



作者:陈巍 博士存算一体/GPU架构和AI专家,高级职称。中关村云计算产业联盟,中国光学工程学会专家,国际计算机学会(ACM)会员,中国计算机学会(CCF)专业会员。曾任AI企业首席科学家、存储芯片大厂3D NAND设计负责人,主要成就包括国内首个大算力可重构存算处理器产品架构(已在互联网大厂完成原型内测),首个医疗领域专用AI处理器(已落地应用),首个RISC-V/x86/ARM平台兼容的AI加速编译器(与阿里平头哥/芯来合作,已应用),国内首个3D NAND芯片架构与设计团队建立(与三星对标),国内首个嵌入式闪存编译器(与台积电对标,已平台级应用)。
本文将深入特斯拉D1处理器的整体架构和设计哲学,并结合特斯拉的专利对其进行深度分析,包括矩阵计算单元、指令集、Chiplet封装、编译生态等。
下载链接:
“机器人+” 系列:机器人研究框架(2023)
汽车芯片深度研究:汽车芯片,自动驾驶浪潮之巅
《自动驾驶芯片研究专题》
1、自动驾驶芯片研究框架(2023) 2、车载计算平台标准化需求研究报告 3、智驾芯片群雄并起,自动驾驶方兴未艾 4、智能驾驶之芯片和软件领域梳理 5、自动驾驶芯片行业研究报告
特斯拉展示了机器人在办公室周围“工作”的视频。名为擎天柱的机器人搬运物品,给植物浇水,甚至自主的在工厂工作了一段时间。”我们的目标是尽快制造出有用的人形机器人”,特斯拉表明,他们的目标是让机器人的价格低于 2 万美元,或者比特斯拉的电动汽车便宜。
特斯拉机器人之所以这么强,除了特斯拉本身在AI技术的积累外,更主要得益于特斯拉强劲的自研AI芯片。这颗AI芯片,不是传统上的CPU,更不是GPU,是一种更适合复杂AI计算的形态。
D1处理器与其他自动驾驶/机器人处理器的对比
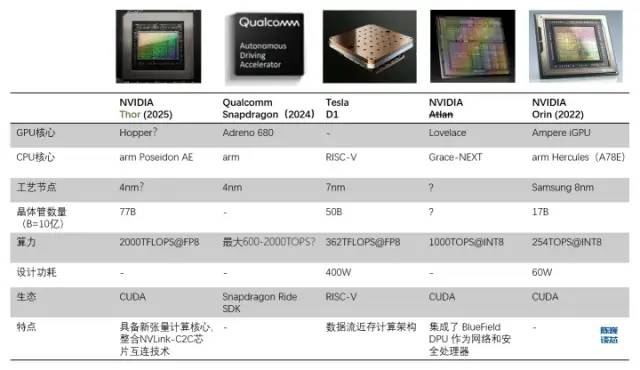
特斯拉打造自有芯片的原因是,GPU 并不是专门为处理深度学习训练而设计的,这使得GPU在计算任务中的效率相对较低。特斯拉与 Dojo(Dojo既是训练模组的名称,又是内核架构名称) 的目标是“实现最佳的 AI 训练性能。启用更大、更复杂的神经网络模型,实现高能效且经济高效的计算。” 特斯拉的标准是制造一台比其他任何计算机都更擅长人工智能计算的计算机,从而他们将来不需要再使用 GPU。
构建超级计算机一个关键点是如何在扩展计算能力同时保持高带宽(困难)和低延迟(非常困难)。特斯拉给出的解决方案是强大的芯片和独特的网格结构组成的分布式 2D 架构(平面),或者说是数据流近存计算架构。
特斯拉算力单元的层级划分
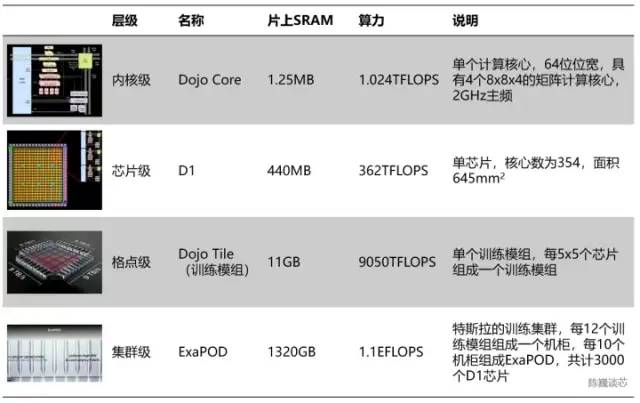
