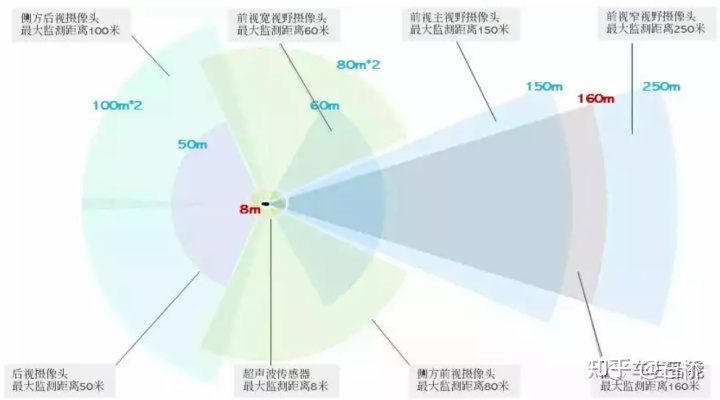
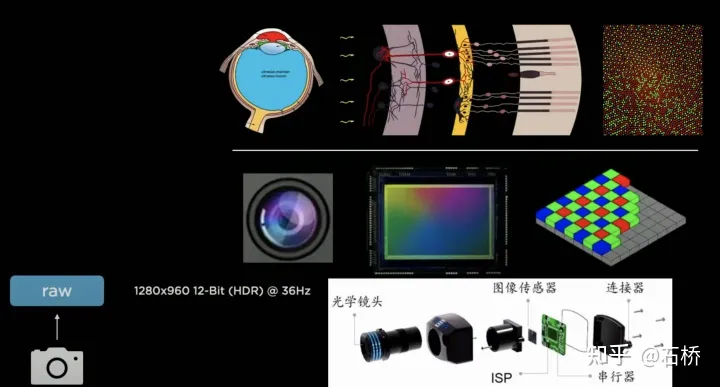
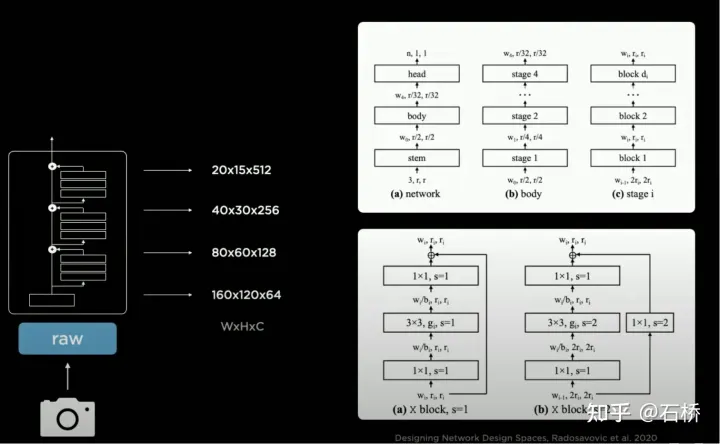
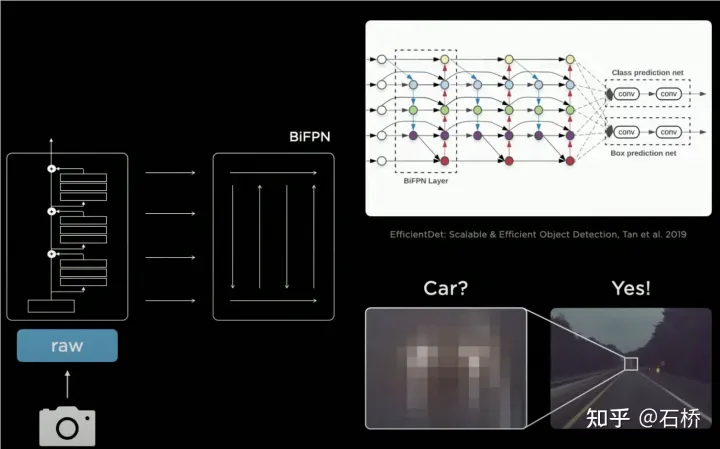
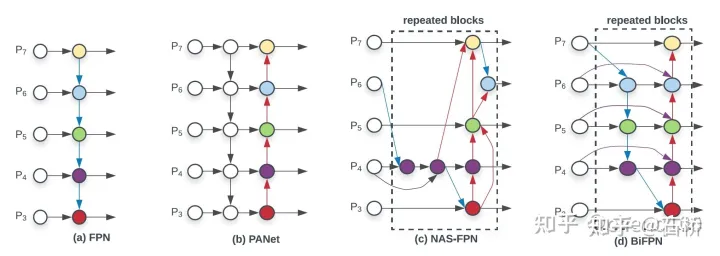
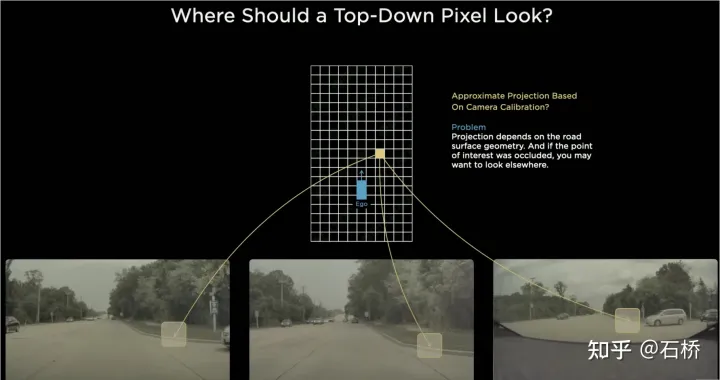
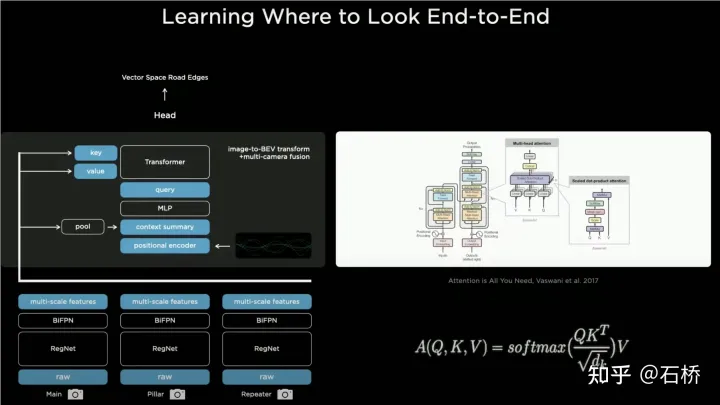
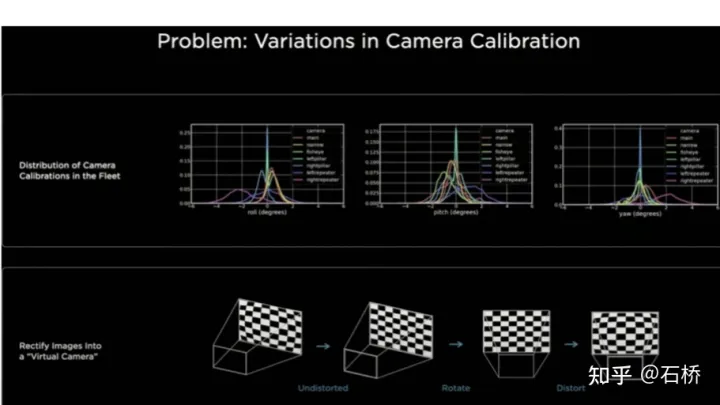
