



前言:
Nvidia 是2月底网络攻击的受害者,他们被黑客入侵并丢失了大量数据。这次黑客攻击不仅对英伟达来说是一场灾难,对所有芯片公司和所有“西方”国家的国家安全来说都是一场灾难。
下载链接:
国产服务器CPU,突围可能性有多大?
GPU技术专题汇总
1、AI芯片:下一代计算革命基石
2、从自主可控渗透国产GPU提升市场规模
3、从全球领先企业看GPU 发展方向
4、人工智能核“芯”,GPU迎来发展良机
5、AI芯片的竞争:GPU、ASIC和FPGA
6、自动驾驶芯片:GPU的现在和ASIC的未来
7、GPU制霸AI数据中心市场
NVIDIA GPU架构白皮书
1、NVIDIA A100 Tensor Core GPU技术白皮书
2、NVIDIA Kepler GK110-GK210架构白皮书
3、NVIDIA Kepler GK110-GK210架构白皮书
4、NVIDIA Kepler GK110架构白皮书
5、NVIDIA Tesla P100技术白皮书
6、NVIDIA Tesla V100 GPU架构白皮书
7、英伟达Turing GPU 架构白皮书
据介绍,被黑的数据包括英伟达下一代GPU Hopper 和 Ada 的详细规格和模拟数据。Hopper现在正在发货,并由 Nvidia 在 GTC 上发布。规格与这次泄漏完全匹配,但以 Ada Lovelace 命名的 Ada 仍然需要几个月的时间。
Ada,下一代客户端和视频专业 GPU 将是本文的主题。基于泄露的规范和模拟,SemiAnalysis 和Locuza联手分析了各种芯片的架构、裸片尺寸,并对 GPU ASIC 进行成本分析。
SemiAnalysis 和Locuza没有从 LAPSUS$ hack下载任何泄露的文件,但许多人在网上分享了摘录。
根据泄漏的这些摘录 , 我们能够为 Nvidia 的下一代 Ada Lovelace GPU 阵容提取以下规格,并将它们与当前一代 Ampere GPU 阵容进行比较。
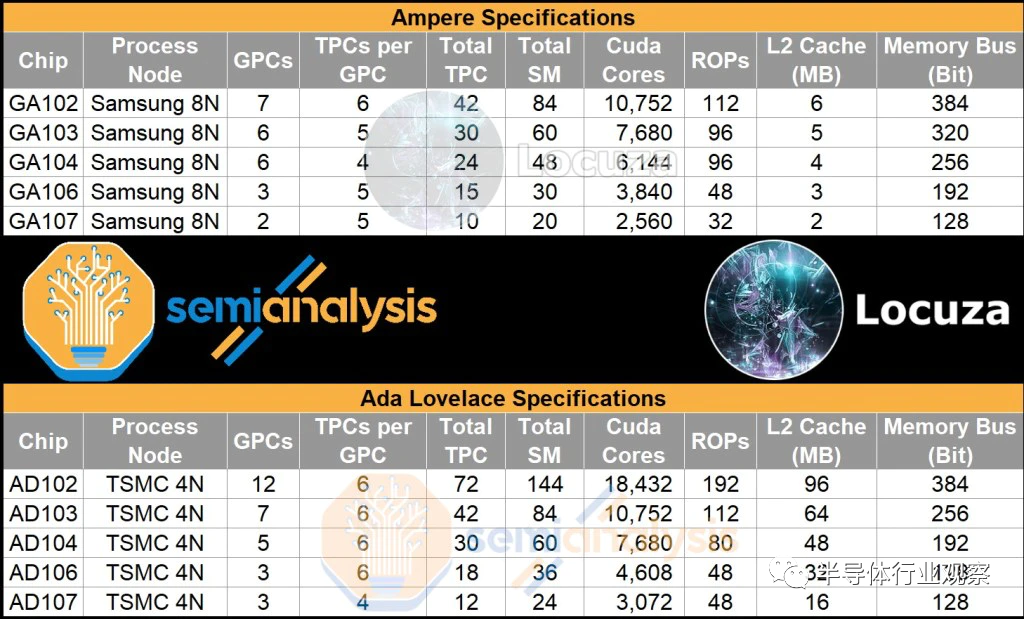
本文的其余部分将展示每个芯片的框图、架构分析、估计的裸片尺寸、我们如何得出这些裸片尺寸,以及一些成本和定位分析。