按照层次划分的话,每354个Dojo核心组成一块D1芯片,而每25颗芯片组成一个训练模组。最后120个训练模组组成一组ExaPOD计算集群,共计3000颗D1芯片。
一个特斯拉Dojo芯片训练模组可以达到6组GPU服务器的性能,成本却少于单组GPU服务器。单台Dojo服务器算力甚至达到了54PFLOPS。只用 4 个 Dojo 机柜就能取代由 4000 颗 GPU 组成的 72 组 GPU 机架。Dojo 将通常需要几个月的AI计算(训练)工作减少到了1 周。这样的“大算力出奇迹”,与特斯拉自动驾驶的风格一脉相承。显然芯片也会大大加速特斯拉AI技术的进步速度。
当然,这一芯片模组还没有到达“完美”的程度,尽管采用了数据流近存计算的思路,其算力能效比并没有超过GPU。单个服务器的功耗巨大,电流达到了2000A,需要特殊定制的电源供电。特斯拉D1芯片已经是近存计算架构的结构极限了。如果特斯拉采用“存内计算”或者“存内逻辑”架构,或许芯片性能或能效比还会有大幅度提升。

特斯拉Dojo芯片服务器由12个Dojo训练模组组成(2层,每层6个)
Dojo核心是一个8路译码的内核,具有较高吞吐量和4路矩阵计算单元(8x8)以及 1.25 MB 的本地 SRAM。但是Dojo核心的尺寸却不大,相比之下,富士通的A64FX在同一工艺节点上占据的面积是其两倍以上。
通过Dojo核心的结构,我们可以看出特斯拉在通用AI处理器上的设计哲学:
面积精简:特斯拉通过将大量计算内核集成到芯片中,以最大限度提高AI计算的吞吐量,因此需要在保障算力的情况下使单个内核的面积尽可能小,更好的折衷超算系统中算力堆叠和延迟的矛盾。
缓存与延迟精简:为了实现其区域计算效率最大化,Dojo内核以相对保守的 2 GHz 运行(保守时钟电路往往占用较少的面积),只使用基本的分支预测器和小的指令缓存,在如此精简只保留必要部件的架构下。其余面积尽可能留给向量计算和矩阵计算单元。当然,如果内核程序的代码占用量很大,或分支较多时,这种策略可能会牺牲一些性能。
功能精简:通过削减对运行内部计算不是必须的处理器功能来进一步减少功耗和面积使用。Dojo核心不进行数据端缓存,不支持虚拟内存,也不支持精确异常。
对于特斯拉和马斯克而言,Dojo不仅仅形状布局像道场,其设计哲学也与道场的精神息息相关,充分体现了“少即是多”的处理器设计美学。
我们先来看看每个Dojo的结构和特点。
每个Dojo核心是带有向量计算/矩阵计算能力的处理器,具有完整的取指、译码、执行部件。Dojo核心具有类似CPU的 风格,似乎比GPU 更能适应不同的算法和分支代码。D1的指令集类似于 RISC-V,处理器运行在2GHz,具有4组8x8矩阵乘法计算单元。同时具有一组自定义向量指令,专注于加速AI计算。
