



51份专业报告
专题研究:ChatGPT:深度拆解(2023)
国泰君安:ChatGPT 研究框架(2023)
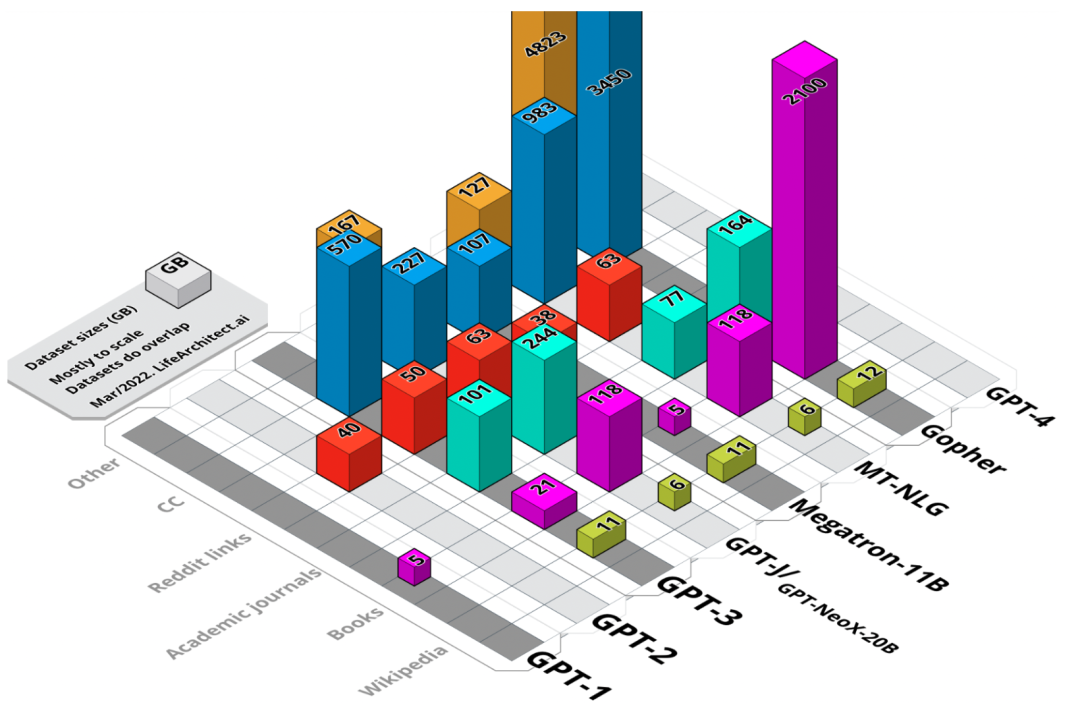
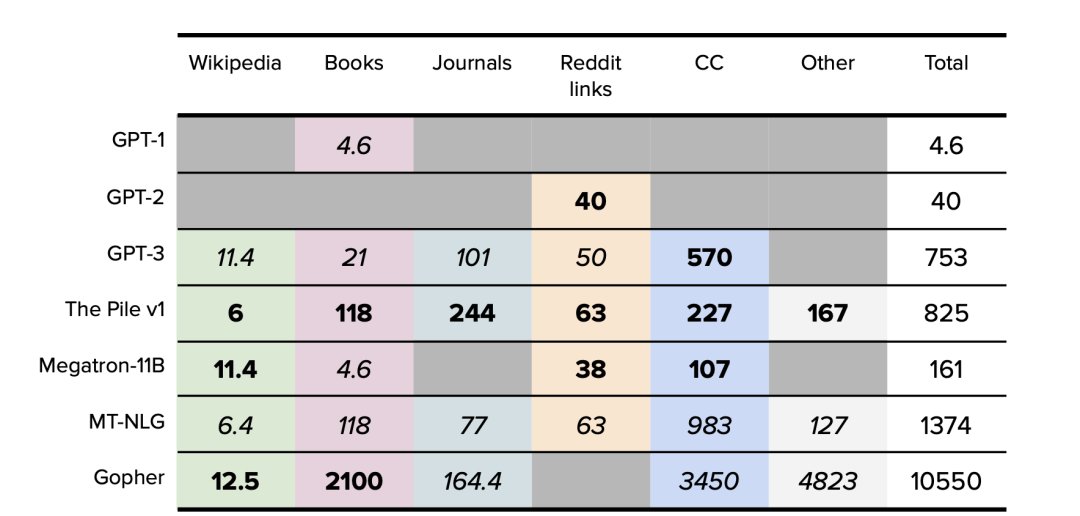
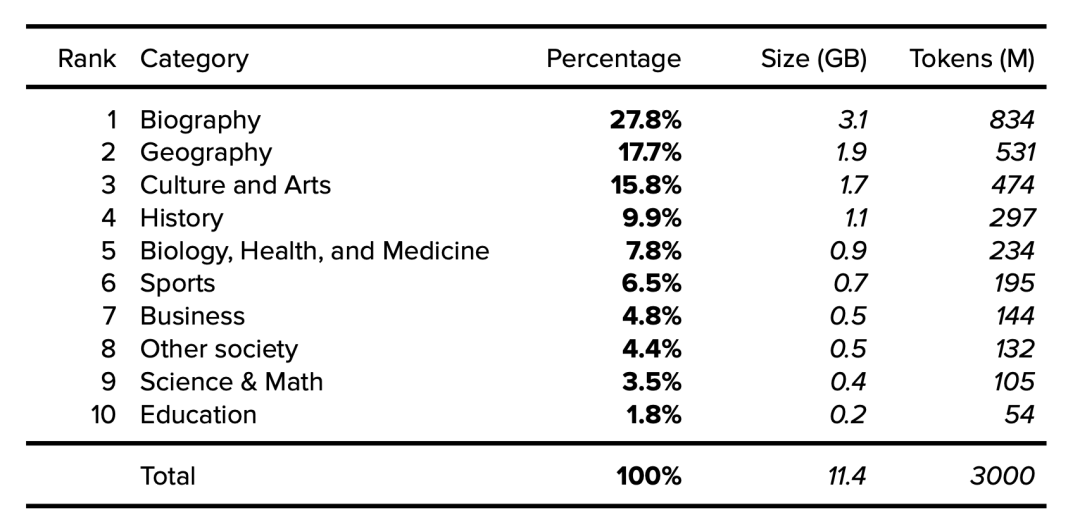







Datasheets for Datasets Gebru, T., Morgenstern, J., Vecchione, B., Vaughan, J., Wallach, H., Daumé III, H., & Crawford, K. (2018). Datasheets for Datasets. https://arxiv.org/abs/1803.09010
