--关注回复“26262”--
智能驾驶的概念模型简单来说就是解决三个核心问题:
1. 我在哪?
2. 我要去哪?
3. 我该如何去?
第一个问题“我在哪?”需要解决的是“环境感知”和“定位”问题,需要了解的是车自身的位置以及该位置周边的静态环境(道路,交通标识,信号灯等)和动态环境(车、人等)。由此引发一系列的感知和定位的技术方案,包括各种传感器以及算法体系。
第二个问题“我要去哪?”在自动驾驶领域就是“规划决策”。由此延伸出一些术语“全局规划””局部规划"、“任务规划”“路径规划”、"行为规划”、“行为决策”“运动规划”,等等,由于语言上的歧义,这些术语有的是同一个意思的不同说法,有的其含义在不同场合经常相近但又有点差别。
抛开具体的术语,一般而言这“规划决策”这个问题都会被分解为三部分:
1. 在一定范围内的全局意义上的规划 (常用术语:全局规划,路径规划,任务规划)
2. 将第一步的结果做划分出多个阶段 (常用术语:行为规划,行为决策)
3. 对每一个阶段进行进一步的规划 (常用术语:局部规划,运动规划)
对于这些各种各样的规划衍生出很多解决问题的算法体系。
第三个问题“我该如何去?”一般指的就是“控制执行”,也就是对最小一个规划的实际执行实践,达到规划的目的。具体在车上,往往体现为各种控制算法,控制理论解决的就是这些问题。
因为这三个问题的解决归根到底都是算法问题,所以某种意义上,说自动驾驶的核心就是算法。而软件架构从某种意义上说,就是要能承载这些算法。没有很好的承载体系,再好的算法也无用武之地。
为了方面我们把基础概念模型的三个问题分别表示为 E , P, X,分别代表 环境(Environment)、计划(Plan)、执行(eXecute)。每一组 E-P-X 都有其描述问题空间。
比如说,我们定义问题空间 A 是“驾车从北京到广州”,那么对于问题 E:其定位关注的可能就是当前在北京那个区,不必细化到街道。我们还需要关心天气是否有雷暴雨,省道以上的道路结构信息。对于问题P:
P-1 : 第一步先设计出一个全局的路径,走哪条高速、国道、省道
P-2 :根据全局路径计划出一系列行为组成,先到哪个高速路口,行驶多少公里,去服务区加油、更换到另一条道路等等
P-3:计划出到每一段的具体道路路径。比如到高速路口要走三环还是四环,在换到哪条路上
X 要执行 P 规划出来的每一步。
如果我们定义问题空间 B 是“驾车安全通过一个路口”,那么对于E 问题,要关注的是当前的道路信息、交通灯信息、道路上的车辆状况、行人状况等。对于P 问题:
P-1 :第一步先规划出通过路口的安全路径,包括根据交通规则和道路信息计划到达当前路口的哪个车道,进入目标路口的哪个车道。