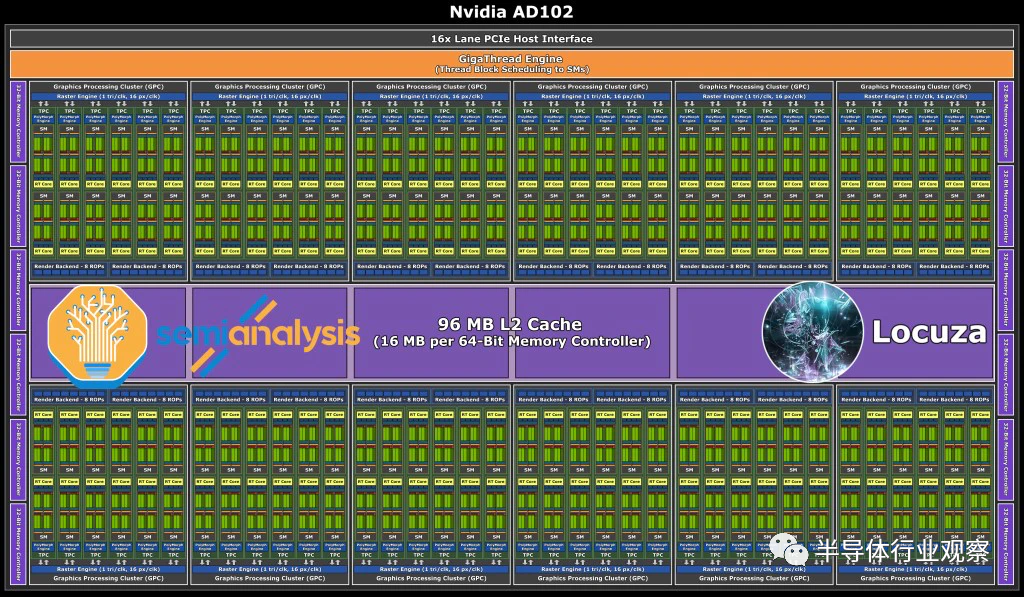
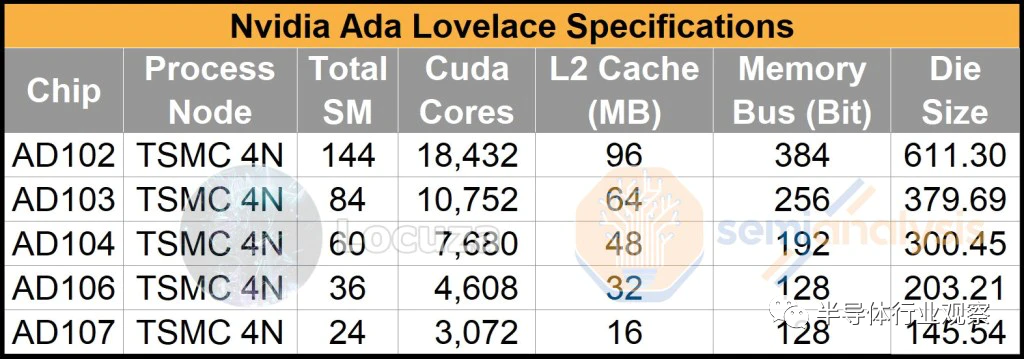
Ada 架构中的佼佼者是 AD102,估计其面积约为 611.3mm²。与上一代 GA102 相比,这是一个巨大的飞跃,因为通过 5 个额外的 GPC,他们获得70% 的 CUDA 内核增加。内存总线宽度则保持384 位不变,但我们预计内存速度会略微提高到 21Gbps 左右。尽管增加了,但这还不足支持该野兽芯片我运行。AD102拥有96MB L2 Cache,远高于上一代GA102的6MB L2 Cache。
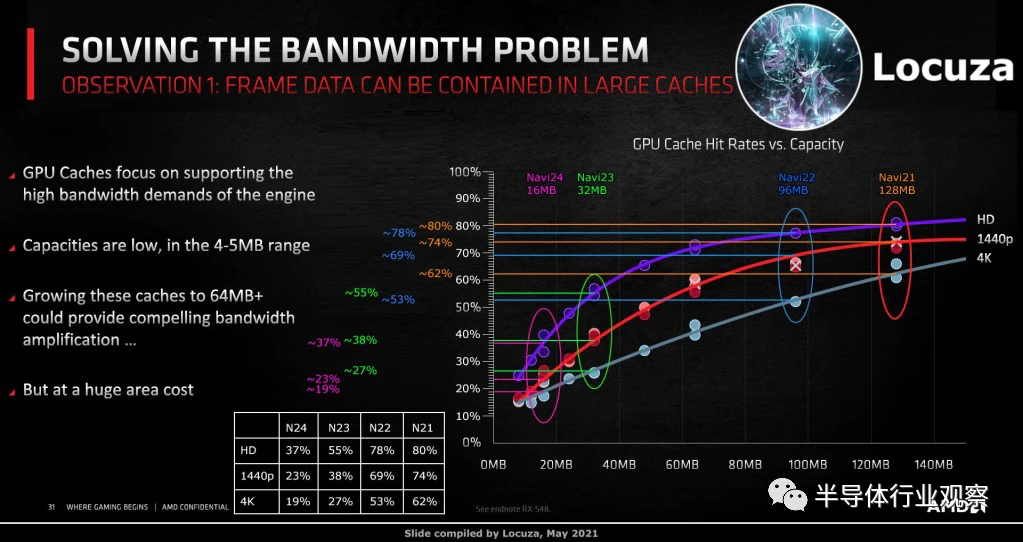
有趣的是,这与 AMD 的 Navi 22 GPU 具有“InfinityCache”的 L2 缓存数量相同。顺便说一句,我们希望 Nvidia 将他们的大型 L2 命名为“Nfinity Cache”只是为了吸引所有人。
AMD 的 Infinity Cache 是 L3 缓存,尽管两家供应商之间的缓存层次结构存在差异,但我们预计hit rates的总体趋势是相同的。以 AMD 为例,1080p 的hit rates为 78%,1440p 的hit rates为 69%,4k 的hit rates为 53%。这些高hit rates有助于降低内存带宽需求。
如果 Nvidia 的大型 L2 以类似的方式工作,尽管内存带宽略有增加,但它将极大地帮助馈送 AD102。Ada 的高端配置应该配备24GB 的 GDDR6X,但我们预计会有一些配置因此而减少。
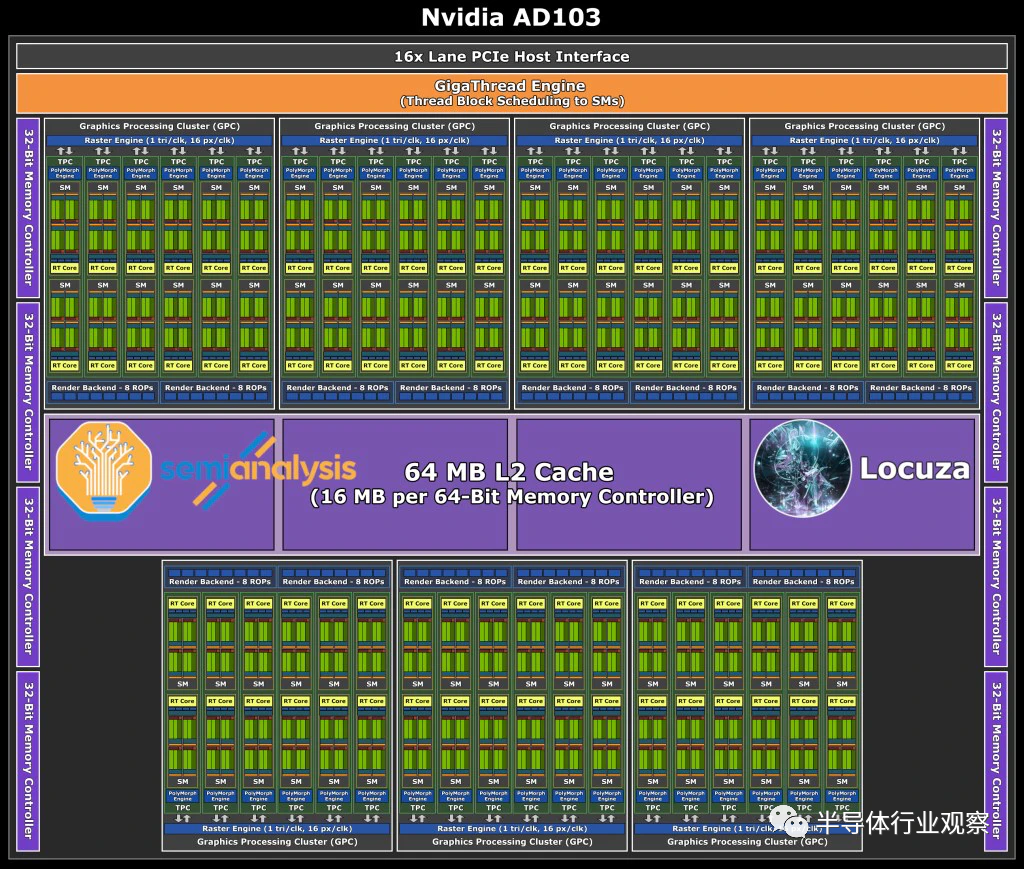
AD103 的配置非常有趣,估计约为379.69mm²。与 AD102 相比,这是一个巨大的降级。这可能是 GPU 一代中顶级芯片和第二个芯片之间近期内存中最大的差距,其中 AD102 的 CUDA 内核比 AD103 多70% 以上。
另一个有趣的事情是 CUDA 核心数量与当前一代高端 GA102 完全相同。内存总线采用 256 位总线,远小于 AD102 的 384 位总线。因此,基于 AD103 的游戏 GPU 最大容量为16GB,但可能会存在缩减版本。尽管内存带宽远低于 GA102,但包含 64MB L2 缓存仍将允许该 GPU 被馈送。
