--关注、星标、回复“26262”--
↓↓领取:ISO 26262↓↓
由于构建自主机器人感知系统的需求,传感器融合能够充分利用跨模态信息已引起研究人员和工程师的大量关注。然而,为了大规模地构建机器人平台,需要强调自主机器人平台带来的成本。camera和radar本身就包含互补的感知信息,有潜力大规模开发自主机器人平台。然而,与LiDAR与视觉融合相比,雷达与视觉融合的工作有限。
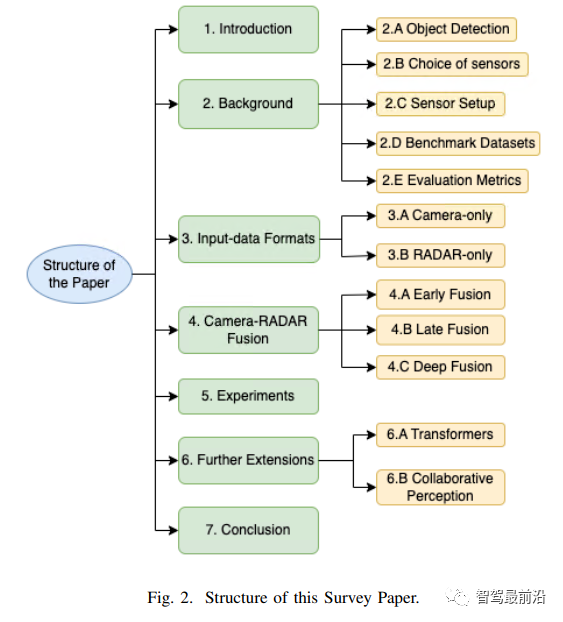
本文通过对BEV目标检测系统的视觉毫米波雷达融合方法的调查来解决这一差距。首先将介绍背景信息,即目标检测任务、传感器选择、传感器设置、基准数据集和机器人感知系统的评估指标。随后,将介绍每种模态(相机和radar)数据表示,然后详细介绍基于子组的传感器融合技术,即早期融合、深度融合和后期融合,以便于理解每种方法的优缺点。最后,我们提出了视觉radar融合的未来可能趋势,以启发未来的研究。
领域应用背景
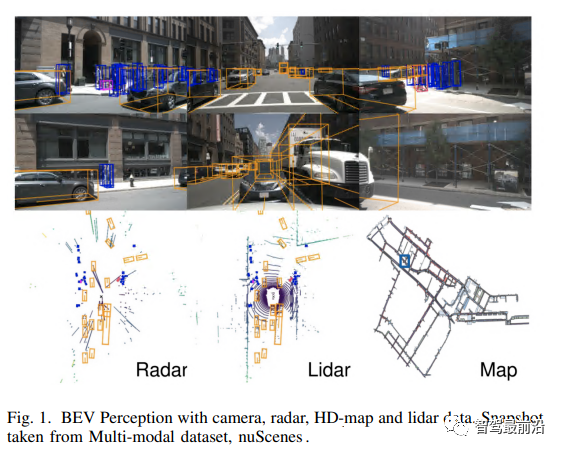
相机在BEV预测中的泛化能力不太好,因为它们接收的输入受到2D像素的限制,然而却包含非常丰富的语义和边界信息。radar的数据已经包括输入点云中的3D数据和速度数据,但缺乏密集的语义信息。由于这些原因,相机-radar传感器组合可以很好地一起工作,但是这些传感器接收的数据需要映射到单个坐标系,接收到的输入数据如图1所示:
本文计划通过涵盖BEV背后的基础知识来解决这一差距,然后深入研究现代视觉radar融合技术,从而更加关注基于transformer的方法。本文的主要组织结构如下:首先在第二节中查看了解机器人BEV感知所需的背景信息,即关于目标检测任务、传感器选择、基准数据集、评估指标等信息。然后,将在第三节中介绍相机和radar的输入数据格式。在第四节中,将详细分析相机和radar融合方法所涉及的技术。此外,还将对它们进行分组,以便能够轻松地理解。稍后,在第五节中,将展示所讨论的方法如何评估相机radar基准nuScenes。然后在第六节中,将对当前的研究趋势进行可能的扩展,这可能会启发未来的研究。最后,在第七节中,将总结整体的研究结果!
