当今时代,通过科技改变生产生活方式的各种先进技术纷纷崛起,交通产业也经历着巨大的变革。国家对于智能交通和交通强国战略的支持使得交通产业更加需要相关技术支撑与赋能。对此,百度飞桨团队与 Apollo 自动驾驶团队强强联合,聚焦人工智能关键技术,深耕自动驾驶各个场景,汇聚各方力量,不断拓宽开源之路。
此次,飞桨基于和 Apollo 自动驾驶团队合作开发的大量业务实践经验,结合自动驾驶感知算法开发难点,联合 NVIDIA 在 NGC 飞桨容器中进行深度适配,正式发布飞桨首个端到端 3D 感知开发套件 Paddle3D,欢迎大家在 NVIDIA GPU 上体验!
加入 Paddle3D 技术交流群
体验 NVIDIA NGC + Paddle3D
Paddle3D 官方开源代码链接如下,也欢迎大家入群进行 3D 感知开发的技术交流,接下来将为大家全面介绍 Paddle3D。
https://github.com/PaddlePaddle/Paddle3D

Paddle3D 概览
Paddle3D 是百度飞桨官方开源的端到端 3D 感知开发套件,套件整体结构自下而上分为框架层、基础层、算法层、工具层 4 层。接下来具体介绍 Paddle3D 的整体架构。
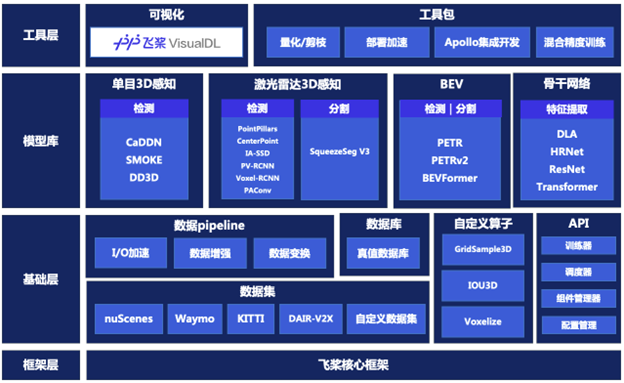
2.1 基础层
基础层主要提供了数据处理管道、数据集的基础支持、自定义算子的开发支持、高级 API 支持。
2.1.1 数据处理管道
提供数据处理的 I/O 加速能力,提高训练阶段数据吞吐速度。同时提供多种数据变换、数据增强能力,满足 3D 模型的快速开发。
2.1.2 数据集
在本次的正式版中,我们全面支持了自动驾驶三大开源数据集 KITTI、Waymo 和 nuScenes。同时,Paddle3D 还支持用户自定义数据集进行训练,详情请前往 Paddle3D 官方开源仓库。
2.1.3 真值库
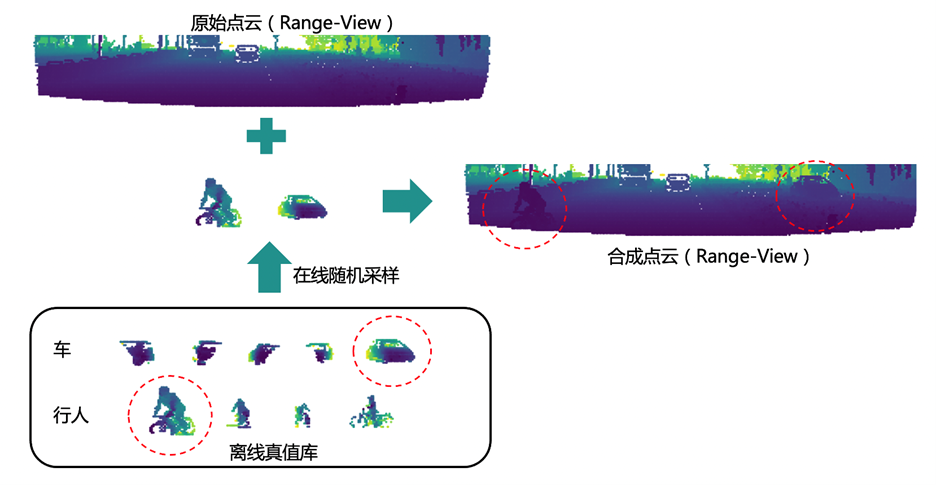