鉴于英伟达将使用定制的台积电“4N”节点,我们预计它们的时钟频率将高于 GA102。时钟增加加上架构改进将使 AD103 的性能优于当前一代旗舰产品 RTX 3090 Ti;如果他们把它带到高功耗的桌面上。需要注意的是,GA103 从未出现在台式机上,仅在笔记本 GPU 的高端上可用,因此 Ada 一代可能会再次出现这种情况。
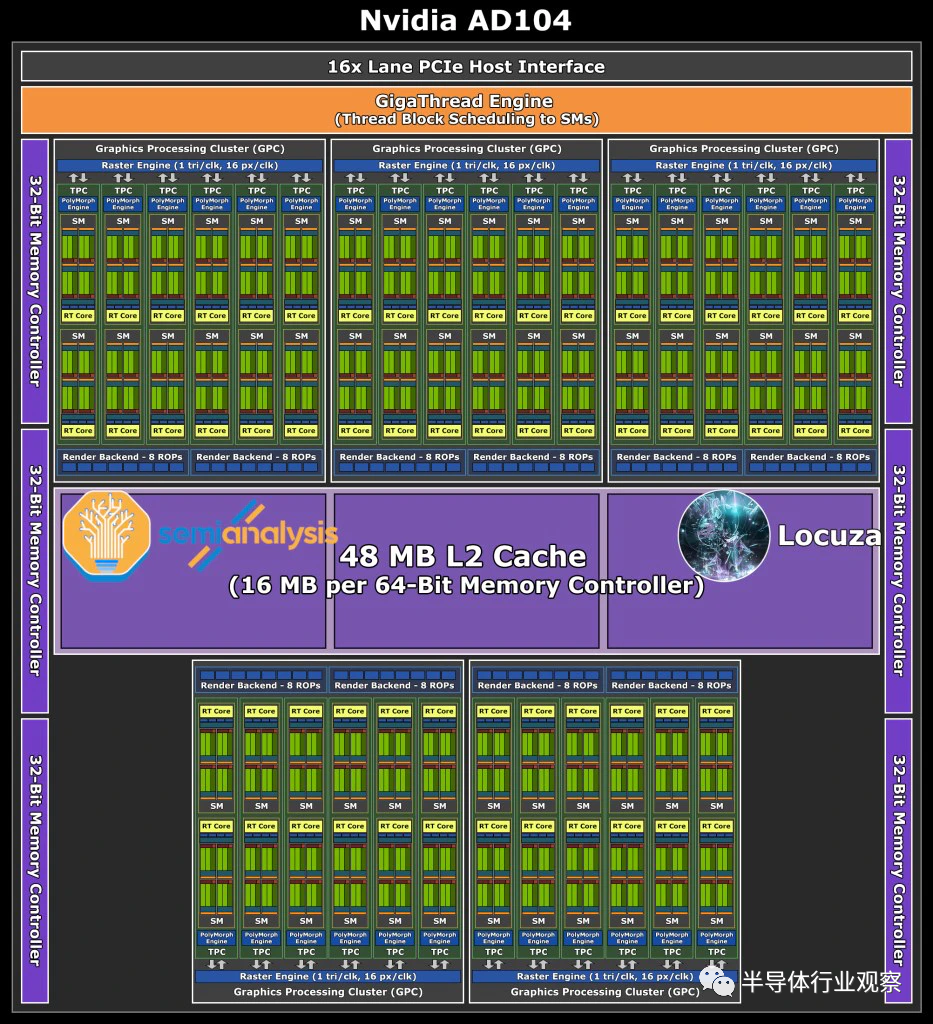
AD104 估计约为 300.45mm²,由于其性能和成本效益,它是 Ada 系列中的最佳选择。192 位总线为游戏 GPU 带来了 12GB 内存,具有足够高的容量,同时将材料清单 (BOM) 保持在合理水平。
同时,Nvidia GPU 的 104 设计往往具有与上一代 102 相似的性能。如果这种趋势持续下去,成本/性能应该会非常出色。事实上,它甚至可能有更多,因为 Nvidia 可能会增加相当多的时钟以达到 3090 以上的性能水平。
我们预计 Nvidia 的顶级 AD104 桌面 GPU 与GDDR6X 的功率将高达 350W 甚至 400W。因此,我们预计这将是大多数发烧友最终购买的 GPU。GPU 也可以是高效的,我们期望在没有 G6X 内存和时钟回退一点的情况下实现这一点。

AD106 是真正的大众市场 GPU,估计约为 203.21mm²。它可能是该系列中容量最大的 GPU,因为 106 个 GPU 是 Pascal、Turing 和 Ampere 世代的最大容量。由于是 128 位总线,它主要配备 8GB 内存。
在高端配置中,我们预计它的性能与GA104 相似,后者在 3070 Ti 中发挥最大作用。鉴于AD106 中只有 3 个 GPC 而 GA104 中只有 6 个 GPC,这个假设可能有点过于乐观。
该 GPU 也将是移动设备中容量最大的 GPU。使用 32MB 的二级缓存,GPU 缓存hit rates在 1080p 中可能为 55%,在1440p 中为 38%,在 4k 中为 27%,如 AMD 的 Navi 23。
在我们讨论这一代的宝贝 AD107 之前,我们需要介绍一些背景知识。
