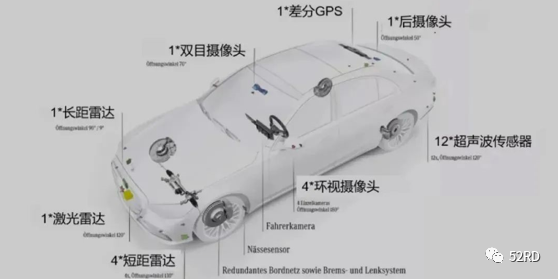
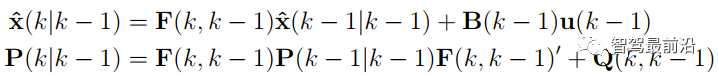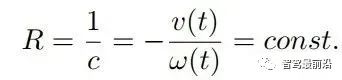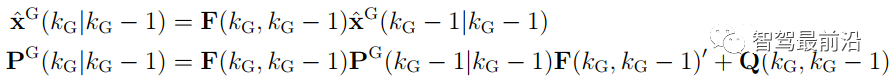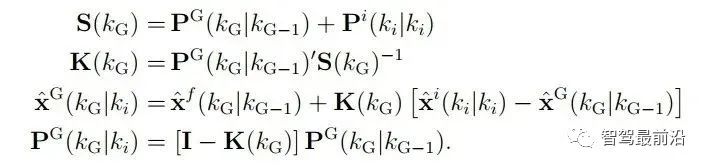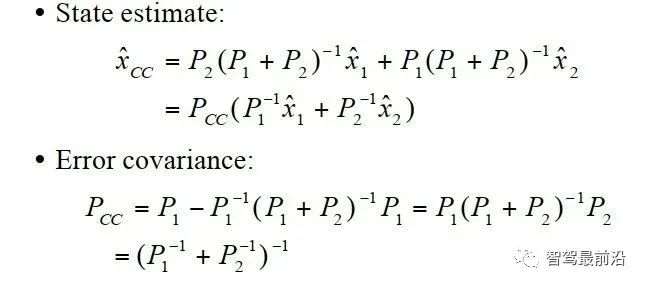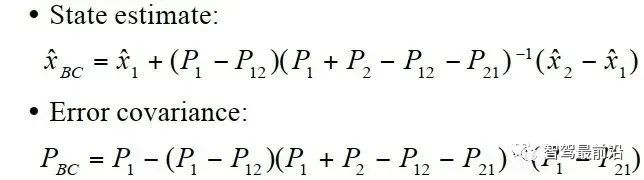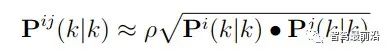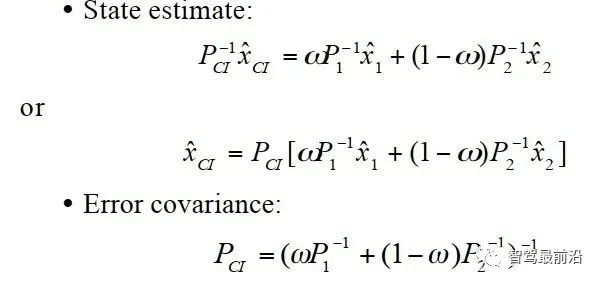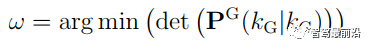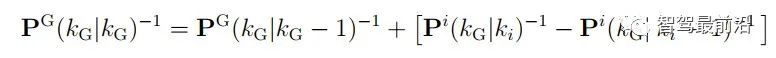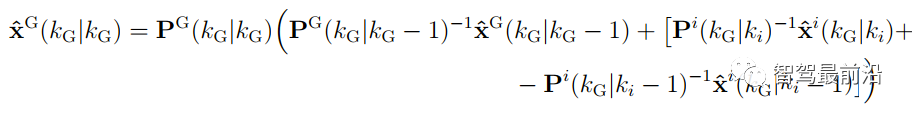本文转 载自知乎@Minne
ADAS系统是一种高自动化的软件应用,对系统的鲁棒性与可靠性要求很高,单一传感器往往存在一定限制,此时便需要多传感器融合。多传感器融合会带来如下收益:
某一传感器出现错误/失效时可以使用另一传感器进行补偿。 在论文《A Review of Data Fusion Techniques》中对融合技术分类中对融合分成以下三类,可见与上面预期收益是对应的: 协作型:多个输入可以组成远比原始信息更复杂的信息。 冗余型:两个或多个输入提供同一个目标信息用于增强可信度。 互补型:输入为同一场景的不同部分用于形成完整的全局信息。
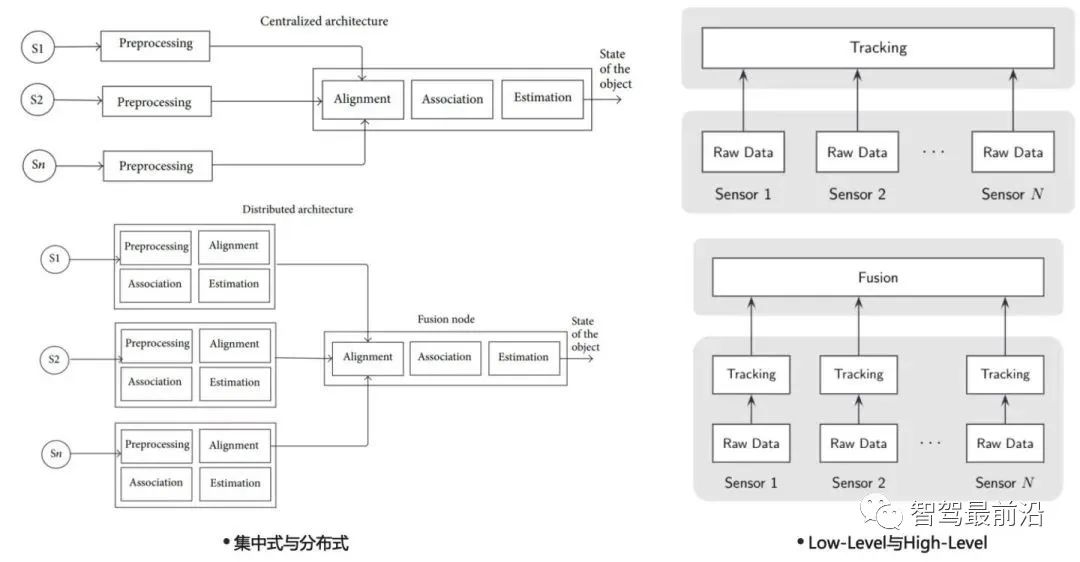
如下图为不同论文介绍的融合架构,虽命名方式有所不同,但基本可以分为以下两类:
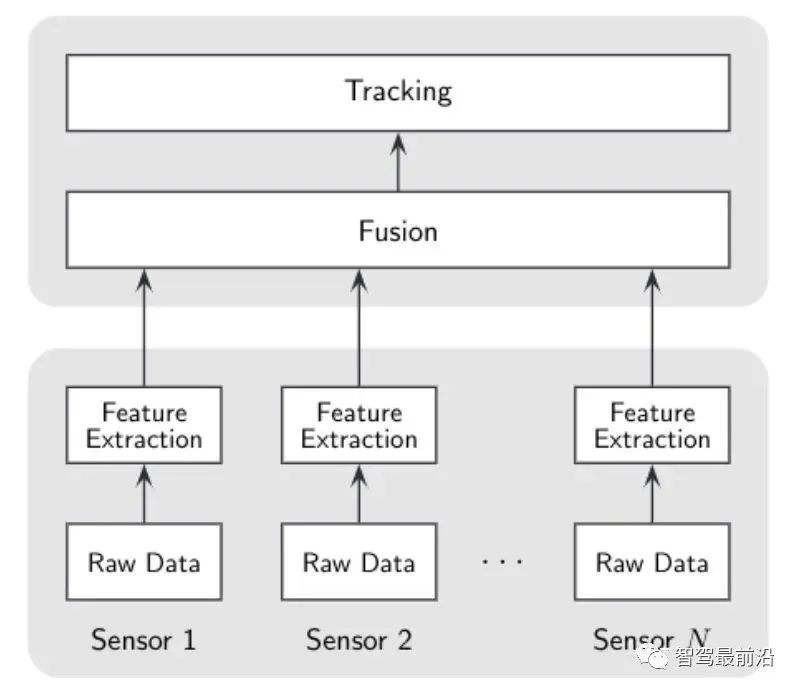
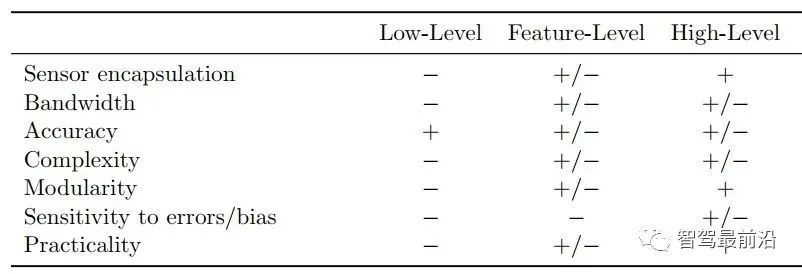
后融合:分布式架构/high-level融合架构。 前融合的中心思想是将所有传感器的原始信息(点云/图像)全都传给中心融合模块,集中在融合模块做跟踪、关联与估计。前融合可以使用深度学习训练网络来实现,也可以对raw data进行关联与融合来跟踪。后者对时间的同步性有较高的要求,否则会影响关联的准确性。 后融合的中心思想是每个传感器使用其内部的滤波与跟踪算法,融合模块做的就是对多个传感器的滤波结果有效的结合起来。由于每个传感器输出已经为目标/track,因此此种融合也可以称为目标级别/track级别融合。 当然我们也可以选择一种折中的方法,称为feature-level。中心思想为从raw data中提取特征信息后送入融合模块进行跟踪融合。比如我们可以提取目标的轮廓信息进行扩展目标跟踪。主要缺点就是:接口不容易定义,不同传感器可能提取的特征有差异,在有新增传感器的情况下可能造成融合框架失效。 下图为low-level、feature-level与high-level三种融合架构的优缺点对比: 当前业界主要采用的融合框架仍为后融合框架。Tier1一般不会放弃后融合架构,因为在商业上来说后融合可以即插即用,单个产品可以卖给主机厂让他们采购别的传感器做拼接,主要还是得益于这个架构的方便落地以及良好的可扩展性。主机厂则一般会在基于后融合框架的系统稳定后,逐步向前融合探索,拿到更多的信息以提升精度。 大大增强系统鲁棒性,如降低单camera传感器的漏检率/单Radar传感器的虚警率;对传感器模块失效可容错等。 如上可知,后融合架构的输入为radar与camera跟踪滤波后的目标级别track信息,输出为融合模块维护的全局track。那全局track中一般包含哪些信息,不同公司有不同的接口设计。
