

CPU% = (1 - idleTime / sysTime) * 100
idleTime:CPU处于空闲状态的时间
sysTime:CPU处于用户态和内核台的时间总和
2、CPU 使用率跟啥有关系?
常听说计算密集型的程序是比较耗 CPU 使用率的。
3、CPU 与进程、线程有关系么?
现在分时操作系统是通过循轮方式分配时间片进行进程调度的,如果进程在等待或阻塞,不会造成 CPU 资源使用。线程称为轻进程,共享进程资源,关于线程的调度,CPU 对于线程也是分时调度。而在 Java 中,线程的调用由 JVM 负责,线程的调度一般有两种模式,分时调度和抢占式调度。
4、一个 while 死循环,会不会引起 CPU 使用率飚升?
会的。
先不说别的,死循环会调用 CPU 寄存器进行计数,这个操作就会占用 CPU。其次,如果线程一直处于死循环状态,CPU 调用会进行线程切换么?
死循环不会让出 CPU,除非操作系统时间片到期,但死循环会不断向系统申请时间片,直到系统没有空闲时间做别的事情。
这个问题在 stackoverflow 也有人提问:why does an infinite loop of the unintended kind increase the CPU use?
地址:https://stackoverflow.com/questions/2846165/why-does-an-infinite-loop-of-the-unintended-kind-increase-the-cpu-use
5、频繁 Young GC 会不会引起 CPU 使用率飚升?
会的。
Young GC 本身是 JVM 进行垃圾回收的操作,会计算内存和调用寄存器,频繁 Young GC 一定是会占用 CPU。
之前有个一个案例,for 循环从数据库查询数据集合,二次封装新的数据集合,这时如果量比较大时,内存没有足够的空间存储,那么 JVM 就会 GC 回收那些不再使用的数据,因此量大的时候,就会收到 CPU 使用率报警。
6、线程数很高的应用,CPU 使用率一定高么?
不会。
通过 jstack 查看系统线程状态,查看整个线程数很多,但 Runable 和 Running 状态的线程不多,这时 CPU 使用率不一定会高。
之前有过一个案例,查看系统线程数 1000+,jstack 分析 900多个线程是 BLOCKED 和 WAITING 状态的,这种线程是不会占用 CPU 的。
如果线程数很高,其实大多数原因是死锁,大量线程处于 BLOCKED 和 WAITING 状态。
7、CPU 使用率高的应用,线程数一定高么?
不会。
同上,CPU 使用率高的关键因素还是计算密集型操作,一个线程如果有大量计算,也会造成 CPU 使用率高,也是现在为什么一个大数据脚本任务,要大规模集群共同运算才能运行的原因。
8、BLOCKED 状态的线程会不会引起 CPU 使用率飚升?
不一定。
CPU使用率的飙升,更多是因为上下文的切换或者runnable状态线程过多导致。Blocked状态,未必会引起CPU上升。
9、分时操作系统 CPU us高或者sy高是什么意思?