来自泄露文件的 Twitter 上发布的数据并未指定此 GPU 的缓存大小。先前的 GPU 假定每个 64 位内存控制器/帧缓冲区分区(FBP) 具有相同的 16MB。对于 AD107,这没有多大意义,因为 GPC 数量和总线宽度保持不变,而每个 GPU 的 TPC 仅下降到 4。如果 L2 缓存保持不变,那么芯片尺寸只会从 ~203.21mm²下降到 ~184.28mm²。这种微小的减少不足以将堆栈中的两个 GPU 分开。

相反,我们假设与图灵一代 GPU 的 TU116 和 TU106 存在类似的关系。TU116 有一个带有 0.5MB 二级缓存的 FBP,而不是像 TU10x 那样的1MB。如果我们对每个 FBP 应用相同的 50% L2 缓存模式,AD107 最终估计约为 145.54mm²。这对于产品定位和成本来说似乎要合理得多。

有了这些假设,AD107 似乎是一款出色的移动 GPU。由于不需要更多的 PCIe 通道,它被调整为 8 个通道,并且 Nvidia 通常将其底部 GPU 向下移动到此通道数。它的性能足以击败英特尔最好的 Meteor LakeiGPU 配置,但它的价格足够便宜,可以用于一些低成本的笔记本电脑。
总的来说,Ada 是一个相当有趣的阵容。在高端,性能(和功耗)有相当大的提高。AD102 的裸片尺寸与 GA102 相似,但采用更昂贵的定制台积电 4N 工艺技术,而不是更便宜的定制三星 8N 工艺技术。
相对于三星的 8nm 衍生产品,台积电 N4 衍生产品的密度增加相当大,这证明了成本是合理的。
有趣的是,尽管是一个更新得多的节点,但SemiAnalysis 的消息来源报告说,台积电 N4 的参数良率实际上比三星的 8nm 节点略好,尽管它具有相似的灾难性良率。这对于 GPU 来说基本上不是问题,因为几乎每个芯片都可以收获良率。
就裸片尺寸和整体 BOM 而言,Ada 阵容的其余部分变得更加温和。尽管晶圆成本要高得多,但在相同功率下性能通常应高于安培,但制造成本要低得多。我们玩了很多晶圆成本和芯片计算器来对成本进行一些估算,但最终英伟达的成本只是最终用户价格的一部分。Nvidia 出售带有标记的芯片,并协商 ODM/AIB 使用的内存定价。ODM/AIB 合作伙伴仍然必须以可能很低的利润率购买和集成内存以及电源组件和冷却系统。