接口 描述 id sensor name polygon 目标点云 track信息 track_id track id tracking_time 跟踪时间 latest_tracked_time 最近一个更新的时间戳 motion 信息 motion_state "UNKNOWN = 0, center 车中心点坐标 center_uncertainty 位置不确定度 anchor_point 锚点 velocity 速度 velocity_uncertainty 速度不确定度 velocity_converged 是否收敛的flag velocity_confidence 收敛可信度 acceleration 三方向加速度 acceleration_uncertainty 加速度不确定度 direction 方向矢量 theta 朝向角 theta_variance 朝向角方差 drops 最多100帧的历史轨迹 feature 信息 size 长宽高 size_variance 长宽高不确定度 type "UNKNOWN = 0, type_probs 每个类别的概率 sub_type "UNKNOWN = 0, sub_type_probs 每个细分类别的概率 confidence 存在概率 其他flag b_cipv obj是否为CIPV car_light "brake_visible = 0.0f
4.1 无记忆策略与有记忆策略
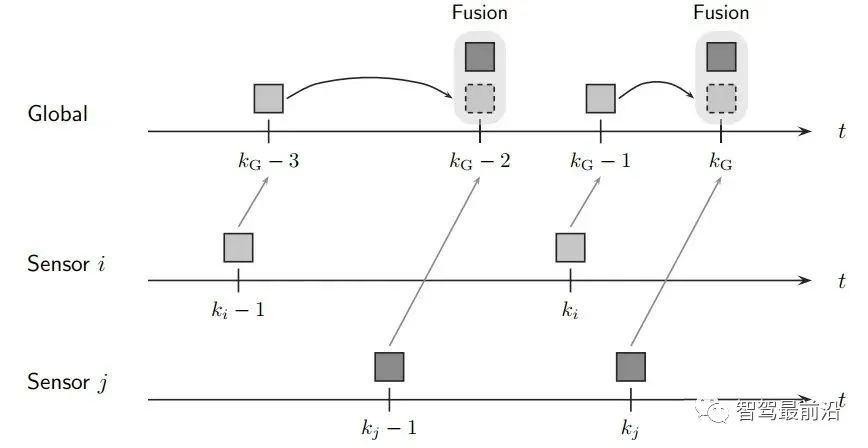
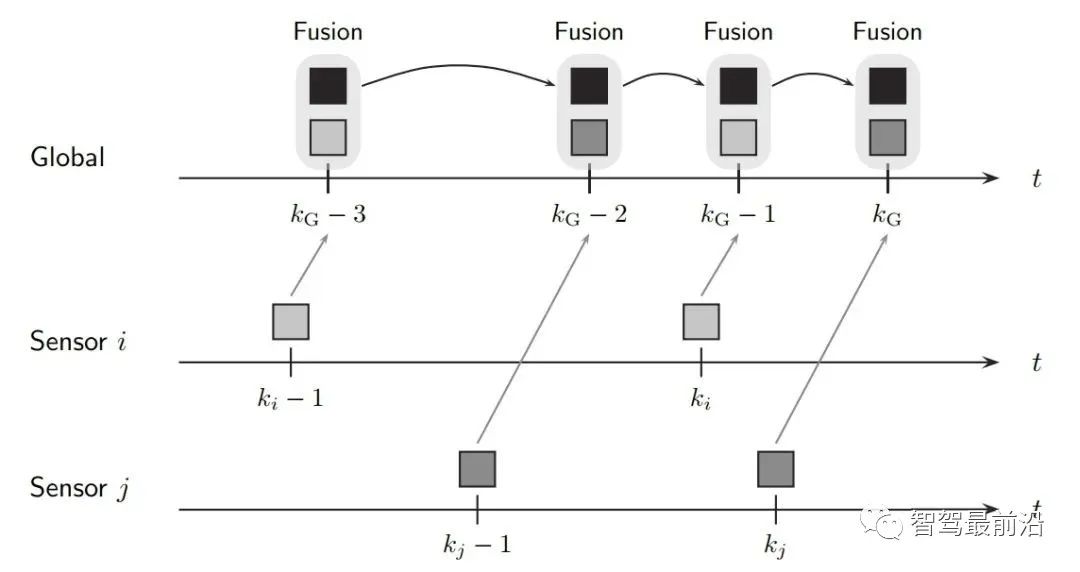
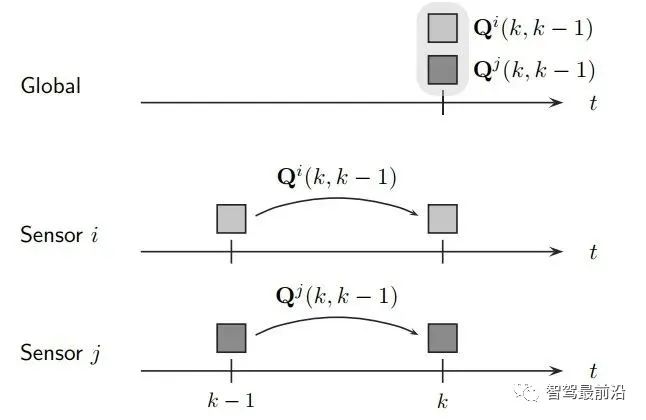
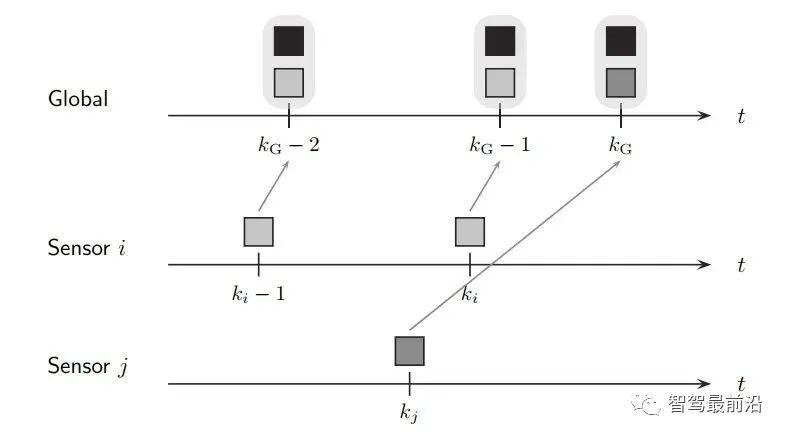
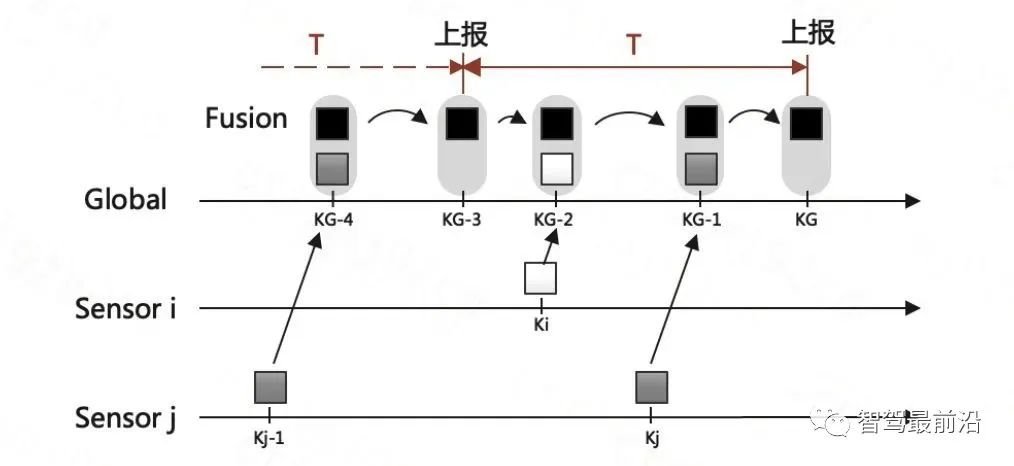
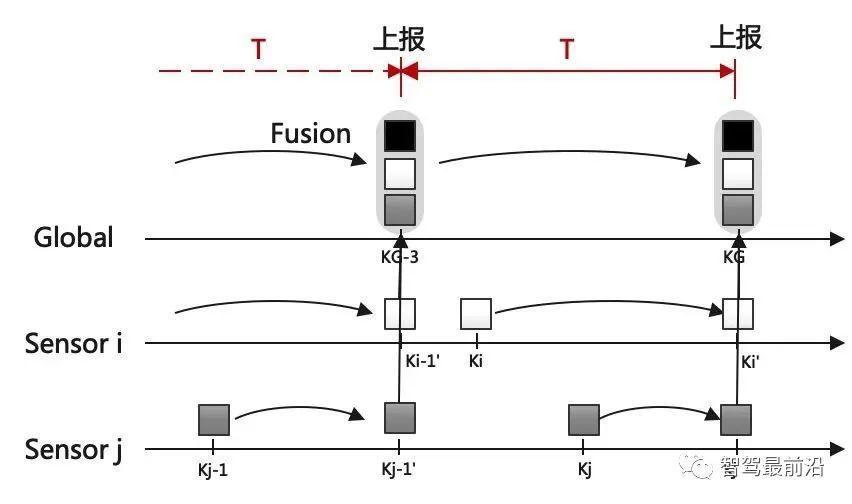
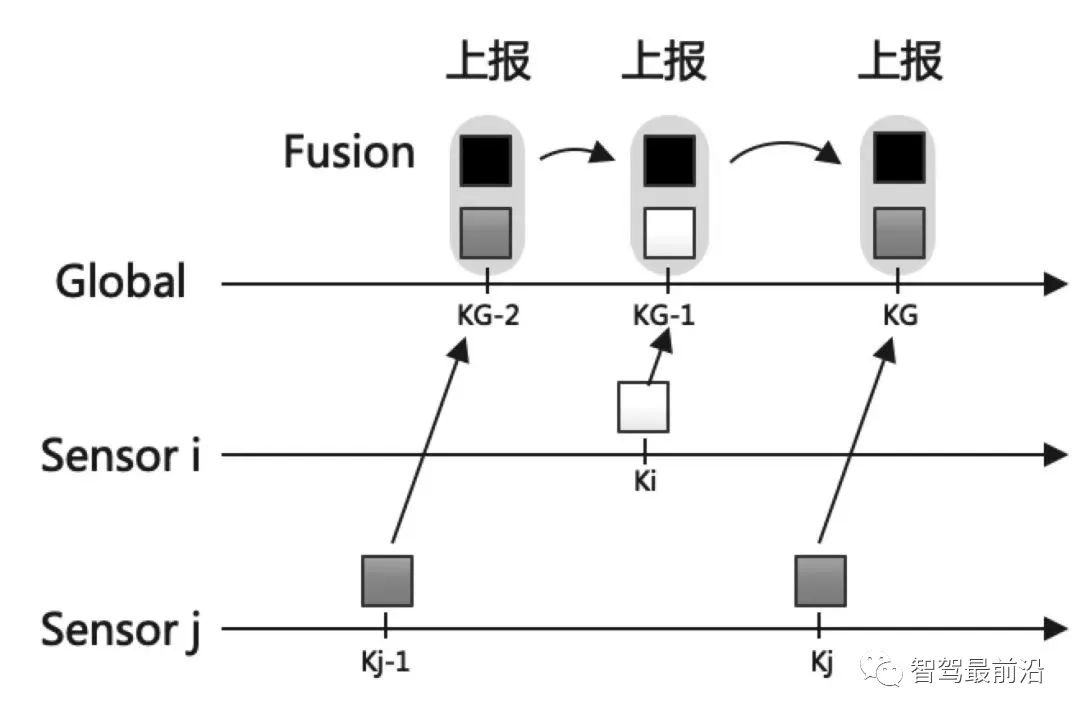
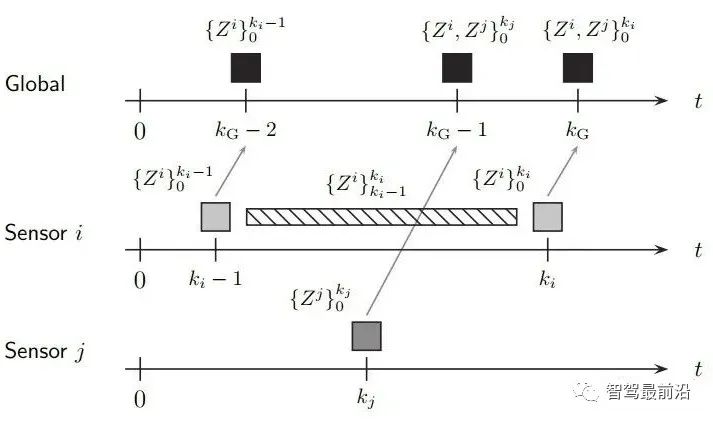
既然融合端要输出全局track,那如何创建与维护它呢,一般有两种融合策略: 如下图为无记忆的融合策略,此框架中,不保留全局track的信息,传感器级别的数据在预设定的融合周期时进行融合。 融合端在kG-3时刻sensor i在ki-1时刻上报数据时,先不进行融合,而将这部分数据存储下来,在KG-2时刻收到sensor j上报的数据时,再进行融合生成全局track。自然kG-3时刻收到的sensor i的数据需要预测到kG-2时刻。如果有多个传感器,那就依次融合。因为在每个融合周期,全局track都是新生成的,和上一融合周期的全局track没有关系,所以此策略叫无记忆的融合策略。 如下图为有记忆的融合策略,此框架保留全局track的信息,在传感器数据来时,对全局track进行预测后马上融合传感器数据。 融合端在kG-3时刻sensor i在ki-1时刻上报数据时,立刻就进行融合了。而后将全局track数据进行预测,在kG-2时刻sensor j的数据来了,再次进行融合,以此类推。与无记忆策略相比,在于全局track在创建后进行保留维护。此策略灵活性较强,具有“即插即用”的优势,因为不同传感器数据之前被隔离开了,传感器数据没有直接接触,都是间接通过全局track进行接触,所以添加与移除某一帧传感器的数据不会对融合端造成较大影响。 当前使用这两种策略的厂商都有,Valeo一篇论文明确说明了他们使用的是无记忆融合策略,Apollo、BMW、huawei等公司使用的是有记忆的融合策略。 接下来主要介绍有记忆的融合策略,虽然这种策略使用起来不错,但是会出现两个问题,如下: 相关性问题主要有两种:1.过程噪声相关性。2.历史信息相关性。 过程噪声相关性:一般融合都采用卡尔曼滤波框架进行预测和更新,而一次卡尔曼滤波流程,添加过程噪声次数应为一次,而实际过程中,如果两个sensor观测到同一个物体,则这个物体在不同sensor中均加过一次过程噪声,也就是两次Qi与Qj,这是不对的。为了解决这种情况,一般需要将两个sensor之间的交叉方差计算出来然后减去。 历史信息相关性:如下图所示在Ki-1时间时,sensori的测量信息第一次被更新在全局航迹中,此时全局航迹包含sensori从0时刻到Ki-1时刻所有的信息了。