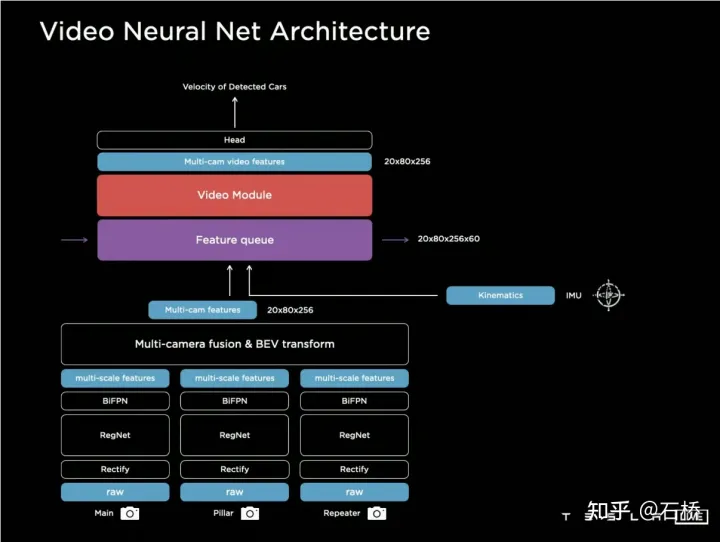
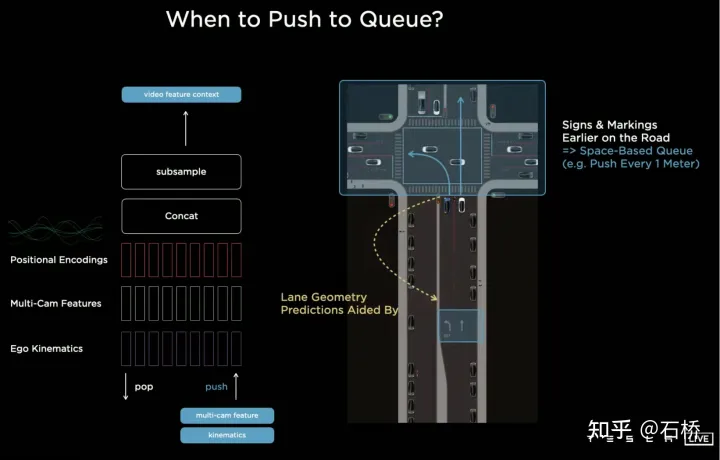
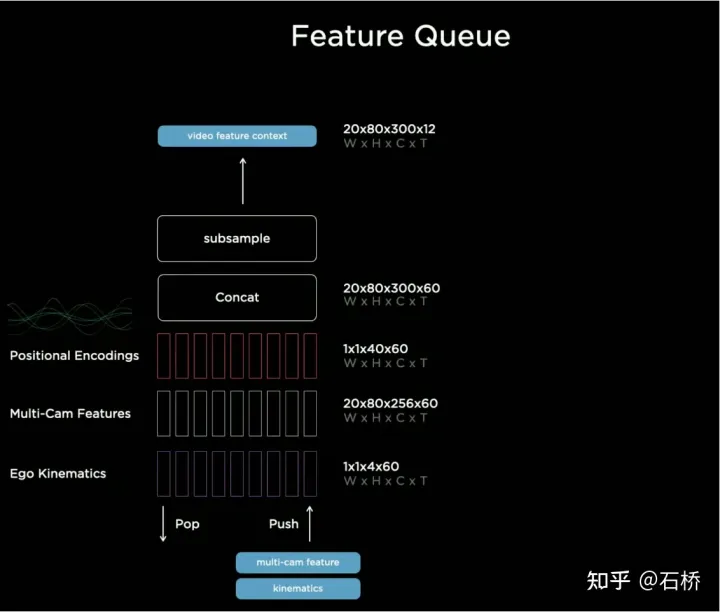
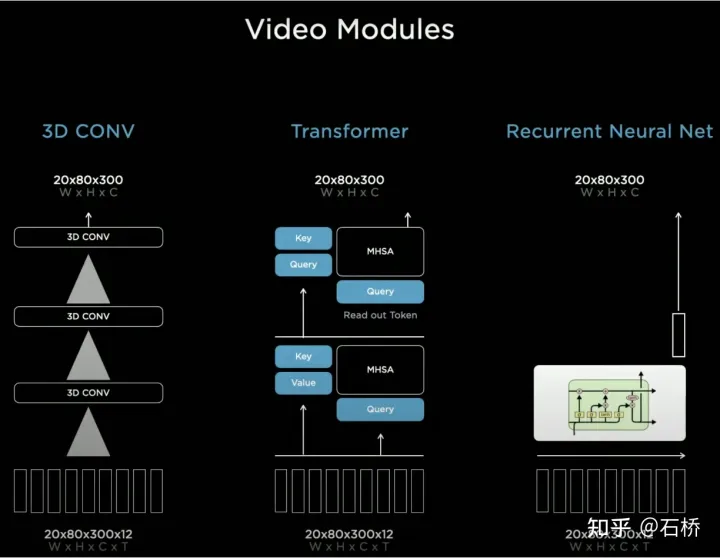
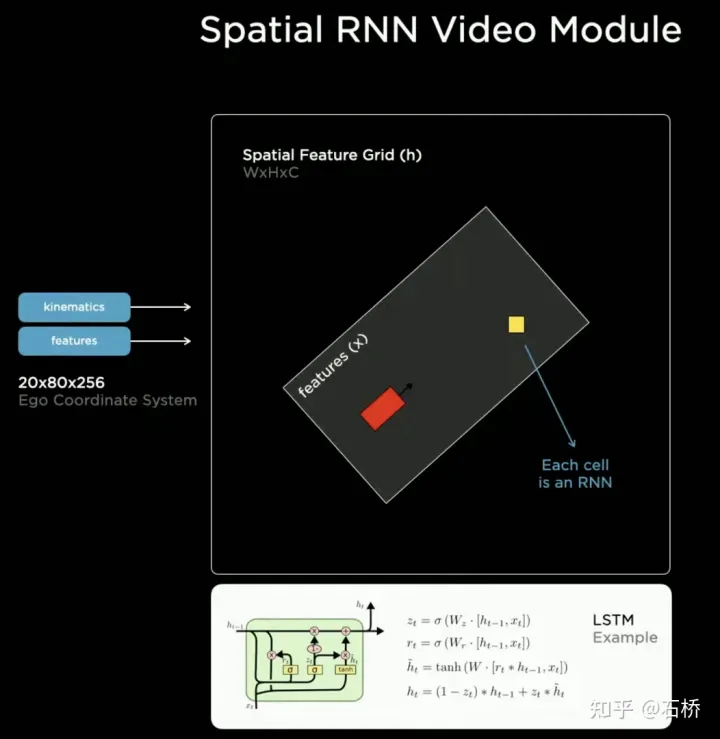
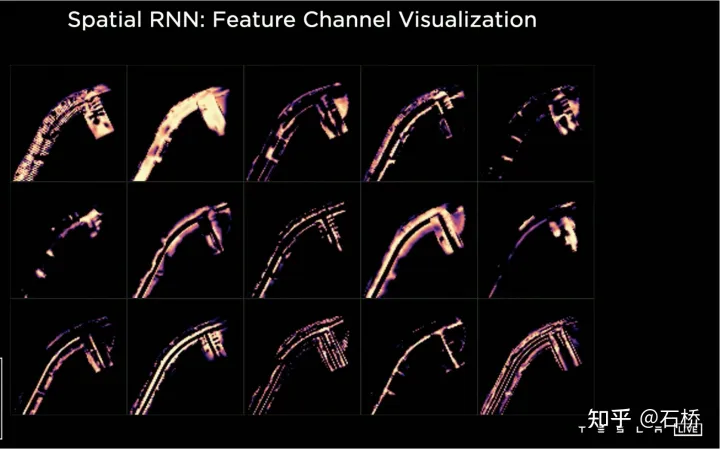
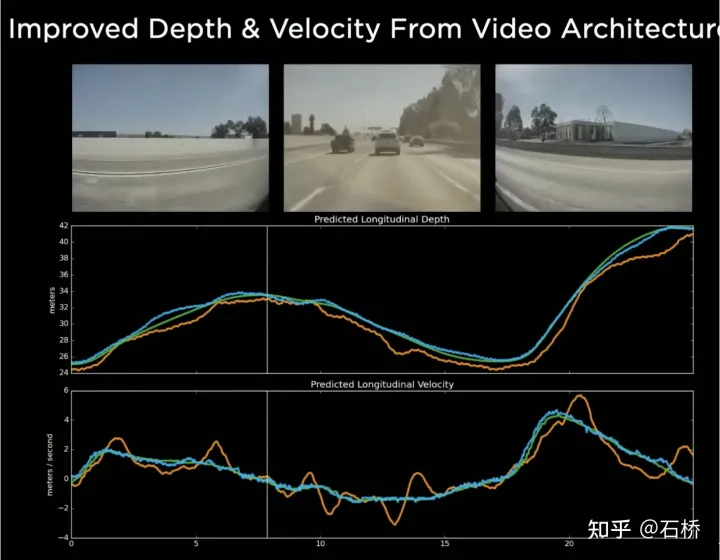
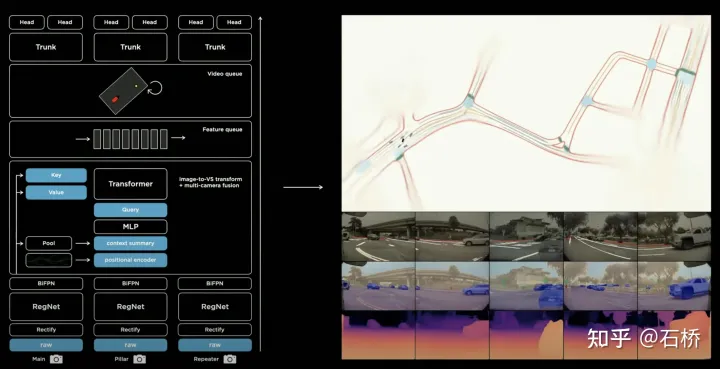
