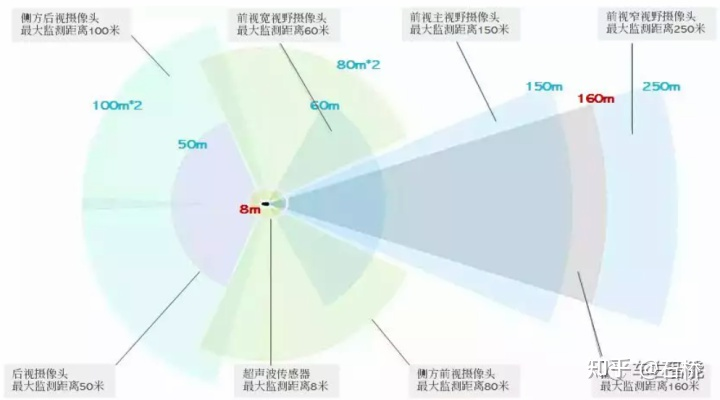
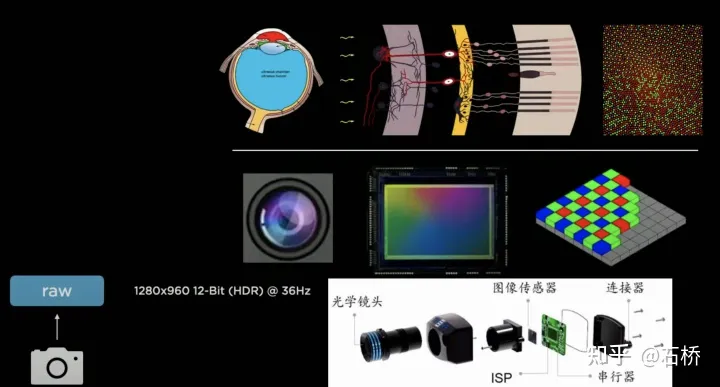
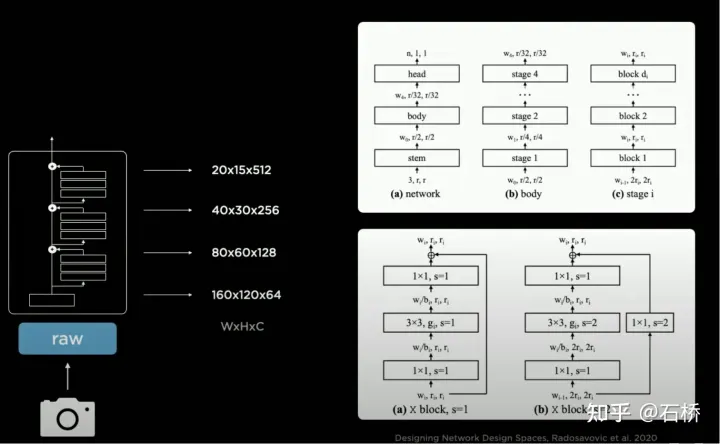
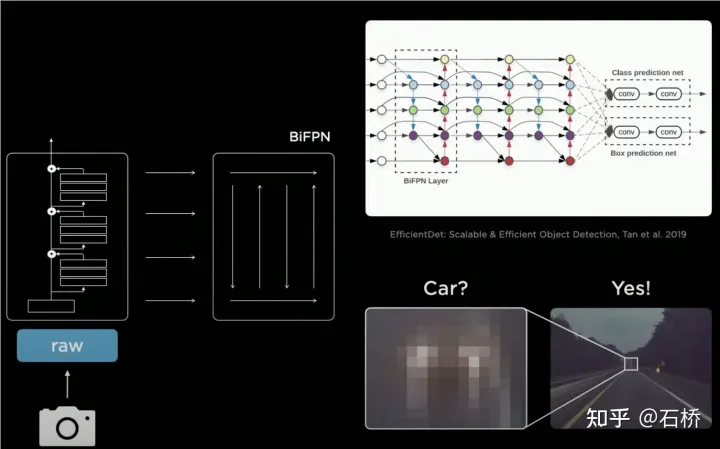
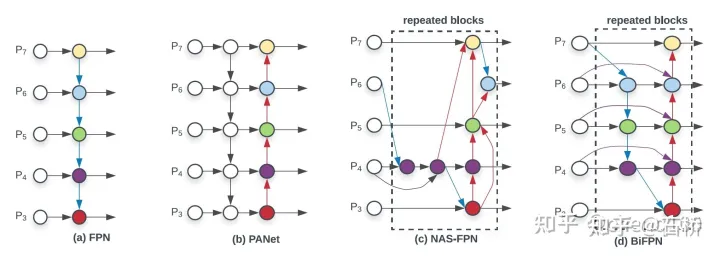
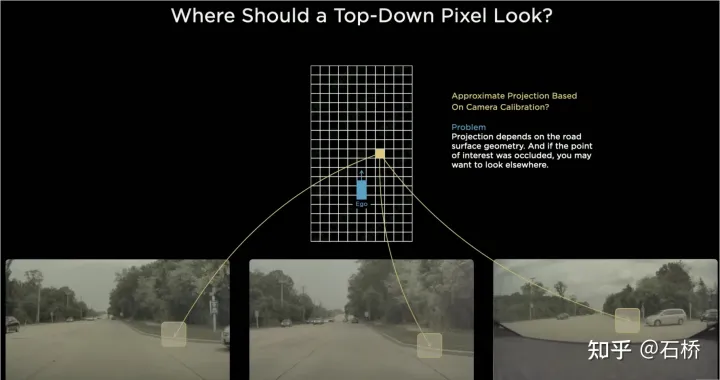
