

最近,海外知名半导体报道者采访了美国初创企业Tenstorrent的CEO Jim Keller。
Jim Keller因为其过往的经历被大家熟知。详细履历可以查看之前的报道《Jim Keller的芯片研发封神之路》。最近几年,他先是成为了AI初创公司Tenstorrent的CTO,并在最近成为了CEO。Tenstorrent是希望在机器学习硬件领域成名的公司之一。Tenstorrent 将自己视为一家设计公司,而不仅仅是一家 AI 硬件公司。Tenstorrent 已经流片了两种芯片设计,Greyskull 和 Wormhole,并且有一个很好的路线图,使用当前领先的工艺节点和未来的工艺节点,使用小芯片和die to die的低功耗接口。Jim Keller 是该公司天使投资人。
在Ian Cutres的本次采访中,他分享了他对AI,Chiplet、RISC-V等技术的看法。现在摘译如下:
Ian Cutress(IC):从 CTO 到 CEO 的转变——我们能简单谈谈你的感受吗?
Jim Keller:我来到 Tenstorrent 尽我所能支持 Ljubisa(公司联合创始人 Ljubisa Bajic,最近转任CTO)。我们开始扩大我们的业务,我们正在与更多的客户交谈,我们还在筹集一些资金。我们正在与投资者交谈。明年会有很多事情让我分心,所以我雇了一些额外的员工 . 我们正在邀请其他一些人加入,以扩展我们做事的能力。Ljubisa 基本上一直在从事软件方面的工作。我认为这对我们双方都很好——我们需要去赚钱,我们需要执行很多事情,但公司的根本挑战是技术开发。
众所周知,软件问题非常困难。我们认为我们正在取得真正的进展,所以是的,总的来说我会说这非常好。
IC:我和很多机器学习公司谈过,很明显他们有硬件策略,无论是并行的 SIMD 引擎还是更深奥的东西,他们都说软件问题很难。那么你们有什么不同的做法吗?
Jim Keller:所以我正在向某人解释这个——就像这个软件几乎太简单了,但它能把你困在里面。
因此,如果您只看一下整个行业:现代 CPU 真的很难,它们是乱序执行的,需要非常有经验的人。但是无论你做什么,我们基本上都在底层运行 C 程序,硬件/软件的工作非常明确,非常大胆,这个定义非常好。
然后是GPU,那里的线程引擎非常简单,但你有上千个——CUDA 的天才之处在于你为每个线程编写了一个看起来像单线程的程序,然后有一个协调层来做到这一点(有时它效果很好,有时效果不是很好),所以硬件在某种程度上比 CPU 简单得多,但软件更难。
然后到了 AI ,你说“哦,它会运行大矩阵乘法张量、变换、卷积,你知道硬件在某种程度上是相似的,但它就像反比例——在 CPU 上,软件很简单,而且硬件很难,在 AI 中,硬件足够简单,软件很难。由于运营者的数量,这比任何都难。
我已经就此发表过演讲——在 AI 中只有五种运算符:矩阵乘法、卷积、张量变换、T-Low、SoftMax。您可以争论其他一些细节。
但你也许会说这有多难呢?好吧,它在数千个处理器上运行,它有本地内存,全局内存,它有通信,它有你的名字,它有书中的所有问题,所有的这些事情都非常难以协调。
那么我们有什么不同呢?好吧,我们从来没有让数百人手工编写一些benchmark,这是一个错误的做法。有这么多支点的部分原因是因为在AI中有推理和训练,有语言和视觉模型,以及大/小模型,然后是生成模型,然后是稳定的扩散模型。它们都同时具有多种功能。他们有图像、语言和回传(backpass)。你知道,如果你开始追逐其中一个,那将是相当复杂的,早在您完成该模型之前,新事物就会出现并且手动调整(hand-tuning )的东西不起作用。
所以我们的使命是让你编写 AI 程序并进行高效编译。我们开始正确地破解它,我们的测试是我们有一个流行模型库,我们正在高性能地运行其中的大部分,并且我们正在努力让所有这些模型都高效地运行。然后另一件事是我们希望从单个芯片扩展到许多芯片和软件,以便在您编写 AI 模型的方式和它的部署方式之间没有太多层。我们已经在大量芯片上展示了一些模型,我们正在努力使其更具产品化性,并制造出非常好的产品。
IC:以我在这里和你的团队呆了一段时间,我发现尽管有行业裁员,但你仍在招聘。随着这种转向更专注于软件的心态,你是否发现进入公司的人必须将他们的传统思维稍微转变?
