目前,用于自动驾驶汽车研究的视觉传感系统,通常能感知到车辆前方250米以内的周围环境。然而,当物体的位置超过50米时,检测的可靠性就会下降,这是由于物体稀疏或不清楚,检测模型无法做出有把握的检测。协同感知扩展了车载传感系统的视界,扩大了传感范围,提高了探测精度。本文通过使用Carla模拟器创建一个多车辆数据集来探索早期的分布式视觉数据融合,创建一个共享的驾驶场景,为每一个生成的车辆配备LiDAR、GNSS和IMU传感器来模拟一个真实的驾驶场景。此外,我们研究了基于ZeroMQ的通信系统的使用情况,以在相关的相邻车辆之间分发视觉和元数据。由于所提出的方法分发原始LiDAR数据,我们利用点云压缩来减少相关连接车辆之间公布的数据大小,以满足通信带宽要求。随后,我们对收到的数据进行转换和融合,并应用深度学习物体检测模型来检测场景中的物体。实验证明,我们提出的框架在满足带宽要求的同时提高了检测的平均精度。
对复杂驾驶环境的态势感知对于自主导航的安全至关重要。随着使用深度学习的计算机视觉的最新发展,单车感知系统的鲁棒性在物体检测等任务上有了明显的改善[1], [2], [3]。尽管取得了这些进展,但仍有一些公开的挑战;例如,由于单一的感知视角,视野有限,导致无法检测到严重遮挡或较远的物体。这反过来又会导致灾难性的后果,影响自主导航的可靠性和安全性。
此外,当一个传感器由于断开连接或其内部硬件的故障而失效时,代理将无法对其周围的情况有所了解;因此,解决这个问题的方法是将代理连接起来。如果车辆配备了传输/接收来自邻近行为体的信息并融合/利用收到的信息,共享态势感知将为自主导航提供超人的能力。最近的研究[4]-[6],提出了视觉数据共享的好处,以避免危急情况,提高交通安全和减少死亡,因为它提高了检测对象的精度和可信度。
协同驾驶的性能取决于共享数据的类型、网络带宽和数据融合方法;所有这些都构成了需要解决的挑战。
一方面,早期视觉数据融合算法融合原始数据更有利[6],因为与后期融合方法相比,数据包含更多的上下文信息,融合其他相邻车辆的输出预测。在后期融合中,预测依赖于单一的车辆传感器和探测器,这只有在两辆车在探测中共享一个参考物体时才会起作用;此外,它并没有解决以前未被检测到的对象的问题,即使在融合[6]之后,这些对象仍然无法被检测到。
另一方面,车辆网络的带宽和延迟要求必须满足协同感知[7]的数据传输,以动态地融合驾驶场景的变化;然而,共享所有收集的数据和原始视觉数据会导致高延迟,因为它们的大小。
为了训练检测模型和评估自主车辆的检测精度,可用的数据集,如KITTI[8]和NuScenes[9]是著名的视觉基准数据集。然而,由于KITTI和NuScenes的数据是从一架飞行器上收集的。
因此,这些数据集只适用于特定的测试场景,如自我车辆对象检测,在分布式感知框架中使用不现实。同样,部署多辆带有视觉传感器的汽车来记录适合合作感知算法基准测试的大规模数据集,在逻辑上是昂贵且耗时的。考虑到上述问题和挑战,在这项工作中,我们旨在:
• 调查使用不同量化参数来压缩点云的性能。
• 使用ZeroMQ共享相关数据。