Nvidia 似乎已最佳地平衡了 L2 缓存大小和内存总线宽度。内存大小将保持合理,因为大多数 GPU 将具有 16Gb G6X 或 G6。一般来说,AD104正在取代 GA102,AD106 正在取代 GA104 在性能层。内存成本相同,并且制造芯片的成本更低。由于效率更高且电路板更小,封装、冷却和电源组件等板级组件更便宜。
当我们比较堆栈中的相同裸片(例如GA104 与 AD104)时,内存大小有所增加,但这是需要的,因为 8GB 对于该段来说太少了,而 16GB 太贵了。
不过,应该考虑到对高功率的恐惧。Nvidia很可能会像上一代那样为每个芯片注入能量。事实上,我们可以想象他们会将功率推到堆栈中更高的 1 个芯片所做的事情,即顶级 AD104 配置达到 3080 级功耗,而顶级 AD106 配置达到 3070 级功耗。谣言指向顶级AD102,打破了GPU功耗的新纪录。
接下来,我们将分解我们如何得出这些裸片尺寸估计值。
芯片尺寸分析的第一步是收集有关 Ada的架构变化并将其与 Ampere 进行比较。SM 架构是 8.9 而不是 8.6,所以这主要是一代的改进。因此,我们假设 SM 大小增加 10%。我们不确定SM 架构的变化是什么,但它们可能包括 192Kb L1 缓存和张量核心。
我们心中最大可能的变化是增加了新的第3 代 RT 内核。在 IO 方面,泄漏表明 NVLink 已完全从阵容中移除,这表明 Nvidia 不会为多 GPU 数据中心和专业可视化应用程序推出 Ada 阵容。我们期待 PCIe 5.0,更好的内存控制器,适用于更高速度的 GDDR6X,和 DisplayPort 2.0 将包括在内。可能包括更新的 NVENC 和 NVDEC,这应该将 AV1 编码混合在一起。

Ada 最大的变化当然是 L2 缓存。Nvidia 似乎没有使用小型 L2 缓存,而是借鉴了 AMD 的 Infinity Cache ,并全面使用了更大的缓存。鉴于我们拥有大部分规格,Ampere 的 GA102 IP 块可用于创建与 AD102 规格相似的假设 GPU 裸片。这不会考虑某些更改,例如 SM 架构更改、更大的编码器块、PCIe 5.0、Displayport 2.0 或针对 GDDR6X 调整的内存控制器。