对RISC-V领域熟悉的大概能看出,特斯拉Dojo架构图的配色方案像是在致敬伯克利的BOOM处理器架构图,上黄中绿下紫。
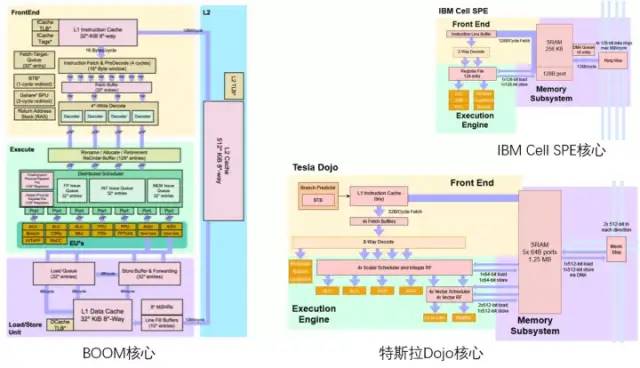
特斯拉Dojo核心与伯克利BOOM/ IBM Cell核心对比
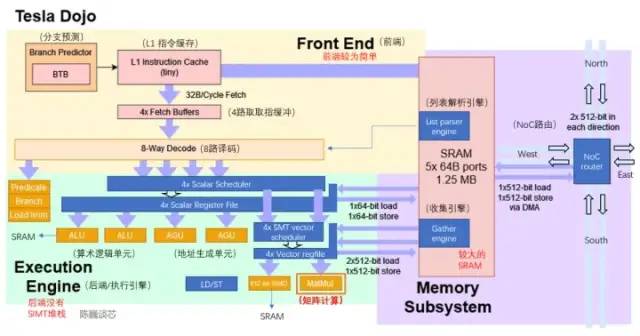
D1核心结构(蓝色部分为添加/修改的细节)
从目前的架构图来看,Dojo核心由前端、执行单元、SRAM和NoC路由4部分组成,比CPU和GPU的控制部件都更少,具有类似CPU的AGU和思路类似GPU张量核心(Tensor core)的矩阵计算单元。
Dojo核心结构比BOOM更加精简,没有Rename这些改善执行部件利用率的组件,同时也难于支持虚拟内存。但这样设计的好处是减少了控制部分占用的面积,可以把芯片上更多的面积划分给计算执行单元。每个Dojo核心提供了1.024TFLOPS的算力。可以看到,每个几乎所有的算力都由矩阵计算单元提供。因而矩阵计算单元和SRAM共同决定了D1处理器的计算能效比。
Dojo核心的主要参数

分支预测:相对GPU这类SIMT架构,Dojo核心也没有SIMT堆栈核心来进行多线程分支任务的分配。但Dojo核心具有 BTB(分支目标缓冲区),因此D1可以通过简单的分支预测来提升性能。
BTB将分支成功的分支指令的地址和它的分支目标地址都放到一个缓冲区中保存起来,缓冲区以分支指令的地址作为标识。可以通过预测分支的路径和缓存分支使用的信息来减少流水线处理器中分支的性能损失。
指令缓存:较小的L1指令缓存直接与核心中的SRAM相连获取计算指令。
取指:每个Dojo内核具有 32 B 的取指窗口,最多可容纳 8 条指令。
译码:一个8路解码器每个周期可以处理两个线程。译码阶段从取指缓冲获取指令并译码,并根据每条指令的要求分配必要的执行资源。
线程调度:在较宽的8路译码之后,则是向量的调度器(Scheduler)和寄存器堆(Register File)。貌似这里没有分支聚合的掩码判断,实际的分支执行效率可能会比GPU略低。希望特斯拉有一个强大的编译器吧。
执行单元:具有2路ALU和2路AGU,以及针对向量/矩阵计算的512位SIMD和矩阵计算单元(分别执行512位向量计算和4路8x8矩阵乘法)。其中矩阵计算单元是D1芯片的算力主体。(在下一节具体介绍)
ALU和AGU主要负责矩阵计算之外的少量逻辑计算。其中AGU是地址生成单元,主要用于生成操作SRAM所需的地址和访问其他核心的地址。通过由与 CPU 的其余部分并行运行地址计算。
