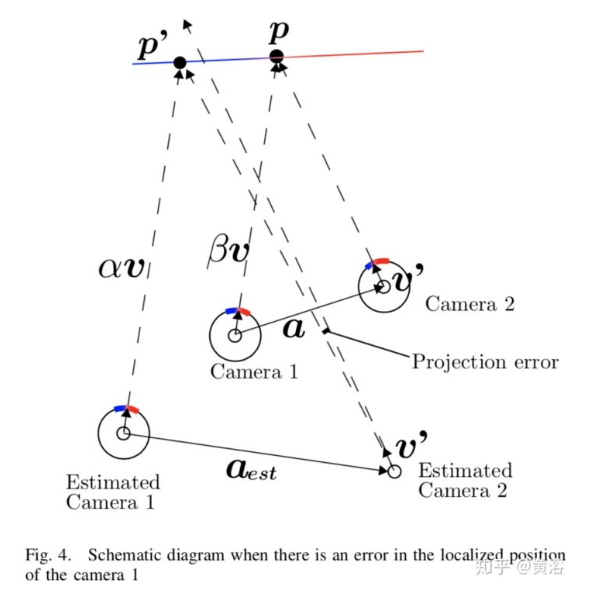
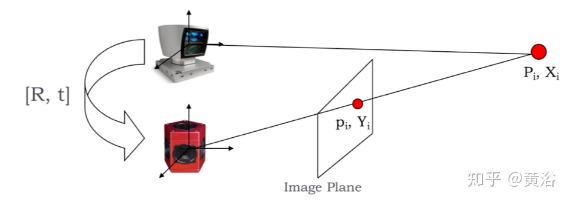
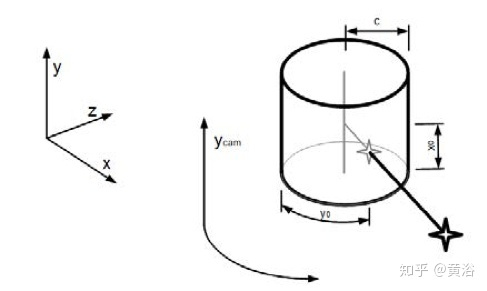
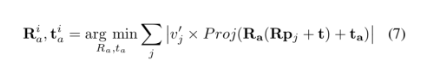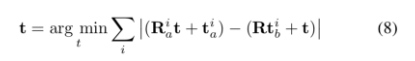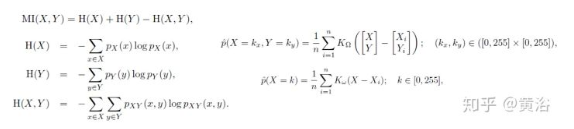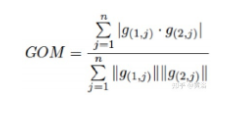80,000人到访的国际大展上,艾迈斯欧司朗有哪些亮点?感未来,光无限。近日,在慕尼黑electronica 2024现场,ams OSRAM通过多款创新DEMO展示,以及数场前瞻洞察分享,全面展示自身融合传感器、发射器及集成电路技术,精准捕捉并呈现环境信息的卓越能力。同时,ams OSRAM通过展会期间与客户、用户等行业人士,以及媒体朋友的深度交流,向业界传达其以光电技术为笔、以创新为墨,书写智能未来的深度思考。electronica 2024electronica 2024构建了一个高度国际