3D目标检测是机器人/自动驾驶平台的一项重要任务。目标检测是两个基本计算机视觉问题的结合,即分类和定位,其目的是检测预定义类的所有实例,并使用轴对齐的框在图像/BEV空间中提供其定位。它通常被视为一个利用大量标记图像的监督学习问题,目标检测任务中的几个关键挑战包括:
box BEV表示:相机图像在透视图中,但下游自治任务在鸟瞰图(BEV)中运行。因此,需要一种将透视信息转换到正交空间BEV的方法。这带来了深度模糊的固有问题,因为正在为这个问题添加一个新的深度维度。
丰富的语义信息:有时需要区分看起来非常相似的物体,例如,附近有多个看起来相似的物体或可能是在滑板上操作的行人。在后面的例子中,滑板上的行人应该遵循骑车人的运动模型,但很难检测行人的这种属性。为了识别这些细粒度信息,需要在模型中嵌入深层语义。
效率:当构建更大、更深的网络时,需要昂贵的计算资源来进行部署,边缘设备是部署平台的常见目标,它很容易成为瓶颈。
域外对象:可以训练网络的数据有限,在测试时可能会遇到一些训练时没有见过的物体,总是缺少一些检测器的泛化能力。
传感器的选择
相机和radar传感器具有互补的特征,两者提供了强大的感知组合。相机对检测的贡献来自:丰富的语义信息和精确的边界,特别是在恶劣天气条件下,相机在融合时间数据或预测具有精确深度的box方面不是很好。然而,radar能够补充!radar可以利用点云中的多普勒效应非常准确地预测物体的深度和速度,雷达数据非常稀疏,因此也不需要太多的计算负载。与其它激光传感器相比,雷达的波长更长,使其成为唯一的感知传感器,其性能不会因恶劣天气条件(即雨/雪/灰尘等)而降低,图3中就很好地总结了这些特性。

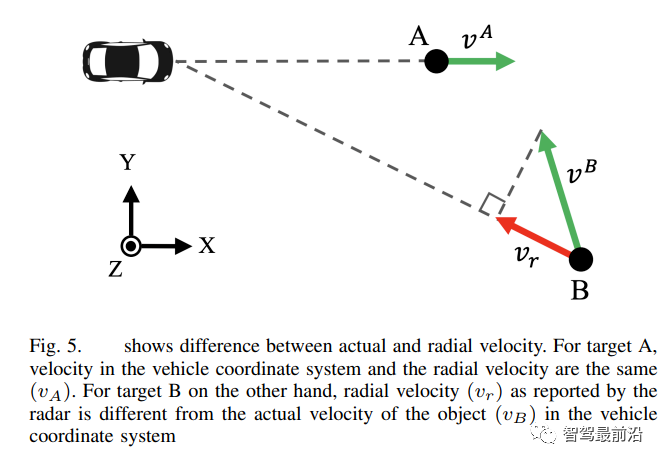
radar的另一个较少被讨论的问题是,它无法检测沿径向方向的速度分量,如图5所示。另外一个,事实上任何基于激光的传感器都在检测黑色物体/汽车上有缺陷,这些物体/汽车吸收了落在它们身上的大部分激光,在这些特殊情况下,camera是一种可依靠的传感器!