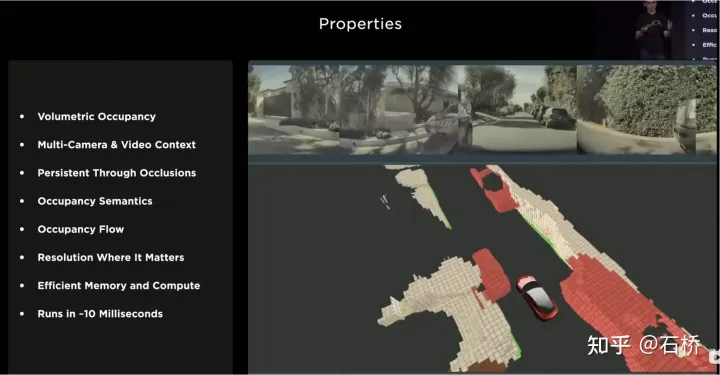
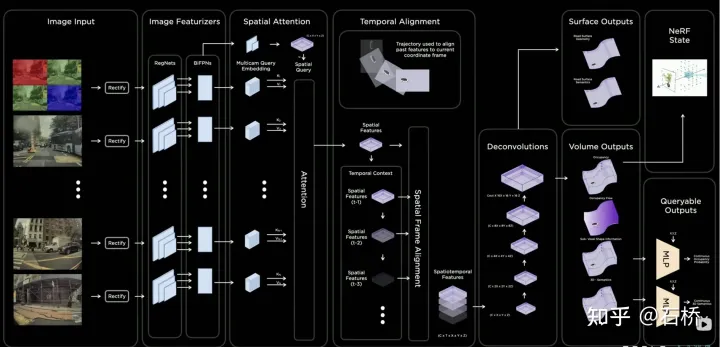
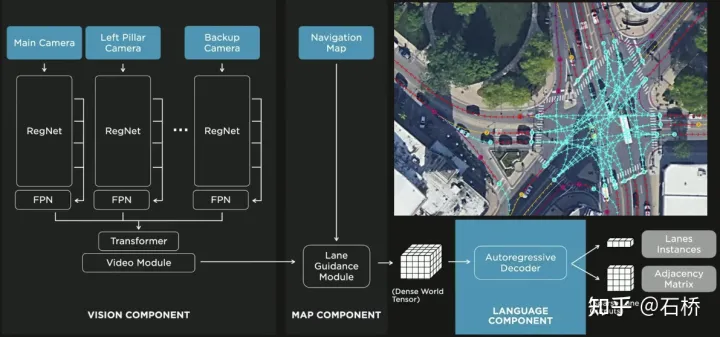
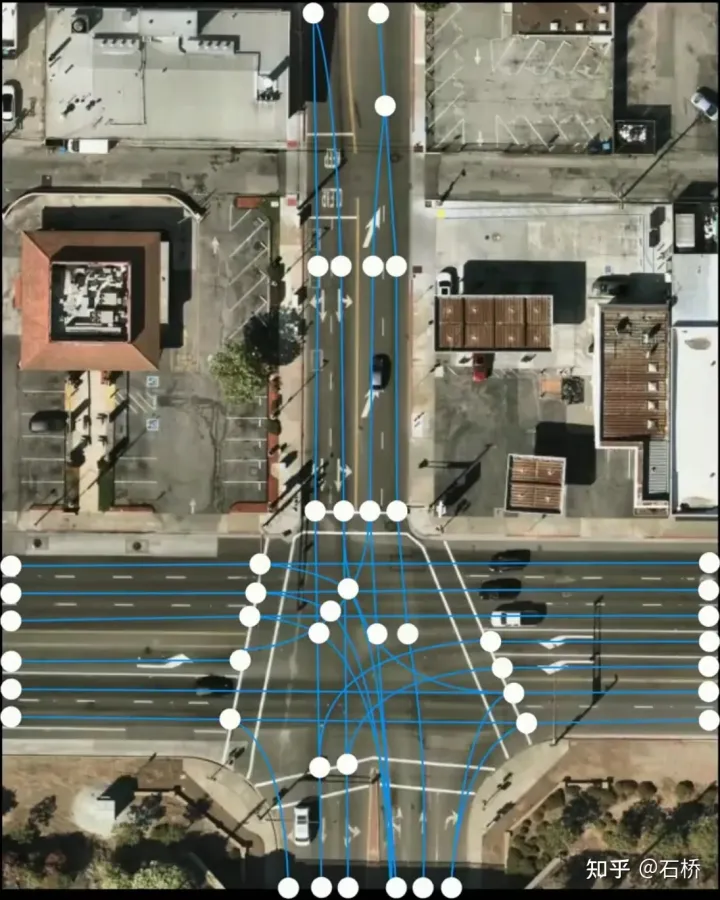
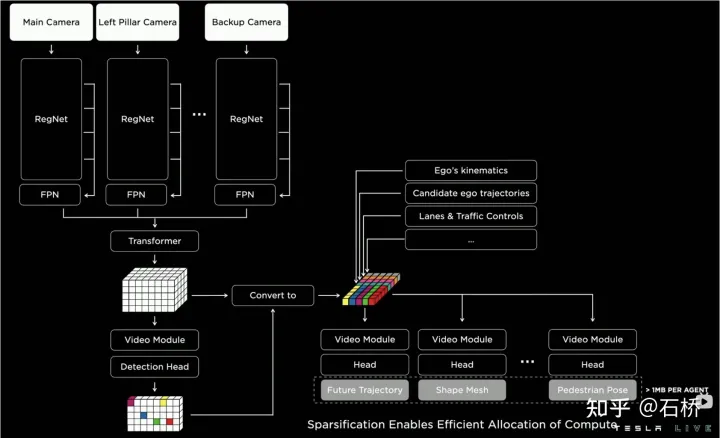
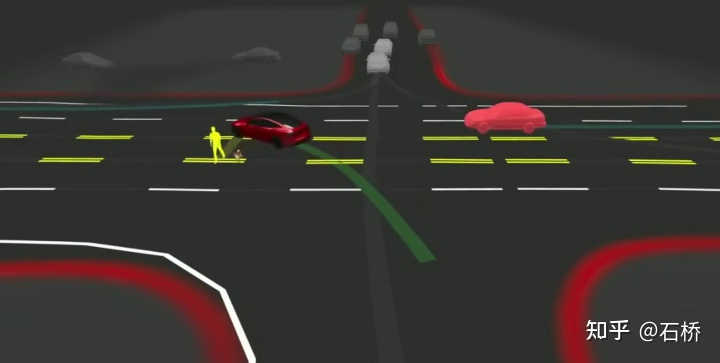
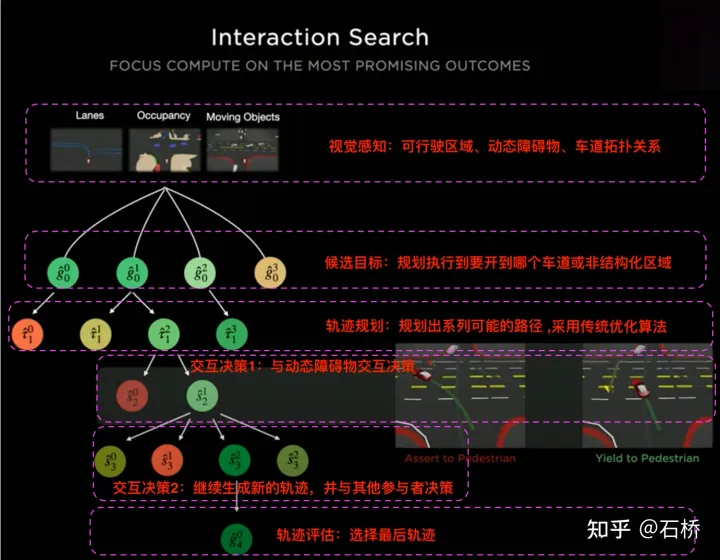
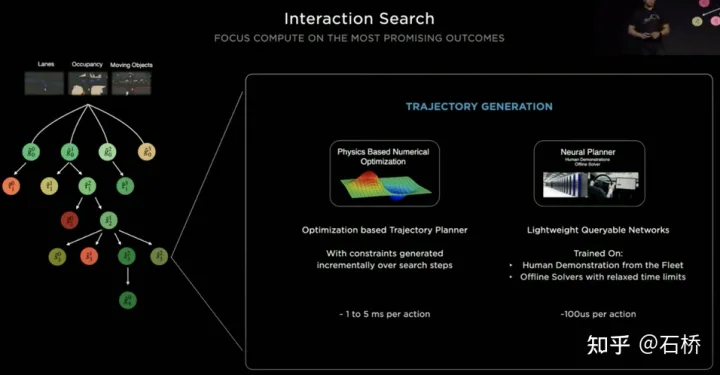
