GPU Hackathon 是一个专门针对全球从事科学研究的应用程序开发者的 GPU 应用加速活动,目标是在 10 天的活动期间,将科研 HPC+AI 应用通过 OpenACC,Python,CUDA 等不同的编程语言移植到 GPU 上。每次活动通常有 6-10 个应用小组参加,每个应用小组由 3-5 位老师和同学组成,并配有两名经验丰富的指导老师。指导老师为 NVIDIA、高校、社区的程序移植专家或 OpenACC 开发团队成员。 如今, GPU Hackathon 已在中国成功举办 9 次。
NVIDIA 联合西湖大学举办 GPU Hackathon
西湖大学作为国家重点的新型高等学校, 一直致力于最尖端的基础和应用研究。上个月,NVIDIA 联合西湖大学举办了 2022 年最后一场 GPU Hackathon,主要针对生命科学,海洋和 AI 应用提供 GPU 加速支持,活动为期 10 天, 为 9 个不同领域的 AI+HPC 应用提供了不同程度的加速效果。
传统海洋 HPC 应用 10 天加速 82 倍
这次活动中, 最 Top 的应用仍然是 HPC 领域的一项应用 — LAG, LAG 应用是海洋领域常用工具 FVCOM 的一部分,应用的主体是基于 Fortran 的流体力学的程序,通常这类程序的 GPU 移植比较费时,即使做好了移植,加速比通常也并不高。在此次 GPU Hackathon 上,通过小组成员和编程指导老师的努力,使用 OpenACC 编程和 NSIGHT 热点分析工具,该应用在活动中实现了 82 倍的速度提升。
这再次证明了 OpenACC 编程的强大之处,在提升传统基于 HPC 程序在 GPU 上的移植和优化上,OpenACC 比其他的编程方式更有效率,适合于大规模的程序移植。而且 OpenACC 对传统 HPC 应用中问题的解决更加的成熟。
GPU 对大规模研究数据的处理实现百倍加速
AI 和 HPC 方法在不同的研究中都需要处理大规模的数据。 在这次活动中,还有一大亮点是让人看到了 GPU 对数据处理方面能提供惊人的加速。
以西湖大学 DOU 团队的 Diabatization 为例, 该应用在计算主体部分使用 Python 处理了大规模的数据, 通常对于数据处理的计算需要 2 周左右时间, 而当参赛团队将处理程序移植到 GPU, 这些处理都能在 16 分钟内完成。该团队表示, 以后在编写处理大规模数据的程序时, 需要更多考虑 GPU,这在很多时候是“不能”和“能做”的差别。
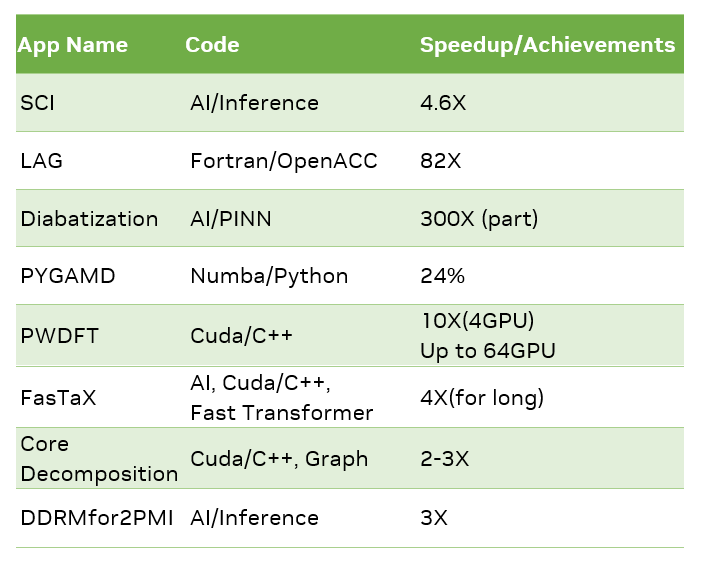
应用加速最终结果
因此,对于那些需要处理大规模数据的开发人员来说,使用 GPU 来处理数据,将会收获不可思议的加速,这种效率的提升和时间的大幅节约,对于研究和业务的提升也是显而易见的。
新的应用, 新的工具, Hackathon 为新的方向提供加速指导
此次 Hackathon 中也同时为其他很多应用提供了加速。 我们也看到一些新的发展趋势:
第一,AI 的方法在科研应用中越来越多, NVIDIA 新的工具也为使用 AI 方法的新应用提供了更好的支撑, 譬如,本次 Hackathon 中就看到了 Fast Transformer,Modulus 的使用。
第二, Python 在数据处理和算法原型方面被广泛使用,GPU 上的 Python 生态也不断发展, 在 Hackathon 中, 不同团队都发现自己很容易把自己的 Python 放到 GPU 上。
第三, 传统的 HPC 应用也在不断采用 GPU 加速计算和 AI 方法, 很多以前很难处理的问题,现在都有了标准答案和好的实践案例。这一点在 OceanStar 和 Kseig 团队解决他们的移植和优化问题中都有很好的体现。
西湖大学 GPU Hackathon 活动是在中国的第 9 次 Hackathon,通过 GPU Hackathon 活动,可在短短 5-10 天的时间内大幅提升基于 GPU 的应用水平,同时为下一阶段的深度优化提供良好的基础。未来,NVIDIA 希望继续借助举办 GPU Hackathon 实践活动,对科研应用 GPU 的加速发展提供实际的帮助。NVIDIA 也欢迎有实际应用加速需求的老师持续关注 GPU Hackathon 项目,帮助 NVIDIA 更好的服务于加速应用领域科研的发展。
点击 “阅读原文” 或扫描下方海报二维码,即可免费注册 GTC 23,切莫错过这场 AI 和元宇宙时代的技术大会!