• 对原始点云进行转换和融合,然后进行物体检测。
• 建立一个大规模的多车数据集来评估所提出的方法。
为了满足延迟和网络带宽的要求,我们利用Draco压缩算法[10]来减少点云的大小,然后再发布。Draco压缩框架经常被用作基准算法[11],由于其计算复杂度低,导致压缩时间快。在[12]中提出的工作表明,使用Draco的压缩点云在进行越来越多的有损压缩时保持了合理的视觉质量。
从车辆的传感器中获取的视觉和位置数据将被共享给其他相关的车辆,以实现共享态势感知;这项工作利用ZeroMQ进行数据共享。数据共享部分分为两部分;1)REQ- ROUTER和 2)发布-订阅,如图1所示。
集中式服务器采用REQ-ROUTER模式工作,每个车辆将其GNSS、IMU数据、IP地址、发布端口和主题作为请求发送给服务器,然后服务器存储这些数据,并为每个车辆创建一个独特的ID。之后,包含相关度量的服务被初始化,以计算请求车辆与其他车辆的空间相关度。为了实现这一目标,我们创建了一个服务来计算车辆之间的相关度。相关性指标是基于车辆和航向之间的距离,如图2所示。
利用所有车辆的GPS坐标,相关性服务计算出哪些其他车辆位于请求车辆的一定半径内,以及这两辆车是否有一个相交的方向,如图2所示。随后,服务器用相关的客户端ID回复请求的车辆。第二部分利用发布-订阅模式,使车辆能够订阅其他相关车辆(使用收到的客户端ID),以便在其数据可用时立即订阅,如图1所示。在订阅和接收相关车辆的数据后,这些数据就会与自我的车辆数据融合。
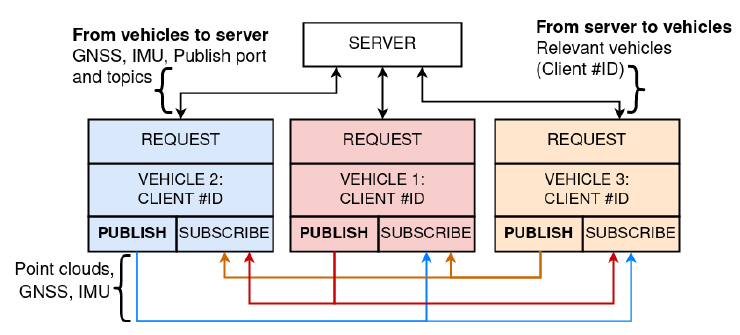
图1:数据共享方案,由REQ-ROUTER和发布订阅模式组成。
从其他邻近车辆接收到的点云应该被重建并转化为自我车辆的姿态,因为它是从环境中的姿态捕获的。我们通过采用点对平面ICP(迭代最接近点)登记[13]来找到自我和发送方点云之间的最佳转换矩阵,然后用它来对齐两个点云。
因此,对齐的点云被连接并馈送到预训练的3D目标检测模型中以执行3D目标检测。在这项工作中,我们使用PIXOR[2]探测器,因为它是一种单级、无提议、密集的3D物体探测器。PIXOR由两个网络组成:1)Backbone和2)Header。主干由卷积层和池化层组成,卷积层提取输入特征的过完整表示,池化层对特征映射大小进行低采样,以节省计算并帮助创建更稳健的表示。
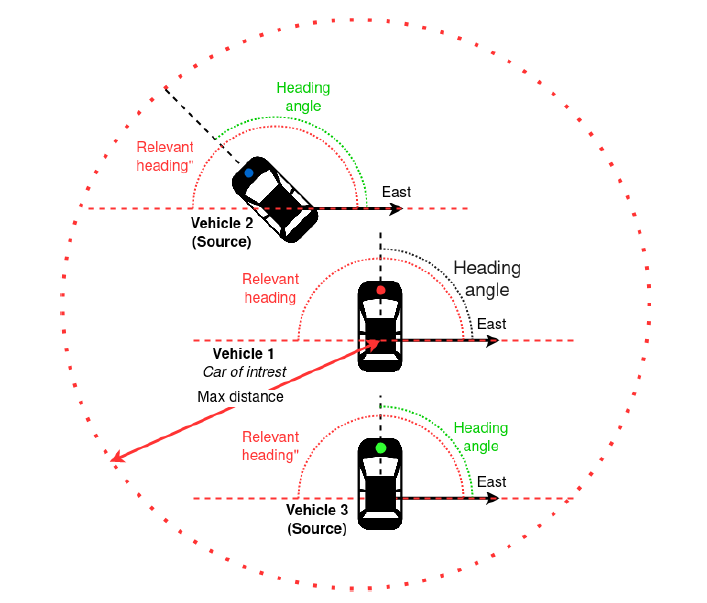 图2:基于感兴趣的车辆和其他相邻车辆之间的距离和相关度量的计算。
图2:基于感兴趣的车辆和其他相邻车辆之间的距离和相关度量的计算。
III.结果与讨论
为了创建分布式感知数据集,我们利用Carla模拟器[14]。我们利用Carla的多代理功能来生成多辆车,每辆车都配备了LiDAR来感知环境,GPS和IMU来检索车辆的姿势和位置。我们建议使用LiDAR传感器,因为点云比二维图像具有空间维度,而且它在融合过程中具有多功能性,因为点云数据是由点而不是像素组成的。
