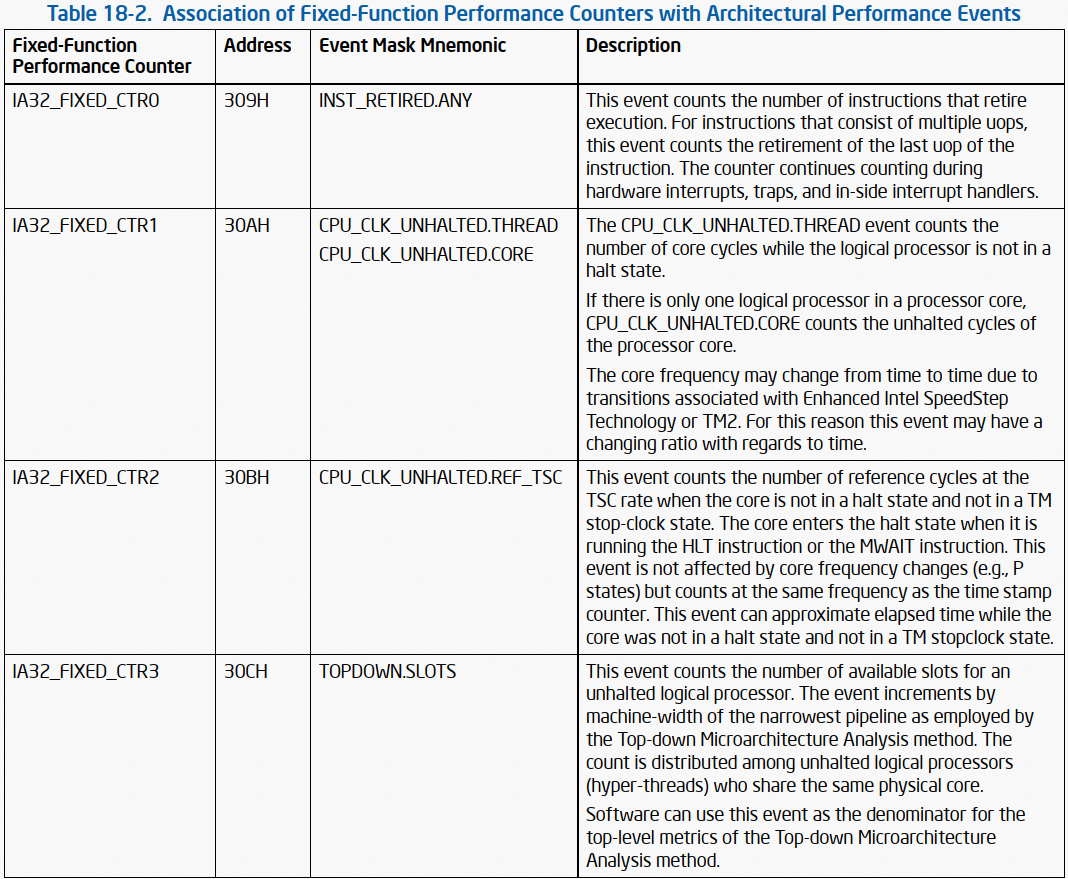
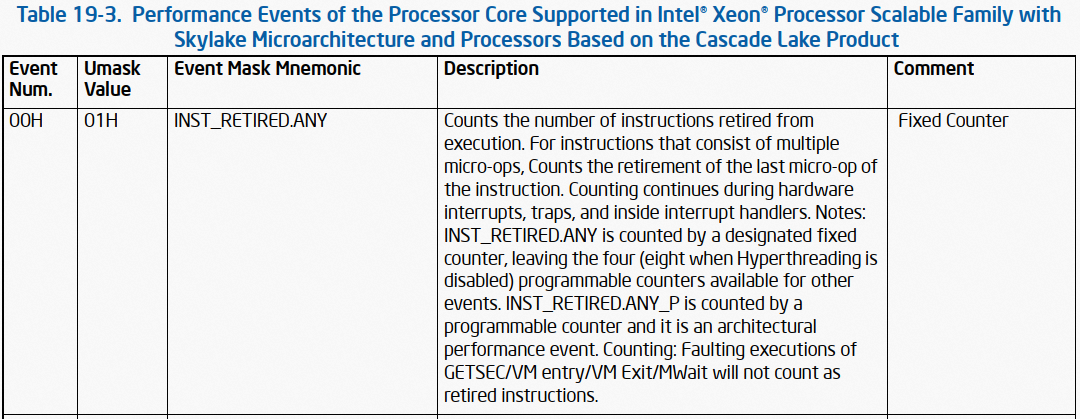
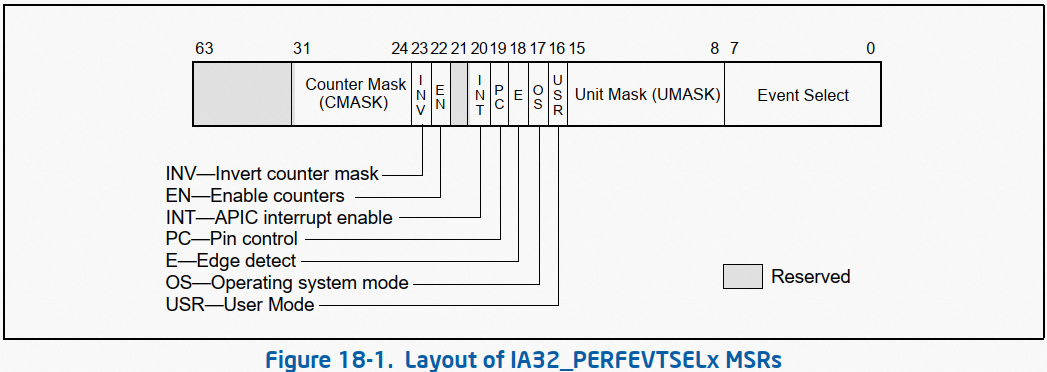
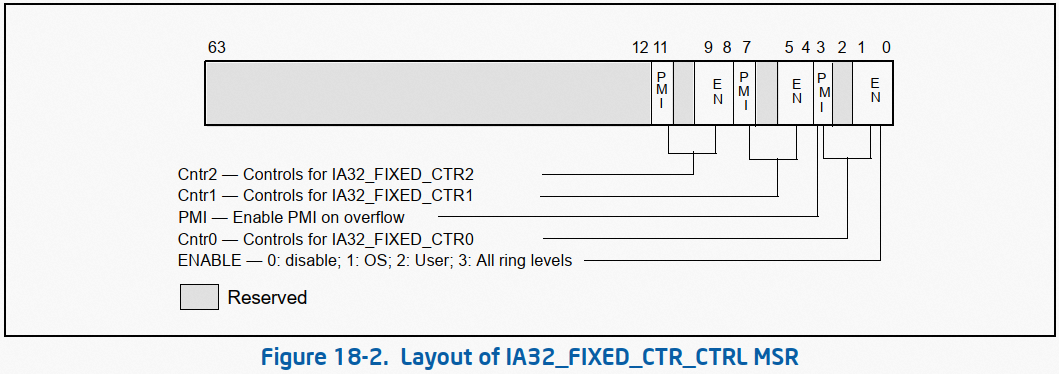
随着数字化的不断推进,LED显示屏行业对4K、8K等超高清画质的需求日益提升。与此同时,Mini及Micro LED技术的日益成熟,推动了间距小于1.2 Pitch的Mini、Micro LED显示屏的快速发展。这类显示屏不仅画质卓越,而且尺寸适中,通常在110至1000英寸之间,非常适合应用于电影院、监控中心、大型会议、以及电影拍摄等多种室内场景。鉴于室内LED显示屏与用户距离较近,因此对于噪音控制、体积小型化、冗余备份能力及电气安全性的要求尤为严格。为满足这一市场需求,开关电源技术推出了专为
晶台光耦
2025-01-13 10:42
524浏览