到了Ki时刻,sensori的测量又来了,此时测量含有0时刻到Ki时刻的所有信息,如果全局航迹直接使用这部分测量进行更新,相当于又一次融了一次0到Ki-1时刻的信息,实际需要的仅仅是Ki-1到Ki时刻的信息。 失序问题产生的原因在于测量数据可能存在延迟处理时间和通信延迟。旧数据进入新目标了,就卷起来了,引入了错误信息。如下图所示,全局track应该融合kj然后融合ki,但由于通讯延迟,变成了先融合ki再融合kj,这就出现了错误。 框架层面:可以采用循环周期策略 + 预测传感器数据到同一节点。(下面介绍) 4.2 循环周期策略与触发式策略 在传感器端将信息上报给融合端后,那融合端如何将融合后的结果上报给后续模块呢,一般有两种策略: 循环周期策略是根据传感器的上报周期以及融合处理数据时间合理制定融合应该的上报周期,比如上报周期就是60ms,那融合就每60ms发一次融合数据,风雨无阻。 循环周期策略有两种实现方式,在传感器上报到融合端后,就马上进行融合,只不过不上报,最后在对应时间周期到了时候再进行上报。如下图,在KG-3时刻上报后,Ki时刻sensor i上报信息,全局track进行预测到KG-2时刻进行融合更新,在Kj时刻sensor j上报信息,全局track预测到KG-1时刻进行融合更新,最后预测到KG时刻进行上报。 相比与上一种方式对全局track进行操作的方式,第二种方式则对融合周期内的传感器端结果预测到上报节点,全局track在对应时刻进行分别融合更新。如下图,KG-1时刻进行融合结果上报后,对Ki时刻的sensor i数据预测到KG时刻,Kj时刻的sensor j数据预测到KG时刻,全局track 预测到KG时刻,使用预测后的传感器数据进行两次关联与更新。此方法不会出现失序问题。 触发式策略是每次传感器来,就做一次融合,而后将融合后的结果上报。所谓触发就是融合上报是被传感器上报数据所触发,故得到此名字。 Apollo使用的是一种触发式策略,在Apollo 7.0中其选择了一个主传感器Lidar,只有在Lidar信息输入后,融合端在融合后才会上报。这样在传感器均正常工作的情况下,融合的上报周期和Lidar周期相同。 相比与循环周期策略,触发式策略更加灵活,容易处理,但是在某一传感器挂掉时候,融合对应的也挂掉了,这并不符合量产的系统稳定性需求。而循环周期测量的两种方法,精度会有差别(不同的预测手段导致),后者则会在问题回归定位时方便,可直接采用帧号对齐。 一般情况下,有记忆策略与循环周期策略/触发式策略均可配套使用,但是无记忆策略通常与循环周期策略配套使用。原因可以理解,触发式策略在任意传感器来时候进行融合而后上报,无记忆策略由于不维护全局track,需要等待两个传感器数据到齐后进行融合,二者结合不是很合适。 如下图为基本RC后融合系统流程图,接下来将介绍各个模块:
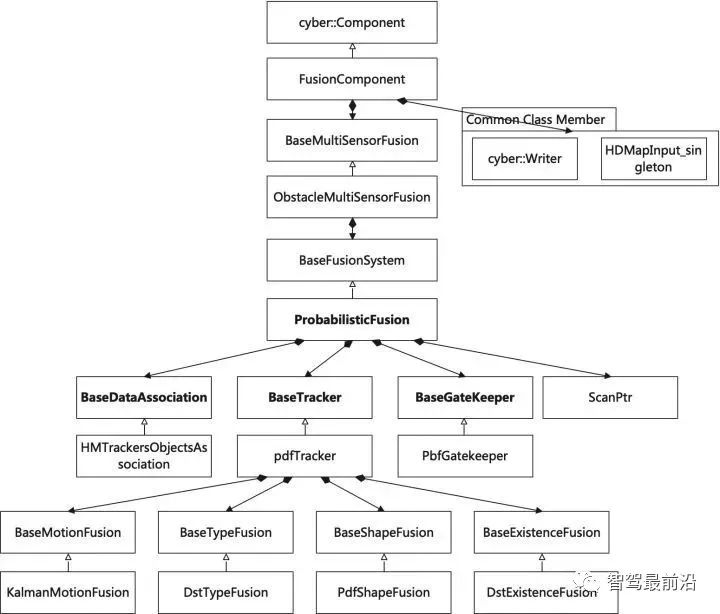
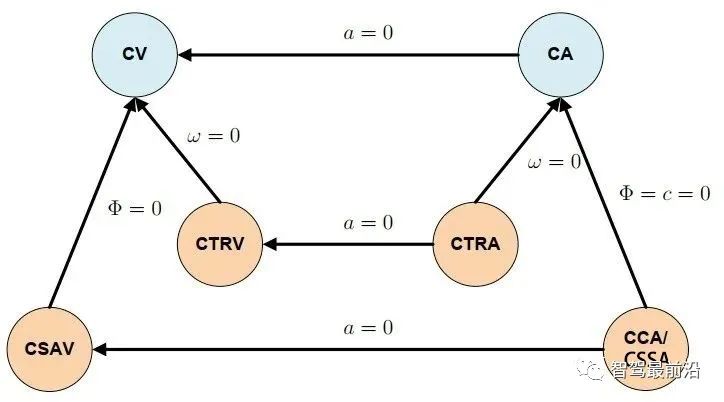
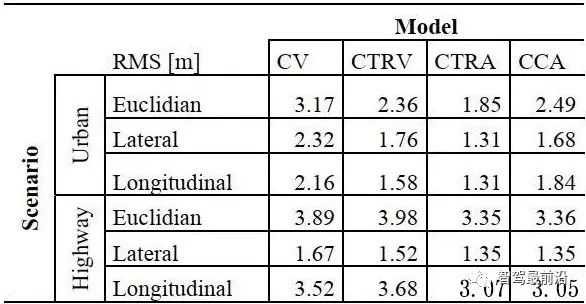
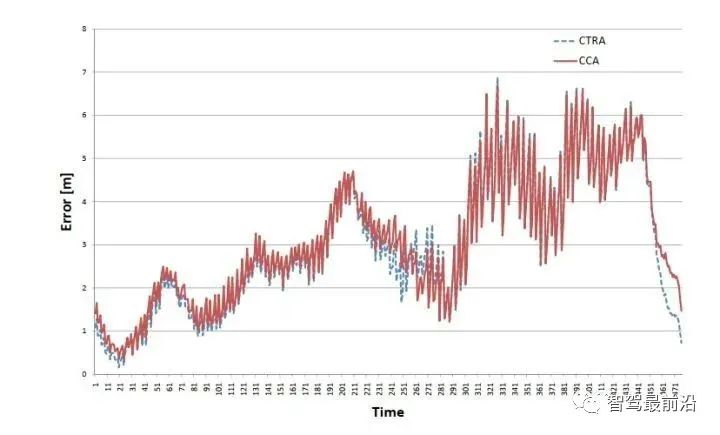
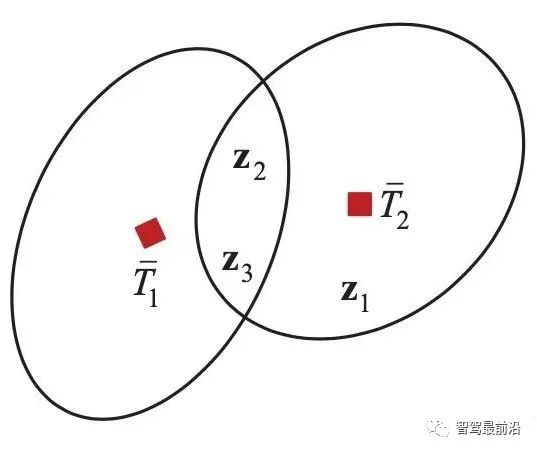
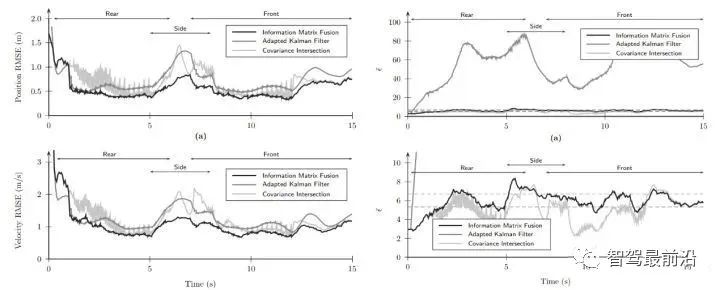
如下图为Apollo融合部分代码UML图,代码层序清晰,BaseDataAssociation、BaseTracker、BaseGateKeeper三部分分别对应数据关联、track预测更新以及特征融合、航迹管理。 在进行关联操作之前,需要将信息统一到相同的坐标系以及时间节点,也就是时空间转换。 因为后融合是目标级别融合,输入以及输出都是点。但是自车以及目标车都是有size的,此时需要统一接口定义。纵向距离和横向距离究竟指的是自车的什么位置到目标车的什么位置的距离,比如究竟是自车的几何中心/前保险杠到目标车的几何中心/后轴中心的距离。 传感器端应定义上报给融合端的距离为传感器安装位置到目标车哪个位置的距离,例如可定义: camera上报横纵向距离为camera安装位置到目标车几何中心的位置。 radar上报横纵向距离为radar安装位置到目标车车后轴中心的位置。 