欢迎关注创芯大讲堂查看最新芯片课程
来源:technews(台) 作者:痴汉水球
本篇文章将带你了解 :
英特尔不断腰斩服务器GPU 的黑历史
当
竞争激烈的科技业,若不考虑迟迟清不光的库存,所有置身其中的参赛者,无不竭尽全力、尽其所能尽快推出新产品,落后竞争对手一年半载更是罪大恶极,但各位能够想像,服务器专用绘图处理器(Server GPU)市场,即将上演「三年空窗期」的世界奇观吗?

美国时间3 月3 日星期五下午,英特尔「加速计算系统和绘图事业群」(Accelerated Computing Systems and Graphics,AXG)临时总经理Jeff McVeigh 公开一封信,简单介绍英特尔服务器GPU 的产品时程表。无独有偶,3 月22 日CEO Pat Gelsinger 宣布首席架构师Raja Koduri(2017年11 月离开AMD,闪电加入英特尔)3 月底离开英特尔,加入生成式AI 新创公司,刚刚好紧跟着2022 年底AXG 事业群重组。
 ▲ 一图胜千言,回顾去年的英特尔计划,现在状况就是这么简单:啊,看到天空了。
▲ 一图胜千言,回顾去年的英特尔计划,现在状况就是这么简单:啊,看到天空了。
简而言之,英特尔已取消一年半内发布多款服务器GPU 产品,包括人工智能与高效能计算(Data Center GPU Max)的「Rialto Bridge」和云端游戏与媒体编码(Data Center GPU Flex)「Lancaster Sound」规划,代表英特尔今年到2025 年不会有新服务器GPU 推出。虽然据英特尔长期计划,仍追求在利润丰厚的服务器GPU 市场,设法从Nvidia 的蛋糕夺取相当占比,但眼前发展,却是英特尔放弃两三年内市场。
至于寄予厚望的「XPU」首发「Falcon Shores」,与Lancaster Sound 后继者「Melville Sound」更延期至2025 年。换言之,英特尔等于变相宣布服务器GPU 领域落后AMD 和 Nvidia整整三年。更让人惊讶的是,这颗重磅炸弹一丢下去,连XPU 也不XPU了,从「2024 年XPU」变成「2025 年GPU」。
这情境讲含蓄点,大概有点像「不必打开窗户,抬头就是天空」之感。晴空万里时非常浪漫,但倾盆大雨就让人笑不出来。
英特尔不断腰斩服务器GPU 的黑历史
但回顾英特尔这家公司的服务器GPU发展史──或严格说「通用运算GPU」一直不缺不断取消产品的黑历史,像15 年前「x86 指令集显示卡」」Larrabee」、2010 年命运多舛最终又始乱终弃的Xeon Phi 产品线、和第一个被封存(名义上是当作Aurora 超级电脑和oneAPI 的开发平台,而不会商品化)的Xe 绘图架构「Xe-HP」,都是血迹斑斑的前车之鉴。
 ▲ 对于英特尔,Larrabee实在是黑到不能再黑的黑历史。
▲ 对于英特尔,Larrabee实在是黑到不能再黑的黑历史。
因「x86 义和团之乱」横空出世的Larrabee 和后代Xeon Phi,透过硬塞巨量小型x86 CPU 核心,硬凑出看起来很漂亮的理论浮点运算效能,就傻傻无视许多先天限制,幻想可经纯软件化手段,有效率做到各种功能,失败一点都不让人感到一丝一毫意外(至于歌功颂德英特尔的「伟大创意」,倒是不少科技媒体努力躬逢其盛),也使英特尔个砍掉重练,打造横跨几乎所有应用领域的Xe 绘图架构体系。
但英特尔2020年一直努力展示FP32 输出量高达42TFlops 的Xe-HP,却在2021 年整个风云变色,Xe-HP 取消,将原本偏游戏应用的Xe-HPG(Alchemist,后来的Arc 系列)推向服务器市场,处理人工智能推论与云端游戏绘图等更具可扩展性的任务,高效能运算与人工智能训练则仰赖Xe-HPC(Ponte Vecchio),整个产品策略变得「有点像又不太像」名为 Nvidia 的最强对手。
但除非英特尔也让Xe-HPG支援模组化多芯片块(Tile)结构,否则无法提供Xe-HP 预定的性能,事后证明这件事也从未发生,真是可喜可贺。