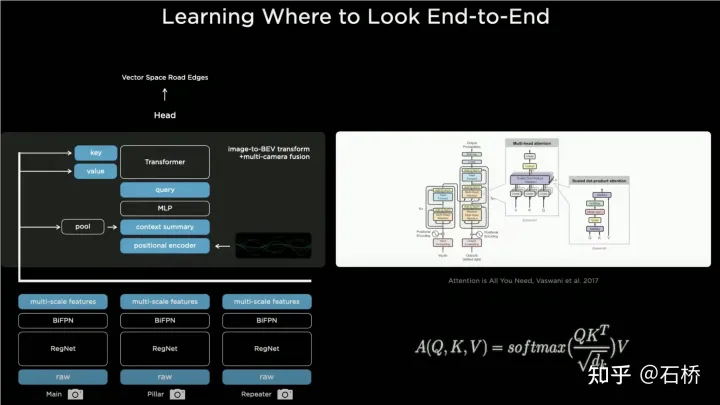
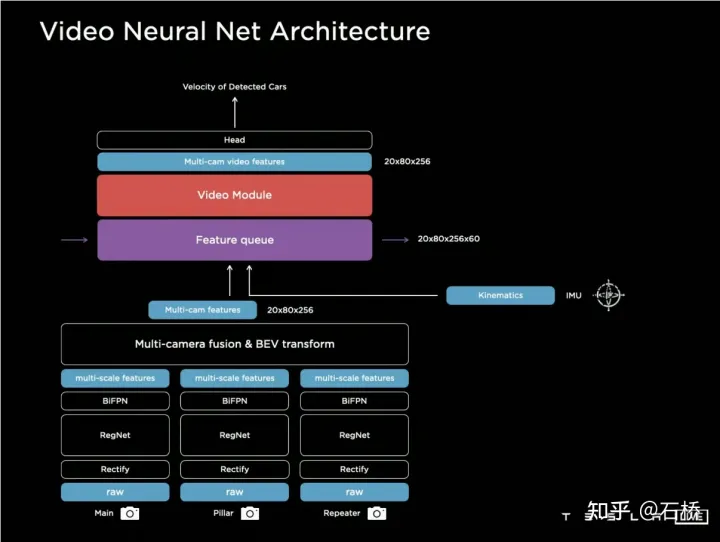
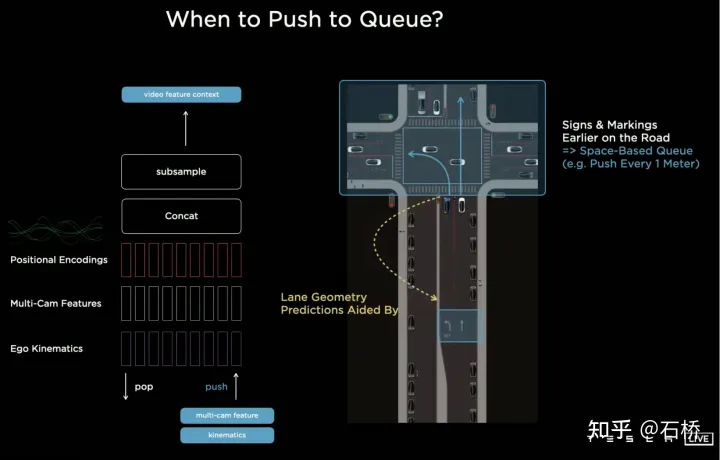
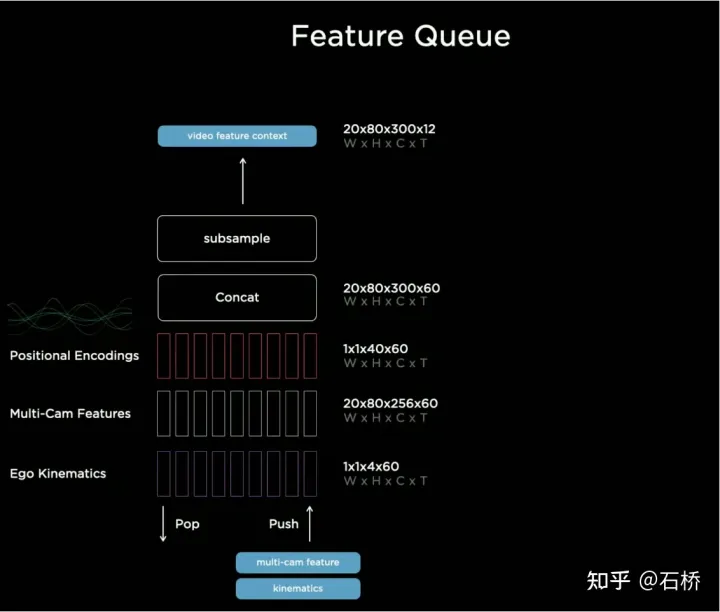
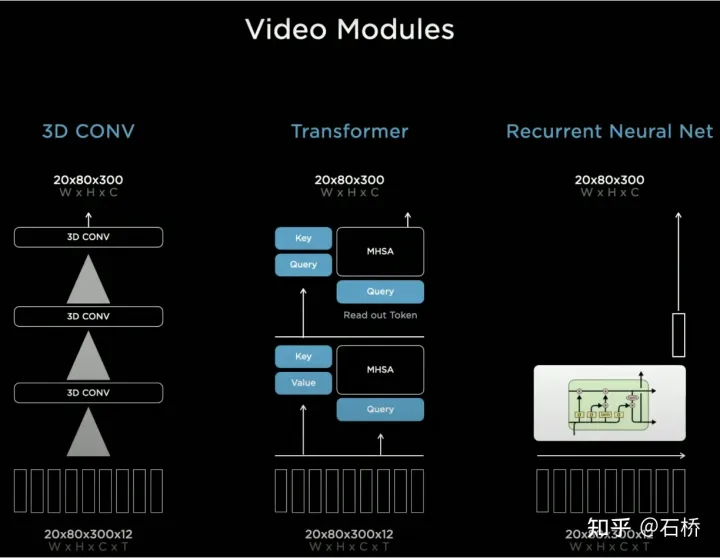
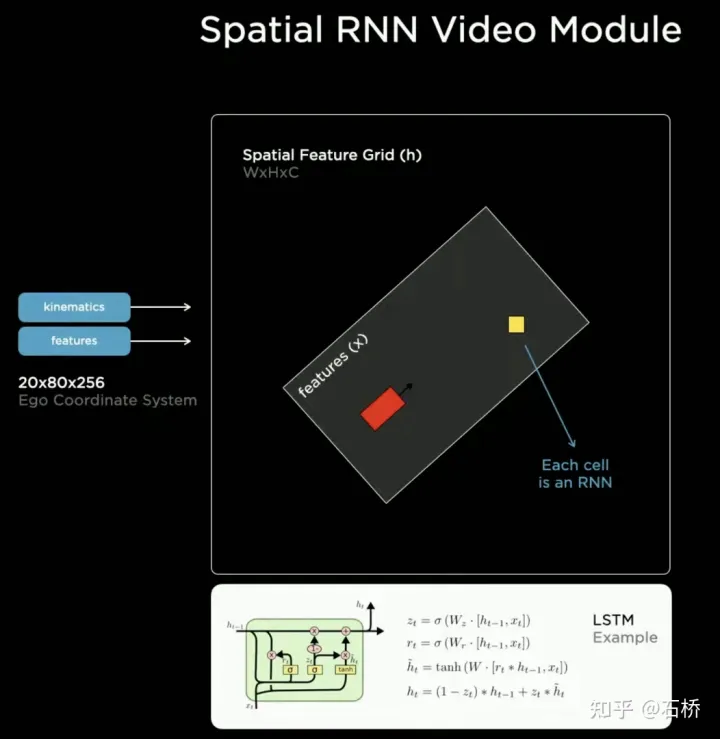
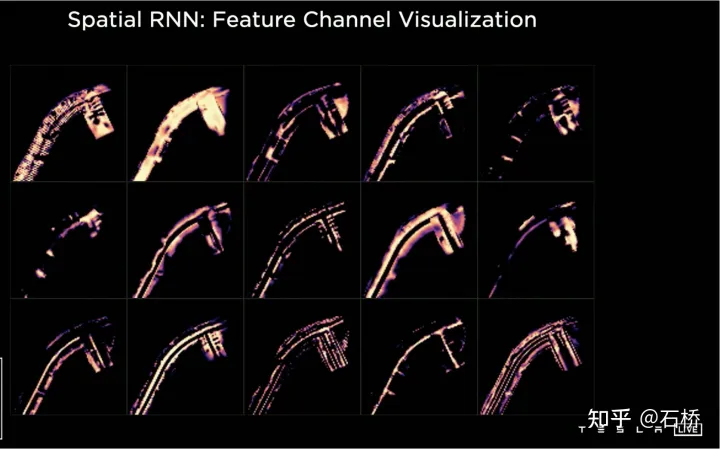