在模型精度优化方面,除了模型层面的一些优化策略,Paddle3D 在数据层面也提供了基于真值库的在线优化策略。在做自动驾驶感知任务时,采集和标注点云数据所耗费的人力成本偏高,我们希望可以充分利用已有的数据来拓展训练数据的多样性。基于真值库的在线优化策略是先根据已有的训练数据离线地生成真值库,训练的过程中在线地从真值库里面随机采样一些真值目标,放到当前帧中来合成一帧新的点云,从而提升模型的泛化能力。
下图是使用这个优化策略前后的精度对比情况,整体精度有 5.39%的提升。

2.1.4 自定义算子即训即推
3D 感知模型在训练过程中会遇到需要开发特色的自定义算子的情况,例如用于过滤重叠三维框的非极大值抑制操作(3D IoU NMS)、PointNet++中聚合和采样点云的操作、点云体素化操作等等。Paddle3D 的模型均可基于飞桨的原生推理库 Paddle Inference 完成服务器端和云端的模型部署,且不需要在部署阶段重新开发自定义算子,完全做到即训即用。
2.2 算法层
算法层主要提供了开箱即用的单目 3D 感知、点云 3D 感知、BEV 3D 感知、多模态 3D 感知等算法,同时提供了主流的骨干网络实现参考。
2.2.1 单目 3D 感知模型
在和自动驾驶开源框架 Apollo 的合作过程中,我们沉淀了 SMOKE、CaDDN 这两个经典的单目 3D 感知模型,并且已经作为 Apollo 最新的内置 3D 视觉感知模型。此外,在本次正式版发布中,我们还新增了 DD3D 模型,FCOS3D 模型的支持也即将完成。

2.2.2 激光雷达 3D 感知模型
除了视觉模型之外,我们在和 Apollo 的合作过程中同样沉淀了激光雷达 3D 感知模型 PointPillars、CenterPoint,且已作为 Apollo 的原生激光雷达支持模型,本次正式版中我们还新增了 IA-SSD、PAConv、PV-RCNN、Voxel-RCNN 等前沿点云 3D 检测模型,同时,也补充了点云分割模型 SqueezeSegV3。

2.2.3 BEV 模型