通过top命令,可以观察到CPU的us,sy值,示例如下:
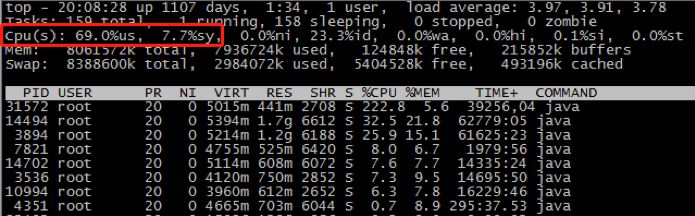
us 用户空间占用CPU百分比,简单来说,us高是因为程序导致的,通过分析线程堆栈,可以很容易的定位到问题线程。
sy 内核空间占用CPU百分比,sy高的时候,如果是程序问题导致,基本是因为线程上下文切换造成的。
CPU飙升线程定位示例:
public class cpuTest {
public static void main(String args[]){
for(int i=0;i<10;i++){
new Thread(){
public void run(){
try{
Thread.sleep(100000);
}catch(Exception e){}
}
}.start();
}
Thread t=new Thread(){
public void run(){
int i=0;
while(true){
i=(i++)/100;
}
}
};
t.setName("Busiest Thread");
t.start();
}
}
步骤1: 执行top -c ,显示进程运行信息列表,键入P (大写p),进程按照CPU使用率排序,最耗CPU的进程PID为18207
步骤2:首先我们可以通过top -Hp <pid>来看这个进程里所有线程的cpu消耗情况
$ top -Hp 18207top - 19:11:43 up 573 days, 2:43, 2 users, load average: 3.03, 3.03, 3.02Tasks: 44 total, 1 running, 43 sleeping, 0 stopped, 0 zombieCpu(s): 18.8%us, 0.0%sy, 0.0%ni, 81.1%id, 0.0%wa, 0.0%hi, 0.0%si, 0.0%stMem: 99191752k total, 98683576k used, 508176k free, 128248k buffersSwap: 1999864k total, 191064k used, 1808800k free, 17413760k cached PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND18250 admin 20 0 26.1g 28m 10m R 99.9 0.0 0:19.50 java Test18207 admin 20 0 26.1g 28m 10m S 0.0 0.0 0:00.00 java Test18208 admin 20 0 26.1g 28m 10m S 0.0 0.0 0:00.09 java Test18209 admin 20 0 26.1g 28m 10m S 0.0 0.0 0:00.00 java Test18210 admin 20 0 26.1g 28m 10m S 0.0 0.0 0:00.00 java Test18211 admin 20 0 26.1g 28m 10m S 0.0 0.0 0:00.00 java
cpu最高的线程是pid为18250的线程,占了99.9%
步骤3:printf “%x\n” 18250将线程PID转化为16进制
$ printf “%x\n” 18250
0X47A
...
步骤4:jstack 18207|grep'0X47A'-C5 --color找出进程中消耗CPU最多的线程栈