GPT-1 paper Radford, A., & Narasimhan, K. (2018). Improving Language Understanding by Generative Pre-Training. OpenAI. https://cdn.openai.com/research-covers/language-unsupervised/language_understan ding_paper.pdf
GPT-2 paper Radford, A., Wu, J., Child, R., Luan, D., Amodei, D. & Sutskever, I. (2019). Language Models are Unsupervised Multitask Learners. OpenAI. https://cdn.openai.com/better-language-models/language_models_are_unsupervised _multitask_learners.pdf
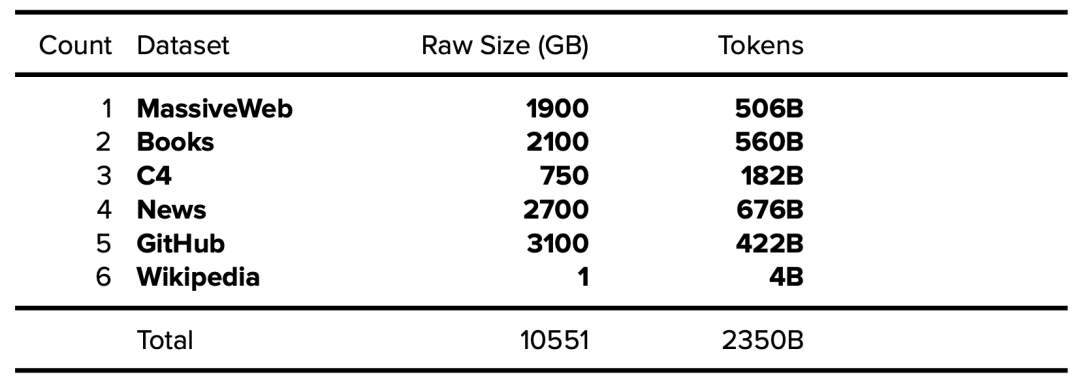
GPT-3 paper Brown, T., Mann, B., Ryder, N., Subbiah, M., Kaplan, J., & Dhariwal, P. et al. (2020). OpenAI. Language Models are Few-Shot Learners. https://arxiv.org/abs/2005.14165