P-2 :第二步要第一步的根结果规划出一系列动作序列,如先减速,切换目标车道,停车等红灯,起步加速,通过路口。
P-3 :第三步对第二步的每一个动作要设计具体的一段轨迹,轨迹要能避开行人车辆等障碍物。
X 负责执行执行 P 问题的输出结果。
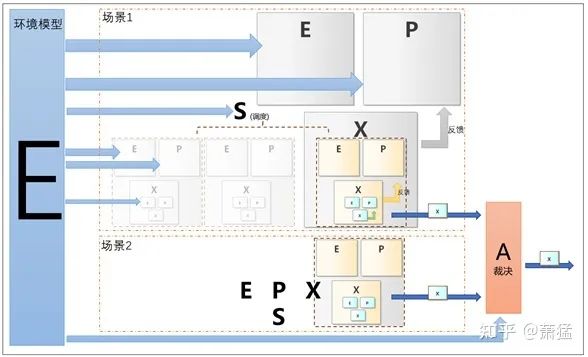
这个问题空间 B 是最接近通常规划算法要解决的问题。其中 P-1 的第一步常称为“全局规划”或“任务规划”,P-2 常被称为“行为规划”或 “行为决策”,P-3 被称为“局部规划”或“运动规划(Motion Plan)”。如下图所示,E-P-X 形成抽象的基础概念模型,问题空间 A 和 B 都是其在某个范围上的具体实现。
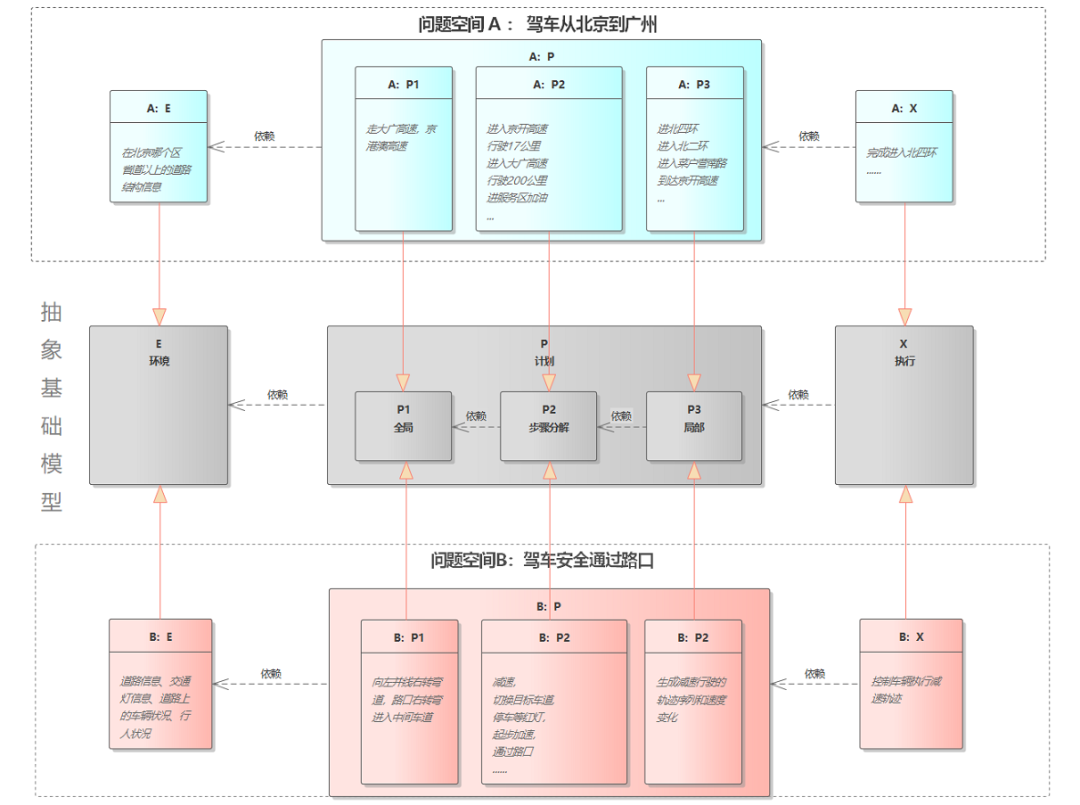
图 1 两个EPX的问题空间
A 和 B 两个问题空间都有 相似的 E-P-X 结构,但是他们解决的问题在时间和空间上的跨度差别很大。上图中 A:X 需要执行的任务 “完成进入北四环”完全可以下一级的 EPX 循环去完成。所以实际上,如下图所示 E-P-X 模型是一个分形递归的结构。
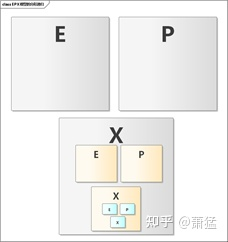
图 2 EPX的分形递归结构
上一级的 X 总能被下一级的再一次分解为更小粒度的 E-P-X 来执行。
"分形" 又称为“自相似分形”,其通俗理解是事物的局部与整体有相似的结构,是在不同尺度上的对称,例如一颗树的一支树枝与整颗树是相似的结构,再进一步,每片树叶的茎脉也是相似的结构。下图列举了一些典型的分形结构。

图3 分形示例
这 6 个图形都有一个特点,每个图形的任何一个局部都与整个图形的结构是一样的。局部进一步放大,会发现局部的局部也是同样的结构。因此当我们有一套业务处理逻辑能够适用于整体,也同样可以适用于局部。就像有些树的培育,可以取一根树枝种下去,会长成一棵新树。映射到软件程序的表达,就是“递归”。这并不是说使用递归函数来处理,是指架构层级的递归。
“分形”更学术化的表达是"用分数维度的视角和数学方法描述和研究客观事物,跳出了一维的线、二维的面、三维的立体乃至四维时空的传统藩篱,更加趋近复杂系统的真实属性与状态的描述,更加符合客观事物的多样性与复杂性“。当我们为“物理现实”找到合适的数学表述,再转换为“程序现实”,就能找到更简洁、清晰、准确的软件架构及实现方式。
E-P-X 是根据“物理现实”抽象出来的结构。而且其中绝大部分都是各种各样的是算法的工作。单个算法本身的研究和开发可以根据预定义的输入输出条件独立进行。但是算法怎么组合起来,在合适的时机被正确的触发,其结果被合理使用,才能最终形成有实际用途的功能。这个从“物理现实”到“程序现实”的桥梁核心就是软件架构。