普通CPU 在执行各种操作时,需要计算从内存(或SRAM)中取数据所需的内存地址。例如,必须先计算数组元素的内存位置,然后 CPU内核才能从实际内存位置获取数据。这些地址生成计算涉及不同的整数算术运算,例如加法、减法、模运算或位移。计算内存地址可以编译多个通用机器指令,也可以类似特斯拉Dojo这样通过AGU的硬件电路直接执行。这样各种地址生成计算可以从ALU卸载,减少执行AI计算所需等待的CPU 周期数,从而提高计算性能。
SIMD主要负责激活等特殊功能计算和数据的累加。
矩阵计算单元是Dojo的主要算力原件,负责二维矩阵计算,进而实现卷积、Transformer等计算。
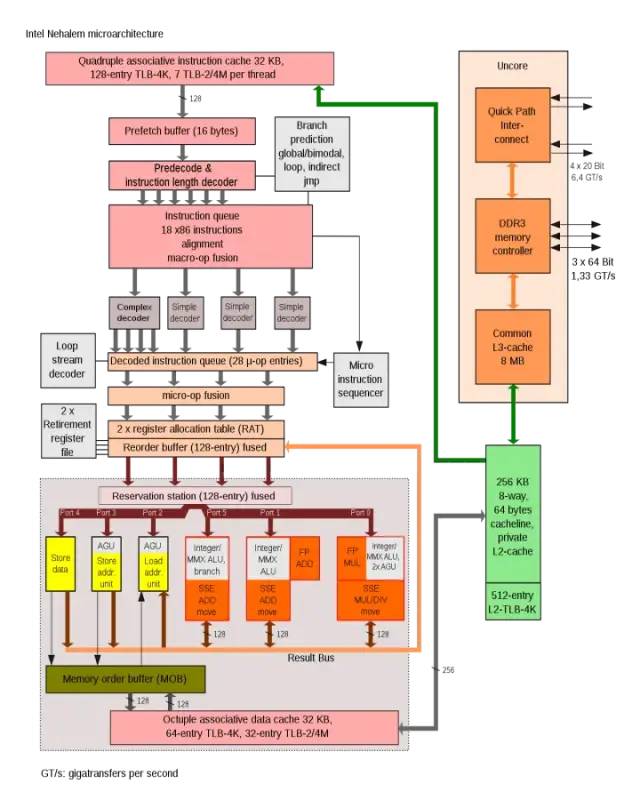
Intel Nehalem架构中使用AGU来提升单周期地址访问效率
Dojo内核的连接方式比较像 IBM 的 Cell处理器中的SPE内核连接方式。主要的相似点包括:
D1或 SPE 上运行的代码都不能直接访问系统内存,应用程序主要在本地 SRAM 中工作;
如果需要来自主存储器(DDR或HBM)的数据,须使用 DMA 操作进行读入
D1 和 Cell 的 SPE 都不支持虚拟内存。
下面将介绍计算与矩阵乘法模块与内核的存储。
Dojo架构算力增强的核心是矩阵计算单元。矩阵计算单元与核心SRAM的数据交互构成了主要的内核数据搬运功耗。
特斯拉矩阵计算单元相应的专利如下图。该模块关键部件是一个8x8矩阵-矩阵乘法单元(图中称为矩阵计算器)。输入为数据输入阵列和权重输入阵列,计算矩阵乘法后直接在输出进行累加。每个Dojo核心包括4路8x8矩阵乘法单元。
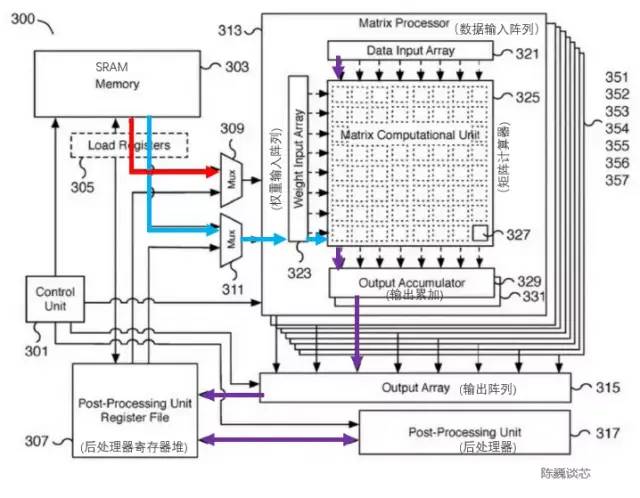
特斯拉矩阵计算单元专利
由于架构图上只有一个L1 缓存和SRAM,大胆猜测特斯拉精简了RISC-V的缓存结构,目的是节约缓存面积并减少延迟。每个核心1.25MB的SRAM块可以为SIMD和矩阵计算单元提供2x512位的读(对应AI计算的权重和数据)和512位的写带宽,以及面向整数寄存器堆的64位读写能力。计算的主要数据流是从SRAM到SIMD和矩阵乘法单元。
矩阵计算单元的主要处理流程为:
通过多路选择器(Mux)从SRAM中加载权重到权重输入阵列(Weight input array),同时SRAM中加载数据到数据输入阵列(Data input array)。
输入的数据与权重在矩阵计算器(Matrix computation Unit)中进行乘法计算(内积或外积?)