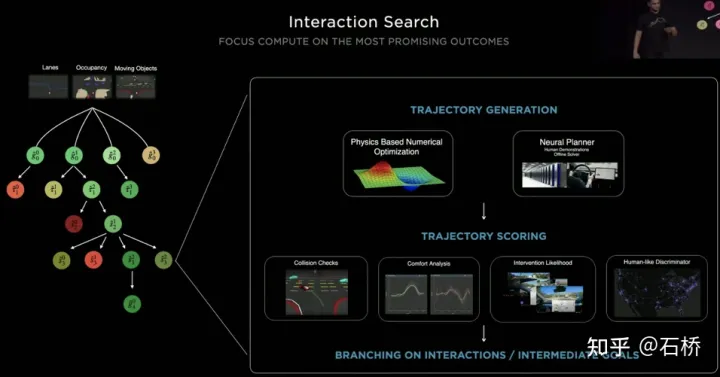
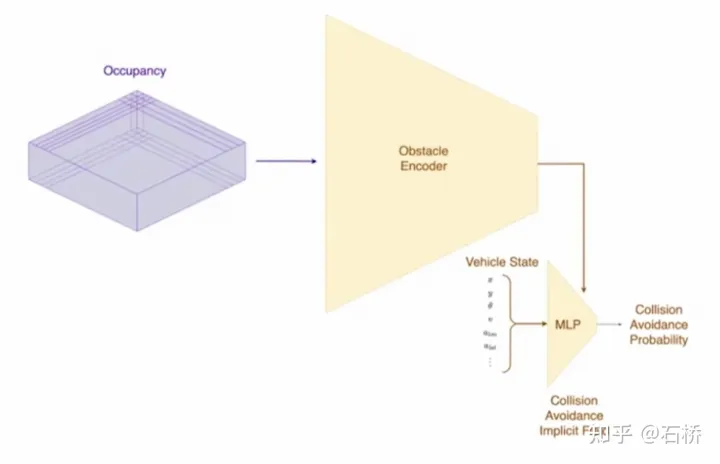
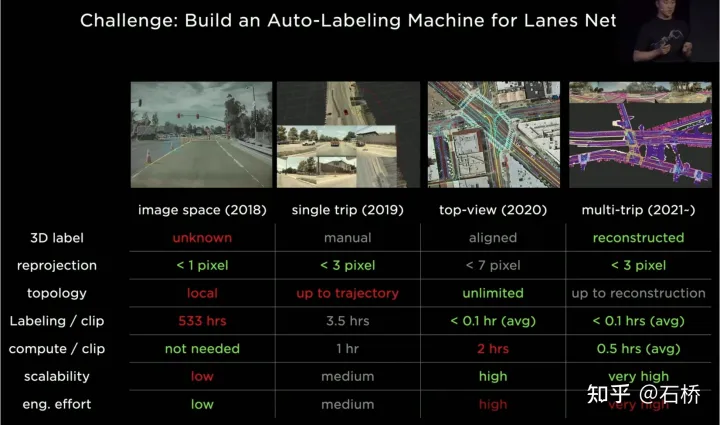
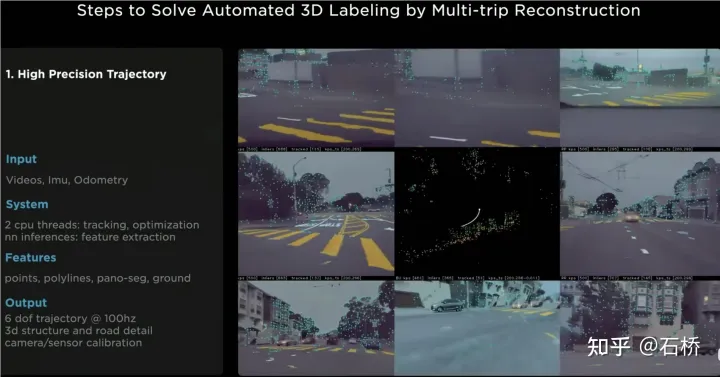
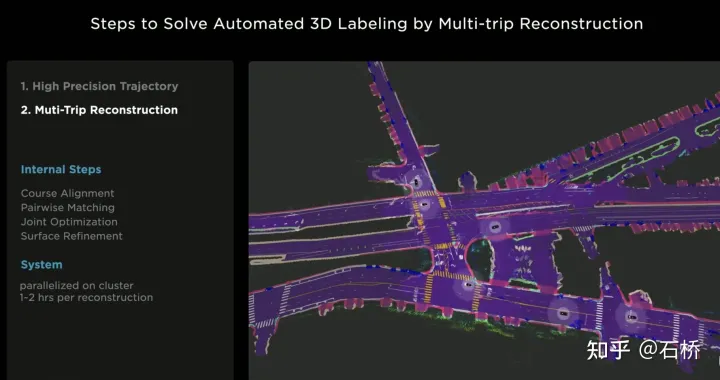
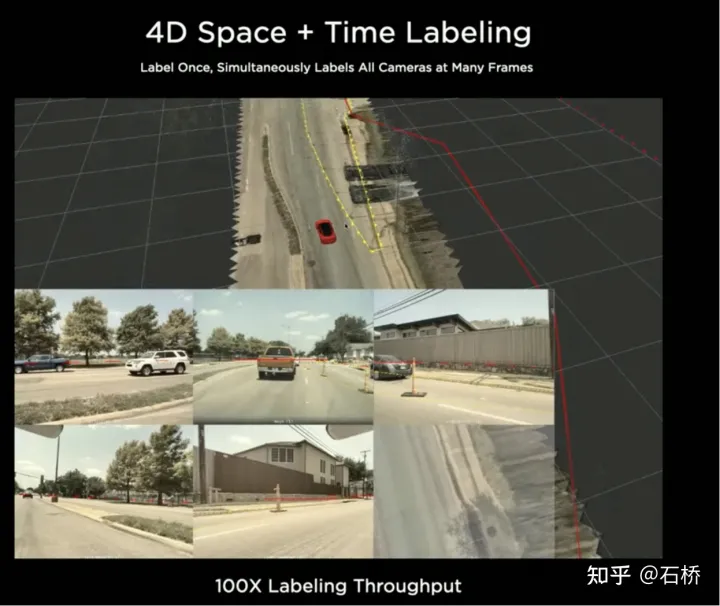
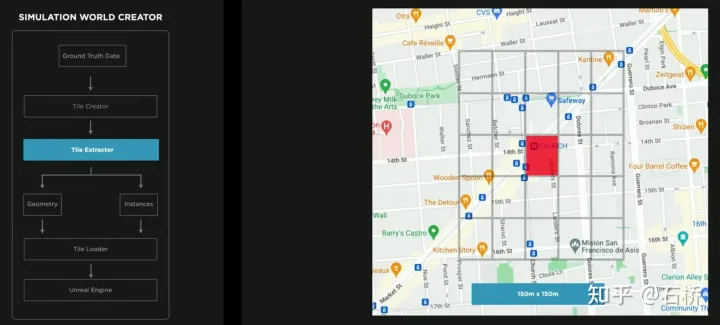
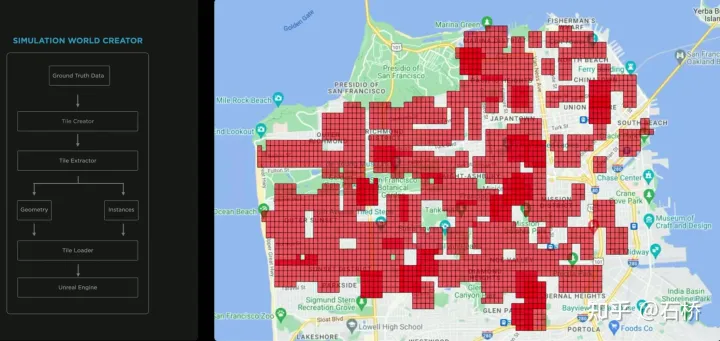