在自动驾驶任务中,对周围场景的视觉感知非常重要,这一工作可以通过多个摄像头给出的二维图像完成对 3D 检测框或语义图的检测。当前,最直接的解决方案是使用单目相机框架和跨相机后处理,该框架的缺点是其需要单独处理不同的视图,无法跨相机捕获信息,导致性能和效率低下。作为单目相机框架的替代方案,一种更统一的框架是从多目相机图像中提取整体表示。鸟瞰图 (Bird’s Eye-View,BEV) 是一种常用的周围场景表示方法,它能清晰地呈现物体的位置和规模,适用于各种自动驾驶任务。
而最近以 BEV 为基础的 3D 检测方案席卷自动驾驶届,我们也在持续跟进该方向。目前已在 Paddle3D 的模型库中补充BEV经典模型 PETR、PETRv2、BEVFormer,而 BEVFusion 正在实现中,即将和大家见面。

2.3. 工具层
工具层主要提供了基于 VisualDL 的训练、推理效果可视化,同时提供了模型的量化部署加速能力、Apollo 的集成开发能力以及混合精度训练能力。
2.3.1 自动混合精度训练支持
自动混合精度训练(Auto Mixed Precision, AMP)是指通过混合使用单精度和半精度数据格式,加速深度神经网络训练的过程,同时保持了单精度训练所能达到的网络精度。混合精度训练能够加速计算过程,同时减少内存使用和存取,并使得在特定的硬件上可以训练更大的模型或 batch size。
Paddle3D 目前全面支持混合精度训练,从而进一步优化 3D 感知算法开发对硬件的需求,加速训练。
2.3.2 量化部署支持
模型量化是一种将浮点计算转成低比特定点计算的技术,可以有效地降低模型参数大小,降低算力、内存等资源消耗,从而提升模型在端侧硬件上的运行效果。
3D 感知模型相比传统的 2D 检测模型往往模型更复杂,参数更多,在服务器上可能可以达到不错的推理速度和精度的平衡,但是实际部署时,由于硬件算力限制,帧率往往达不到要求。对此,Paddle3D 对 3D 感知模型通过量化压缩等手段在端侧硬件达到了实时性能。目前官方支持 SMOKE、CenterPoint 的量化部署,同时 Paddle3D 将结合飞桨部署神器 FastDeploy 对 3D 感知模型通过量化压缩等手段在端侧硬件进行端到端的优化,支持更多模型的量化部署,链接参考如下:
https://github.com/PaddlePaddle/Paddle3D/tree/develop/configs/quant
https://github.com/PaddlePaddle/FastDeploy
2.3.3 稀疏卷积支持
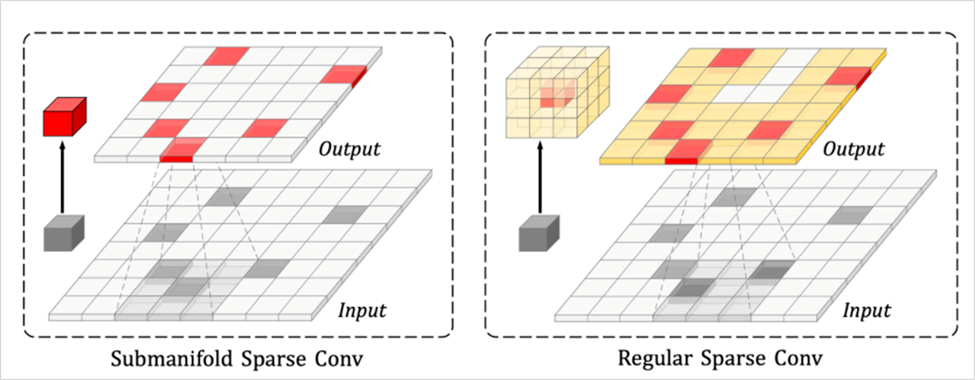
在基于点云的 3D 检测任务中,主流的解决思路会把无序的点云表示成有序的三维体素空间,精准地学习到几何结构特征的最佳方法莫过于采取 3D 卷积。但是 3D 卷积耗费非常大的显存和计算量,使得面向实时端侧场景的应用须以损失部分检测精度作为代价,将三维空间压缩至二维空间后采用 2D 卷积来换取速度的提升和计算量的减小。然而,室外场景中数量高达~100k的点云经过体素化后,三维体素空间的稀疏性低至~0.5%,采用 3D 卷积会有大量零元素的计算浪费。
在稀疏 3D 卷积中,会预先建立一个规则表,表中仅记录与卷积核相乘的非零输入元素及其输出元素在密集特征层上的位置,基于规则表完成卷积计算可避免零元素的无效运算。飞桨框架 v2.4 已经全面支持稀疏计算,Paddle3D 也集成了许多使用稀疏 3D 卷积的前沿模型,如 PV-RCNN、VoxelRCNN、CenterPoint。以CenterPoint 为例,基于飞桨原生推理库 Paddle Inference 在一块 RTX 3080 显卡上的推理速度可达到 21.20 毫秒每帧,nuScenes 验证集上精度 NDS(NuScenes Detection Score)可达到 66.74%。
2.4. 用户体验持续优化
2.4.1 3D 感知算法多卡算力在线开发
考虑到 3D 感知算法在实际开发过程中对显存等硬件资源需求较大,飞桨团队提供了免费的算力资源,方便大家在线开发,同时 Paddle3D 也提供了官方的在线开发示例,欢迎大家 fork 进行二次开发。
在线开发示例链接如下:
https://aistudio.baidu.com/aistudio/projectdetail/5268894
https://aistudio.baidu.com/aistudio/projectdetail/5269115
2.4.2 详细文档
文档是快速上手一个开源项目的关键,Paddle3D 针对模型训练部署以及每个算法都有详细的文档说明,欢迎大家阅读浏览,同时我们也欢迎大家一同建立更完善的 Paddle3D 文档和教程。
2.4.3 直播课&技术解读文章
考虑到 3D 感知的更新迭代速度快,上手难度大,Paddle3D 会定期组织直播课程,由开发同学为大家深入讲解 3D 感知算法的开发、部署细节。同时也会定期发布技术专栏文章进行解读。相应的课程链接以及技术文章链接我们会定期更新到 GitHub 首页,再次欢迎大家关注 Paddle3D 官方仓库:
https://github.com/PaddlePaddle/Paddle3D
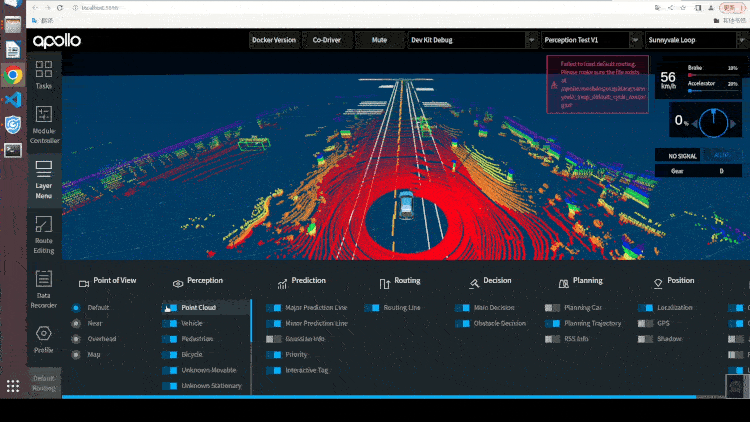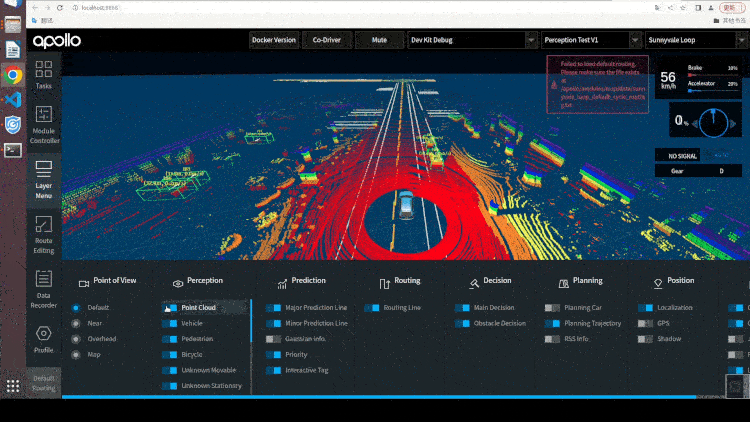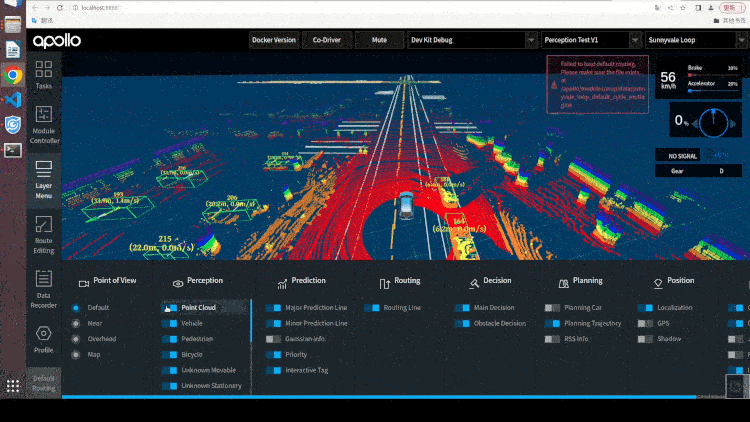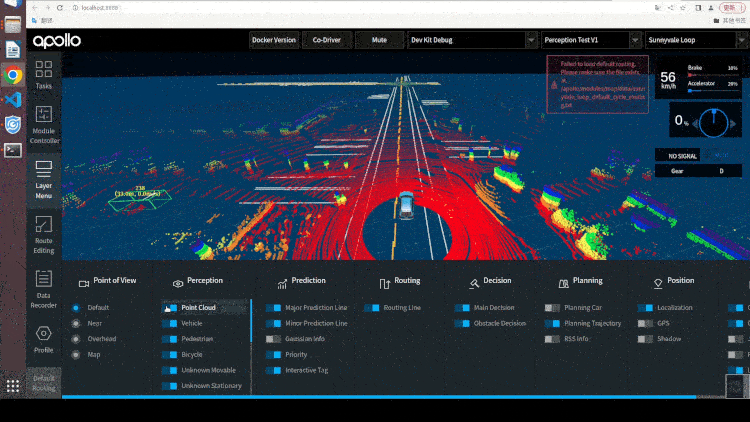
2.5 Paddle3D & Apollo 无缝衔接
Apollo 是由百度开源的开放、完整、安全的自动驾驶平台,助力开发者快速搭建自动驾驶系统,Apollo 官方仓库:
https://github.com/ApolloAuto/apollo
Paddle3D 和 Apollo 在持续性的进行合作开发,目前已打通视觉感知模型 SMOKE、CaDDN,点云感知模型 PointPillars、CenterPoint,BEV 感知模型 PETR 等模型的训练和推理。用户可以在 Paddle3D 进行模型的训练、测试、导出,然后一键部署集成到 Apollo 的感知算法部分,和下游的跟踪算法、多传感器融合算法、预测算法、规划控制算法全栈运行。同时,用户可以通过 Apollo 的 DreamView 平台联合定位、预测、规划控制模块进行仿真调试,找出 Badcase 指导模型的优化开发。