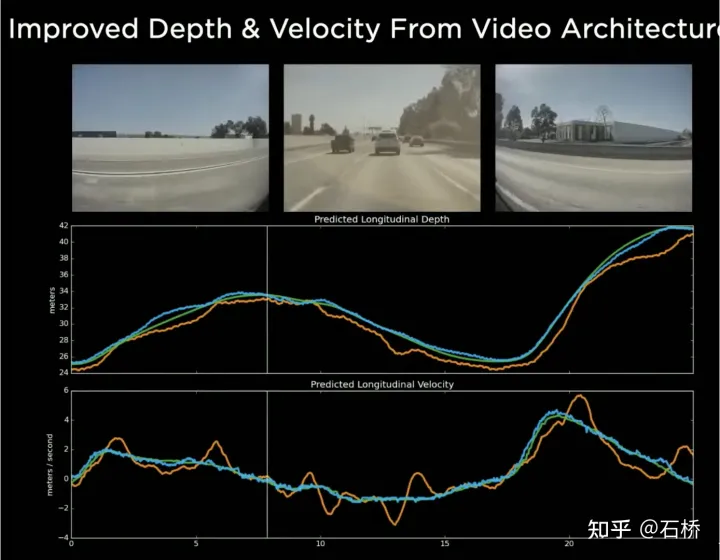
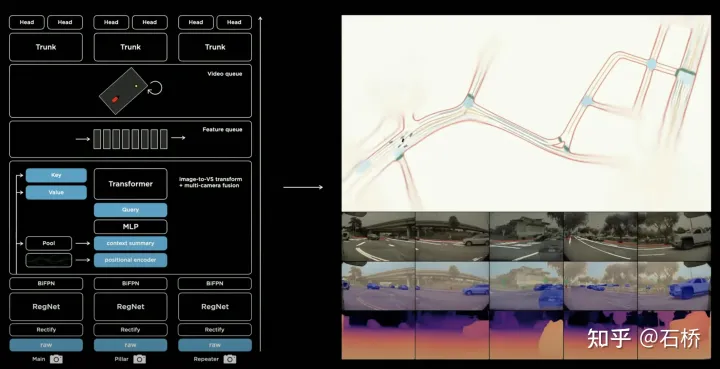
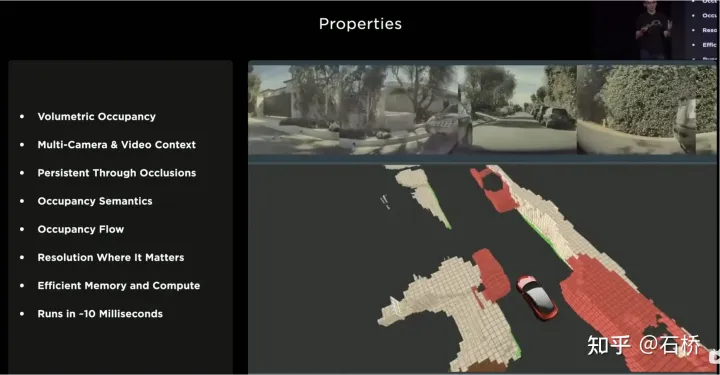
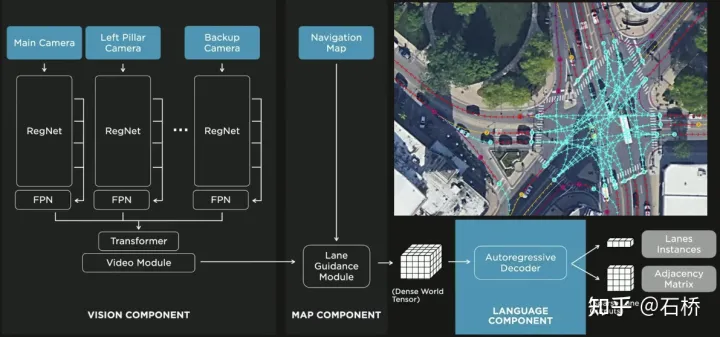
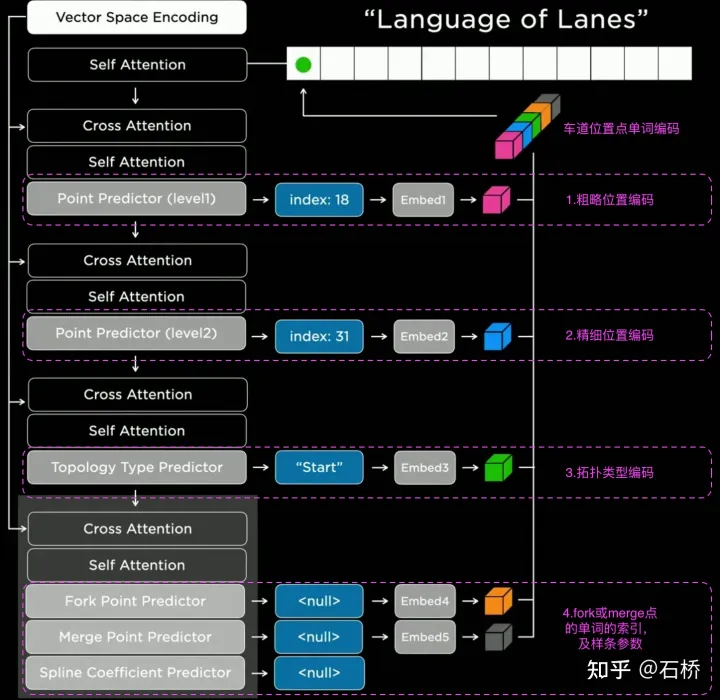
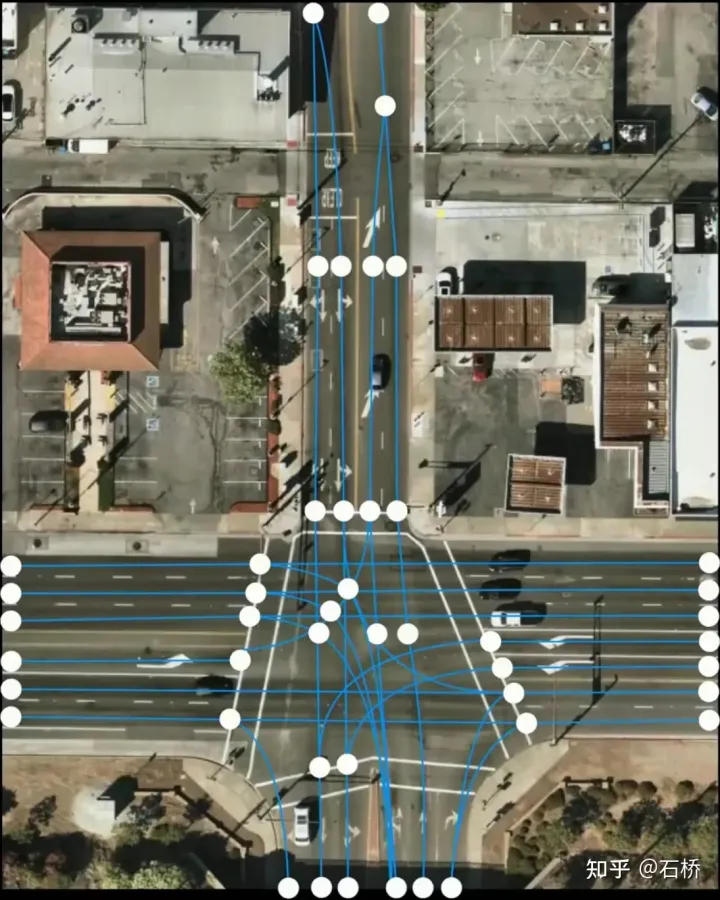