乘法计算结果输出到输出累加(Output accumulator)中进行累加。这里计算时可以通过矩阵划分拼接的方式进行超过8x8的矩阵计算。
累加后的输出传入后处理器寄存器堆进行缓存,随后进行后处理(可执行例如激活、池化、Padding等操作)。
整个计算流程由控制单元(Control unit)直接控制,无需CPU干预。
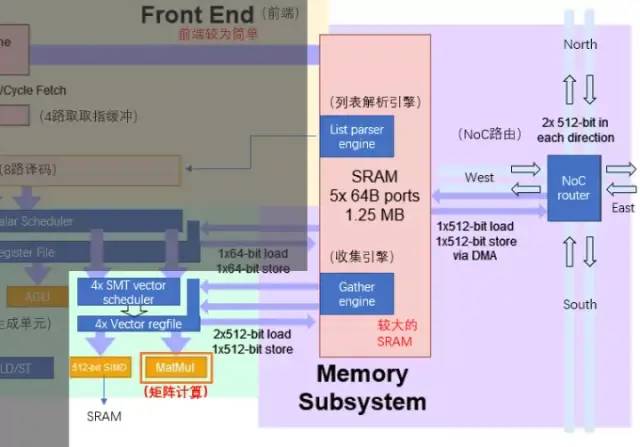
执行单元与SRAM/NoC的数据交互
Dojo核心内的SRAM具有非常大的读写带宽,可以以 400 GB/秒的速度加载并以 270 GB/秒的速度写入。Dojo核心指令集具有专用的网络传输指令,通过NoC路由,可以直接将数据移入或移出 D1 芯片中甚至Dojo训练模块中其他内核的SRAM 存储器。
与普通的SRAM不同,Dojo的SRAM包括列表解析引擎(list parser engine)和一个收集引擎(gather engine)。列表解析功能是 D1芯片的关键特性之一,通过列表解析引擎可以将复杂的不同数据类型的传输序列进行打包,提升传输效率。
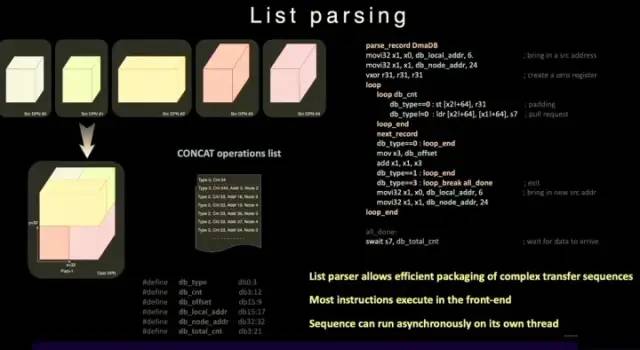
列表解析功能
为了进一步减少操作延迟、面积和复杂度,D1 并不支持虚拟内存。在通常的处理器中,程序使用的内存地址不是直接访问物理内存地址,而是由 CPU 使用操作系统设置的分页结构转换为物理地址。
在 D1内核中, 4 路 SMT 功能让计算具备显式并行性,简化 AGU 和寻址计算方式,以让特斯拉以足够低的延迟访问 SRAM,其优势是可避免中间L1 数据缓存的延迟。

D1处理器指令集
D1参考了RISC-V 架构的指令,并且自定义了一些指令,特别是矢量计算相关的指令。
D1指令集支持 64 位标量指令和 64字节 SIMD 指令,网络传输与同步原语和机器学习/深度学习相关的专用原语(例如8x8矩阵计算)。
在网络数据传输和同步原语方面,支持从本地存储(SRAM)到远程存储传输数据的指令原语(Primitives),以及信号量(Semaphore)和屏障约束( Barrier constraints)。这可以使D1支持多线程,其存储操作指令可以在多个 D1 内核中运行。
针对机器学习和深度学习,特斯拉定义了包括 shuffle、transpose 和 convert 等数学操作的指令,以及随机舍入( stochastic rounding ),padding相关的指令。