因为不同传感器的安装位置不同,应将其统一到车体坐标系中,一般为自车几何中心。一般会有标定矩阵,乘上去就好,公式如下: 时间对齐容易理解,fusion与measure必须在同一时间下,如果差了一个△t,就是用卡尔曼滤波中的运动学外推即可。CV模型比较合适,当然CTRV也可以,那就需要EKF了。 一般这部分位移差都会补上去,但是也有公司-Valeo在论文中认为如果△t比较小不用补也可以,因为这补偿的微小位移差会被原始测量噪声所淹没。 5.2 航迹预测 对于有记忆的融合策略,需要维护全局track,在有传感器测量上报后,需要从上一时间节点预测到此时时间节点,而后进行关联,选择到测量后进行更新。其实就是一个关联模块插入到滤波过程中。常见的预测模型如下: CV:匀速模型。假设目标车直行,且速度不变。线性模型。 CA:匀加速度模型。假设目标车直行,且加速度不变。线性模型。 CTRV:恒定速度与转速模型。假设目标车转弯,且速度以及角加速度不变。非线性模型。 CTRA:恒定加速度与加速度模型。假设目标车转弯,且加速度以及角加速度不变。非线性模型。 由于CTRV以及CTRA模型认为速度v与角速度w是没有相关性,所以即使速度为0,加速度也会改变yaw角,相当于原地转圈,这是不合常理的。 为了解决上述问题,有CCV以及CCA模型。这两个模型假定运动的曲率半径一定,曲率半径的计算公式如下,可见曲率半径变量补充速度v与角速度w的相关性。可用c = 1/R放到变量中参与滤波。 在论文《Comparison and Evaluation of Advanced Motion Models for Vehicle Tracking》中作者对比了如上不同的模型(更新全都用的UKF),得到精度对比表如下: CTRV与CTRA模型在角速度w>2度/s时候相比CV与CA模型表现提升。 CCA与CTRA模型性能基本无提升,原因在于非线性程度高,计算误差大。下图为二者在同一转弯场景误差对比。 CV模型:可适合绝大部分场景,计算复杂度低且效果良好,性价比高。但对于stop&go场景会出现问题,尤其是急刹,这会影响功能。 CA模型:对加速度的准确性需求上升,可解决刹车等场景的问题。在加速度不出问题情况下,直行用此模型就可以。缺点就是对弯道场景有局限性,损失一定精度。 CTRV:对航向角准确性需求上升,直行场景如果航向角错误/横向速度错误,可能导致预测到其他车道,导致功能性问题。 CA+CT+IMM算法:综合二者优点,保证直行性能基础上可在在弯道获得收益,但具有滞后性。 5.3 数据关联 每个测量目标仅属于一个track,如果它不属于任何一个track,那它就是虚警。 每个track如果可和多个测量相关联,那只有一个是正确的,其他都是错误的。 以上两个假设将关联问题简化,关联问题变为一对一的最优问题。 熟悉多目标跟踪的大家都知道,相比于单目标跟踪,其会出现一个复杂的问题就是分配问题,如下图所示,两个global track T1与T2,落入T1关联门限的测量有Z2、Z3,落入T2关联门限的测量有Z1、Z2和Z3,不难计算他们有10种关联的可能,而只有一种是正确的。 根据经验可以知道,距离自车40m的全局track不能与距离自车100m的测量关联上,所以就没必要计算这二者的相似度而后进入分配算法。步骤1设定门限的目的便是在此,对于不在门限范围内的测量,系统将不认为其应该与对应全局track关联上,二者相似度可设为极大值,不参与后续分配。这样做优点可以降低算法复杂度,提升效率。 过大的门限会在杂波较多时候放入过多目标,造成算力提升并提升关联错误的概率。 过小的门限会使得正确的关联目标被卡在门限外面,会导致关联不上的情况。 门限选取一般根据全局track与测量的距离差、速度差进行设定,同时根据传感器特性进行调整,一般基本思想如下: 全局track距离自车越远距离门限应该放的越大。由于camera测距不准,但其角度测量准确,所以可设定对应角度门限,如果满足角度门限,可对camera测量放大距离门限。 速度门限也应随着全局track距离自车的距离进行变化,同时考虑camera存在速度收敛的情况,可根据跟踪camera测量的帧数适当放大速度门限, 关于计算全局track与门限内测量的相似度,其用途就是构建一个track与测量的相似度矩阵,有很多种方法去计算,基本思想就是我们希望track与测量的state差距越小,相似度越大。