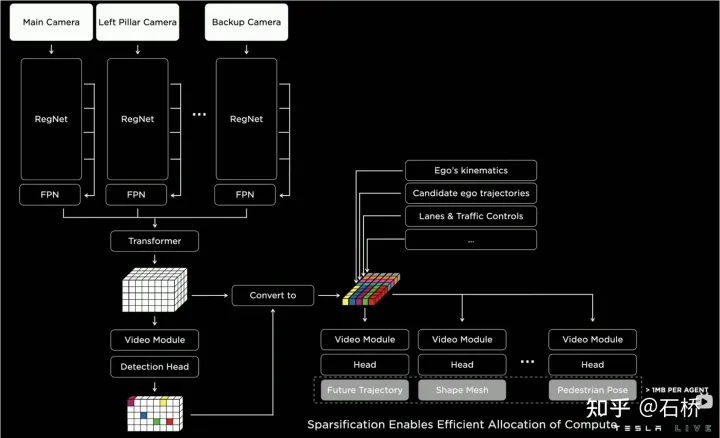
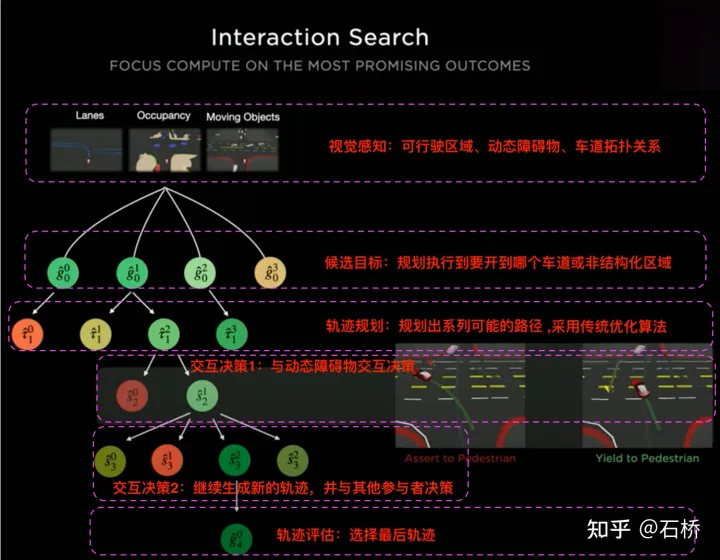
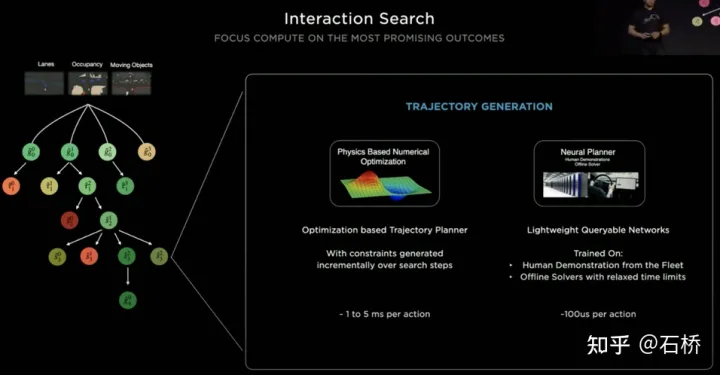
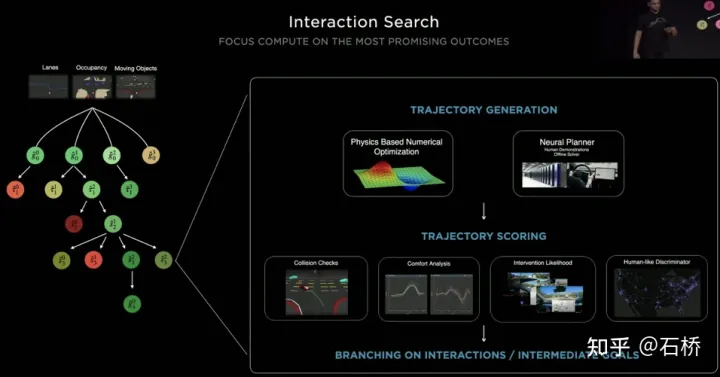
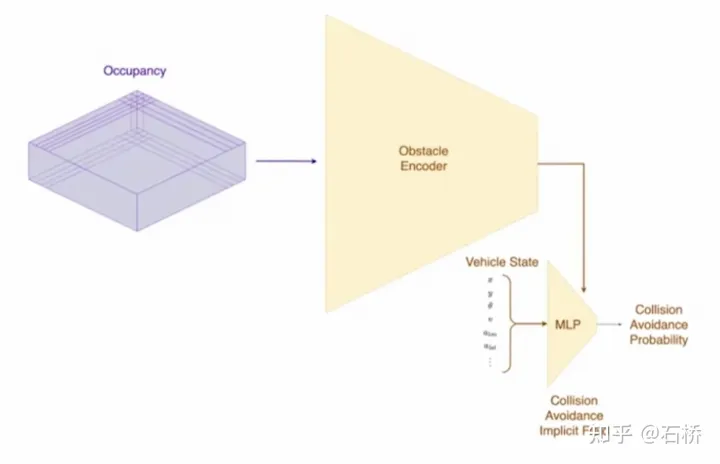
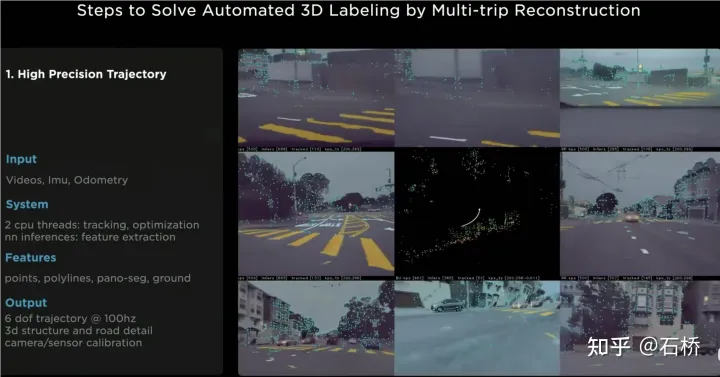