Jim Keller:首先我们的软件团队比较小。我们正在招聘真正了解它的人。所以这很有趣——我们有高级程序员编写 JavaScript 和各种东西。有很多这样的人,他们在自己的领域内变得更强,然后你就有了系统级程序员;如果他们了解操作系统的各种细节,然后你就有了我们过去认为在硬件上编程的低级(low-level )程序员;然后在编译器堆栈中有同样的事情:有高级语言功能,然后是编译器的中间部分,然后是低级细节。我们需要的那种人是从头到尾都了解系统编程和编译器的人。
另一件有趣的事情是,Tenstorrent 是从具有 FPGA 综合背景和 HPC 背景的人开始的,因为 AI 是这些的组合,它们不会长在树上,所以人们带着不同的东西进来,他们必须进入‘我要构建一个软件工具链,它的一部分看起来像综合,一部分看起来像 HPC问题和它的一部分看起来像低级驱动程序代码'。我们雇用我们认为优秀的人,然后您必须在软件堆栈中找到自己的位置。这与软件堆栈中的标准描述有点不同,但我们运气不错——我们喜欢我们雇用的人。
IC:我一直在与您的 RISC-V 首席架构师 Wei-Han Lien 交谈。这是一个分为两部分的问题——为什么你的 AI 芯片中有内核,为什么它们是 RISC-V 内核?
Jim Keller:首先,我们的 Tensix 处理器有五个 RISC-V 内核,我们称它们为“Baby RISC”,它们执行诸如获取数据、执行数学操作数、推送数据、管理 NOC 以及执行一些操作其他事情。它们是 RISC-V,部分原因是我们可以编写它做我们想做的事——我们不必征求任何人的许可,我们可以更改 Baby RISC。他们实际上遗漏了一些东西——这非常简单。在下一代中,我们正在增强数学能力并修复了一大堆东西,这样我们就可以直接与本地硬件控制对话。所以这是我们的,我们可以做任何我们想做的事。
我们在下一代芯片中加入了 RISC-V,我们去要求其他供应商为我们添加一些浮点格式(他们拒绝了)。我们热衷于人工智能、浮点格式和准确性/精度的东西,人工智能程序必须支持它,因为你想要驱动小浮点数据大小,但要在数十亿次操作中保持准确性。RISC-V 的家伙说“当然”,这就是 RISC-V 存在的原因。
我们认为,在未来,AI 和 CPU 的集成将会很有趣。我们希望能够做我们想做的事,我不想请求别人允许添加数据类型或从处理器添加端口到此或更改数据移动引擎的工作方式 - 我只想能够做到。
IC:你也在转向小芯片——机器学习小芯片,CPU 型小芯片,原因是什么?
Jim Keller:有几个驱动力,一个是 3nm 流片非常昂贵,这是每个人都知道的事情;另一个是你想在密度和功率效率方面推动计算,但所有 IO 部分都不太关心;另一个重要的驱动因素是封装技术已经发展到可以得到精细间距、良好的低功耗 die-to-die PHY 并做你想做的事情的地步。
现在的梦想是你有一个 AI chiplet、一个 CPU triplet、一个 NPU chiplet,支持几种内存控制器、几种 PCIe 控制器,然后你可以用不同芯片的组合构建一个产品。你可以说这有点像一块板,但现在它在一个封装中,它在芯片所在的封装中,但它确实很短,芯片到芯片和高带宽的功率效率非常好。
我们怀疑未来几年会出现越来越多的头疼问题!我们已经和很多人谈过这个问题,我认为如果你有一个你真正想要的解决方案,并且你正在构建这个芯片,而其他人已经构建了另一个芯片,你就可以工作在一起并共同模拟,一起工作的可能性很大。然后很酷的事情是你可以用 [更少] 的tapeouts 构建更多产品,我也认为它会降低某些产品的门槛。
所以我认为这是一个非常好的主意。有几件事在推动它——对成本的需求、封装的可用性、人们在这些领域合作的意愿。但就像任何事情一样,这并不容易。这将是一团血腥的混乱,我预测一年后我会想'天哪,我们为什么要进入这个,我们应该等待其他人拿箭!(take the arrows)。
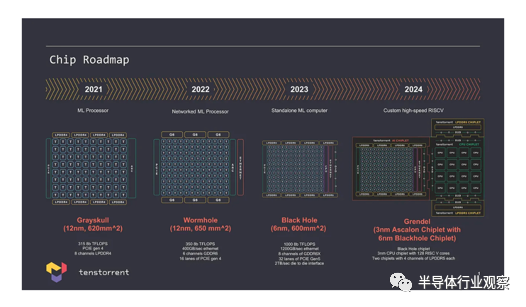
IC:Tenstorrent 目前有其路线图——Wormhole [2021]、Black Hole [2022]、Grendel [2023],然后是这个 chiplet 设计,以及 Ascalon 的多个设计点的公告。我们将 Tenstorrent 视为一家 AI 机器学习硬件公司,但如果你有小芯片并且有各种不同的 IP,那么你实际上是在销售产品还是在销售 IP?经营战略是什么?
