验的位 | x | x | x | x | |||
| 校验的位 | x | x | x | x |
上面说第一位校验位校验1、3、5、7位,但是为什么校验这些位却没有说。包括一些教材也都没有说明缘由。
| 码字位置 | B1 | B2 | B3 | B4 | B5 | B6 | B7 |
|---|---|---|---|---|---|---|---|
| 复合码字 | P1 | P2 | D1 | P3 | D2 | D3 | D4 |
| 校验位 | 001(1) | 010(2) | 100(4) |
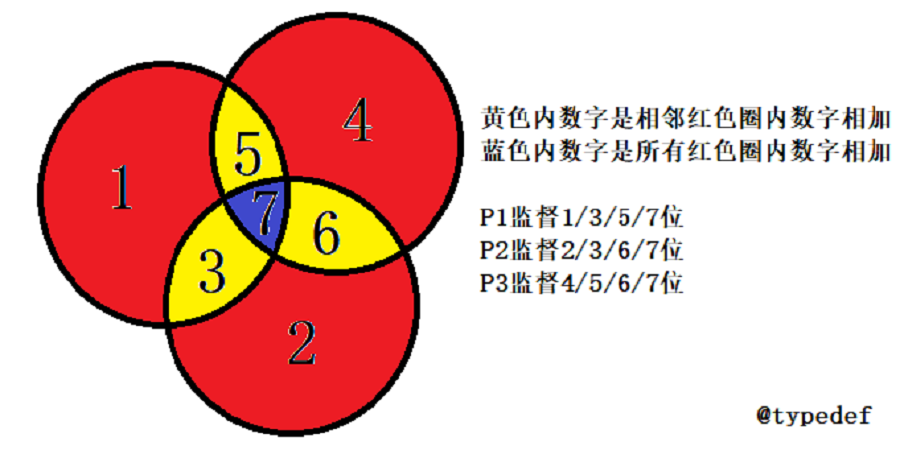
我们来看一张表格,就知道是什么意思了。如下图:
| 码字位置 | B1 | B2 | B4 |
|---|---|---|---|
| 复合码字 | P1 | P2 | P3 |
| 编码的第几位 | 001(1) | 010(2) | 100(4) |
| 满足条件的位 | 001(1) 011(3) 101(5) 111(7) | 010(2) 011(3) 110(6) 111(7) | 100(4) 101(5) 110(6) 111(7) |
这就就是P1监控1、3、5、7位的原因。P2、P3同理。这部分才是精髓,一定要理解。
若有四位信息码:1101,进行偶校验,求编码之后的海明编码。
根据前文提到的校验规则,可以得知,根据校验码的位置:
根据上述的条件得知(,,) = (0,1,0)
| 复合码字 | P1 | P2 | D1 | P3 | D2 | D3 | D4 |
|---|---|---|---|---|---|---|---|
| 信息码 | 1 | 0 | 1 | 1 | |||
| 校验的位 | x | x | x | x | |||
| 校验的位 | x | x | x | x | |||
| 校验的位 | x | x | x | x | |||
| 编码后的海明码 | 0 | 1 | 1 | 0 | 0 | 1 | 1 |
在原有的编码系统中插入若干校验位,能够提高系统的码距,从而能够实现检错和纠错的功能。
码距是编码系统中两个编码之间不同的二进制的位数。
假如四位信息码中,编码范围为0000~1111。例如数据1001和数据0000的码距就是2,因为它们的第1和第4位数据不同,所以码距是2。
但是我们通常关心的是编码系统中的最小码距。即最小的那个值。例如四位编码系统中的数据0000和0001,最小码距为1,没有比这个码距更小的值了。
这里举个极端的例子,假如说我的编码系统中,经过编码之后的数据只会出现数据0000 0000和1111 1111两种可能。即最小码距为8。
但是我在接收方却收到了数据0000 0001,这个编码明显不在我的编码系统中,数据一定是被干扰了。假设发送数据为0000 0000则最低位被干扰了,可能性较大。假设发送是数据为1111 1111则高七位被干扰了,可能性较小。
由于数据0000 0001最接近0000 0000,从而断定发送方数据为0000 0000,继而达到纠错的功能。检错的功能也类似。
首先我们说的海明码通常指的是(n,k)=(7,4),即编码长度为7位、信息位为4、校验位为3位的海明码,所以通常叫74海明码。
关于海明码的码距,在网络上搜了大量的资料,也没见到说的比较明白的,果然还是得靠自己啊。
既然最小码距是编码系统中码距的最小值。那我们直接把4位信息码经过海明码编码后的所有可能穷举出来,找到最小值即可,请看下面这张表格。
| 原始信息码 | 海明码编码 |
|---|---|
| 0001 | 000 0111 |
| 0010 | 001 1001 |
| 0011 | 001 1110 |
| 0100 | 010 1010 |
| 0101 | 010 1101 |
| 0110 | 011 0011 |
| 0111 | 011 0100 |
| 1000 | 100 1011 |
| 1001 | 100 1100 |
| 1010 | 101 0010 |
| 1011 | 101 0101 |
| 1100 | 110 0001 |
| 1101 | 110 0110 |
| 1110 | 111 1000 |
| 1111 | 111 1111 |
通过观察上面这个表可以得知,经过插入三个校验位,任意两个编码之间不同的二进制位最小值为3,所以74海明码的最小码距为3。
码距和纠错的能力有如下关系:
D >= e + 1D >= 2*t+1D >= e + t + 1(e>t)根据上述公式和海明码的最小码距为3可以得知,海明码能够检测两位错误或者纠正一个错误。
在接收方,也可根据这3个校验方程对接收到的信息进行,同样的奇偶测试:
假如只有一位数据出错,错误位置就可简单地用二进制数CBA指出。如果CBA=000,则说明没有错。若CBA不等于0,说明有错。假如B5位出错。根据上述校验可得CBA=101,刚好是十进制5。也代表是第五位出现错误。
但是当有两位错误的时候,例如B3和B6同时出错,CBA仍然是等于101。
可以观看下面的图,比较直观。
看了这么多,做两题练练手吧,请问下面两句话表述是否正确。
https://www.cnblogs.com/godoforange/p/12003676.htmlhttps://www.electrically4u.com/hamming-code-with-a-solved-problem/END
点赞、转发加关注,一键三连,好运年年
关注公众号后台回复数字688可获取嵌入式相关资料
往期推荐
为什么C语言执行效率高,运行快?

二维数组与二级指针是好兄弟吗?

工作这么久,才明白的SOLID设计原则
C语言中的不完整类型