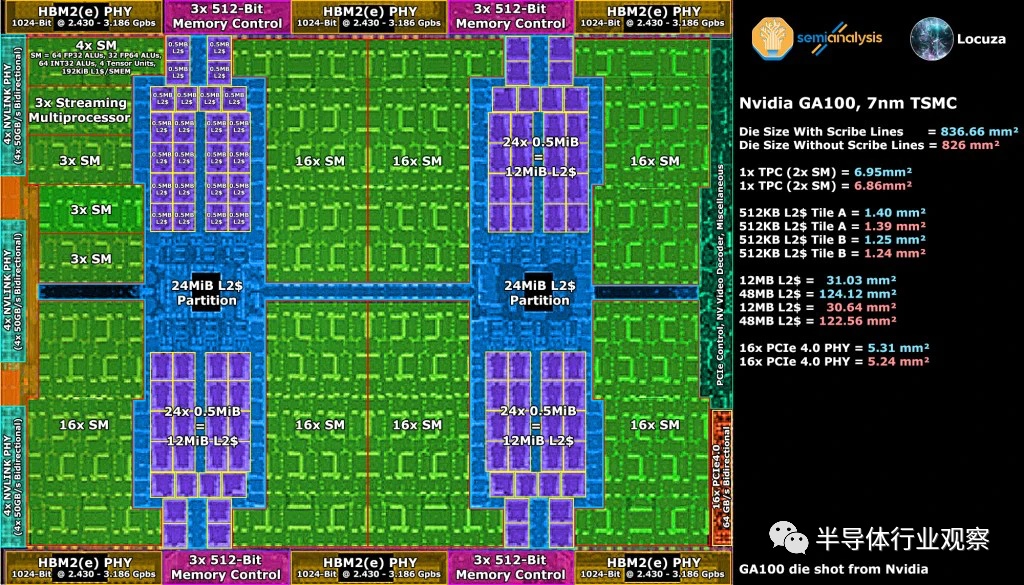
通过使用 GA102 构建块,我们为这个假设的 Ampere GPU 获得了 1629.60mm²的裸片尺寸,该 GPU 具有与 AD102 相同的配置,但采用 8nm。您会立即注意到的是 L2 缓存是巨大的。AMD 在其 Navi 21 GPU 上具有更大容量的 L3 Infinity Cache,但他们没有分配如此大的区域专用于该缓存。是的,AMD位于更密集的 N7 节点上,但这只是难题的一小部分。密度上的大部分差异来自 L2 缓存的布局和配置。
GA102 使用 48 个 128KB 的 SRAM 片,每个64 位内存控制器/帧缓冲区分区 (FBP) 有 1MB 的 L2。另一方面,GA100使用 80 个 512KB 的 SRAM 切片。从与 AMD 的 L2缓存的比较中可以看出,这些更大的切片似乎大大提高了密度。
GA100的密度提升远不止工艺节点缩小那么简单。使用 AMD 的 L3 Infinity Cache 可以看到相同的效果。

虽然 AMD 在许多设计元素上不如 Nvidia,但我们相信它们在缓存和封装等某些领域无疑更好。我们相信这在很大程度上源于他们的 CPU 团队的血统。AMD 非常擅长为GPU 制作极其密集的高性能缓存,如 Infinity Cache 所示。事实上,在我们最终的芯片尺寸估计中,Nvidia 的 96MB L2 仍然远不及 AMD 的 96MB L3 Infinity Cache。
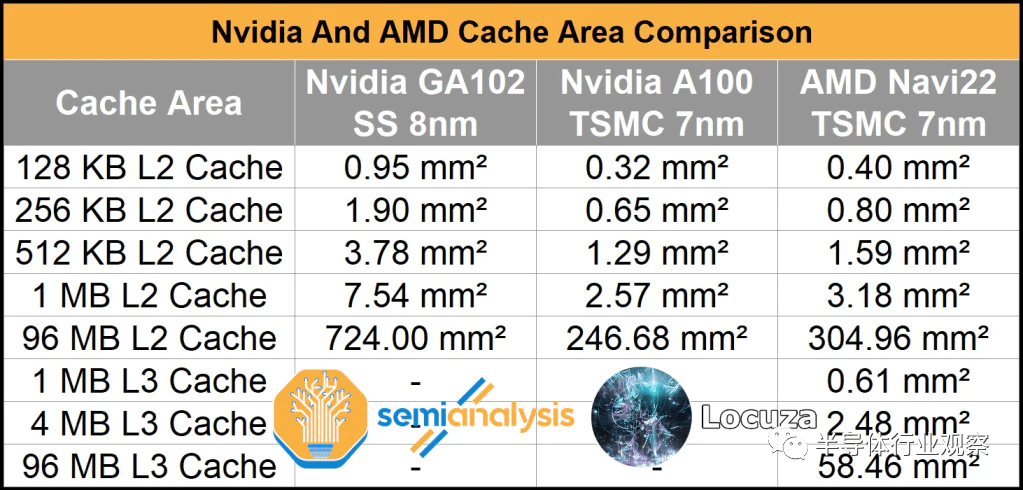
无论如何,仅从三星 8 缩小到台积电 4 不会使 GA102 构建块达到合理的裸片尺寸。相反,缓存设计需要进行架构返工。泄漏告诉我们,现在 AD102 的 FBP 中每个 64 位内存控制器有 16MB 的 L2。我们估计Nvidia 将迁移到 48、2048KB 的 SRAM 切片。
有了这个缓存配置,我们就可以用这些数字计算出理论上的缓存带宽。