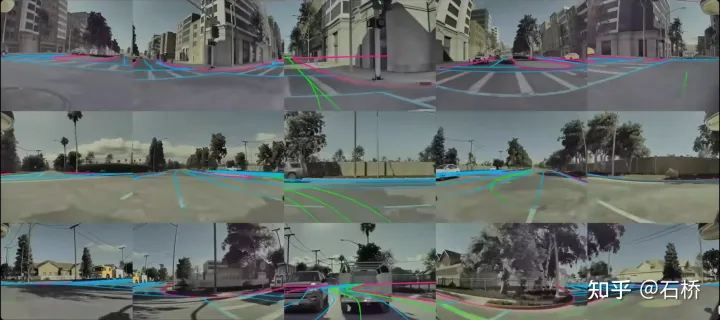
只分割、识别出车道线是不够的,还需要推理获取车道之间的拓扑连接关系,这样才能用于轨迹规划。 FSD车道线拓扑关系感知 1)Lane Guidance Module:使用了导航图中的道路的几何&拓扑关系,车道等级、数量、宽度、属性信息,将这些信息与Occupancy特征整合起来进行编码生成Dense World Tensor给到拓扑关系建立的模块,将视频流稠密的特征通序列生成范式解析出 稀疏的道路拓扑信息(车道节点lane segment和连接关系adjacent)。 