D1核心具备FP32和FP16这两个标准的计算格式,同时还具备更适合Inference的BFP16格式。为了达到混合精度计算提升性能的目的, D1还采用了用于较低精度和更高吞吐量的 8 位 CFP8 格式。
采用CFP8的优势在于可以节约更多的乘法器空间实现几乎同样的算力,这对提升D1的算力密度非常有帮助。
Dojo 编译器可以在尾数精度附近滑动,以涵盖更广泛的范围和精度。在任何给定时间,最多可以使用 16 种不同的矢量格式,灵活提升算力。

D1处理器的数据格式
根据特斯拉提供的信息,在矩阵乘法单元内部可使用CFP8来进行计算(存储为CFP16格式)。
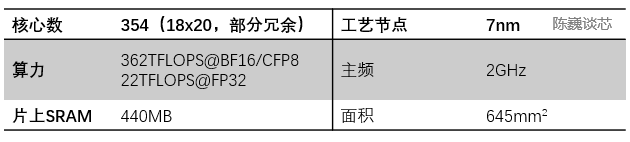
D1处理器由台积电制造,采用7纳米制造工艺,拥有500亿个晶体管,芯片面积为645mm²,小于英伟达的A100(826 mm²)和AMD Arcturus(750 mm²)。

D1处理器结构
每个D1处理器由 18 x 20 的Dojo核心拼接构成。每个D1处理器中有354个Dojo核心可用。(之所以只使用360个核心中的354个是出于良率和每处理器核心稳定考虑)由台积电制造,采用7nm制造工艺,拥有500亿个晶体管,芯片面积为645mm²。
每个Dojo核心有一块1.25MB的SRAM作为主要的权重和数据存储。不同的Dojo核心通过片上网络路由(NoC路由)进行连接,不同的Dojo内核通过复杂的NoC网络进行数据同步,而不是共享数据缓存。NoC 可以处理跨节点边界4个方向(东南西北)的 8 个数据包,每个方向 64 B/每个时钟周期,即在所有四个方向上一个数据包输入和一个数据包输出到网格中每个相邻的Dojo核心。该NoC路由还可以在每个周期对核心内的 SRAM 进行一次 64 B 双向读写。
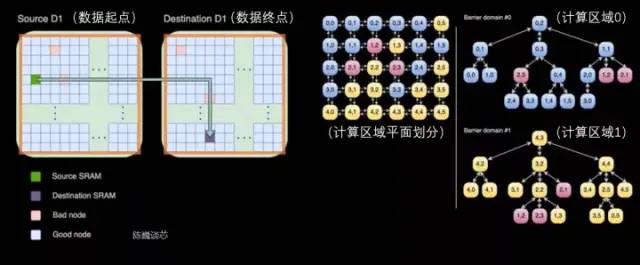
跨处理器传输和D1处理器内部的任务划分
每个Dojo核心都是一个相对完整的带矩阵计算能力的类CPU(由于每个核心具备单独的矩阵计算单元,且前端相对较小,所以这里称为类CPU)其数据流架构则有点类似于SambaNova的二维数据流网格结构,数据直接在各个处理核心之间流转,无需回到内存。
D1芯片运行在2GHz,拥有巨大的440MB SRAM。特斯拉将设计重心放在计算网格中的分布式SRAM,通过大量更快更近的片上存储和片上存储之间的流转减少对内存的访问频度,来提升整个系统的性能,具有明显的数据流存算一体架构(数据流近存计算)特征。