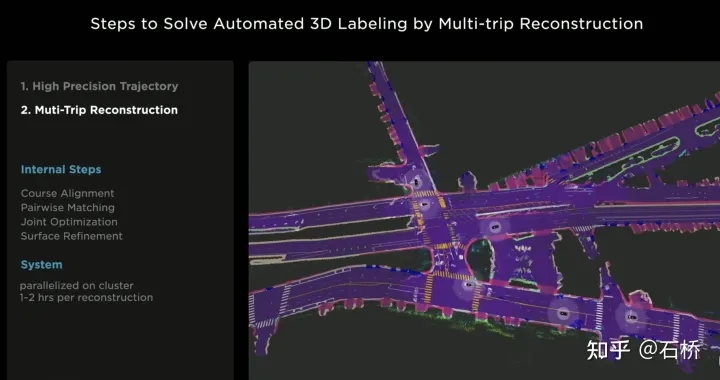
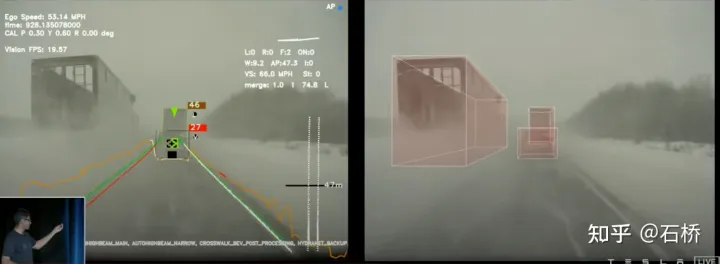
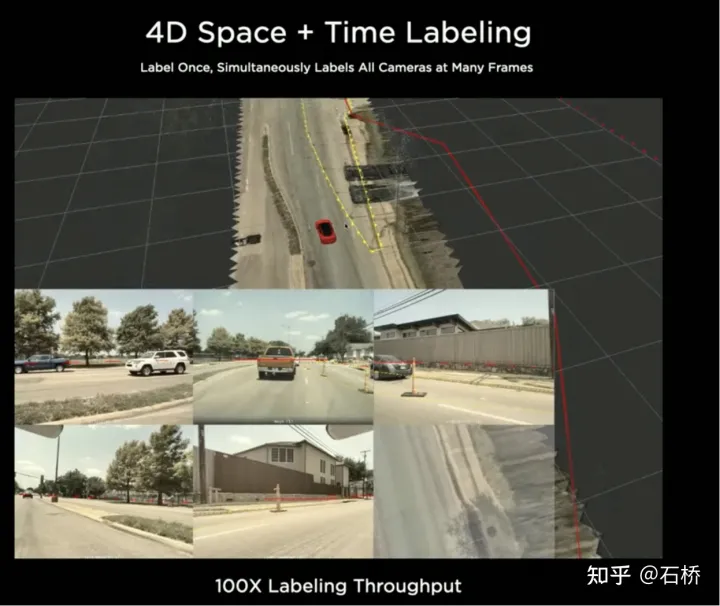
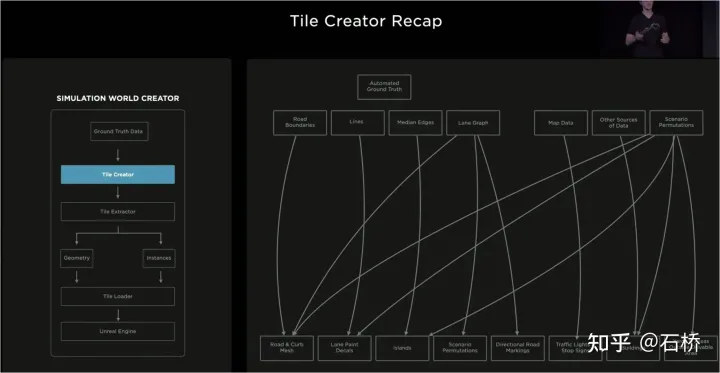
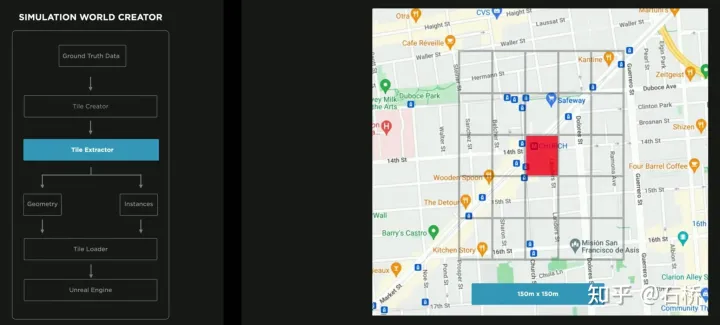
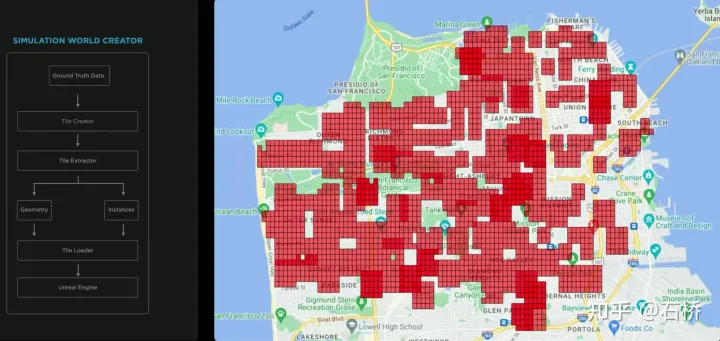