Jim Keller:我们考虑过这个,对我来说它相对清晰。但是你知道,世界很复杂!我给你举个例子——如果你做一个 C 编译器,没有人会问你是在自动驾驶、工业控制还是数据中心上做,这仅仅是一个C编译器。那是一种技术。该技术可用于任何事物。所以我们是一家设计公司——就像我们设计硬件一样,我们设计 CPU 和 AI 软件,这就是我们所做的。这就是每个人进来做的事情。
现在,我们要销售产品。我们要卖的硬件产品是AI电脑。我们将出售芯片、电路板或系统。我们还有一个云,这样人们就可以来试用并加入。还有一些人并不是真的想买电脑,他们想用云,所以这本身就是一个产品。但我们也可以将我们的 AI 小芯片和 CPU 小芯片作为产品出售。这些是我们设计的技术,人们可以基于此用来做很多事情。
现在有趣的是,当我们向人们展示我们的计划时,就像这是这个 AI 芯片,然后我们将放入 RISC-V 处理器,因为我们想要在芯片中进行本地计算。我们从授权处理器开始,但随后我们建立了一个团队,该团队的表现超出了我们的目标。所以我们有这个你知道的非常棒的 CPU 团队,然后人们说'嘿,我可以买那个 CPU 吗?'。好吧,我真的不想将 CPU 作为产品销售,这是一个复杂的大市场,但其他人想要这样做,所以我们将对 CPU 进行许可。我们还将以小芯片上模式出售该 CPU,人们可以将其嵌入到自己的产品中,这变成了非常有趣的对话。对公司来说,他们就像‘好吧,我正在构建这个东西’,他们最不想做的就是支付许可费来许可 CPU,然后必须对其进行强化,这需要很多专业知识。拥有一个 CPU triplet,他们可以将其放入封装中来执行他们想要的操作。顺便说一句,还有其他人在做这样做,如果他们想要其他人的产品,那就太好了。
但我们是一家设计公司。特别是对于 CPU,当你构建一个复杂的 CPU 时,你需要多个目标,因为要让它正确,你需要自己模拟它。然后你与某人合作,他们模拟它,我向你保证,他们会发现你从未想过的错误。所以是的,我们一直热衷于为此寻找一些好的技术客户,或者你知道他们将在我们调试时成为合作伙伴。
Tenstorrent首先是一家设计公司,我们有伟大的架构师,然后真正困难的是人工智能。
IC:从我的角度来看,因为我们想到的机器学习硬件公司只是提供设备——看起来你在追求主机、设备,然后是“你想要多大”的所有不同组合你的小芯片,多少个核心,你想要什么样的核心'。这就是我认为 Tenstorrent 与该领域其他一些产品相比的差异化之处,而这只是您在团队中拥有的专业知识的一个功能。
Jim Keller:是的,所以你必须思考。在某些时候,客户需要解决方案。因此,如果您进入数据中心,就会看到一台服务器 - 它的定义非常明确,还有定义好的架顶式交换机,还有 SAN 或 LAN。有存储计算机和网络计算机,有时它们都集成在同一台服务器中,有时有服务器用于存储,服务器用于连接到网关,因此在这方面有很多区别。今天的人工智能主要是服务器上的加速卡——人们想要分解的人工智能。所以我们将看看它是如何发展的。
将 AI 计算和通用计算紧挨着构建芯片意味着当 AI 和那些人需要相互交谈时,他们不必去某个有延迟或功率开销和其他一切的地方。这将如何发展将是复杂而有机的。我们可以制作这种 AI 小芯片、CPU 和 AI,它们真的很忙,但它们仍然位于面向其他应用程序堆的服务器后面。但是可能还有另一个应用程序,现在我们有一个单芯片解决方案,你把它放在板上,你连接了一些传感器,你有一个边缘服务器,它不需要quote主机。这将如何发展,是所有人的关注。
IC:你害怕这些模型的初始输出,创造出无法解释的设计吗?所以当涉及到调试或边缘情况时,你真的不能去修复吗?(问题的背景是JK他们用AI去写一写代码)
Jim Keller:所以这是争论之一——就像在自动驾驶中一样,“难道你不希望部分代码由人类编写吗?”。因为你可以审核它,我在想“真的吗?”。如果您有 500 万行代码,由 100 人在五年内编写,其中大多数人不再在您的公司工作——您认为这是可以审计的吗?答案是否定的。
对于人工智能,这是一件非常有趣的事情——如果你有一个好的数据集,并且你有很好的训练,你实际上可以训练它到一个已知的损失函数(known loss function)。大型 C 程序的奇怪之处在于它没有损失函数。你不知道它的锋利边缘在哪里,它的完全失败在哪里。Windows已经发布很长时间了,每个人都在使用它,但它还经常出现蓝屏。所以这就是您知道的可审核软件?所以你也觉得AI低人一等?