每颗D1 芯片有 576 个双向 SerDes 通道,分布在四周,可连接到其他 D1 芯片,单边带宽为 4 TB/秒。
D1处理器芯片主要参数
每个D1训练模块由5x5的 D1芯片阵列排布而成,以二维Mesh结构互连。片上跨内核SRAM达到惊人的11GB,当然耗电量也达到了15kW的惊人指标。能效比为0.6TFLOPS/W@BF16/CFP8。(希望是我算错了,否则这个能效比确实不是太理想)。外部32GB共享HBM内存。(HBM2e或HBM3)
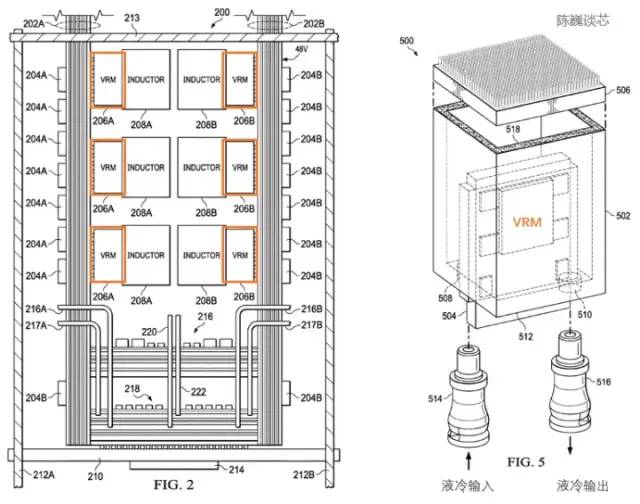
特斯拉D1处理器的散热结构专利
特斯拉使用了专用的电源调节模块(VRM)和散热结构来进行功耗管理。在这里功耗管理的主要目的有2个:
减少不必要的功耗损失,提升能效比。
减少散热形变造成的处理器模组失效。
根据特斯拉的专利,我们可以看到电源调节模块与芯片本身垂直,极大的减少了对处理器平面的面积占用,且可以通过液冷来迅速平衡处理器的温度。
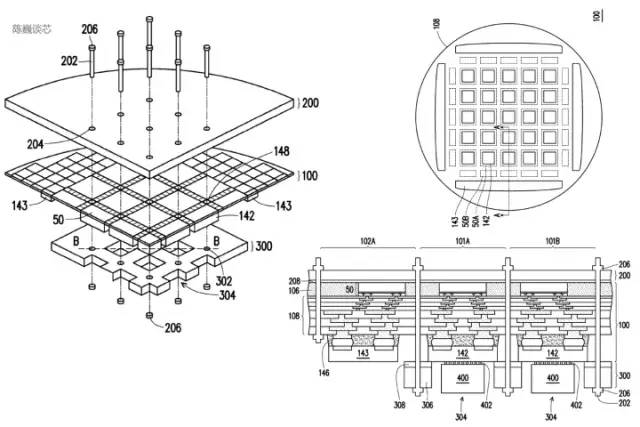
特斯拉D1处理器的散热和封装结构专利
训练模组在封装上采用InFO_SoW(Silicon on Wafer)封装来提高芯片间的互连密度。该封装除了TSMC的INFO_SoW技术之外,也采用了特斯拉自己的机械封装结构,以减小处理器模组的失效。
每个训练模块外部边缘的 40 个 I/O 芯片达到了 36 TB/s的聚合带宽,或者10TB/s的横跨带宽。每层训练模块都连接着超高速存储系统:640GB 运行内存可以提供超过 18TB/s的带宽,另外还有超过 1TB/s的网络交换带宽。
数据传输方向与芯片平面平行,供电及液冷方向与芯片平面垂直。这是一个非常优美的结构设计,不同的训练模块之间还可以互连。通过立体结构,节约了芯片模组的供电面积,尽可能减少计算芯片间的距离。
一个 Dojo POD 机柜由两层计算托盘和存储系统组成。每一层托盘都有 6 个 D1 训练模组。两层共 12个训练模组组成的一个机柜,可提供 108PFLOPS 的深度学习算力。

Dojo模组与Dojo POD机柜
超算平台的散热,一直是衡量超算系统水平的重要维度。