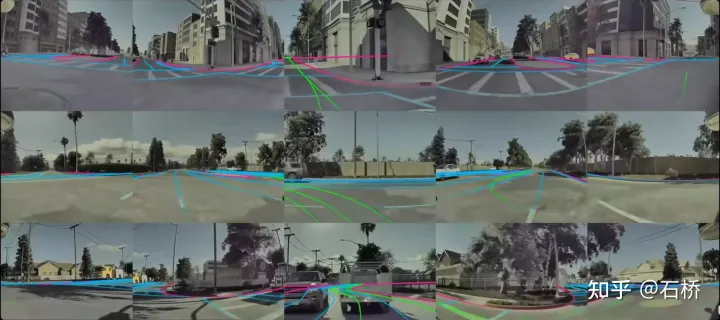
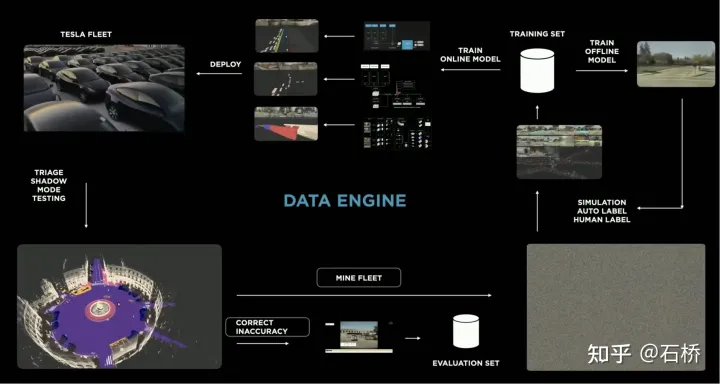
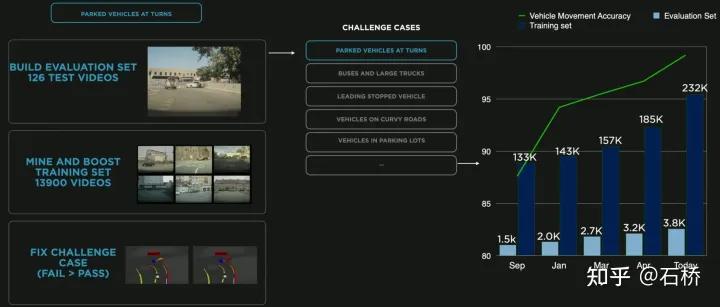
只分割、识别出车道线是不够的,还需要推理获取车道之间的拓扑连接关系,这样才能用于轨迹规划。FSD车道线拓扑关系感知1)Lane Guidance Module:使用了导航图中的道路的几何&拓扑关系,车道等级、数量、宽度、属性信息,将这些信息与Occupancy特征整合起来进行编码生成Dense World Tensor给到拓扑关系建立的模块,将视频流稠密的特征通序列生成范式解析出 稀疏的道路拓扑信息(车道节点lane segment和连接关系adjacent)。2)Language Component:把车道相关信息包括车道节点位置、属性(起点,中间点,终点等)、分叉点、汇合点,以及车道样条曲线几何参数进行编码,做成类似语言模型中单词token的编码,然后利用时序处理办法进行处理。具体流程如下:language of lanes 流程language of lanes最终language of lanes表征的就是图中的拓扑连接关系。
根据Global Info Research项目团队最新调研,预计2030年全球封闭式电机产值达到1425百万美元,2024-2030年期间年复合增长率CAGR为3.4%。 封闭式电机是一种电动机,其外壳设计为密闭结构,通常用于要求较高的防护等级的应用场合。封闭式电机可以有效防止外部灰尘、水分和其他污染物进入内部,从而保护电机的内部组件,延长其使用寿命。 环洋市场咨询机构出版的调研分析报告【全球封闭式电机行业总体规模、主要厂商及IPO上市调研报告,2025-2031】研究全球封闭式电机总体规