2)Language Component:把车道相关信息包括车道节点位置、属性(起点,中间点,终点等)、分叉点、汇合点,以及车道样条曲线几何参数进行编码,做成类似语言模型中单词token的编码,然后利用时序处理办法进行处理。具体流程如下: language of lanes 流程 language of lanes 最终language of lanes表征的就是图中的拓扑连接关系。
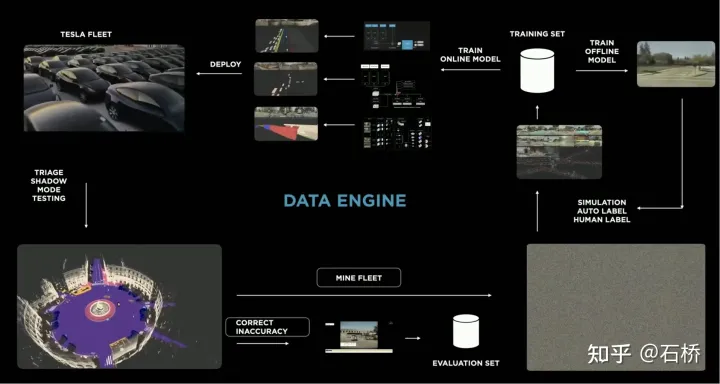
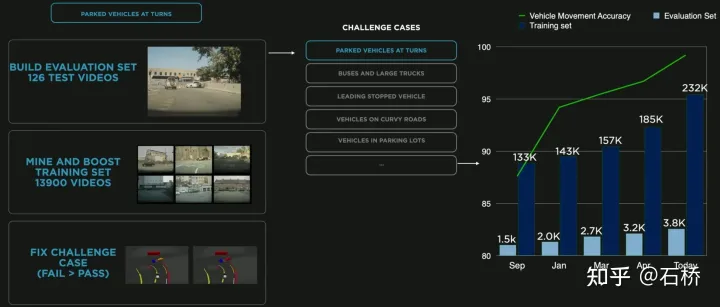
构建巨量的驾驶场景时,测试ADAS和AD系统面临着巨大挑战,如传统的实验设计(Design of Experiments, DoE)方法难以有效覆盖识别驾驶边缘场景案例,但这些边缘案例恰恰是进一步提升自动驾驶系统性能的关键。