01
介绍
02
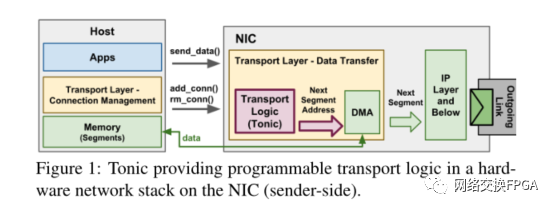
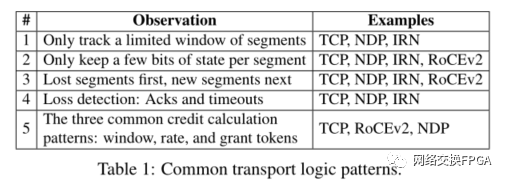
Tonic作为传输逻辑
03
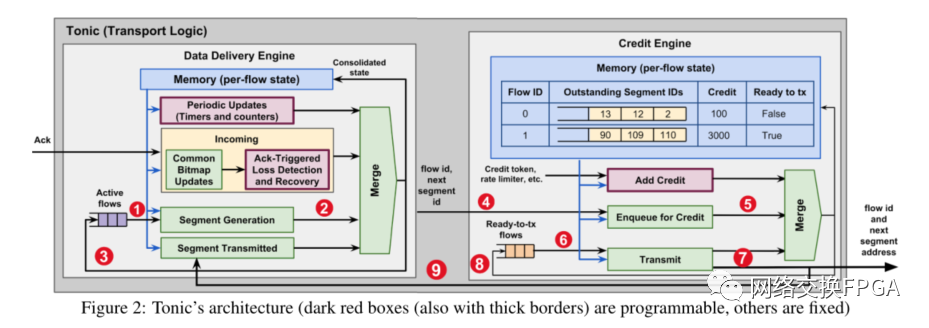
Tonic架构

04
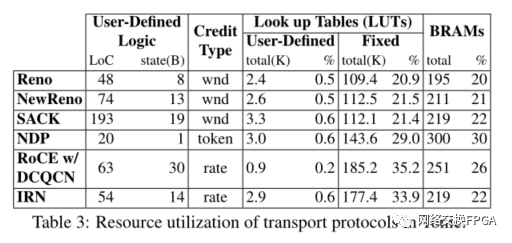
硬件实现
05
将Tonic集成到传输层
06
评估
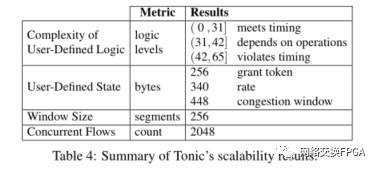
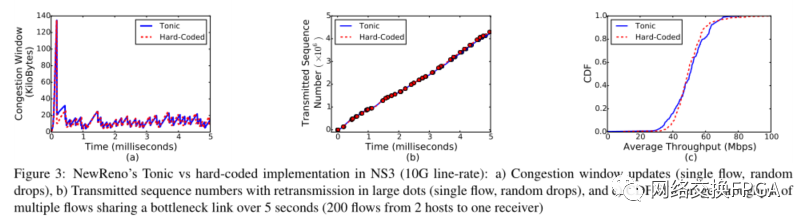
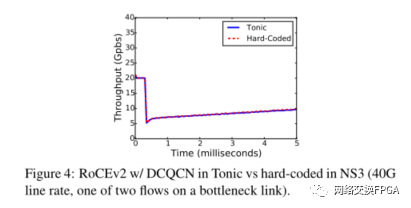
07
相关工作
附录
往期精选




FPGA技术江湖广发江湖帖
无广告纯净模式,给技术交流一片净土,从初学小白到行业精英业界大佬等,从军工领域到民用企业等,从通信、图像处理到人工智能等各个方向应有尽有,QQ微信双选,FPGA技术江湖打造最纯净最专业的技术交流学习平台。
FPGA技术江湖微信交流群

加群主微信,备注姓名+公司/学校+岗位/专业进群
FPGA技术江湖QQ交流群

备注姓名+公司/学校+岗位/专业进群