AMD 在 1.94GHz 的 Navi 21 上拥有 1.99TB/s 的 Infinity Cache 带宽。如果我们假设 Nvidia 在 AD102 上以相同的 1.94GHz 运行,那么他们将能够在其 L2 上实现 5.96TB/s 的带宽。最终产品的时钟会有所不同,但我们预计 2.25GHz 左右的频率对于台式机中的 Ada 来说是现实的。我们预计 RDNA3 在台式机上的时钟频率将高于 2.5GHz。Nvidia 正在以一定的密度为代价做出使用高带宽缓存的设计选择。
Nvidia 本可以引入更高密度的缓存,每片 8-16MB。这可能会使它们的 L2 密度与 AMD 的 Infinity Cache 相似,但它会导致 L2 带宽下降到 Ampere 的带宽以下。最后,这可能不是一个选择。
我们对这种不同的缓存架构对 AD102构建块 L2 区域的影响进行了估算。然后我们对台积电的 N7 应用了收缩系数,对台积电 N4 应用了另一个收缩系数。SRAM 似乎使用 60:40 的 SRAM 与逻辑分割,这有助于影响我们使用的 SRAM 缩小。我们对 SM 应用了10% 的总增长因子来解释那里的任何架构变化,并根据它们的 SRAM 与逻辑的混合(通常为 30:70)对各种数字逻辑块具有不同的收缩因子。
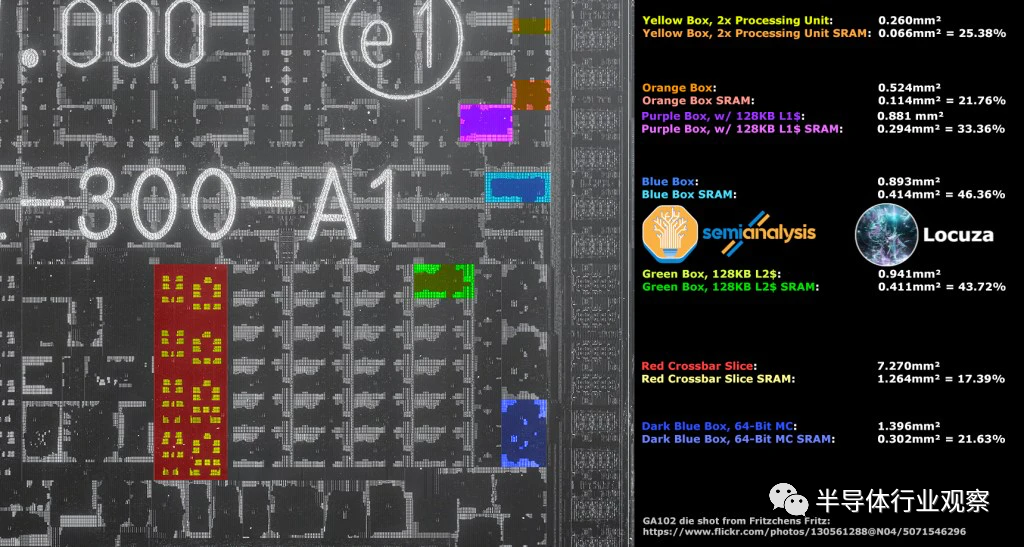
最后,我们保持芯片的模拟部分相同,因为缩小幅度很小,但这些将通过可能增加面积的升级来平衡,例如 PCIe 5.0、GDDR6X 内存速度和 DisplayPort 2.0。在这些图中删除了 NVLink。最后我们到达了~611.3mm²。这与kopite7kimi 所说的模具尺寸约为 600mm²的说法独立一致。
在收集了一个小的概述之后,我们可以从其余阵容的配置开始。GPC、计数、TPC 计数、L2 大小、命令缓冲区、各种PHY、交叉开关等都可以根据 GPU 配置动态缩小。基于我们对台积电和实际产品的陈述的捏造,我们为收缩因素选择的所有数字都有些武断,所以最后它有点在黑暗中拍摄。对于 AD107,我们略微放弃了不同的缓存架构,因为每个 FBP 的缓存量较少。