以下是一些计算方法: 对X、Y、Vx、Vy的欧式/马氏距离差进行一定规则的权重加和。 根据高斯分布等特性,利用卡方分布查表获得相似度。(Apollo) 关于分配算法,其实此数据关联就是个二分图的最大匹配问题。 关于find best方法其实就是对相似度矩阵进行一次排序,安装相似度从大到小进行分配。相比原始的NN算法,其不会因为obj排序不同而导致不同的关联结果。 根据一些仿真结果,基本结论是拍卖算法时间复杂度相对较小,但存在大颗粒度问题,可能达不到全局最优。匈牙利匹配存在不收敛情况,稳定性存疑。 在实际工程中,数据关联模块如果按照上述流程,同样会出现很多稳定性问题。我们希望的系统应该是有稳定的关联,不会总出现跳变,所以需要一定的逻辑来维持其关联的稳定性。可以采用如下方式: 当一个track和对应的RC关联超过100帧就将其直接关联起来作为强绑定逻辑。 使用CJPDA算法+alpha滤波跟踪落入门限中测量的关联概率,满足条件再关联切换,可作为弱绑定逻辑。 5.4 航迹更新 经过前面数据关联模块,全局track已经和R/C的测量关联上,如何使用二者的state以及cov矫正全局track的state便是此模块的工作。 Convex Combination 、Covariance Intersection Julier S, Uhlmann J K. General decentralized data fusion with covariance intersection[M]//Handbook of multisensor data fusion. CRC Press, 2017: 339-364. Information Matrix Fusion M. Aeberhard, A. Rauch, M. Rabiega, N. Kaempchen and T. Bertram, "Track-to-track fusion with asynchronous sensors and out-of-sequence tracks using information matrix fusion for advanced driver assistance systems," 2012 IEEE Intelligent Vehicles Symposium, 2012, pp. 1-6, doi: 10.1109/IVS.2012.6232115. 卡尔曼滤波算法是最普遍的方法,将传感器层面上报的track作为输入,但是卡尔曼滤波基于的假设是测量之间彼此独立,但由于传感器层track之间有共同的历史观测 ,测量之间具有相关性了,违反了彼此独立的假设,所以使用KF滤波无法获得无偏估计。
而且Bar-Shalom retrodiction算法被成功用于此算法中去解决失序问题。 A. Novoselsky, S. E. Sklarz and M. Dorfan, "Track to track fusion using out-of-sequence track information," 2007 10th International Conference on Information Fusion, 2007, pp. 1-5, doi: 10.1109/ICIF.2007.4408008. CC算法是一种最简单的融合方法,算法如下。中心思想就是使用协方差做了一次加权。
如果考虑测量之间的相关性,则可对CC算法进行一定的变形,如下:
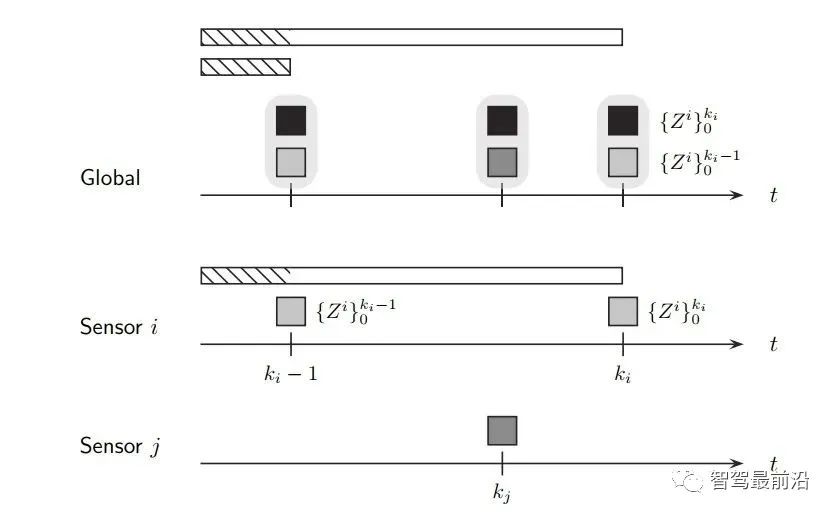