此外,图像融合需要一个明确的重叠区,而这对于点云来说是不必要的,这使得它在融合从不同地点捕获的数据时更加稳健。Carla内置的LiDAR传感器是基于光线投射的,我们将LiDAR的属性定义为Velodyne HDL-64E,产生250k点/秒,水平视场为360°,频率为10Hz,与技术规范相匹配。使用的GPS和IMU是Carla的内置对象,我们利用了Carla定义的默认设置属性。在每次LiDAR扫描时,都会检索并保存邻近行动者的地面真实边界框和类别标签。
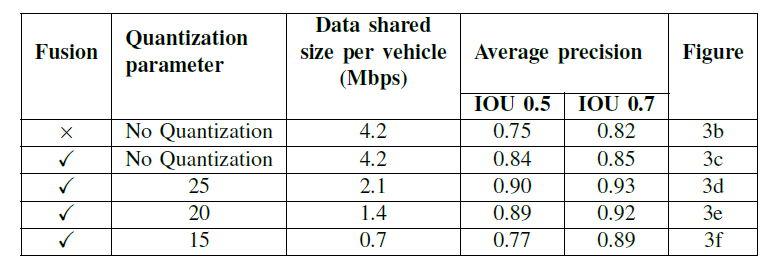
我们根据现有的通信协议[7]和与自我车辆70°的航向交叉点,将半径130米内的车辆广播的数据进行融合,并评估检测。在我们的分布式感知数据集中,我们包括完全遮挡的物体,使任务更具挑战性和现实性。对于目标检测,我们在相交-联合(IoU)阈值0.5和0.7处计算平均精度(AP)。我们评估了无融合的单车设置,无量化的早期融合,以及25、20、15的比特量化参数。

图3:(a)代表驾驶场景的BEV图像。(b)代表没有融合的BEV,(c)代表没有量化的BEV,(d)、(e)、(f)分别是量化参数为25、20、15时的物体检测。
上述五种设置场景下的检测视觉结果见图3,数值评估见表I。在实验中,我们假设绿色表示的车辆是接收其他相关车辆数据的自我车辆。从图3所示的视觉对比来看,不可否认的是,通过融合设置,可以检测到更多最初仅使用自我激光雷达遮挡的物体。
关于融合,总的来说,较低的量化参数产生了较小的点云尺寸,可以共享。将量化参数设置为20比特似乎是有损压缩的最佳中间地带,因为它在保持4.2倍的压缩率的同时仍然有一个良好的输出质量。如图3f所示,量化为15比特,结果是提高了压缩率;然而,这降低了点云的质量,导致在识别某些物体时失败。而不进行量化,则会产生最佳的AP值;但是,它分享了最大的点云尺寸。
表一: 应用不同量化参数后的点云大小和物体检测的AP评估。
IV.结论和未来工作
在本文中,我们创建了一个共享态势感知框架,该框架由以下部分组成:分布式感知数据集、点云压缩以减少尺寸以满足网络带宽,随后在接收代理处进行点云转换和融合。我们提出的共享态势感知方法在满足IEEE 802.11p专用短程通信(DSRC)要求[7]的同时,取得了显著的效果。
在未来,我们计划扩展我们的工作,包括深入分析使用PC-MSDM[15]压缩后的点云质量,以选择最佳的量化参数。我们将基于DSRC V2V通信协议IEEE 802.11p[7]计算传输时延。此外,我们将使用5G独立网络进行实际操作。
参考文献
[1] Yin Zhou and Oncel Tuzel. Voxelnet: End-to-end learning for point
cloud based 3d object detection. In Proceedings of the IEEE conference
on computer vision and pattern recognition, pages 4490–4499, 2018.
