3、FreeRTOS线程计算的弊端?如何打破 FreeRTOS 线程计算方式的时间限制?
《
实操RT-Thread系统CPU利用率功能添加》
但是却没有介绍该如何计算每个线程(任务)的CPU使用率。
首先要问的是,为什么要计算线程的CPU使用率,有啥用?
我们知道系统的CPU使用率关注的是整个系统的使用情况,使用率越低,表示越能更及时的响应外部情况,整个系统的性能也会越好。
但这是从系统整体考量的,并不能反映单个线程的执行情况。
比如虽然整体的CPU使用率是30%,但是有一个线程占据了25%的使用率,一个线程使用率是5%,那么你肯定会想,为啥这个线程需要占用这么高的CPU使用率,是不是代码写的有问题,是不是代码可以优化一下?
当系统运行时,如果你能实时观察各个线程的CPU使用率,那么你就能知道平时这个线程的CPU使用情况是怎样的,为什么后来又高那么多,那么你就可以由此分析出这个线程可能出现了问题,也就可以针对性的进行检查了。
这点对于合作开发的项目更是明显,很多时候因为有些线程的代码不是自己写的,所以根本不知道代码执行情况,一旦系统出现问题,那么可能就是互相甩锅了。
而当计算了线程的CPU使用率,一旦发现某个线程执行异常,那么就能交给负责的人去查看了。
所以说,使用操作系统的项目是非常有必要计算各个线程(任务)的CPU使用率的。
就好比你的电脑,风扇嗡嗡响(CPU高负荷运行),如果只有一个系统CPU使用率,发现高达90%,但是你却根本不知道为什么这么高,所以只能重启。
而一旦有了进程CPU使用率,查看一下哪个进程CPU使用率高,把对应的进程关闭就行了,根本不需要重启电脑。
那么现在就来看看该如何计算各个线程的CPU使用率。
从前面的笔记,我们其实也可以猜测该如何计算,无非就是获取
每个线程的执行时间罢了。
比如,1秒时间内,空闲任务执行700毫秒,任务1执行200毫秒,任务2执行100毫秒,那么各个任务的CPU使用率分别是 70%、20%、10%。
以前计算系统的CPU使用率的时候,采用了软件方法计算空闲任务的运行时间,这必然是不够准确的,所以最好的方式是采用硬件计时。
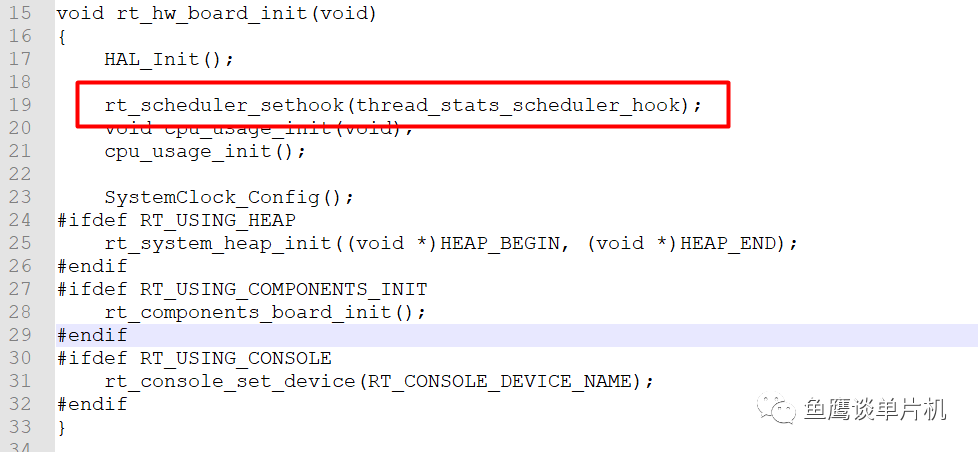
因为鱼鹰采用STM32F103进行测试,所以使用DWT外设进行精确计时,不过麻烦的是,在KEIL
软件仿真情况下,DWT外设是无法工作的,所以如果要测试的话,必须使用硬件仿真的方式,不过如果真要KEIL软件仿真的话,也不是没有办法,就是使用硬件定时器,这个按下不表。
毕竟,DWT外设的功能在这里说白了也就是个定时器而已。
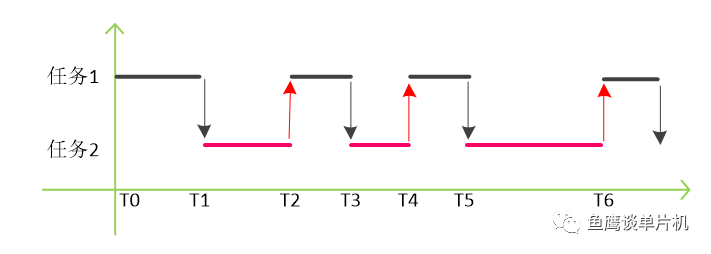
既然要获取线程的执行时间,关键一点就是,我们要知道操作系统什么时候会切换到某一个线程运行,什么时候又会从这个线程切出,到另一个线程执行呢?