可以看出其需要计算cross-covariance matrix,一般计算方法如下,参数取0.4是一个不错的选择。 CI算法则在考虑了相关性的同时,不需要显示计算cross-covariance matrix,算法流程如下: 论文中提到,此方法融合的协方差矩阵中最大化的保留了测量之间的相关信息。 Information Matrix Fusion方法是BMW公司主要使用的一个方法,其主要可以解决记忆框架的历史相关性问题。如下图所示,在KG-2时刻,global track含有sensor i 的从0到Ki-1时刻的信息,在KG-1时刻,融合Kj时候,在解决掉两传感器的测量噪声相关性之后,global track含有从0到Kj时刻sensor i与sensor j的信息。主要问题就在KG时刻。KG时刻如果再次直接融合Ki传来的数据,就多融合了一遍sensor i在0到Ki-1时刻的信息,而我们真正需要的信息是Ki-1时刻到Ki时刻的协方差信息,所以信息矩阵融合想到的方法就是,减下去就完事了。
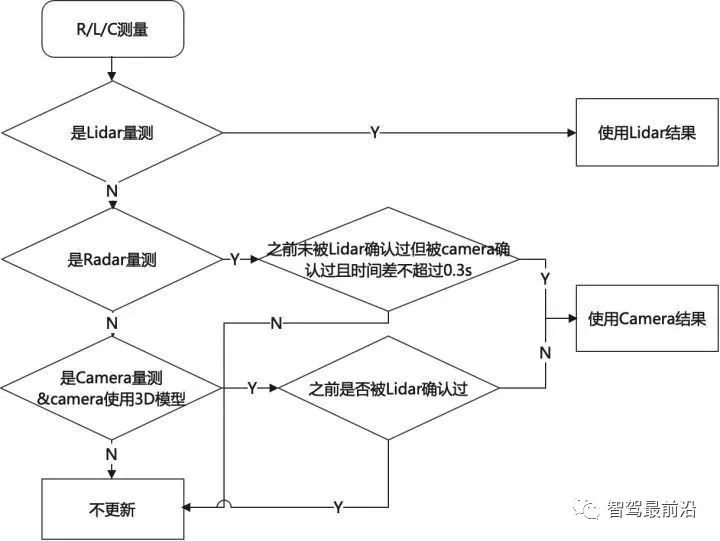
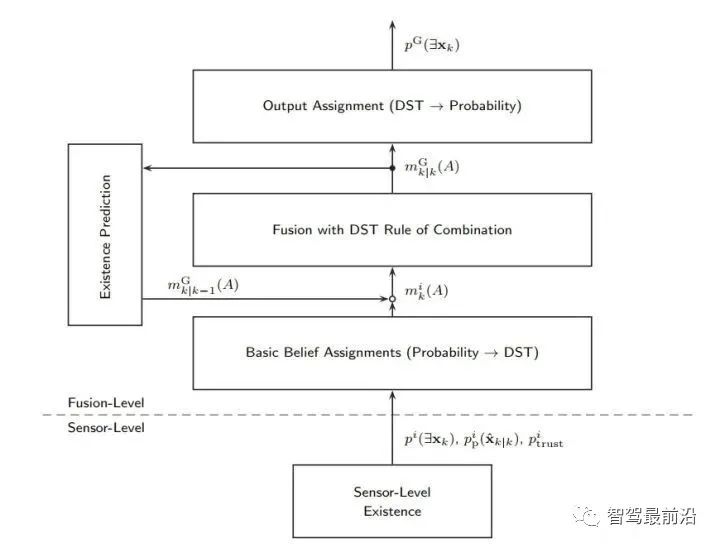
可以看出此方法需要存储上一帧传感器的state以及协方差矩阵,这是一个缺点。 Apollo的方法当前仅使用KF滤波加一些自己的逻辑,比如根据track质量调整了协方差、对主sensor降低协方差、限幅等操作。可以看出其主要保证系统的稳定性与可控性,而非理论最优。 以上的方法其实都是在xy方向上进行的更新,业界在更加信任哪个传感器上也有自己的考量,使用策略调整来调整传感器的协方差,如下: xy方向进行位置更新,纵向信任radar,横向信任camera。 frenet方法进行更新:结合车道线信息,转换到frenet坐标系上,进行更新。此方法会在弯道产生收益。因为传统坐标系可能出现过大弯道更新后踩线或更新到别的车道的情况。但是此方法对车道线质量有依赖。 5.5 特征融合 业界当前对长宽的融合基本都需要Lidar传感器,可分为以下两种: Apollo对于长宽融合采用的策略如下图,可看出Apollo的逻辑是,有lidar就信lidar,没lidar信任使用3D检测模型的camera,radar压根不信任。 在RC融合中,camera上报长宽(高)一般基于3D bounding box的角点进行一定解算后获得。CIPV的长度信息无法保证,一定距离外精度无法保证;radar因其特性,点云稀疏,无法拟合处应有形状特征,上报的长宽相比camera不具备优势,一般根据其类别结果放一个默认值上去。 融合端可以camera上报的长宽为主,在此基础上抑制波动、尽量提升精度。融合理论上相比camera有更准确的距离信息以及类别信息,若camera解算size时与其本身估计的距离相关(小孔成像远离),则可根据融合端更准确的距离做一定矫正;根据类别信息做合理性判别。 前面关于state、类别、长宽的估计的用途都很好理解。那存在概率是用来干什么的呢,有什么用呢?这是由于在实际系统中,传感器上报的目标很可能是虚警(false positive),融合端需要有一个概率来确定这个目标是否真的存在,在概存在概率低于某一个阈值时系统可以将这个目标滤除,以防功能端误刹、CIPV误选择。 RC融合中,radar由于其传感器特性(多径、镜像、受到护栏影响)很容易上报虚警,虽然radar内部有算法会对虚警进行抑制,但无法解决所有,这时候融合可根据camera的信息进行进一步抑制,这也是融合存在的价值之一。 上述可知:存在概率与航迹管理模块强相关。同时可以与功能端共同建立一套基于概率的控制系统。 融合端应该得到RC分别上报的存在概率后进行融合。而传感器端上报的存在概率是通过他们跟踪过程的质量算出来,一般计算方法一般有如下两种: D. Musicki, R. Evans and S. Stankovic, "Integrated probabilistic data association," in IEEE Transactions on Automatic Control, vol. 39, no. 6, pp. 1237-1241, June 1994, doi: 10.1109/9.293185. M. Aeberhard, S. Paul, N. Kaempchen and T. Bertram, "Object existence probability fusion using dempster-shafer theory in a high-level sensor data fusion architecture," 2011 IEEE Intelligent Vehicles Symposium (IV), 2011, pp. 770-775, doi: 10.1109/IVS.2011.5940430. 