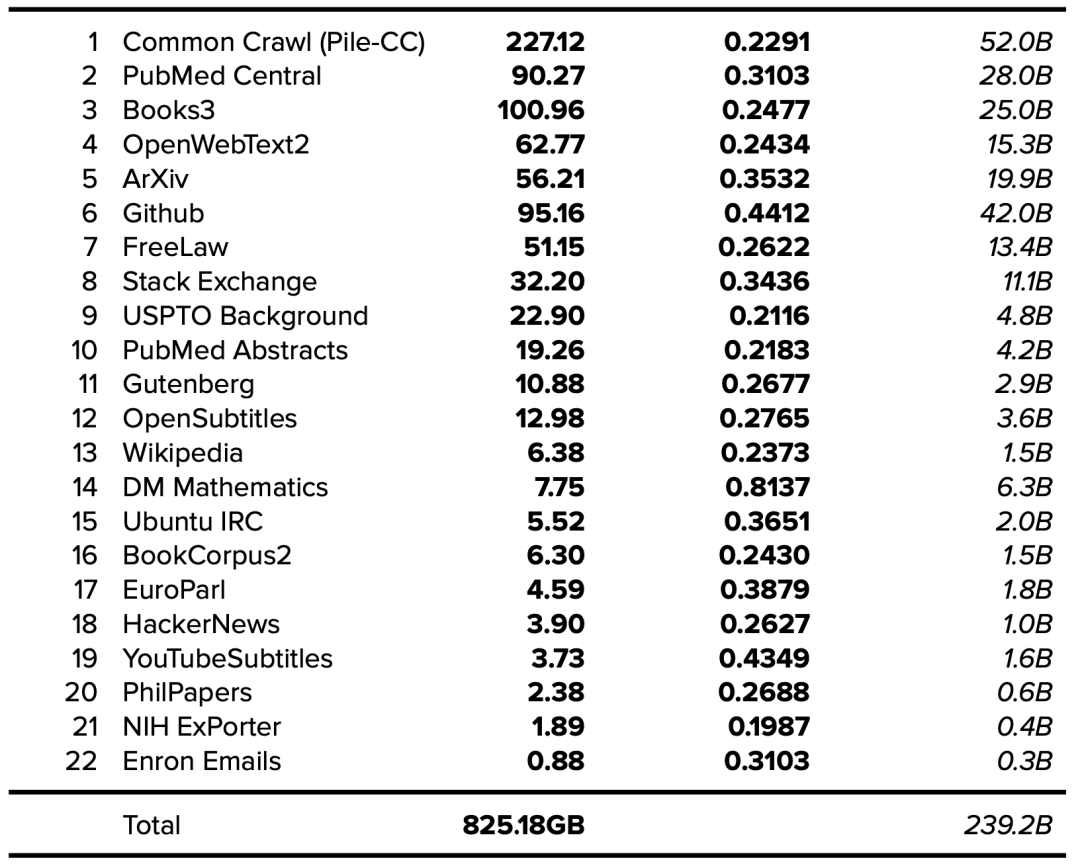
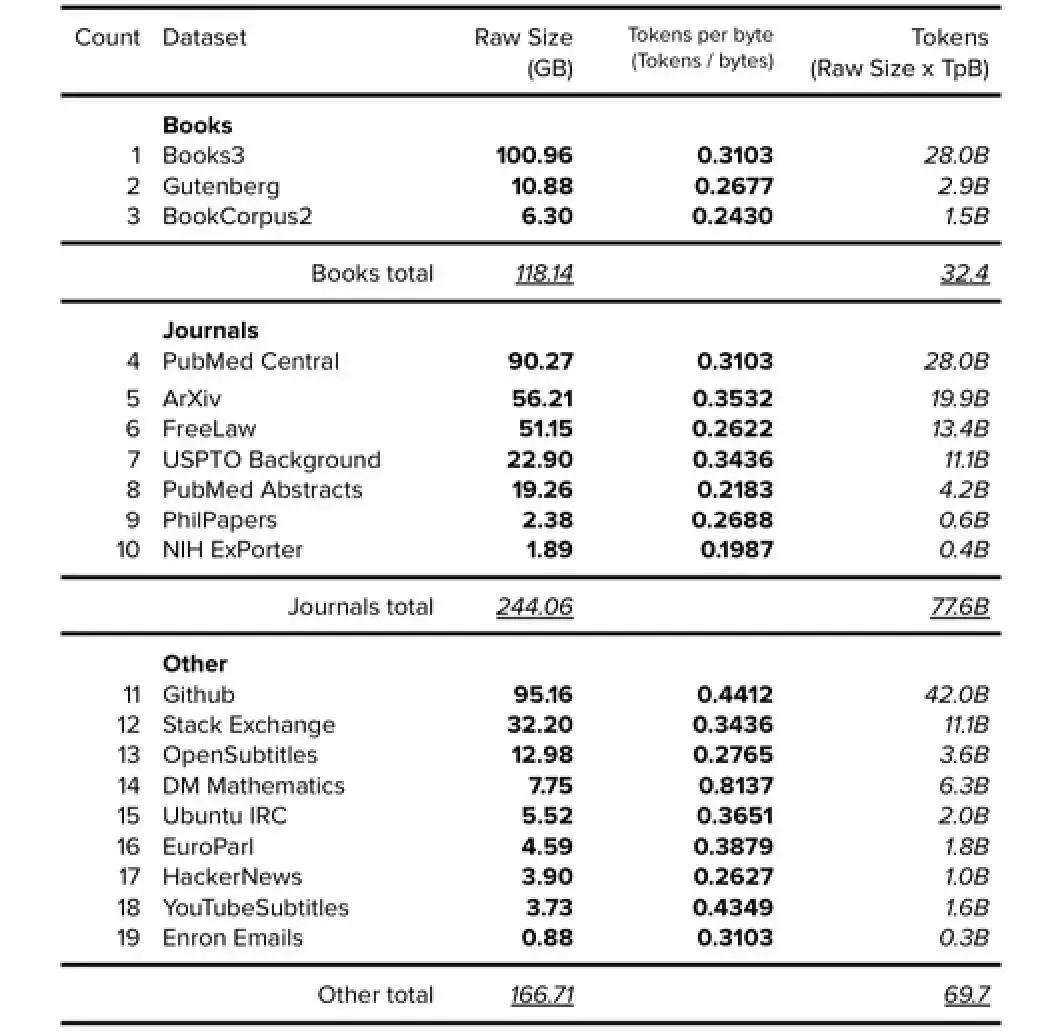
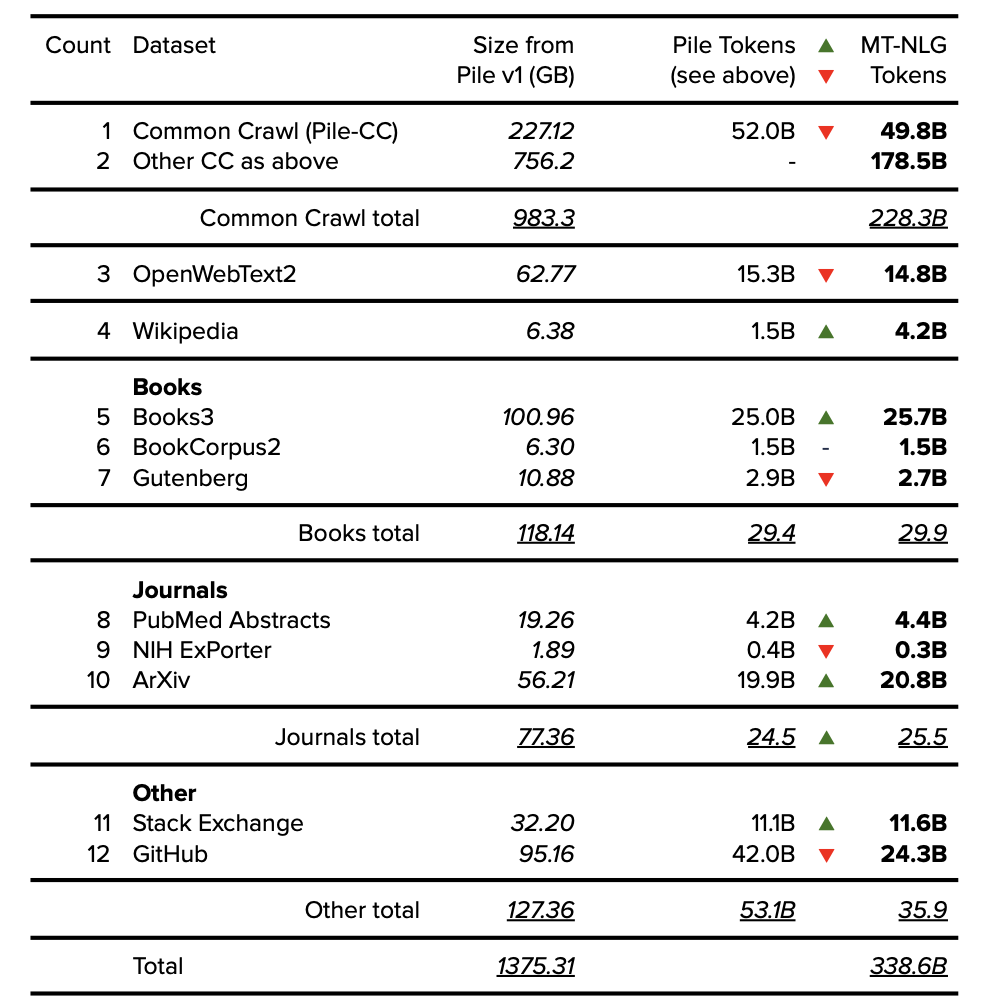
The Pile v1 paper Gao, L., Biderman, S., Black, S., Golding, L., Hoppe, T., & Foster, C. et al. (2021). The Pile: An 800GB Dataset of Diverse Text for Language Modeling.