传感器设置
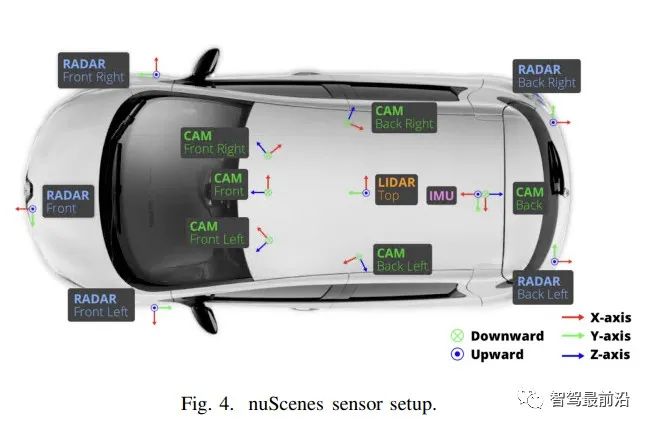
每一套传感器的自动驾驶汽车(AV),可能会因不同的自动驾驶汽车公司而异。通常每辆车有6−12个摄像头和3−6个radar,需要这些传感器来覆盖整个周围的3D场景。一般只能使用具有正常FOV(视野)的相机,否则可能会得到无法恢复的图像失真,如鱼眼相机(宽FOV),其仅适用于几十米。在图4中可以看到AV空间中最被引用的基准数据集之一nuScenes中的感知传感器设置。由于价格低廉的原因,与激光雷达相比,AV/移动机器人行业一直在生产汽车的radar和camera上投入更多资金。

Benchmark Datasets
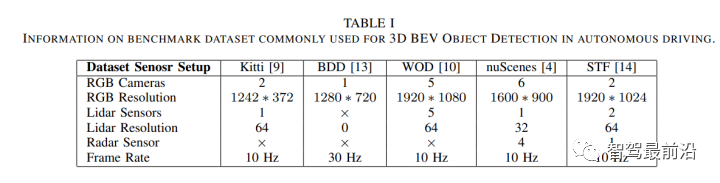
nuScenes、KITTI和Waymo开放数据集(WOD)是三种最常用的3D BEV目标检测任务基准,除此之外,H3D、Lyft L5、BDD、STF和Argovers也可用于BEV感知任务,关于这些数据集的详细信息可参见表1:
评测指标
3D目标检测器使用多种标准来测量检测器的性能,如精度和召回率。然而,平均精度(mAP)是最常用的评估指标,IoU是预测框和GT之间的重叠面积和联合面积之比。IoU阈值(通常为0.5)用于判断预测框是否与任何特定的真值框匹配。如果IoU大于阈值,则该预测被视为真阳性(TP),否则为假阳性(FP),漏检视为假阴性(FN)。
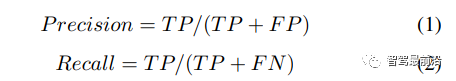
此外,还有一些特定于数据集的度量,即,KITTI引入了平均方向相似性(AOS),用于评估地平面上长方体的方向估计质量。mAP度量仅考虑目标的3D位置,但忽略了维度和方向的影响。与此相关,nuScenes引入了TP度量,即平均平移误差(ATE)、平均尺度误差(ASE)和平均方位误差(AOE)。WOD引入了按航向加权的平均精度(APH)作为其主要度量。此外,考虑到像相机这样的2D传感器的深度混淆,WOD引入了纵向误差容忍3D平均精度(LET-3D-AP),它更强调预测中的横向误差而非纵向误差。
输入数据格式
全景相机图像可以用表示。这里,N、V、H和W分别是时间帧的数量、视图的数量、高度和宽度,每个都具有一个外矩阵和一个内矩阵,可以在BEV坐标系中找到特征的光栅化BEV图,,其中C、X和y是BEV图的通道深度、高度和宽度。外部矩阵和内部矩阵一起定义了V个摄像机视图从参考坐标(x,y,z)到局部像素坐标(h,w,d)的映射。Radar是机器人中使用的另一组主动传感器,它发射无线电波来感知环境,并测量反射波来确定物体的位置和速度。传感器的原始输出是极坐标,可以通过传感器校准矩阵轻松转换为BEV空间。然而,噪声Radar点必须经过滤波,这将利用某种形式的聚类和时间跟踪,这种时间跟踪可以通过卡尔曼滤波器实现。卡尔曼滤波器是一种递归算法,它可以通过获得先前观测到的目标状态估计和当前状态的测量值来估计目标的当前状态。运行内部过滤后,返回BEV中的2D点(无高度尺寸),提供到物体的方位角和径向距离。它还产生每个2D点的径向速度矢量分量,如图5中所示,这里可以将点视为检测到的对象。在BEV传感器融合研究工作中,Radar探测被表示为以自我为中心的坐标系中的3D点。雷达点云中的这个3D点被参数化为P=(x,y,z,vx,vy),其中(x,y,z)是位置,(vx,wy)是物体在x和y方向上的径向速度。这个径向速度是一个相对速度,因此需要用自我车辆的运动来补偿。由于该雷达点云的高度稀疏性,通常聚合3-5次时间扫描。它为点云表示添加了时间维度,由于在许多方法中,检测头都在360度环绕场景中,因此将车辆周围所有雷达的3D点合并为单个合并点云。nuScenes数据集提供了将Radar点云从雷达坐标系映射到自我中心坐标系所需的校准参数,自动驾驶汽车的雷达点云见图1。