其实这两种方法通过推导殊途同归,只不过在建模参数采用的模型相同,计算方法是相同的。BMW的文章通过建模Pp-持续概率、Pb-出生概率、Pd-检测概率以及Pc-杂波概率,对不同的传感器引入不同的建模方式,计算出的存在概率可与以下目标特性有关: 当然我们也可以通过车道线与路边沿约束降低不合理目标的存在概率。 那融合端拿到传感器端的存在概率,采用DS证据理论的方法去融合是业界的主要方法。如下图所示: 我们设定DS的判别空间为[存在、不存在],而后调用DST流程融合即可。Apollo就采用这种方法。 RC融合过程中,由于radar可以检测到被遮挡的目标,然而camera却无法检测到,以上的power set的分配方式会造成被遮挡的存在的目标在使用radar进行融合时候,提升存在概率,而在融合camera时降低存在概率,造成冲突。 为解决上述问题,可以将遮挡信息引入来扩大DS的判别空间,判别空间扩大为[遮挡时存在、未遮挡时存在、不存在],可解决以上问题。BMW采用此种方法。 5.6 航迹管理 融合端在接受到新的、未出现过的测量时,此测量有两种可能,一为新检测到的真实目标,二为虚警。融合端不可能一接收到新测量就开始起始全局track进行跟踪,这样会引入大量的虚警目标,造成误刹等功能性错误。也不能确认很久仍未起始,这样可能会漏报目标,可能会撞上去。当前主要的航迹起始方法包含以下集中: 逻辑法:M/N逻辑。在N帧中如果有M帧观测到该目标就起始。一般为2/3逻辑,3帧中有2帧观测到就起始。 SPRT:建模目标存在的似然函数P0和不存在的似然函数P1,计算二者的比值,超过门限就起始。 IPAD算法:计算目标的存在概率,可以用来做航迹的起始以及终结。主要思想为根据预测状态的位置信息和实际传感器的测量信息计算偏差,动态计算测量落入关联门限的概率,进而迭代增加或减少存在的概率,在概率超过一定阈值时进行起始。由于IPAD本身也包含关联算法,方便与后面数据关联方法结果进行对比。 论文中:在强杂波的环境中,起始效果IPAD>SPRT>M/N 在实际系统中,在传感器性能良好的情况下,M/N方法仍为简单可控且表现不错的方法。 SPRT方法中,Pd、Pf 、alpha、beta等调参复杂,可能出现目标长时间无法删除的情况。调整好参数情况下,与其他的方法差距不大。但是在FOV附近可以通过对FOV附近以及非FOV附近调整设置不同参数,使得在非FOV附近目标正常上报,在FOV附近目标延迟上报等增益。 IPAD法由于存在概率与track的运动状态有关系,对于radar存在持续上报的虚警,如果目标运动状态不稳定,相比N/M方法,能够延缓起始;可以根据加减分方法,灵活调整radar与camera的参数,应用于FOV附近与非FOV区域目标。 所谓merge目标,即为合并单R与单C目标。若radar与camera上报稳定的目标,二者无法在初始时刻在融合端关联上,分成了两个目标进行起始。融合端应该提供在二者生命周期内,若可关联上便将其合并为一个目标的功能。 就算单R目标不上报,当仍需要此功能。若无此功能,单C目标在整个生命周期内便一直无法再与radar目标关联上,会损失精度。 若单R与单C目标关联上,在合并为一个目标的过程中,要防止跳变。不能出现一下子从Camera位置跳到radar那边的情况。 RC融合中,global track可能为RC的融合目标、单R目标、一般情况下,对于单R与单C目标会与融合目标有不同的处理逻辑(透传)。所以一般会对全局track维护一个objSource接口表示目标为何种融合方式,而后根据objSource选择不同的逻辑。 融合端便要维护objSource接口,当单C/单R目标关联上互补传感器后形成RC融合目标后,objSource升级,这可以理解。而我们也应有一定逻辑将track级别降下来,因为RC融合目标在某一个传感器消亡后,将退化为单C/R目标。 若某一帧R/C的测量未出现,便直接将融合目标降级为单传感器目标是欠考量的。传感器上报的测量可能会闪烁,如果使用这种策略会造成objSource不断跳变,从而导致选择逻辑不断切换,影响上报的state。 