一、传统解决方案:静态DoE标准的DoE方案旨在系统性地探索场景的参数空间,从而确保能够实现完全的测试覆盖范围。但在边缘案例,比如暴露在潜在安全风险的场景或是ADAS系统性能极限场景时,DoE方案通常会失效,让我们看一些常见的DoE方案:1、网格搜索法(Grid)实现原理:将
1,微软下载免费Visual Studio Code2,安装C/C++插件,如果无法直接点击下载, 可以选择手动install from VSIX:ms-vscode.cpptools-1.23.6@win32-x64.vsix3,安装C/C++编译器MniGW (MinGW在 Windows 环境下提供类似于 Unix/Linux 环境下的开发工具,使开发者能够轻松地在 Windows 上编写和编译 C、C++ 等程序.)4,C/C++插件扩展设置中添加Include Path 5,
Matter 协议,原名 CHIP(Connected Home over IP),是由苹果、谷歌、亚马逊和三星等科技巨头联合ZigBee联盟(现连接标准联盟CSA)共同推出的一套基于IP协议的智能家居连接标准,旨在打破智能家居设备之间的 “语言障碍”,实现真正的互联互通。然而,目标与现实之间总有落差,前期阶段的Matter 协议由于设备支持类型有限、设备生态协同滞后以及设备通信协议割裂等原因,并未能彻底消除智能家居中的“设备孤岛”现象,但随着2025年的到来,这些现象都将得到完美的解决。近期,