这个关键还是在系统内置的
钩子函数。上次的笔记鱼鹰介绍过空闲钩子函数,今天介绍另一个钩子,任务切换钩子函数。
这个钩子函数的特点就是,每当系统需要切换到下一个任务时,就会
先执行这个函数。这个函数一般有两个参数,
当前任务和
即将切换的任务。
只要设置任务切换的钩子函数,并且有时间戳,那么计算一个任务的执行时间也就不那么困难了。
比如,操作系统在时刻12345 ms 切换到空闲任务执行,突然一个任务就绪,开始准备执行,所以在时刻12445切换到那个就绪任务执行,那么空闲任务的执行时间我们也就可以准确计算出来了。
如果我们要计算单位时间(比如1秒内)空闲任务的执行时间,我们只要在每次运行到空闲任务时
累计时间即可。
比如1秒内,空闲任务执行了 5 次,分别是 10、200、100、200、50,累计时间为
10 + 200 + 100 + 200 + 50 = 560毫秒
由此,可计算空闲任务的CPU使用率为 56%,从而可计算出系统的CPU使用率是44%。
是的,通过线程的CPU使用率方法,我们其实也可以计算整个系统的CPU使用率。而且这种计算方式比前面所说的计算方法更准确,更科学。
前面采用时间戳进行计算,但是时间戳是会溢出的,那个时候,你的时间计算还是准确的吗?
现在鱼鹰就来说说第三个问题,FreeRTOS线程计算的弊端?如何打破 FreeRTOS 线程计算方式的时间限制?
从网上查找FreeRTOS任务CPU计算相关的资料,可以得到以下信息:
1、需要开一个定时器,这个定时器中断频率是操作系统时钟的十几倍(为了保证计算精度)。
2、一个64 位的变量在定时器自加更新,一旦变量溢出,时间计算就会出现问题。
第一个问题会导致系统性能下降(中断频率太高,一般是微秒级别的),而第二个问题导致在一段时间内(小时级别)线程CPU使用率计算准确,超出时间后,计算会有问题,所以教程中不建议在正式版本加入此功能。
第一个问题其实很好解决,就是使用硬件定时器,不再由CPU去更新时间,这样不会占用CPU时间,第二个问题其实也非常好解决,就是通过《
延时功能进化论(合集)》的方式解决溢出问题,这里不再展开说其中的奥妙。
总之,鱼鹰接下来的实现方式解决了以上两个痛点,即使无限执行下去,也不会影响到计算精度问题,唯一对系统产生的一点影响,只有在任务切换时消耗的一点计算时间(微秒级别)。
那么先上任务切换
钩子函数关键实现代码(RT-Thread):
void thread_stats_scheduler_hook(struct rt_thread *from, struct rt_thread *to){ static uint32_t schedule_last_time; uint32_t time; time = get_curr_time(); from->user_data += (time - schedule_last_time); schedule_last_time = time;}
每次任务开始切换时,更新这个时间戳,同时累积时间,这个时间保存在当前任务的user_data里面。
假设系统调度是从任务1切换到任务2,即from为
任务
1,to为
任务
2,此时获取的时间戳为
T1
。
上一次的时间戳我们已经通过静态变量保留了,这里为T0,那么T1-T0就是from任务即
任务
1在本次运行的时间,只要下次运行任务1时继续不断的累积这个时间,那么就可以得到任务1的总运行时间。
当然我们不可能一直累积下去,不然肯定会溢出,所以隔一段时间就需要清零,这个时间其实就是
线程
CPU
计算的周期。
这里还有一个函数没有说,就是 get_curr_time(),在这里使用DWT,为了可以重新实现该函数,鱼鹰使用了弱属性 weak(关于这个看参考:《
困惑多年,为什么 printf 可以重定向? 》)。
__weakuint32_t get_curr_time() { return DWT->CYCCNT; }
这里可以看到有个注释,不要使用 rt_tick_get 函数,为啥?