Camera-Radar融合
根据在哪个阶段融合两个传感器的信息,这些方法可以分为三类,即早期融合、后融合和深度特征融合。早期和后融合都只有一个不同特征的交互操作,在模块开始或结束时进行处理。然而,深度融合具有更多不同特征的交互操作,这三种方法总结在图6中。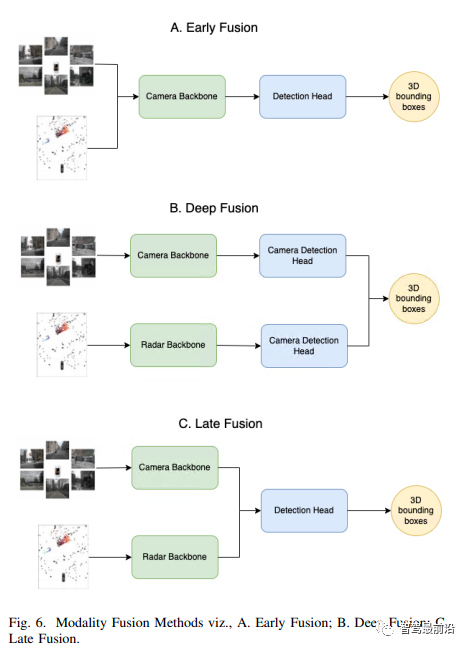
早期融合
早期融合也称为数据级融合。这是三种方案中探索最少的一种,在该方法中,来自两个传感器的信息在非常早期的阶段即在计算任何特征之前被融合在一起,这种方法的关键挑战之一是数据的同步。我们有来自不同坐标空间的相机和雷达数据,而且数据的性质也非常正交,前者是密集的2D像素,而后者是稀疏的BEV点云。这种方法具有最小的数据丢失问题,然而,没有有效的方法来处理从相机和雷达收集原始数据的复杂性。这一融合类别中的共同工作通常是按顺序完成的,这里首先基于雷达点提取感兴趣区域(ROI);然后将它们投射到相机上;并使用一些启发式方法来收集区域中的相机特征。这不是非常可靠的方法,因为很有可能会在雷达点云中预先过滤掉关键目标,而且由于设计的性质,甚至不会在图像中查找这些目标。然而,这种方法的另一个好处是,只对ROI内的图像部分执行卷积运算,从而节省了一些计算预算!后融合
后期融合工作是这三种工作中最简单的,这使得它成为过去十年基于相机-雷达融合的目标检测工作以来最常见的方法。从之前的推理中可以很肯定,一些物体和属性可以通过相机更好地处理,而其它物体和属性则可以通过雷达更好地处理。该方法允许各个传感器检测它们做得最好的目标,并使用数据关联技术将2组检测融合为1组检测。例如,一般来说,相机可以很好地检测box,雷达可以很有信心地检测速度,该流程中的工作可进一步分为两个部分:1) 基于概率推理:在这种方法中,贝叶斯跟踪方法以多模式的概率密度跟踪多智能体目标,它用分量概率密度近似每个模式。贝叶斯算法和粒子滤波器(PF)处理非线性和非高斯估计。这是一种迭代算法,它递归地估计多个目标的状态,并使用最大似然确定当前目标数量。2) 基于卡尔曼滤波器:在这种方法中,通过获得先前观察到的目标状态估计和当前状态的测量值来估计目标的当前状态。简单的卡尔曼滤波器不能准确地结合非线性系统。然而,EKF(扩展卡尔曼滤波器)和UKF(无迹卡尔曼滤波器)是更复杂的系统,可以在系统中引入非线性。EKF将非线性问题线性化,而UKF采用统计线性化技术通过采样点将随机变量的非线性函数线性化。SORT和Deep SORT是这一领域的开创性论文。SORT探索了利用匈牙利匹配进行数据关联的多目标跟踪任务和利用卡尔曼-菲特勒估计的恒速运动模型。Deep SORT是对这项工作的进一步扩展,其中作者还在算法中以图像特征的形式添加外观信息。这两种算法都非常便宜,并且可以由边缘设备轻松处理。MHT是另一种通过检测进行跟踪的方法,它保留了一小部分潜在假设,这可以通过当前可用的精确目标检测器来实现!后期融合方法可以利用作为模块化组件独立开发的现成检测算法,然而,依赖于启发式和后处理技术的后期融合策略会受到性能可靠性权衡的影响,特别是当这两个传感器不一致时!深度特征融合