$ jstack 18207|grep'0X47A'-C5 --colorFull thread dump OpenJDK 64-Bit Server VM (25.66-b60 mixed mode):"Attach Listener" #30 daemon prio=9 os_prio=0 tid=0x00007fb90be13000 nid=0x47d7 waiting on condition [0x0000000000000000] java.lang.Thread.State: RUNNABLE"DestroyJavaVM" #29 prio=5 os_prio=0 tid=0x00007fb96245b800 nid=0x4720 waiting on condition [0x0000000000000000] java.lang.Thread.State: RUNNABLE"Busiest Thread" #28 prio=5 os_prio=0 tid=0x00007fb91498d000 nid=0x474a runnable [0x00007fb9065fe000] java.lang.Thread.State: RUNNABLE at Test$2.run(Test.java:18)"Thread-9" #27 prio=5 os_prio=0 tid=0x00007fb91498c800 nid=0x4749 waiting on condition [0x00007fb906bfe000] java.lang.Thread.State: TIMED_WAITING (sleeping) at java.lang.Thread.sleep(Native Method) at Test$1.run(Test.java:9)...
因此,最耗cpu的线程是Busiest Thread
日常程序中常见的耗CPU的操作:
1、频繁GC,访问量高时,有可能造成频繁的GC、甚至FGC。当调用量大时,内存分配过快,就会造成GC线程不停的执行,导致CPU飙高
2、序列化与反序列化,后文中举了一个真实的案例,程序执行xml解析的时,调用量增大的情况下,导致了CPU被打满
3、加密解密
4、正则表达式校验,曾经线上发生一次血案,正则校验将CPU打满。大概原因是:Java 正则表达式使用的引擎实现是 NFA 自动机,这种引擎在进行字符匹配会发生回溯(backtracking)
5、线程上下文切换、当启动了很多线程,而这些线程都处于不断的阻塞状态(锁等待、IO等待等)和执行状态的变化过程中。当锁竞争激烈时,很容易出现这种情况
6、某些线程在做无阻塞的运算,简单的例子while(true)中不停的做运算,没有任何阻塞。写程序时,如果需要做很久的计算,可以适当将程序sleep下
7、Excel 导出事件
频繁GC案例
案例背景:网关服务进行控制单个url访问次数限流,CPU过若干天后飙升到80%,重启服务过若干天后又再次飙升到80%
分析过程:通过上述方法进行线程栈定位,并进行内存堆分析,发现pathRaterLimiterConcurrentHashMap对象占用大量堆空间,找到程序中对应的filter过滤器代码如下
public HttpRequestMessage apply(HttpRequestMessage request) {
String requestPath = request.getPath();
if (pathRaterLimiterConcurrentHashMap.containsKey(requestPath)) {