详细开发步骤请参考:
https://apollo.baidu.com/community/Apollo-Homepage-Document/Apollo_Doc_CN_8_0/lidar
https://apollo.baidu.com/community/Apollo-Homepage-Document/Apollo_Doc_CN_8_0/camera

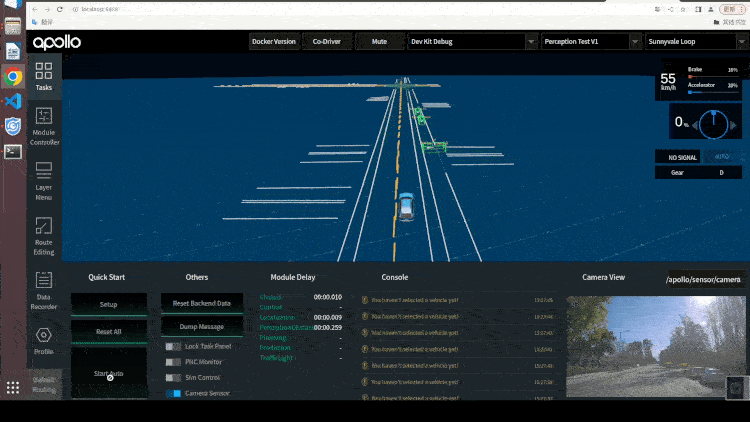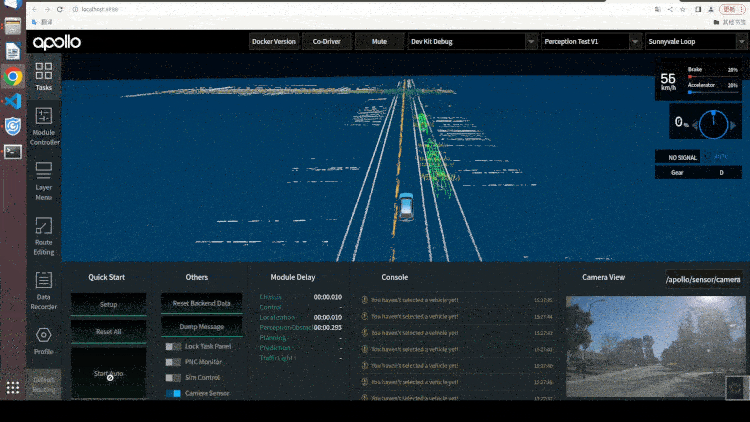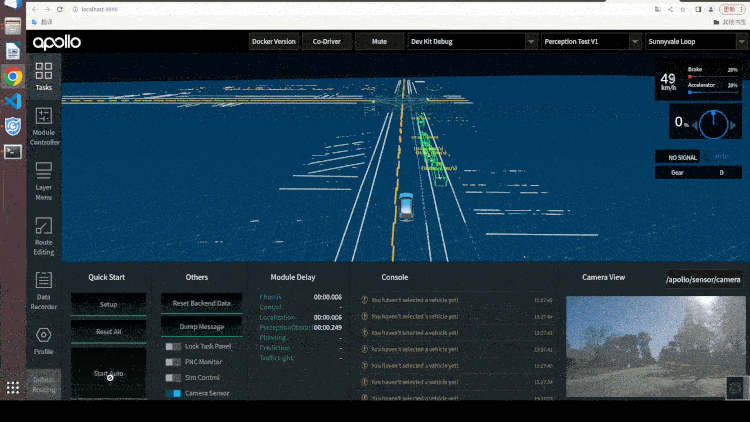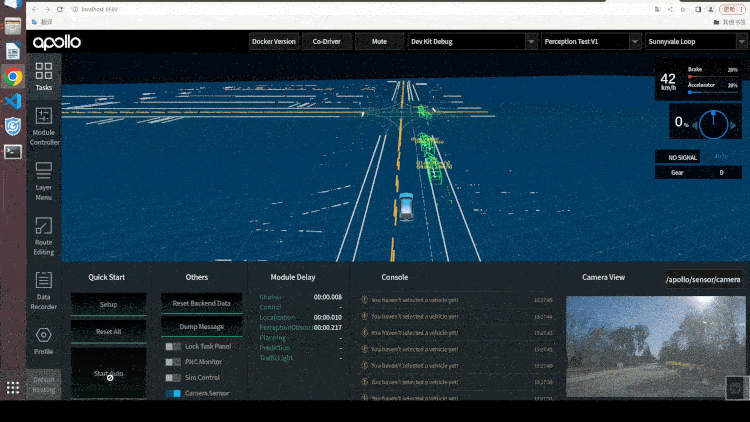
2.6 总结
以上就是本次正式版本的主要内容,欢迎大家 fork 体验。未来,我们将持续更新丰富模型库和预训练模型,持续优化模型在端侧的量化压缩部署,提供更详细的开发文档以及更简洁的 API,为社区带来更好用的 3D 感知开发套件。我们也欢迎社区用户参与到 Paddle3D 的建设中,不断完善 Paddle3D。
NGC 飞桨容器介绍
如果您希望体验 PaddleNLP 的新特性,欢迎使用 NGC 飞桨容器。NVIDIA 与百度飞桨联合开发了 NGC 飞桨容器,将最新版本的飞桨与最新的NVIDIA的软件栈(如CUDA)进行了无缝的集成与性能优化,最大程度的释放飞桨框架在 NVIDIA 最新硬件上的计算能力。这样,用户不仅可以快速开启 AI 应用,专注于创新和应用本身,还能够在 AI 训练和推理任务上获得飞桨+NVIDIA 带来的飞速体验。
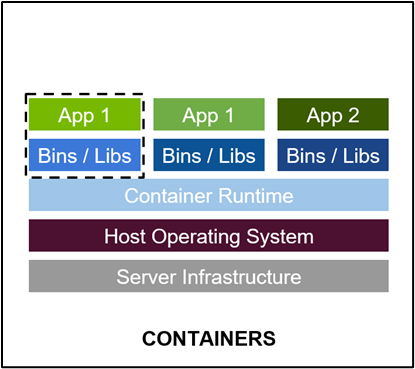
最佳的开发环境搭建工具 - 容器技术