EleutherAI. https://arxiv.org/abs/2101.00027
GPT-J announcement Komatsuzak, A., Wang, B. (2021). GPT-J-6B: 6B JAX-Based Transformer. https://arankomatsuzaki.wordpress.com/2021/06/04/gpt-j/
GPT-NeoX-20B paper Black, S., Biderman, S., Hallahan, E. et al. (2022). EleutherAI. GPT-NeoX-20B: An Open-Source Autoregressive Language Model. http://eaidata.bmk.sh/data/GPT_NeoX_20B.pdf
RoBERTa paper Liu, Y., Ott, M., Goyal, N., Du, J., Joshi, M., & Chen, D. et al. (2019). RoBERTa: A Robustly Optimized BERT Pretraining Approach. Meta AI. https://arxiv.org/abs/1907.11692
MT-NLG paper Smith, S., Patwary, M., Norick, B., LeGresley, P., Rajbhandari, S., & Casper, J. et al. (2021). Using DeepSpeed and Megatron to Train Megatron-Turing NLG 530B, A Large-Scale Generative Language Model. Microsoft/NVIDIA. https://arxiv.org/abs/2201.11990
Gopher paper Rae, J., Borgeaud, S., Cai, T., Millican, K., Hoffmann, J., & Song, F. et al. (2021). Scaling Language Models: Methods, Analysis & Insights from Training Gopher. DeepMind. https://arxiv.org/abs/2112.11446
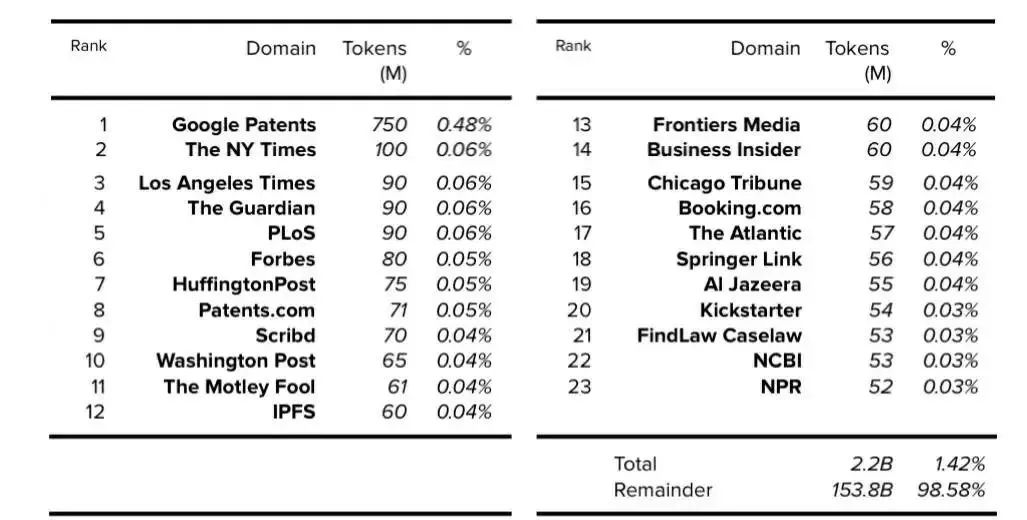
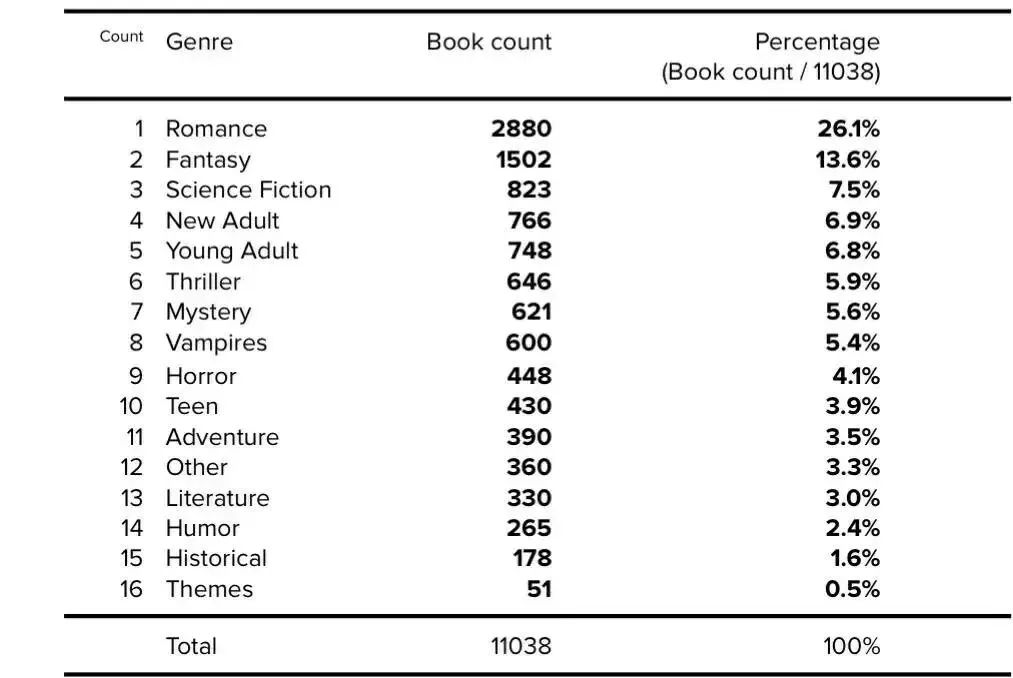
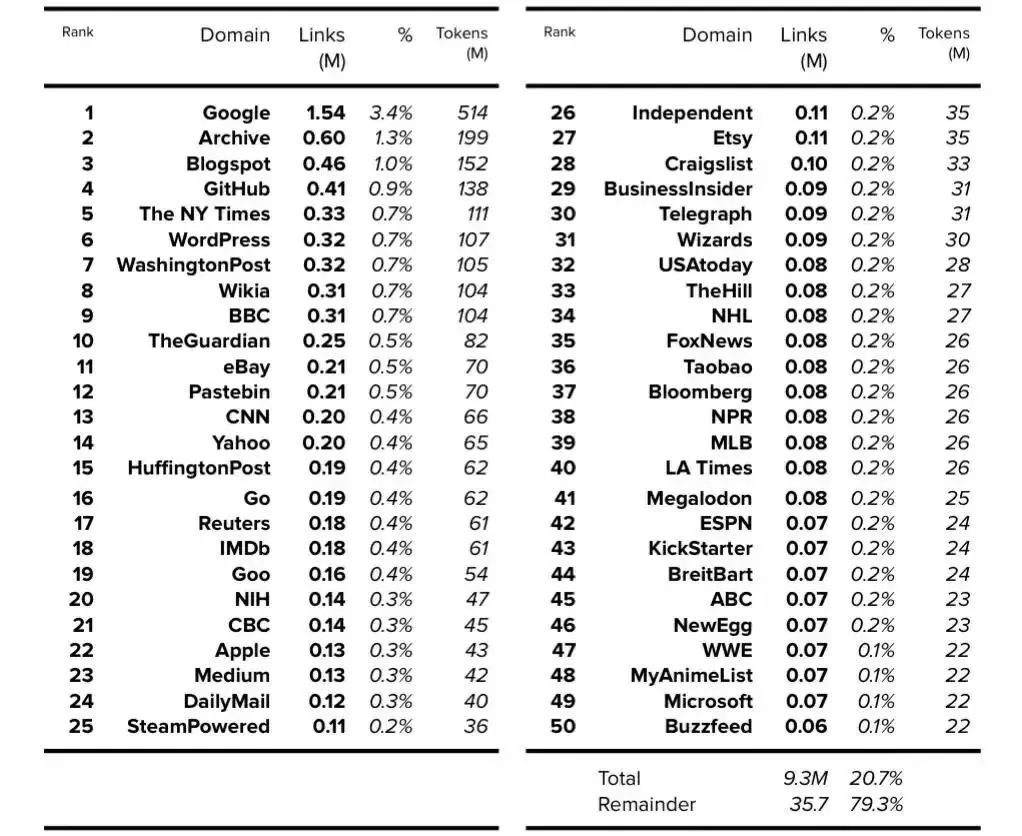
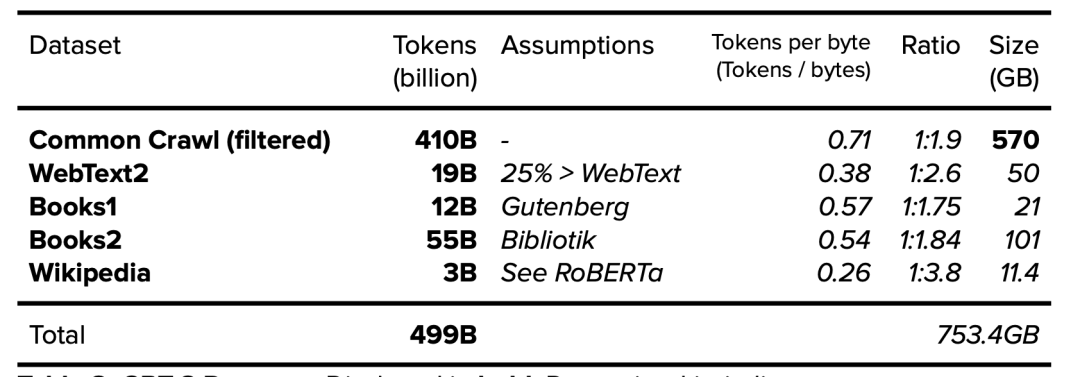
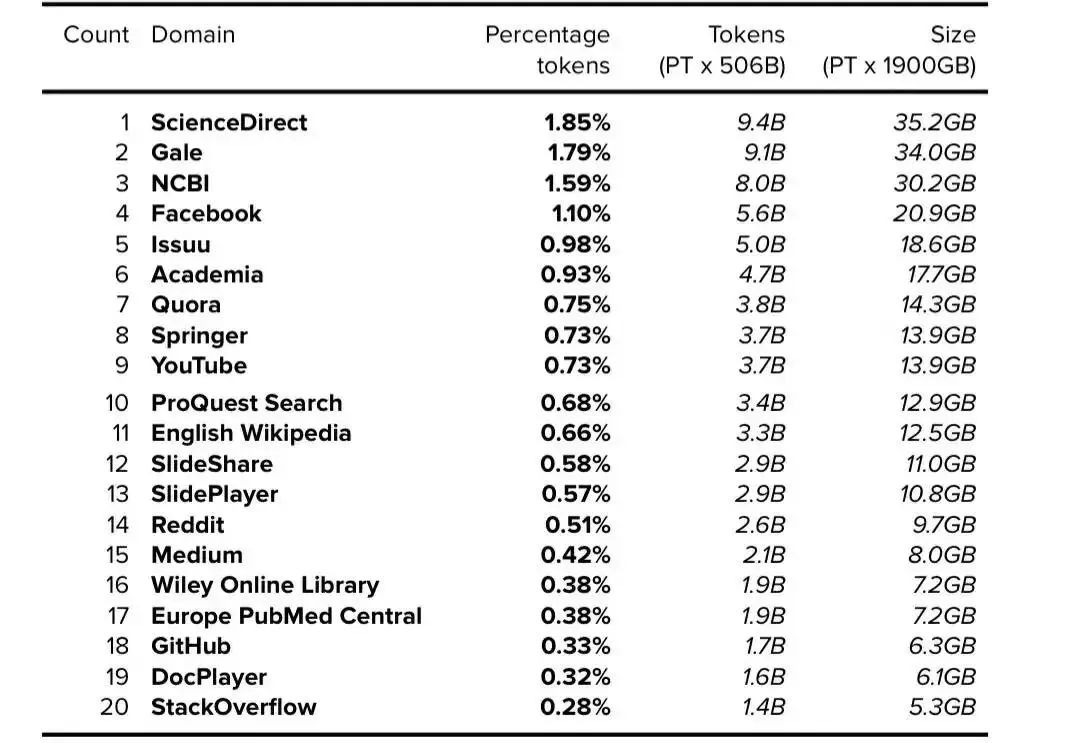