总体而言,Ada Lovelace 在架构上似乎与当前的 Ampere 架构并没有太大的不同,但它确实带来的变化,例如改进的光线追踪核心、改进的编码器和更大的 L2 缓存将在降低成本的同时显着提升性能尽管位于更昂贵的基于 TSMC N4 的定制节点上。Nvidia 一直保持着在堆栈中保持内存大小平衡的传统,每个级别的内存大小适度增加。L2与 AMD 相比,有传言指出高端产品的性能非常高,但成本也很高。我们对他们的 Navi33芯片更感兴趣,它应该介于 AD104 和 AD106 之间。范围很大,但泄漏表明它在大众市场上是一个很好的竞争对手。
AMD 目前在光线追踪性能方面远远落后,并且缺乏 DLSS 和广播等许多差异化软件功能确实损害了他们的竞争力,但我们相信这将是十年来最具竞争力的 一代GPU 。
随着以太坊 2.0 猛烈抨击采矿需求的中断以及消费者将他们的支出组合从商品转向服务,GPU 价格正在快速下跌。这些因素与更高的通货膨胀相结合意味着我们预测 AdaLovelace(和 RDNA 3)GPU 价格在 400 至 1,000 美元的市场中将是相当不错的性价比。堆栈的顶端很可能具有惊人的性能水平,但成本更高。
来源:
https://semianalysis.substack.com/p/nvidia-ada-lovelace-leaked-specifications?s=r
相关下载:
《GPU高性能计算概述》
《GPU深度学习基础介绍》
《OpenACC基本介绍》
《CUDA CC 编程介绍》
《CUDA Fortr基本介绍》
深度报告:GPU研究框架
CPU和GPU研究框架合集
信创研究框架
信创产业系列专题(总篇)
2021年中国信创生态研究报告
中国数据处理器行业概览(2021)
DPU在数据中心和边缘云上的应用
英伟达DPU集数据中心于芯片
本号资料全部上传至知识星球,更多内容请登录智能计算芯知识(知识星球)星球下载全部资料。
免责申明:本号聚焦相关技术分享,内容观点不代表本号立场,可追溯内容均注明来源,发布文章若存在版权等问题,请留言联系删除,谢谢。
电子书<服务器基础知识全解(终极版)>更新完毕。
获取方式:点击“阅读原文”即可查看182页 PPT可编辑版本和PDF阅读版本详情。
温馨提示:
请搜索“AI_Architect”或“扫码”关注公众号实时掌握深度技术分享,点击“阅读原文”获取更多原创技术干货。