[2] Bin Yang, Wenjie Luo, and Raquel Urtasun. Pixor: Real-time 3d object
detection from point clouds. In Proceedings of the IEEE conference on
Computer Vision and Pattern Recognition, pages 7652–7660, 2018.
[3] Alex H Lang, Sourabh Vora, Holger Caesar, Lubing Zhou, Jiong Yang,
and Oscar Beijbom. Pointpillars: Fast encoders for object detection from
point clouds. In Proceedings of the IEEE/CVF Conference on Computer
Vision and PatternRecognition, pages 12697– 12705, 2019.
[4] Qi Chen, Xu Ma, Sihai Tang, JingdaGuo, Qing Yang,and Song Fu.
F-cooper: Feature based cooperative perception for autonomous vehicle
edge computing system using 3d point clouds. In Proceedings of the
4th ACM/IEEE Symposium on Edge Computing, pages 88– 100, 2019.
[5] Tsun-Hsuan Wang, Sivabalan Manivasagam, Ming Liang, Bin Yang,
Wenyuan Zeng, and Raquel Urtasun. V2vnet: Vehicle-to-vehicle com-
munication for joint perception and prediction. In European Conference
on Computer Vision, pages 605–621. Springer, 2020.
[6] Qi Chen, Sihai Tang, Qing Yang, and Song Fu. Cooper: Cooperative
perception for connected autonomous vehicles based on 3d point clouds.
In 2019 IEEE 39th International Conference on Distributed Computing
Systems (ICDCS), pages 514–524. IEEE, 2019.
[7] John B Kenney. Dedicated short-range communications (dsrc) standards
in the united states. Proceedings of the IEEE, 99(7):1162– 1182, 2011.
[8] Andreas Geiger, Philip Lenz, and Raquel Urtasun. Are we ready for
autonomous driving? the kitti vision benchmark suite. In 2012 IEEE
conference on computer vision and pattern recognition, pages 3354–
3361. IEEE, 2012.
[9] Holger Caesar, Varun Bankiti, Alex H Lang, Sourabh Vora, Venice Erin
Liong, Qiang Xu, Anush Krishnan, Yu Pan, Giancarlo Baldan, and Oscar
Beijbom. nuscenes: A multimodal dataset for autonomous driving.
In Proceedings of the IEEE/CVF conference on computer vision and
pattern recognition, pages 11621– 11631, 2020.
[10] Google. Draco: 3D Data Compression, 2018.
[11] Xuebin Sun, Sukai Wang, Miaohui Wang, Zheng Wang, and Ming Liu. A
novel coding architecture for lidar point cloud sequence. IEEE Robotics
and Automation Letters, 5(4):5637–5644, 2020.
[12] Jens de Hoog, Ahmed N Ahmed, Ali Anwar, Steven Latré, and Peter
Hellinckx. Quality-aware compression of point clouds with google
draco. In International Conference on P2P, Parallel, Grid, Cloud and
Internet Computing, pages 227–236. Springer, 2021.
[13] Szymon Rusinkiewicz and Marc Levoy. Efficient variants of the icp
algorithm. In Proceedings third international conference on 3-D digital
imaging and modeling, pages 145– 152. IEEE, 2001.
[14] Alexey Dosovitskiy, German Ros, Felipe Codevilla, Antonio Lopez,
and Vladlen Koltun. CARLA: An open urban driving simulator. In
Proceedings of the 1st Annual Conference on Robot Learning, pages
1– 16, 2017.
[15] Gabriel Meynet, Julie Digne, and Guillaume Lavoué . Pc-msdm: A
quality metric for 3d point clouds. In 2019 Eleventh International
Conference on Quality of Multimedia Experience (QoMEX), pages 1–3.
IEEE, 2019.
分享不易,恳请点个【👍】和【在看】