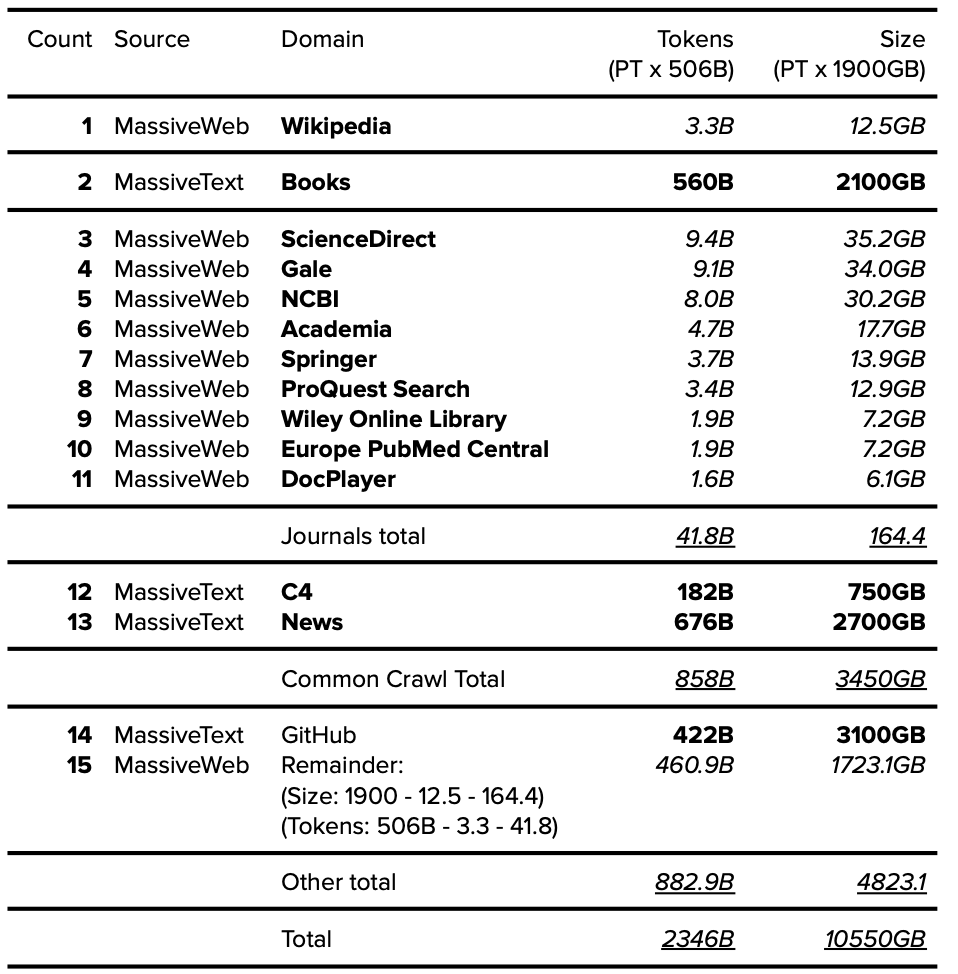
Appendix A: Top 50 Resources: Wikipedia + CC + WebText (i.e. GPT-3)
附录 A:前 50 个资源:Wikipedia + CC + WebText(即 GPT-3)
本号资料全部上传至知识星球,更多内容请登录智能计算芯知识(知识星球)星球下载全部资料。
免责申明:本号聚焦相关技术分享,内容观点不代表本号立场,可追溯内容均注明来源,发布文章若存在版权等问题,请留言联系删除,谢谢。
电子书<服务器基础知识全解(终极版)>更新完毕,知识点深度讲解,提供182页完整版下载。
服务器基础知识全解PPT(终极版)
服务器基础知识全解PDF(终极版)
温馨提示:
请搜索“AI_Architect”或“扫码”关注公众号实时掌握深度技术分享,点击“阅读原文”获取更多原创技术干货。