另一个神秘的东西是写代码的人,人类,他们似乎也大多有智慧,而且他们也不可审计。我们不是生活在一个可以审计的世界里。
IC:我想你可以说,即使是现代硬件,硬件本身,也是不可审计的——有多少特性没有被记录下来。
Jim Keller:这是我过去多年来痛苦地学会的一点。所以最重要的是具有清晰边界的抽象层,因为我们并没有变得更聪明。我已经说过很多次了——我们并没有变得更聪明。我们构建更复杂的东西,但那些复杂的东西需要用某些人理解的组件来构建,经常发生的事情是你有一个非常棒的设计,然后你用了十年向它添加东西 ,人们来来去去。在某些时候,它开始变得脆弱,人们会说“哇,它变得越来越复杂了!”。不,它只是变得一团糟。就像你没有做正确的事——在某个时候你应该停下来,你应该放下你的铅笔,把它分成几块,确保每一块都有一个理解它的主人,它们之间的接口有一组人类可读的事务,您可以对其进行验证。
因此,设计良好的硬件是相当可预测和可理解的——不像像毛球一样成长的硬件。有一篇论文叫“Big Ball of Mud”,我很喜欢。每个人都应该去谷歌一下,看看这篇论文,因为它实际上是软件灾难的定义,硬件也是如此。
IC:我想我认为这可以追溯到你之前提出的关于撕毁一切并以新基线重新开始的观点,这比人们往往想要做的更频繁。
Jim Keller:是的,这是我四到五年前说的。正确的数字实际上是三年,因为您需要一年的时间才能克服必须这样做的事实!
你必须——如果不是重新设计,那就是重构,并且愿意这样做,因为你只会到达一个点,它是如此复杂和脆弱,以至于你无法触摸它。然后出了问题,你真的创造了一些你无法控制的东西。
所以回到 AI 点,关于 AI 的奇怪之处在于你有一个新的模型,你有一个新的数据集,你有新的误差函数,然后你训练它。您可以重新生成它所做的事情——对于大型语言模型来说这是不合理的,但大多数模型在合理的时间内。在某种程度上,您永远无法为所有 RTL 或所有历史基础架构重新生成 500 万行 C 代码。因此,AI 指向的是一个实际上移动得更快而不是更慢的未来。
史蒂夫·乔布斯 (Steve Jobs) 对此有一句名言:“未来在加速”。所以你的未来必须走得更快,所以你不能处于这样一种情况:你越成功,你拥有的“遗产”就越多,然后你就走得越慢。
IC:那么这是否意味着今天将永远是最舒适的?
Jim Keller:不,是昨天!今天是不确定的,昨天是你所知道的最舒服的。人们热爱过去,因为他们有选择地编辑自己的记忆。10 年前发生的事情没有不确定性——你可能会为此感到难过或其他什么,但你不会感到惊讶。所以未来是一个令人生畏的地方。我没有那样想过。
IC:回到Tenstorrent,我们上次谈话时你说了一些让我产生共鸣的话,我之前在演讲中实际使用过:你必须有一个内核,看起来像一个芯片,看起来像一个系统,现在这个观点有什么改变吗?