容器其实是一个开箱即用的服务器。极大降低了深度学习开发环境的搭建难度。例如你的开发环境中包含其他依赖进程(redis,MySQL,Ngnix,selenium-hub等等),或者你需要进行跨操作系统级别的迁移
容器镜像方便了开发者的版本化管理
容器镜像是一种易于复现的开发环境载体
容器技术支持多容器同时运行
最好的 PaddlePaddle 容器
NGC 飞桨容器针对 NVIDIA GPU 加速进行了优化,并包含一组经过验证的库,可启用和优化 NVIDIA GPU 性能。此容器还可能包含对 PaddlePaddle 源代码的修改,以最大限度地提高性能和兼容性。此容器还包含用于加速 ETL (DALI, RAPIDS),、训练(cuDNN, NCCL)和推理(TensorRT)工作负载的软件。
PaddlePaddle 容器具有以下优点:
适配最新版本的 NVIDIA 软件栈(例如最新版本CUDA),更多功能,更高性能
更新的 Ubuntu 操作系统,更好的软件兼容性
按月更新
满足 NVIDIA NGC 开发及验证规范,质量管理
通过飞桨官网快速获取
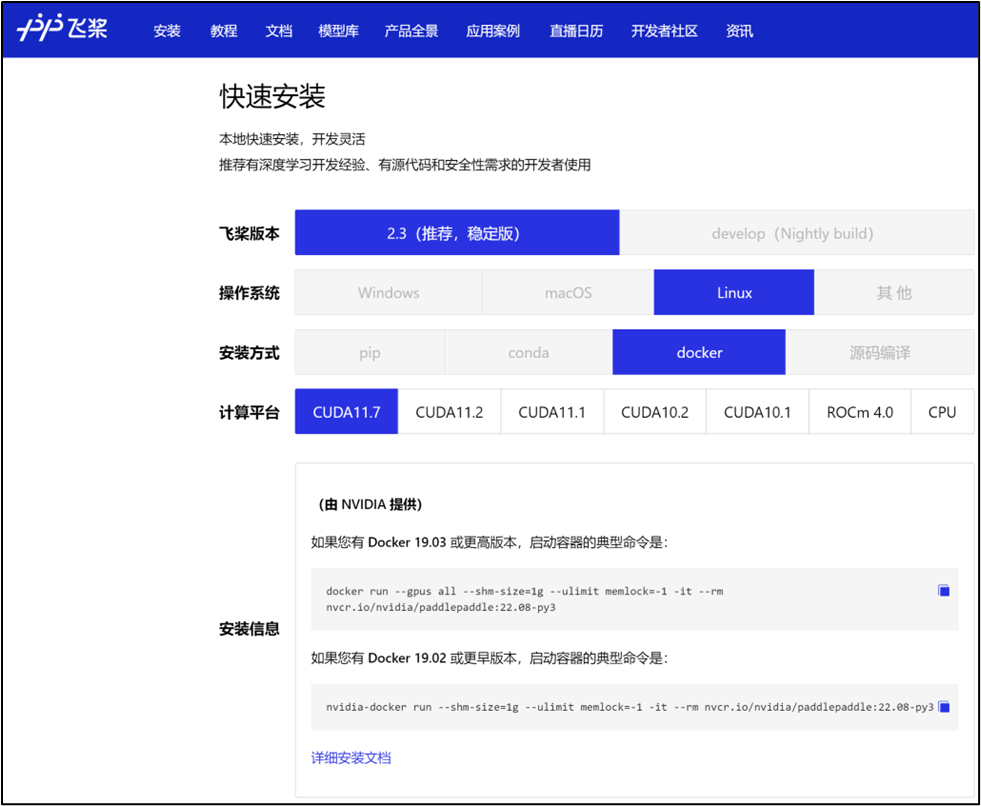
环境准备
使用 NGC 飞桨容器需要主机系统(Linux)安装以下内容:
Docker 引擎
NVIDIA GPU 驱动程序
NVIDIA 容器工具包
有关支持的版本,请参阅 NVIDIA 框架容器支持矩阵 和 NVIDIA 容器工具包文档。
不需要其他安装、编译或依赖管理。无需安装 NVIDIA CUDA Toolkit。
NGC 飞桨容器正式安装:
要运行容器,请按照 NVIDIA Containers For Deep Learning Frameworks User’s Guide 中 Running A Container 一章中的说明发出适当的命令,并指定注册表、存储库和标签。有关使用 NGC 的更多信息,请参阅 NGC 容器用户指南。如果您有 Docker 19.03 或更高版本,启动容器的典型命令是:
docker run --gpus all --shm-size=1g --ulimit memlock=-1 -it --rmnvcr.io/nvidia/paddlepaddle:22.08-py3
