RTX 40系列发布之后,黄仁勋曾经亲口确认,SLI技术已经被彻底放弃。
不过现在,NVIDIA又以另一种方式复活了它,这就是最新发布的数据中心加速计算卡H100 NVL。
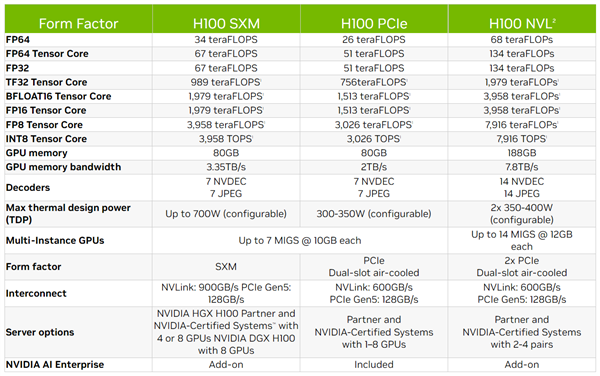
NVIDIA一年前就发布了Hopper架构的新一代计算卡H100,具备三个NVLink总线,可以组建多卡互连。
H100 NVL则不太一样,单卡集成两颗H100 GPU,彼此通过NVLink互连,一致对外。
这显然是给那些不支持SXM的服务器准备的,适合大规模AI推理训练。
它的规格基本就是H100 SXM版本翻一番甚至还多:33792个CUDA核心、1056个Tensor核心、188GB HBM3高带宽内存、7.8TB/s带宽、700-800W功耗。
性能也是直接翻倍,Tensor加持之下FP64 134万亿次、TF32 1979万亿次、BF16/FP16 3958万亿次、FP8/INT8 7916万亿次。
H100 NVL一块卡需要占用两个插槽,每个服务器节点可以配备2块或者4块,也就是最多八颗GPU。
那规格,那性能,还有那价格,多美丽。

单系统四卡八GPU
H100 NVL是已有H100系列的特殊加强版,专为大型语言模型(LLM)进行优化,是部署ChatGPT等应用的理想平台。
H100 NVL单卡具备多达94GB HBM3高带宽显存(内存),照此容量看显然是开启了完整的6144-bit位宽,并启用了全部六颗,等效频率按照5.1GHz计算的话,带宽就是恐怖的3.9TB/s。
但也有个问题,六颗HBM3显存总容量应该是96GB,但是这里少了2GB,官方没有解释,猜测还是出于良品率考虑,屏蔽了少数存储单元。
相比之下,H100 PCIe/SXM版本都只开启了5120-bit位宽,六个显存位只使用五个,容量均为80GB,区别在于一个是HBM2e 2TB/s带宽,一个是HBM3 3.35TB/s带宽。

H100 NVL还可以双卡组成一个计算节点,彼此通过PCIe 5.0总线互连,总显存容量就是188GB,总显存带宽7.8TB/s,NVLink带宽600GB/s,总功耗可达700-800W。
计算性能相当于H100 SXM的整整两倍,意味着也开启了全部16896个CUDA核心、528个Tensor核心,其中FP64双精度浮点性能64TFlops,FP32单精度浮点性能134TFlops。
再加上Transformer引擎加速的辅佐,在数据中心规模,H100 NVL与上一代A100相比,GPT-3上的推理性能提高了多达12倍。
H100 NVL将在今年下半年开始出货,价格……尽情想象去吧。

值得一提的是,NVIDIA还同时推出了其他两套推理平台:
NVIDIA L4:
适用于AI视频,性能比CPU高出120倍,能效提高99,提供强大的的视频解码和转码能力、视频流式传输、增强现实、生成式AI视频等。
NVIDIA L40:
适用于图像生成,针对图形以及AI支持的2D、视频和3D图像生成进行了优化,与上一代产品相比,Stable Diffusion推理性能提高7倍,Omniverse性能提高12倍。
顺带一提,CPU、GPU二合一的NVIDIA Grace Hopper适用于图形推荐模型、矢量数据库、图神经网络,通过NVLink-C2C 900GB/s带宽连接CPU和GPU,数据传输和查询速度比PCIe 5.0快了7倍。