自动驾驶系统从 Level 1 到 Level 5, 越往上,上述 E-P-X 模型的嵌套深度就越多。软件架构上的难度也就越大。大部分单一的 Level1 和 Level2 功能只需要一层 E-P-X 模型。以 AEB (自动紧急刹车)为例:
E 部分(感知) :主要就是对前方目标(车,人)的静态识别和分类、动态跟踪,检测距离和速度。
P 部分: 因为 AEB 只做纵向的控制,可以全部通过对速度的控制来实现。所以只需要做对一段时间内的速度做出规划。
X 部分:将速度规划交由车辆控制单元执行。
并不是说只有一层 EPX ,AEB功能就简单。实际上 能够量产的 AEB 功能实现难度一样是非常大的。不过一层的 EPX , 就不需要基于场景进行调度,只需要关注与单一场景下 EPX 的实现,其软件架构就相对简单。第二章会介绍 L2 功能常见的软件架构。
即便是在最小粒度层级的 EPX 循环中,也不是一个EXP的实现就能解决这一层级的所有问题。
比如:就一个简单的直线行驶用例,我们可以将最末端 X 单元实现为一个车辆控制算法,这算法处理完所有的平道、上坡、下坡场景。也可以使用一个调度单元(S),根据 E 单元的信息,将平道、上坡、下坡识别为不同的场景,切换不同的 下一级 EXP 循环。下一级的每个 EXP 循环实现单一的场景。实际上,即便使用一个 X 单元的控制算法解决所有平道、上坡、下坡场景,这个算法内部也一样会对这些场景进行区分,实际还是一个微小粒度的 EXP 循环。

图4 EPX的调度
如图 4所示,场景的调度(S) 可以在每一个层级都有,也就是说对“场景”的定义也有粒度的划分。所以 ,EPX模型应该是 EPX-S 模型。只是在 L2 以下没有明显的 S 部分。
自动泊车辅助功能就开始有场景调度的需求,比如垂直泊车、垂直泊入、水平泊出、水平泊入、斜向泊入等等都是不同的场景,其 P 和 X 部分都需要分别实现。但是场景调度可以通过HMI界面由人工来选择,是一个“人在回路中”的 S 单元。
Level 3 以上功能中,很长一段连续的驾驶过程都不需要人工干预。就必然涉及到多个不同的 EXP层级自动调度。这样在软件架构上就跟L2以下功能有很大不同。这也是为什么很多公司把 L2 和 L3+分成两个不同的团队的原因之一。
实际上只要是有意识的基于多层级的 EXP-S 模型来设计软件架构,每一个EXP-S单元都有其合适的体现,实际上是可以实现一套软件架构支持从 L1到L3+以上的自动驾驶基本。只是说 S 单元对 L2以下功能来说比较弱一些,但是其架构地位仍然存在。