if (!pathRaterLimiterConcurrentHashMap.get(requestPath).tryAcquire()) {
log.warn("too many request:"+requestPath+",time:"+System.currentTimeMillis());
SessionContext context = request.getContext();
if(requestPath!=null && requestPath.equals("/voting/selection")){
context.setEndpoint(VoteTimeOutEndpoint.class.getCanonicalName());
}
//context.setEndpoint(ManyRequestsEndpoint.class.getCanonicalName());
request.setPath("/404.html");
context.setRouteVIP("limit-api");
}
} else {
pathRaterLimiterConcurrentHashMap.put(requestPath, RateLimiter.create(limit));
pathRaterLimiterConcurrentHashMap.get(requestPath).tryAcquire();
}
return request;
}
分析发现当url不断增加时,map的k-v会不断增加,以至于最后频繁触发fullgc,导致cpu飙升。
解决方案:跑一个定时任务线程定期清理map中的对象,后采用LRU算法重写一个maputil,定时清理过期的key值。
正则表达式案例
案例背景:前几天线上一个项目监控信息突然报告异常,上到机器上后查看相关资源的使用情况,发现 CPU 利用率将近 100%。
分析过程:
通过 Java 自带的线程 Dump 工具,我们导出了出问题的堆栈信息。我们可以看到所有的堆栈都指向了一个名为 validateUrl 的方法,这样的报错信息在堆栈中一共超过 100 处。通过排查代码,我们知道这个方法的主要功能是校验 URL 是否合法。
很奇怪,一个正则表达式怎么会导致 CPU 利用率居高不下。为了弄清楚复现问题,我们将其中的关键代码摘抄出来,做了个简单的单元测试。
public static void main(String[] args) {
String badRegex = "^([hH][tT]{2}[pP]://|[hH][tT]{2}[pP][sS]://)" +
"(([A-Za-z0-9-~]+).)+([A-Za-z0-9-~\\\\/])+$";
String bugUrl = "http://www.fapiao.com/dddp-web/pdf/download?" +
"request=6e7JGxxxxx4ILd-kExxxxxxxqJ4-CHLmqVnenXC692m7" +
"4H38sdfdsazxcUmfcOH2fAfY1Vw__%5EDadIfJgiEf";
if (bugUrl.matches(badRegex)) {
System.out.println("match!!");
} else {
System.out.println("no match!!");
}
}
正则表达式分为三部分:
第一部分匹配 http 和 https 协议,第二部分匹配 www. 字符,第三部分匹配许多字符。我看着这个表达式发呆了许久,也没发现没有什么大的问题。