可以看出系统应维护objSource的稳定。一般业界在某一帧测量没来时不会降级,而是维持融合状态,并在关联模块记录R/C在关联期间未关联上的帧数,而后可以使用逻辑,在合适时候将其降级。 消亡的全局track应将其从维护的track列表删除。因为传感器可能出现闪烁、因为遮挡暂时未上报等情况,不可在全局track某一帧均未关联上RC测量便将其删除。 上报模块为融合与后端的最后模块,可以将其理解为闸门。之前融合端起始跟踪的全局track均会经过此模块来确定是否要报给后端。 上报与不上报与全局track起始和删除是不同的,后者主要是融合端内部自嗨,而前者就属于汇报阶段了。 上报模块是非常重要的,因为融合端信息通过此模块后便要对功能负责。一个合适的上报模块应该会让稳定可靠的目标快速上报,而对于错误/不稳定目标有过滤作用(融合意义所在)。 一般情况此上报模块应有一个参考的数值作为衡量track是否存在且稳定可靠的指标,前文提到的存在概率便是一个合适指标,前提是需要经过合理的建模。仅仅一个数值无法cover所有场景,此时需要一些硬逻辑来识别错误目标延迟上报(问题驱动)。 Valeo在论文中提出过一个全局可信任分数来作为上报模块,其实也就是存在概率,但是有它自己的一套建模方式。 从最底层的工作原理来说,毫米波雷达主要是依靠多普勒效应来感知移动目标。多普勒效应的特性是动态对动态最容易感知,动态对静态较难感知、静态对静态极难感知。这是因为如果前方车辆静止,目标信息容易和地杂波等掺杂在一起,需要一定的算法才能从中分辨出目标。而如果是一个行驶中的汽车,基于其多普勒信息,从而比较好探测到目标。 6.2 毫米波雷达没有高度信息,同时空间分辨率不足 没有高度信息,意味着雷达很难区分横穿马路的路牌和桥下的车;空间分辨率不足,意味着两个距离很近的物体,其回波会被混在一起,很难知道有几个目标。如下为路中央的路牌以及其下的车。 2021.1.25 ES8在沈海高速碰撞护栏边正在放置三角警示牌的行人 然后碰撞边上爆胎的五菱宏光问题 这个场景中五菱宏光车身和护栏挨得很近,并且都是静止状态,这个时候雷达对于这两个目标的区分就得依靠角分辨率来实现了。在较远的距离雷达反射点混在一起,要到很近的距离才能区分护栏和车辆。 如果很难区分,把静态目标错误的识别为车辆,然后进行刹车会严重影响用户体验,甚至增加事故,所以一些雷达公司和自动驾驶公司会选择将静态物体(包括车)过滤掉,来减少误触发的情况。 当前博世、大陆等企业,已经可以通过不同物体RCS反射面积的不同和不同帧之间的反射点的不同来区分路牌、立交桥和车辆。但准确率并不算高。 利用RCS直接进行分类仍是不现实的,因为不同形状、材质的物体RCS都不相同。而即使是同一个物体,不同角度的RCS也不相同,车载场景下变量太多暂时很难以简单通过RCS来确定一个物体的类型。 融合端搭建出一套可使用的系统是较为容易的,而且这套系统还可解决70%的场景,然而如何将70%场景做到90%甚至95%则是困难的,需要大量的路测数据进行调试。
融合需要构建场景的白名单与黑名单,明确融合的能力边界,确定这个边界因什么而被限制,哪些可以随后续升级而放开。而后续升级是应该sensor升级性能还是融合这边进行cover,如果是融合这边cover,对sensor又有哪些依赖,这些都是需要明确的。对于sensor解决不了的场景,融合要有策略进行兜底。 融合应梳理不同场景传感器的性能基线,总结特性并在融合端更好的进行逻辑预埋。传感器特性例子如下: radar对近处目标、行人、truck目标检测能力比较弱。如果目标旁边有路沿,那这个目标存在可信度降低。radar对静止目标检测能力弱,可能检测不到或闪烁。 Cut in场景应该camera比radar更早的识别,因为DL;FOV附近,camera横漂严重;camera对ax测量不准。 对融合架构来说,应该扩展性良好,模块间耦合性低。支持功能的升级扩展与降级裁剪。 而后续测试出来了问题场景,我们应该有方法能确定这个问题是方案类问题还是极端场景问题,做好分类归档。
END.
立讯精密:预计到2030年智能驾驶在国内市场将是千亿规模
*免责声明:本文由作者原创,52RD转载是为分享该信息或观点,不能代表对观点的支持,如果有任何异议,欢迎联系我们。