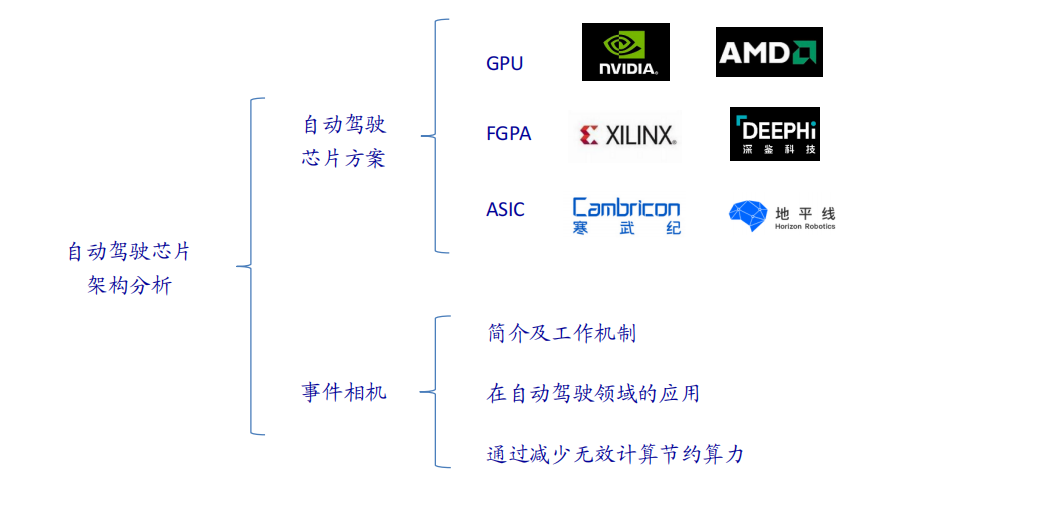
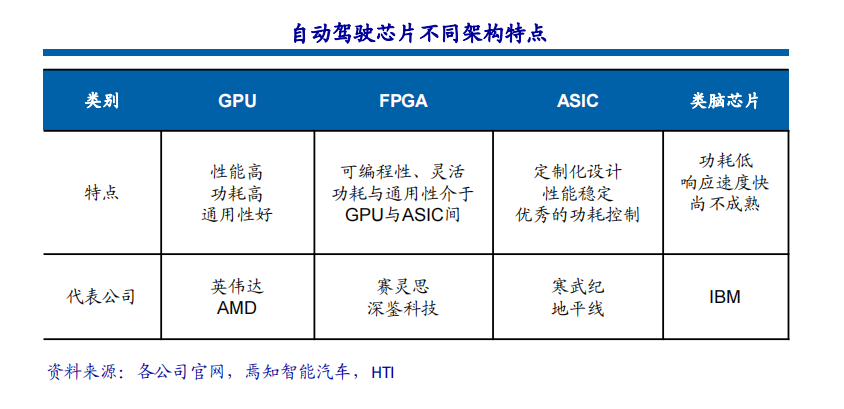
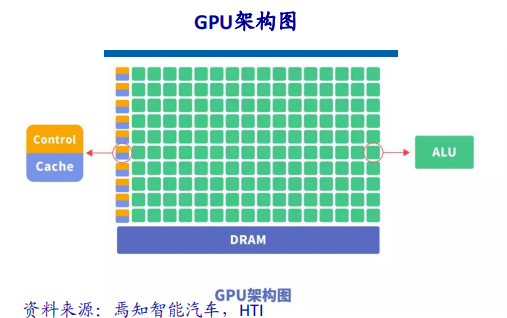
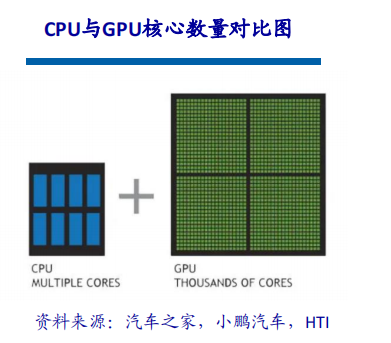
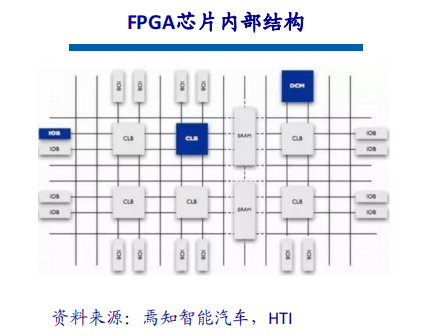
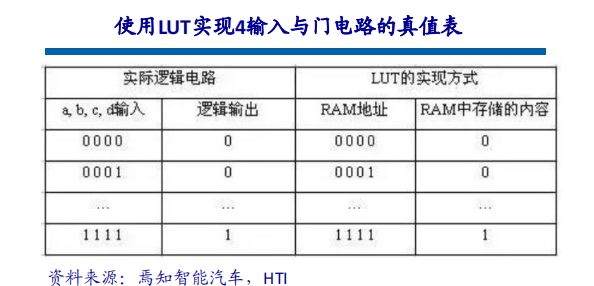
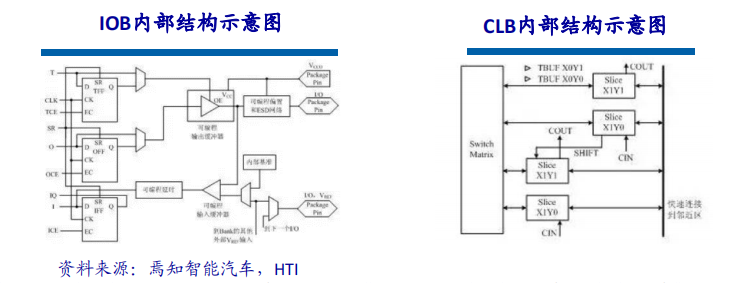
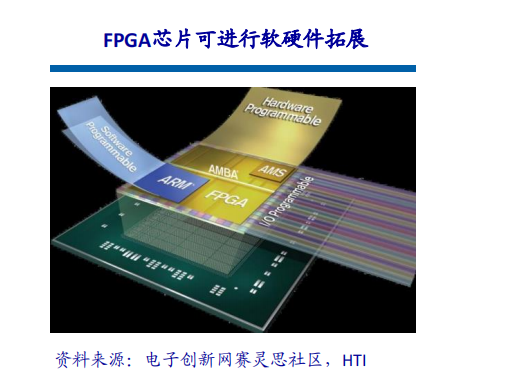
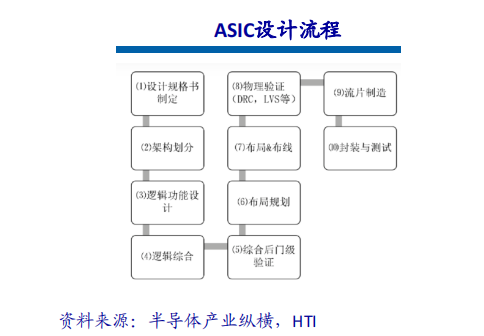