其实这里导致 CPU 使用率高的关键原因就是:Java 正则表达式使用的引擎实现是 NFA 自动机,这种正则表达式引擎在进行字符匹配时会发生回溯(backtracking)。而一旦发生回溯,那其消耗的时间就会变得很长,有可能是几分钟,也有可能是几个小时,时间长短取决于回溯的次数和复杂度。
正则表达式是一个很方便的匹配符号,但要实现这么复杂,功能如此强大的匹配语法,就必须要有一套算法来实现,而实现这套算法的东西就叫做正则表达式引擎。简单地说,实现正则表达式引擎的有两种方式:DFA 自动机(Deterministic Final Automata 确定型有穷自动机)和 NFA 自动机(Non deterministic Finite Automaton 不确定型有穷自动机)。
对于这两种自动机,他们有各自的区别,这里并不打算深入将它们的原理。简单地说,DFA 自动机的时间复杂度是线性的,更加稳定,但是功能有限。而 NFA 的时间复杂度比较不稳定,有时候很好,有时候不怎么好,好不好取决于你写的正则表达式。
解决方案:
其实在正则表达式中有这么三种模式:贪婪模式、懒惰模式、独占模式。在关于数量的匹配中,有 + ? * {min,max} 四种,如果只是单独使用,那么它们就是贪婪模式。
如果在他们之后加多一个 ? 符号,那么原先的贪婪模式就会变成懒惰模式,即尽可能少地匹配。但是懒惰模式还是会发生回溯现象的。
如果在他们之后加多一个 + 符号,那么原先的贪婪模式就会变成独占模式,即尽可能多地匹配,但是不回溯。
String goodRegex = "^([hH][tT]{2}[pP]://|[hH][tT]{2}[pP][sS]://)" +
"(([A-Za-z0-9-~]+).)++([A-Za-z0-9-~\\\\/])+$";
Excel导出案例
案例背景:京东某系统使用了poi-ooxml-3.5-final做excel导出功能。起初使用该版本的poi的HSSF配合多线程生成excel,没有任何问题,后来改成了XSSF生成后上线,导出3w条数据时,cpu使用率达到了100%,内存达到了100%
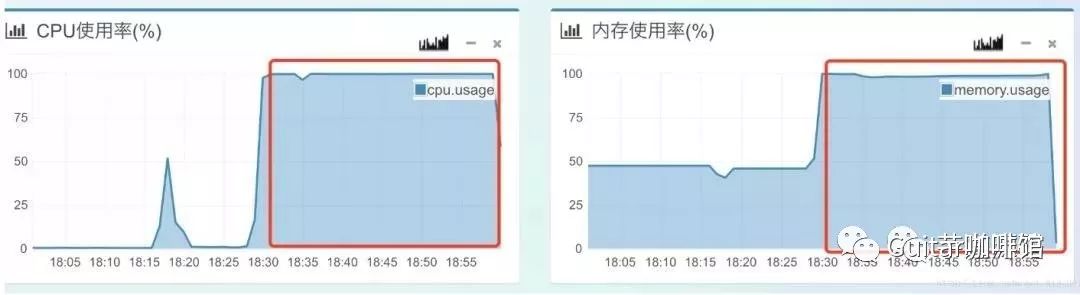
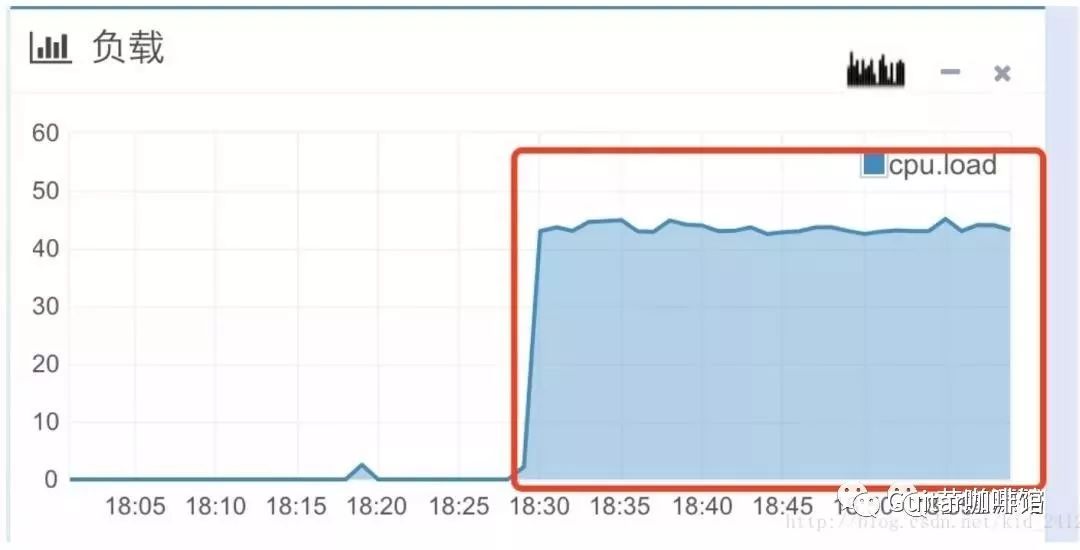
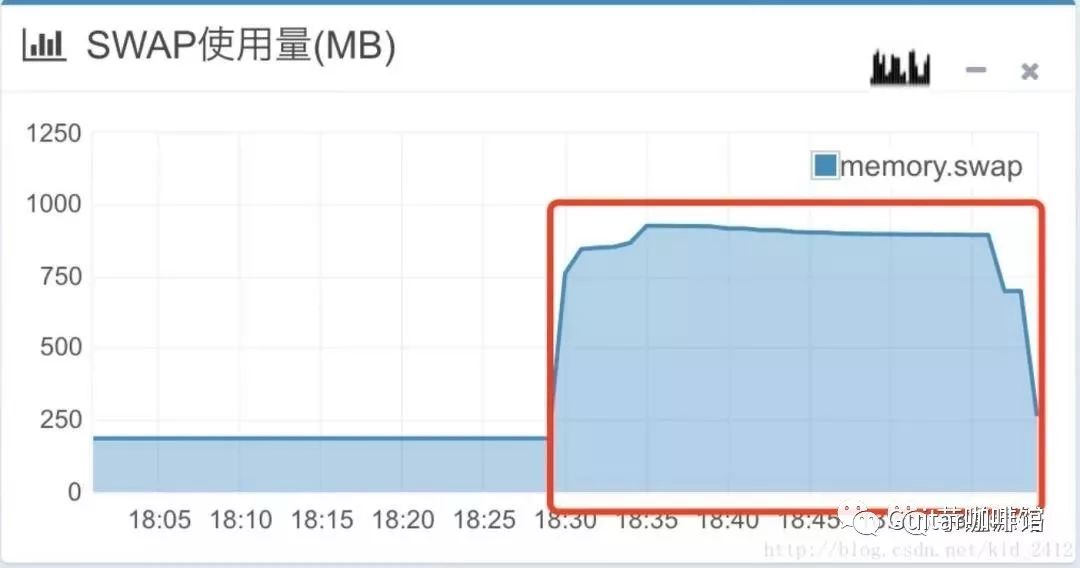
由于cpu使用率打爆,内存打爆,整个服务器处于拒绝服务状态,而呈现到前端则是应用系统大部分卡死。于是业务方不断反复点击导出按钮,状况不断扩大到集群内其他机器上,导致集群出现雪崩现象。
分析过程
由于服务器已经被打死,内存那么高,根本无法dump线上堆内存,甚至连jstack查看线程栈都无法使用。因此尝试在测试机复盘

可见eden空间的s0和s1已经无法交换了,eden空间已经完全打满,old空间也一样打满,yong gc和full gc都非常频繁,cpu自然使用率高了,不过不足以打满整个cpu!现在目前定位到了fullgc没有回收垃圾,那么需要找到内存打满和为啥没回收的原因。要想找到内存打满的原因肯定需要分析heap空间对象。
由于问题出现在导出报表,并且已知升级了版本并且改成了单线程导出就解决了,同时之前使用HSSF的时候并没有出现问题,也证明了业务代码没有问题,问题出现在XSSF的版本和多线程上。所以本地可以模拟poi-ooxml-3.5-FINAL的XSSF进行大量数据的导出实验,同时需要进行多线程导出。