深度融合也称为特征级融合,在这种方法中,以特征的形式融合两个传感器的信息,因此将其作为先前讨论的方法的中间部分。根据目前的研究工作,这种方法似乎最有前途。这是一种基于学习的方法,其中摄像机和Radar的特征可以并行计算,然后相互软关联,该方法可进一步分为三个部分:1) 基于Radar图像生成:为了将雷达信息引入图像域,提取雷达特征并将其转换为类似于图像的矩阵信息,这被称为雷达图像。该雷达图像的信道表示来自雷达点表示的信息,即距离、速度等物理量。由于雷达点云中固有的稀疏性,这种方法并不成功,这使得它们无法形成良好的像矩阵一样的图像!2)基于CNN:这一工作重点是卷积神经网络(CNN),用于从两种不同的模式进行特征融合。直到2年前,基于CNN的探测器一直是SOTA,直到transformer开始对空间环境做出贡献。在CNN的部分中,一项代表性工作使用了基于RentinaNet和VGG骨干的神经网络。它使用雷达channel来增强图像。该模型通过估计2D box使问题更简单。有专家声称,一个雷达点中编码的信息量与一个像素的信息量不同,因此不能简单地提前融合这些不同的信息。一个更为理想的解决方案是在CNN的深层进行,在那里,信息更加压缩,并且在潜在空间中包含更多相关信息。由于很难抽象出什么深度是正确的融合深度,作者设计了一个网络,让它自己学习这种融合策略。这些作者还介绍了一种称为BlackIn的技术,使用了丢弃策略,但在传感器级别而不是神经元级别。这有助于更多地利用稀疏的雷达点信息,这些信息可能很容易被密集的相机像素遮挡。CenterFusion是另一项基于中心点检测框架来检测目标的工作,论文使用基于截头体的新方法来将雷达检测结果与其对应的目标中心相关联,从而解决了关键数据关联问题。相关雷达检测用于生成基于雷达的特征地图,以补充图像特征,并回归到目标属性,如深度、旋转和速度。作者声称,仅仅增加雷达输入就可以显著提高速度估计,而不需要复杂的时间信息。这项工作的主要问题是,它将主传感器视为camera,并将直接丢弃仅由雷达感测的检测。该方法的另一个问题是它基于图像中的BEV中心对雷达点进行采样。然而,由于其2D透视图输入数据,无法保证图像网络能够预测良好的BEV中心!3) 基于transformer:该工作线通常使用transformer模块,即交叉关注来自不同模态的特征,并形成更精细的特征表示。CRAFT中的一项代表性工作将图像建议与极坐标系中的雷达点相关联,以有效处理坐标系和空间属性之间的差异。然后在第二阶段,使用连续的基于交叉注意力的特征融合层在相机和雷达之间共享空间上下文信息,本文是迄今为止排行榜上的SOTA方法之一。MT-DETR是另一种利用类似的交叉注意力结构来融合交叉模态特征的方法。
实验
nuScenes是文献中广泛使用的数据集,图4中的传感器设置包括6个校准camera和5个雷达,覆盖整个360度场景讨论的作品的结果显示在表II中的nuScenes测试集上,这是在滤波器下camera雷达跟踪检测。
未来的方向
基于生产多域BEV感知检测的最新发展,论文主要强调未来研究的可能方向。transformer扩展:从基准数据集的趋势来看,很明显,基于transformer的网络能够在视觉和雷达数据之间建立正确的模型,以获得良好的融合特征表示。即使在基于视觉的方法中,transformer也领先于卷积。如II DETR3D和BEVFormer中所强调的,可以很容易地扩展到从雷达点云发起查询。可以为雷达图像添加一个新的交叉关注层,而不是仅仅关注视觉特征。协作感知:一个相对较新的领域是如何利用多代理、多模态transformer来实现协作感知。这种设置需要最小的基础设施设置,以实现道路上不同自动驾驶车辆之间的顺畅通信。CoBEVT展示了车对车通信如何导致卓越感知性能的初步证据,并在OPV2V的V2V感知基准数据集上测试其性能。参考
[1] Vision-RADAR fusion for Robotics BEV Detections: A Survey转载自自动驾驶之心,文中观点仅供分享交流,不代表本公众号立场,如涉及版权等问题,请您告知,我们将及时处理。
-- END --