D1 芯片的热设计功率 (TDP) 为 400 W。将 25 颗 D1 芯片紧密封装成为一个训练模组,仅处理器TDP就可能高达 10 kW。在如此之高密度的计算芯片矩阵环境下,综合考虑散热和电力传输,特斯拉需要为D1芯片提供全新的方案。
特斯拉在 Dojo POD 上使用了全自研的 VRM(电压调节模组),单个 VRM可以在不足 25 美分硬币面积的电路上,提供52V电压和超过 1000A 的巨大电流,电流目的为0.86A每平方毫米,共计12个独立供电相位。
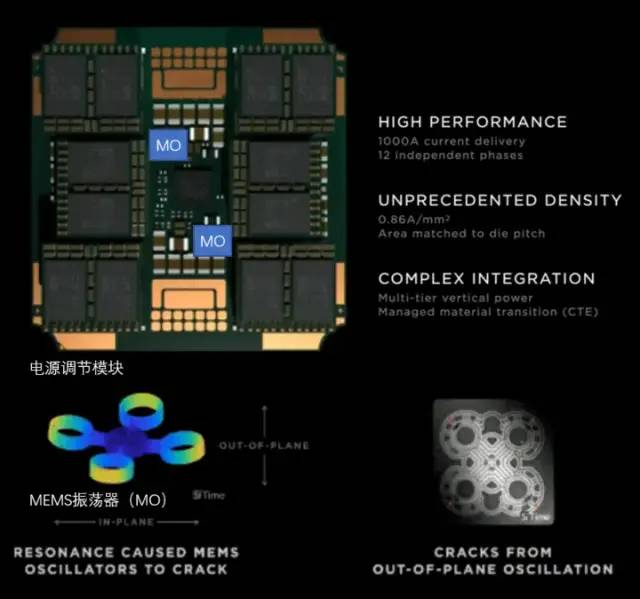
特斯拉的电源调节模组
对高密度芯片散热而言,其重点是控制热膨胀系数(CTE)。Dojo系统的芯片密度极高,如果CTE稍微失控,都可能导致结构变形/失效,进而出现连接故障。
特斯拉这套自研 VRM 在过去2年内迭代了 14 个版本,采用了MEMS振荡器(MO)来感知电源调节模组的热形变,最终才完全符合内部对 CTE 指标的要求。这种通过MEMS技术主动调节电源功率的方式,与控制火箭箭身振动的主动调节方式类似。
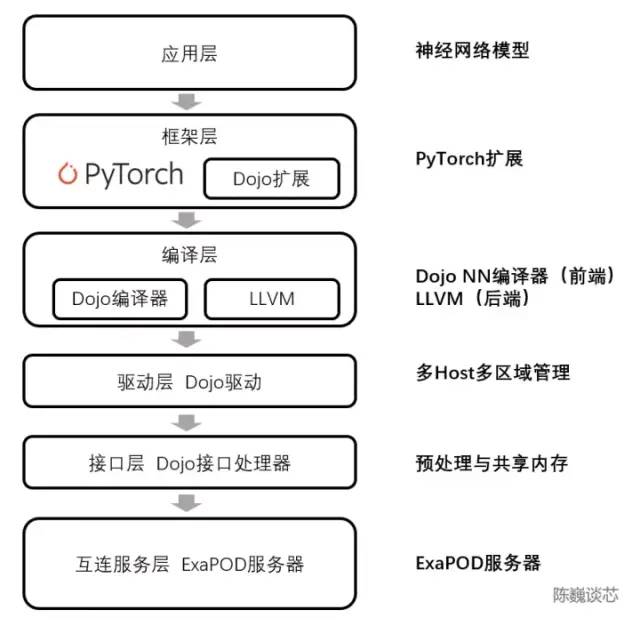
D1处理器软件栈
对于D1这类AI芯片来说,编译生态的重要性不低于芯片本身。
在D1处理器平面上,D1被划分为矩阵式的计算单元。编译工具链负责任务的划分和配置数据存储,并且通过多种方式进行细粒度的并行计算,并减少存储占用。
Dojo编译器支持的并行方式包括数据并行、模型并行和图并行。支持的存储分配方式包括分布式张量、重算分配和分割填充。
编译器本身可以处理各种CPU中常用的动态控制流,包括循环和图优化算法。借助Dojo编译器,用户可将Dojo大型分布式系统视作一个加速器进行整体设计和训练。
整个软件生态的顶层基于PyTorch,底层基于Dojo驱动,中间使用Dojo编译器和LLVM形成编译层。这里加入LLVM后,可以使特斯拉更好的利用LLVM上已有的各种编译生态进行编译优化。
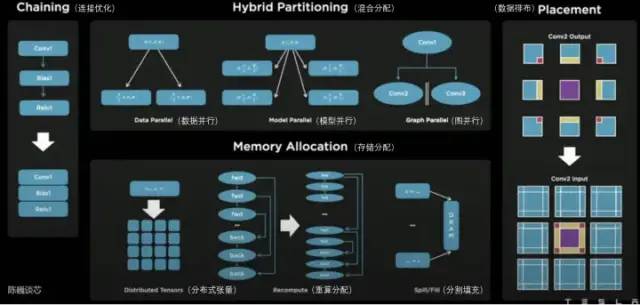
特斯拉Dojo 编译器
通过特斯拉AI日,我们看到了特斯拉机器人的真身,并且对其强大的“内芯”有了更多的认识。
特斯拉的Dojo核心与以往的CPU和GPU架构特点都有差别,可以说是结合了CPU特点的精简GPU,相信其在编译上也会与CPU和GPU有较大的差异。为了提升计算密度,特斯拉做了极致精简的优化,并且提供了主动调节的电源管理机制。
服务器基础知识全解PPT(终极版)
服务器基础知识全解PDF(终极版)