我们先来看一下L2 功能的常用软件架构,我们对常用
AEB/ACC/LKA 三个功能是 L2 最经典的驾驶辅助功能,一般的系统方案的感知部分多采用前向的摄像头输出目标(车辆、行人)信息,并与前向毫米波雷达给出的目标数据做融合,得到更准确的速度和距离。视觉感知和雷达感知多采用Smart Sensor 方案,这样 Tier 1 可以选用成熟的 Tier2 供应商的产品。Tier 1 主要的开发工作在感知融合与功能状态机的实现以及车辆控制算法。
方案一:视觉感知结果传递给雷达感知控制器,雷达感知控制器中完成感知融合和 L2功能状态机
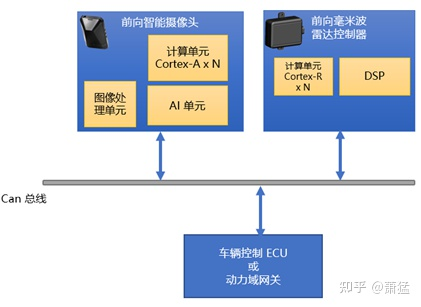
图 5 方案一拓扑
方案二:独立的L2 控制器连接 视觉和雷达的Smart Sensor,L2控制器完成感知融合和 L2 功能状态机
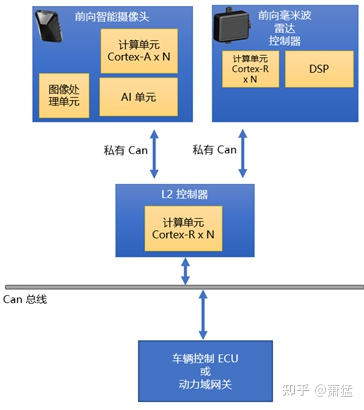
图 6 方案二拓扑
两个方案都是经常被采用的。方案一采用较高性能的雷达控制器,分配部分计算单元用来实现融合算法和功能状态机。很多芯片厂商做雷达处理芯片设计时就考虑到这部分算力预留。比如NXP 专为雷达ECU设计的 S32R 系列,其多核心足够同时做雷达信号处理与 L2 的功能实现。毕竟最耗算力的视觉算法是在另外器件上完成的。
方案二单独独立出来 L2实现 L2 功能的控制器, 通过私有Can 与两个 Smart Sensor 通讯获取感知数据。一般来说,这个方案可以考虑后续增加更多的 L2 功能,如果有需要,可以再接更多的 Smart Sensor。
对于采用 Smart Sensor 的系统架构来说,前向智能摄像头和前向毫米波雷达分别给出各自观测到的环境中目标对象的语义。这两部分数据直接通过 Can 总线或内部的 IPC (计算机OS的进程间通讯)机制传递给负责感知融合和 L2 功能实现的模块。
无论是硬件方案一还是方案二,业内最常用的软件架构是基于 Classic AutoSar 来开发。Classic AutoSar 提供了车载ECU通用的功能并为引用软件提供执行环境和数据输入输出通道。感知融合模块和其它 ACC/AEB/LKA 功能可以实现为一个或多个 AutoSar SWC(软件组件)。具体这些 SWC 组件是否进行拆分,如何拆分,各家开发商有自己的合理逻辑。但基本架构大同小异。
当然也可以不采用 Classic AutoSar , 用其它合适的 RTOS 作为底层系统,或许对于车载ECU需要通用功能开发和达到功能安全标准的难度会大一些,但在应用功能开发的架构体系上跟采用 Classic AutoSar 的方案没有太大差别。