在本地mock数据可以使用简单的大量对象构成的结构进行导出,线上30个列导出,本地测试5个列,线上是本地的6倍,线上的每一行的数据量必然要比本地的数据量大很多。同时怀疑是poi-ooxml-3.5-FINAL内存泄露或内存管理出现的问题,那么其实不需要4g内存,在2g的内存下压榨到死看看heap中大量的对象是不是poi相关的就可以了。然后再升级下版本,继续压榨一下看看会不会压死即可。
public static void main(String[] args) {
int size = 500000;
List<User> users = new ArrayList<>(size);
User user;
for (int i = 0; i < size; i++) {
user = new User();
user.setId(Integer.toUnsignedLong(i));
user.setAge(i + 10);
user.setName("user" + i);
user.setRemark(System.currentTimeMillis() + "");
user.setSex("男");
users.add(user);
}
new Thread(() -{
String[] columnName = {"用户id", "姓名", "年龄", "性别", "备注"};
Object[][] data = new Object[size][5];
int index = 0;
for (User u : users) {
data[index][0] = u.getId();
data[index][1] = u.getName();
data[index][2] = u.getAge();
data[index][3] = u.getSex();
data[index][4] = u.getRemark();
index++;
}
XSSFWorkbook xssfWorkbook = generateExcel("test", "test", columnName, data);
}).start();
try {
Thread.currentThread().join();//等待子线程结束
} catch (InterruptedException e) {
e.printStackTrace();
}
}
模拟现象与线上情况类似,大量cpu占用在XSSFCell.setCellValue中,生成excel generateExcel就占据了所有的cpu,堆信息全是POI对象
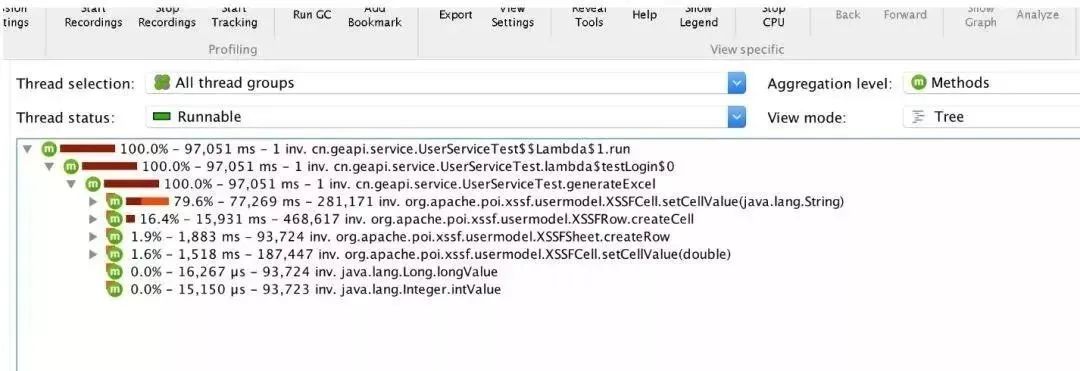
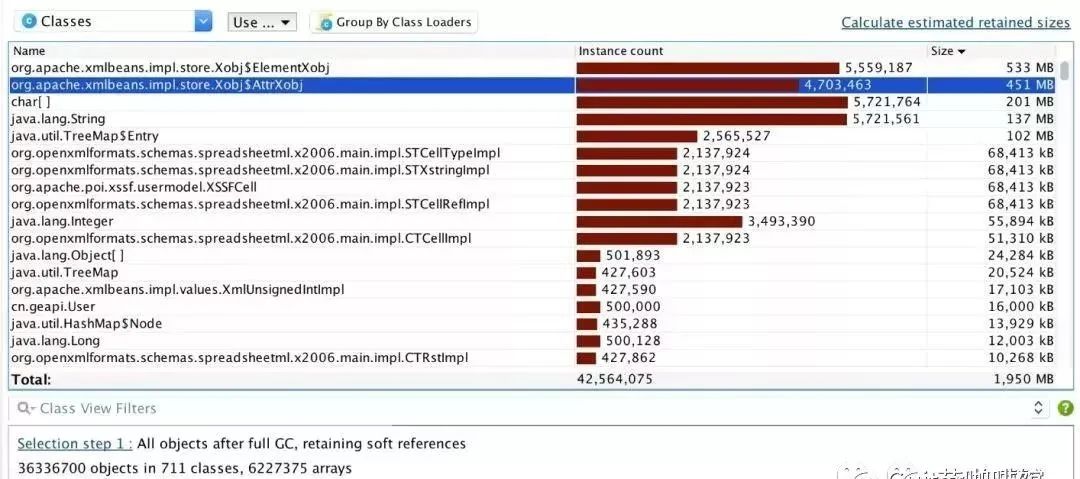
这里还需要注意的是,需要验证poi-ooxml-3.5-FINAL在多线程情况下是否会出现这个问题,验证很简单,把new Thread去掉,直接在主线程导出。这里直接说明实验结果,new Thread去了依然内存爆满!
解决方案
查看poi官网的change log http://poi.apache.org/changes.html ,既然3.5-FINAL的XSSF有问题,向上查找3.5-FINAL之后的XSSF相关字样的信息,会发现在3.6中memory usage optimization in xssf - avoid creating parentless xml beans,xxsf进行中做了内存优化 - 避免了创建无父类的xml bean对象
所以得出结论,升级poi-oxxml版本到3.6或者更高版本!
来源:技术让梦想更伟大