▲ Xe-HP 最重要特色莫过于「积木叠叠乐」,对应不同性能需求,但换成Xe-HPG 就力有未逮了。
英特尔会这样决定的理由,最直觉猜测就是「Xe-HP 夹在Xe-HPC 和Xe-HPG中间,不上不下,地位尴尬」,但当各位想起Xe-HP 是英特尔计划自行生产的唯一高性能Xe 绘图架构芯片(10nm Enhanced Super-Fin,现在Intel 7 制程),但其他两款却都是台积电6 纳米(N6),也许大家心里就会推论出自己的答案了,一切尽在不言中。
 ▲ 看到Xe-HP是「纯英特尔制造」,再回想英特尔当时景况,很多人心里大概就有底了。
▲ 看到Xe-HP是「纯英特尔制造」,再回想英特尔当时景况,很多人心里大概就有底了。
当XPU 不再XPU:减少存储器搬移对改善能耗比很重要
将往事抛诸脑后,聚焦2025 年的「救世主」、下一个Max 系列:「Falcon Shores」吧,会赫然发现:这不再是英特尔2022 年概述的「具备同时封装CPU 和GPU 弹性」的XPU,而更像「传统」GPU。Falcon Shores 将提供不同IP 区块选项,为XPU 的一部分,但也不是2025 年登场的这代。

▲ 英特尔XPU,看来还要等很久,如果没出意外。
为何让CPU 和GPU 共享存储器,现在会变得那么重要,原因不外乎减少两者间移动和复制数据浪费的功耗,让CPU和GPU 更快速容易传递数据。大型高效能运算系统,光运算节点内部和外部移动数据,就会消耗大量电力。因此采用更先进技术,共同封装CPU、GPU、加速器和存储器,视为「不同于传统独立组件的功率曲线」提高互连速度的方法,并允许更多功耗预算去计算,而不是搬移数据。
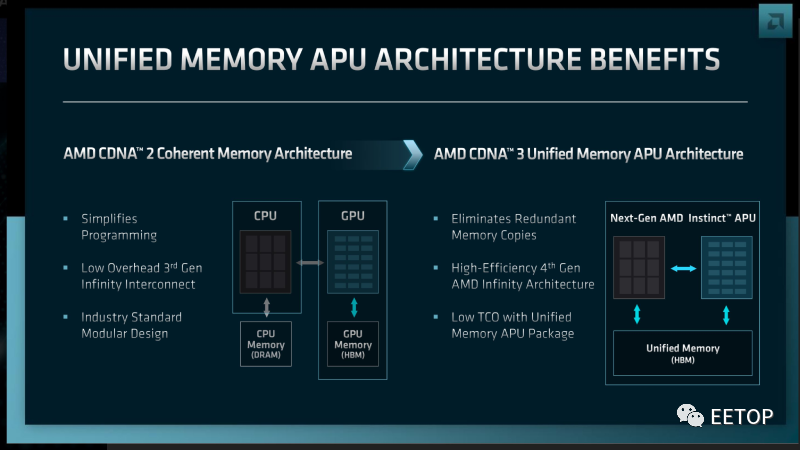
▲ 这看似简单的道理,AMD 却布局超过十年。
如果脑袋还是转不过来,就想想苹果M1 / M2 可怕的能耗比就知道了,充分对世人展示了整合的威力。

▲ 靠越近走越快,且还更省电,苹果M1 / M2 就是最好示范。
反观2023 年,AMD Instinct MI300 与 Nvidia Grace Hopper,却都是CPU、GPU 和存储器高度封装在一起的产物。即使Nvidia Grace Hopper,本质上是在主机板上摆两个紧密耦合的芯片,而不像AMD默默努力多年的EHP(Exascale Heterogenous Processor)大玩3D 堆叠,但依然领先英特尔时下水准。
更何况2025 年前,无论AMD 还是Nvidia,MI300 和Grace Hopper 的继承者,几乎肯定会在Falcon Shores 上市前浮上水面,英特尔依旧会承担「产品还没上阵就变落伍」的潜在风险──意味2026 年前,AMD 和 Nvidia下一代架构仍处于领先地位。
也许oneAPI 和个人电脑市场才是英特尔的救赎
到头来视为「英特尔的XPU 野心扩张计划」的oneAPI,企图让开发者通吃CPU、GPU、FPGA 甚至ASIC,打造最符合应用程式需求的任何运算架构,最终成功才是属于英特尔的救赎,尤其当英特尔极可能需要三年内,完全仰赖仍处于市占率优势的CPU 和必须「苦撑三年」的现有GPU 产品线,来守住服务器市场阵地。

▲「突破Nvidia CUDA 封锁网」不是简单的事。
此外,即便从AMD挖角一堆人,总算勉强弄起来的Xe 绘图架构体系,从游戏到数据中心,一路跌跌撞撞,最起码证实足堪大任,但英特尔能否建立起稳固的GPU 基本盘,最终还是得仰仗消费市场把「量」做起来,特别是高阶显卡。
Nvidia 和AMD 已耗费近17年时间,证明这条硬道理(x86 CPU 的服务器霸权之路也是奠基于巨大的个人电脑市场之上)。或许关心英特尔服务器战线,并早就习惯其靠CPU 内显躺着吃掉大半市占率之余,也值得多多观察身边是否出现越来越多「Intel Inside」独显,搞不好数量已多到超出各位预期。
附:EETOP创芯英才网高薪职位
扫描二维码申请职位

扫描二维码申请职位