精度太低,有些任务本来执行了的,但是因为执行时间
小于操作系统的时钟(比如1毫秒),那么就无法累积时间了,那么即使这个任务运行再多,时间累积也为 0,这肯定是我们不希望看到的。
然后再说一个点,为了简化代码(钩子函数代码只有短短几行),鱼鹰这样的实现是有两个问题的。
1、首次运行计算有误,因为静态变量应该在运行任务之前就初始化的(不应该初始化为 0),而钩子函数是在任务运行之后才调用的,所以从开机以来的时间被累加到第一个运行任务中了,这肯定是有问题的,不过后面随着系统的运行,静态变量被持续更新,就不会再出现这个问题了。
2、为了减少修改,鱼鹰把线程的use_data当成一个变量使用了,实际上这个变量的功能应该是存储线程私有变量地址的,但是因为鱼鹰懒得修改太多代码,所以直接拿来用了。正因为如此,所以鱼鹰添加线程CPU计算时,只要修改很少的代码就可以了。
目前我们已经能够通过钩子函数获取各个线程的CPU执行时间,现在就看该如何计算了。
为了计算各个线程的CPU使用率,我们需要确定计算周期,这里我们可以设置1秒计算一次。
原理上来说,可以是系统中的任何一个任务,但是为了减少对系统的干扰,可以将计算工作放到优先级比较低的任务中进行,比如空闲任务。
void thread_cal_usage(thread_run_info_def *run_info){ static uint32_t total_time_last; uint32_t time, total_time; struct rt_list_node *node; struct rt_list_node *list; struct rt_thread *thread; uint32_t i; rt_enter_critical(); time = get_curr_time(); total_time = time - total_time_last; total_time_last = time; list = &(rt_object_get_information(RT_Object_Class_Thread)->object_list); for(i = 0, node = list->next; (node != list) && i < THREAD_NBR_MAX; node = node->next, i++){ thread = rt_list_entry(node, struct rt_thread, list); run_info[i].name = thread->name; run_info[i].time = thread->user_data; thread->user_data = 0; } rt_exit_critical(); total_time /= 100; if(total_time > 0){ for(uint32_t j = i, i = 0; i < j; i++) { run_info[i].usage = run_info[i].time / total_time; } }}
注释已经很详尽了,所以不多做讨论。主要说以下几点:
关调度器是为了防止在获取各个线程执行时间时,因为系统调度而导致执行时间被更新,从而导致计算有误,所以需要关闭调度器。
那么为什么不使用关中断的方式呢?没有必要。一旦关中断,那么中断就无法响应了,所以在可以关调度器的情况下满足要求,就不应该关中断。
2、为什么分两步计算,为什么不将最终的计算放在第一个循环中执行呢?
节省时间,为了尽量减少关调度器的时间,能省一点是一点。毕竟只要能获取到关键信息,啥时候计算都一样。
3、因为线程CPU计算周期是自动计算的,所以,计算周期其实就是该函数的调用周期,即2秒调用一次,那么线程CPU计算周期就是2秒,但是需要注意的是,调用周期必须小于定时器的溢出时间,即当你使用 DWT 时,调用周期应该在 60 秒以下(72 M 系统时钟),否则计算是有问题的。
现在我们已经算是完成了线程CPU计算问题,但为了使用方便,我们需要把它打印出来,或者把这些信息字符串化:
void thread_stats_print(void){ thread_run_info_def run_info[THREAD_NBR_MAX] = {0}; thread_run_info_def *p_info;
thread_cal_usage(run_info); rt_kprintf("thread\t\t\ttime\t usage\n"); for(uint32_t i = 0; i < THREAD_NBR_MAX; i++) { p_info = &run_info[i]; if(p_info->name != NULL) { if(p_info->usage > 0) { rt_kprintf("%-16s\t%u\t%2u%%\n", p_info->name, (uint32_t)p_info->time, (uint32_t)p_info->usage); } else { rt_kprintf("%-16s\t%u\t<1%%\n", p_info->name, (uint32_t)p_info->time, (uint32_t)p_info->usage); } } else { break; } }}
这里将
线程名、线程执行时间、线程使用率都打印出来了,但是需要注意的是,这里的time 时间单位是定时器的单位,而不是微秒、毫秒,比如如果使用 DWT,那么单位就是 1/72 微秒,即如果 time 值为 1000,那么换算到微秒,应该是 1000/72 秒,当然了,你也可以在打印的同时就把时间换算一下,这个自由发挥就好。
▲Linux内核中I2C总线及设备长啥样?
[墙裂推荐]