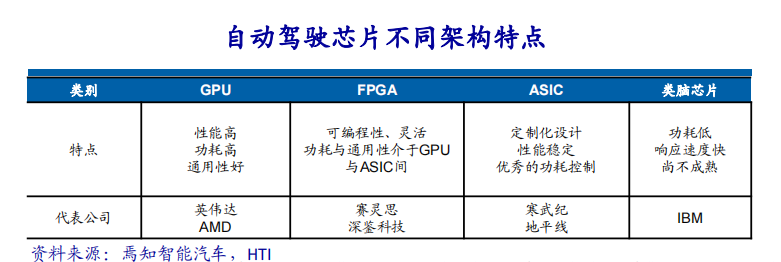
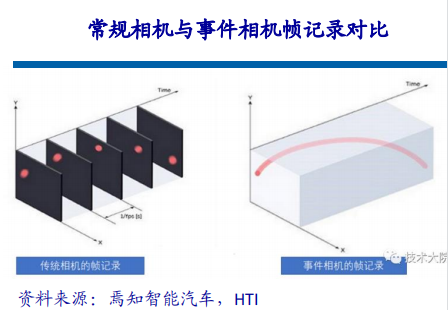
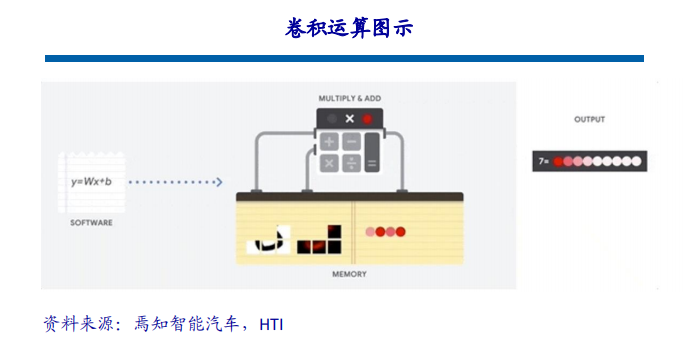
一、行业背景与市场需求高血压作为全球发病率最高的慢性病之一,其早期监测与管理已成为公共卫生领域的重要课题。世界卫生组织数据显示,全球超13亿人受高血压困扰,且患者群体呈现年轻化趋势。传统血压计因功能单一、数据孤立等缺陷,难以满足现代健康管理的需求。在此背景下,集语音播报、蓝牙传输、电量检测于一体的智能血压计应运而生,通过技术创新实现“测量-分析-管理”全流程智能化,成为慢性病管理的核心终端设备。二、技术架构与核心功能智能血压计以电子血压测量技术为基础,融合物联网、AI算法及语音交互技术,构建起多