*详细安装介绍 《NGC 飞桨容器安装指南》
https://www.paddlepaddle.org.cn/documentation/docs/zh/install/install_NGC_PaddlePaddle_ch.html
*详细产品介绍视频
【飞桨开发者说|NGC飞桨容器全新上线 NVIDIA产品专家全面解读】
https://www.bilibili.com/video/BV16B4y1V7ue?share_source=copy_web&vd_source=266ac44430b3656de0c2f4e58b4daf82
飞桨与 NVIDIA NGC 合作介绍
NVIDIA 非常重视中国市场,特别关注中国的生态伙伴,而当前飞桨拥有超过 535 万的开发者。在过去五年里我们紧密合作,深度融合,做了大量适配工作,如下图所示。

今年,我们将飞桨列为 NVIDIA 全球前三的深度学习框架合作伙伴。我们在中国已经设立了专门的工程团队支持,赋能飞桨生态。
为了让更多的开发者能用上基于 NVIDIA 最新的高性能硬件和软件栈。当前,我们正在进行全新一代 NVIDIA GPU H100 的适配工作,以及提高飞桨对 CUDA Operation API 的使用率,让飞桨的开发者拥有优秀的用户体验及极致性能。
以上的各种适配,仅仅是让飞桨的开发者拥有高性能的推理训练成为可能。但是,这些离行业开发者还很远,门槛还很高,难度还很大。
为此,我们将刚刚这些集成和优化工作,整合到三大产品线中。其中 NGC 飞桨容器最为闪亮。
NVIDIA NGC Container – 最佳的飞桨开发环境,集成最新的 NVIDIA 工具包(例如 CUDA)

点击 “阅读原文” 或扫描下方海报二维码,即可免费注册 GTC23,在 3 月 24 日 听 OpenAI 联合创始人与 NVIDIA 创始人的炉边谈话,将由 NVIDIA 专家主持,配中文讲解和实时答疑,一起看 AI 的现状和未来!