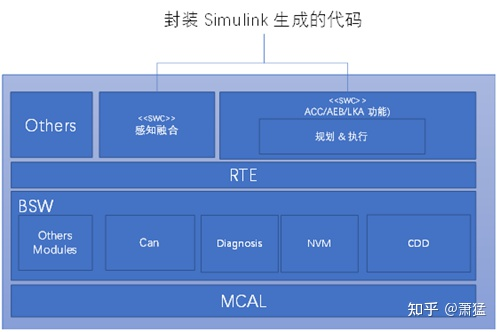
图7 ACC/AEB/LKA 的典型软件架构
MBD开发方式
业内常用MBD(基于模型的开发)方式来实现感知融合算法,规划和控制执行算法以及 ACC/AEB/LKA 功能状态机。然后使用工具生成 C 代码,再手动集成到目标平台。MDB开发方式的一个便利之处在于可以先使用模型工具和 CanOE 之类的设备直接上车开发调试,或者与仿真平台连接进行开发调试。这样开发团队可以分成两部分,一部分人用模型工具开发应用功能,一部分人开发所有车载ECU都需要的一系列繁琐工作,然后再集成在一起。
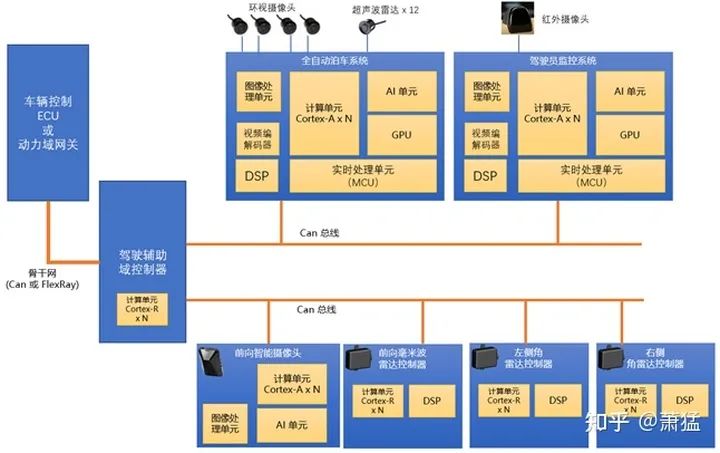
一般全自动泊车产品会采用集成度更高的方案,在一个 ECU 内将视觉算法(静态障碍物识别,动态障碍物识别,行人识别,车位线识别)超声波雷达算法(距离检测,障碍物检测)泊车过程的轨迹规划和控制执行,都放在一个控制器内完成。集成度更高的还会在自动泊车控制器中同时 支持360环视功能,这就还需要支持摄像头环视图像的校正和拼接2D/3D 的图形渲染视频输出HMI 生成等功能。
示意性的硬件拓扑如下。
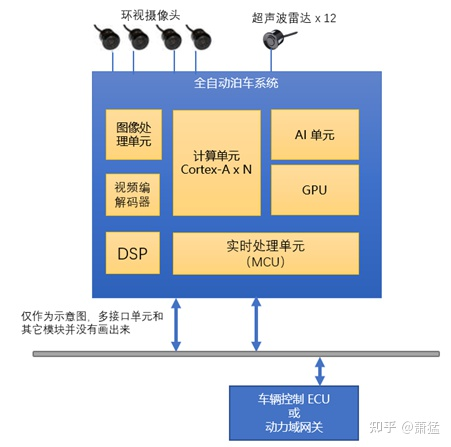
图 8 泊车系统的硬件拓扑方案
图中的各个模块在不同的硬件选型方案中有不同的分布模式。一般情况下用于实时处理的 MCU 会单独使用一颗芯片。不同的芯片厂家有各自的 AI 单元解决方案。有的用高性能的 DSP,有的专有的矩阵计算单元,有的用FPGA, 不一而足。
下图是自动泊车系统一个典型的软件架构(只是简化后的示意,实际量产系统会复杂更多):
与 2.1.1 相比,这里最显著的改变就是区分了“实时域”和 “性能域”两套系统。一般来说,我们把MCU或其它实时核心(Cortex-R,Cortex-M 或其它对等系列)上的软硬件系统成为“实时域”。把 SOC 内的大核心(Cortex-A或对等系列)以及运行在其上的 Linux/QNX 统称为性能域,这里面一般还包含了支持视觉算法加速的软硬件体系。
虽然从量产的工程化难度上,全自动泊车系统比 ACC/AEB/LKA 等 Level2 主动安全功能要小很多。但是在软件架构上,泊车系统却复杂很多。主要体现在以下方面:
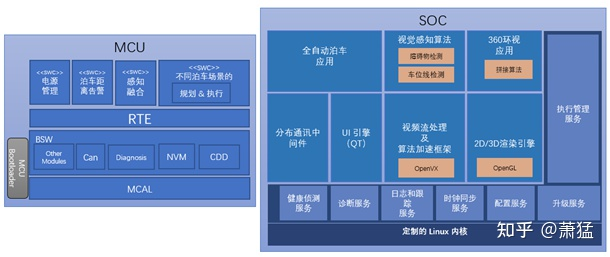
图 9 泊车系统的软件架构
实时域和性能域的划分带来系统性的复杂度,需要根据实时性要求和计算资源的要求,为不同的计算选择不同的硬件平台
-- END --