Jim Keller:没有。嗯,我想了很多。因此,如果在计算世界开始时,你自然而然地拥有一千个处理器,那么所有的软件开发都将是如何在一千个处理器之间进行协调。但是从 1950 年左右到 2005 年左右,大多数人都在一台计算机上编程,所以计算机是一个单一的东西,可以在 PC 上执行指令,而且在大部分时间里,他们一次只执行一条指令。
所以现在这些做GPU 的人,当它可编程时,他们有上千个线程——所以他们开始考虑它。但是他们在编程模型中的思维方式仍然是单线程执行但重复了很多次。我们称其为标量程序向量,这是一件奇怪的事情。但是现在你想编写一个程序来运行并使用数千个处理器,老实说,你必须愿意容忍一些严重的低效率才能实现这一目标。
如果有人使用 chatGPT 写东西,它会做一些疯狂的事情,比如产生新颖的段落,但它也会弄清楚标点符号放在哪里。现在标点符号可以用一个简单的 C 程序来完成——在一些单词的末尾有两个空格;放入句号或逗号。这不是火箭科学。你认为使用 chatGPT 来做一些 c 程序可以做的事情,这实际上是使用每秒 petaflops 的计算来放置一个逗号,而不是 100 行 C 程序。
但事实是,您的大脑有 10^20 个操作中的 10^18 个,您愿意花半秒钟时间思考逗号放在哪里。你不认为那是低效的吗?我们使用这些大型计算机来做非常简单的事情。你知道,我女儿正站在冰箱前,试图决定是喝橙汁还是牛奶——这是每秒 10^18 次操作,持续三秒钟。那是 3x10^18,一个非常大的运算量!
IC:它让我想起了关于谷歌搜索如何消耗足够的能量来煮水壶喝一杯茶或其他东西的奇怪统计数据。
Jim Keller:是的!所以人工智能,以及一般意义上的智能,把一切都放在一个你可以思考事物并做出某种选择的领域,这是一个非常有趣的现象。事实上,“是的,现在我们可以制造一台计算机”,我们正在制造一台有 1000 个芯片的计算机,每个芯片有 200 个内核——也就是 200,000 个处理器。我们想从一个简单的程序开始,通过一个软件堆栈来编写程序,让你编写一个程序,就好像你正在执行这个程序一样,并将它部署到看起来像成千上万的小兵一样的东西上。想想这有点令人震惊,但你的大脑有数百亿个神经元,它们本质上都在做同样的事情——它们都是相互协调的小电脑。所以这是一种自然的行为。
Amazon 的 Lambda 就是这样的东西——用高级语言编程,无需考虑内核就可以部署数千个内核。我敢肯定它的“每线程”效率低得离谱,但从意图到行动的角度来看,它的效率确实高得离谱,这正是我们优化的目标。
IC:所以你刚才说你正在建造一台有 1000 个芯片的计算机,每个芯片有 200 个内核。再一次,你在我们上次发言时说过的另一件事是,你需要找到想要用 100 个芯片构建系统的客户来满足想要 1000 个芯片的客户,然后构建一个千个系统来满足想要 10000 个芯片的客户。
Jim Keller:所以我们不想做的是把产品卖给某个人,而这个人又卖给那些遇到他们无法解决的问题的人。我想做的是,我们想要构建可用的、可编程的 AI 计算机,然后在短期内将它们出售给想要对 AI 计算机进行编程的人。他们将从小处开始,你知道 10、100、1000 个芯片。然后他们会说这是否好,他们会扩大规模,我们也会扩大规模。然后我们会卖给更多的人,在某个时候,我们会卖给卖给某人的人。我们希望循序渐进地做到这一点,因为 AI 软件堆栈及其在各个方面的扩展都很困难。我们认为我们有一个很好的计划来做到这一点,并且我们已经与很多人就此进行了接触。
扩展多个维度是有用的,但从单核到百万核并拥有一个可以灵活地做到这一点的软件堆栈才是我们的使命。在某些时间点,这将是一件相当正常的事情,但现在这是一个技术问题。
以上为采访的部分内容编译,希望能对广大读者有参考意义。更多采访细节,请查看文章最后的“阅读原文”。
*免责声明:本文由作者原创。文章内容系作者个人观点,路科验证转载仅为了传达一种不同的观点,不代表路科验证对该观点赞同或支持,如果有任何异议,欢迎联系路科验证。
