作者简介:尹忠凯,Linux内核爱好者,阅码场用户。现就职于北京地平线信息技术有限公司,任系统软件工程师。
物理内存分配设计有两个重要的评价维度。一方面,物理内存分配器要追求更高的内存资源利用率,即尽可能减少资源浪费。另一方面,物理内存分配器要追求更好的性能,主要是尽可能降低分配延迟和节约CPU资源。
内存碎片指的是无法被利用的内存,进一步又可以分为外部碎片和内部碎片。

图1 外部碎片
如图1所示,假设系统中共有25MB内存,系统经过长期的运行后,使用了19MB内存(带颜色的部分),假如此时想申请3MB内存,总的空闲内存是满足要求的,但每一块单独的空闲内存都不满足要求。此时这些无法被使用的内存称为外部碎片。
为了解决外部碎片问题,一种比较简的方式就是将物理内存以固定大小划分成若干块,每次用一个块或者多个块来满足一次内存请求。
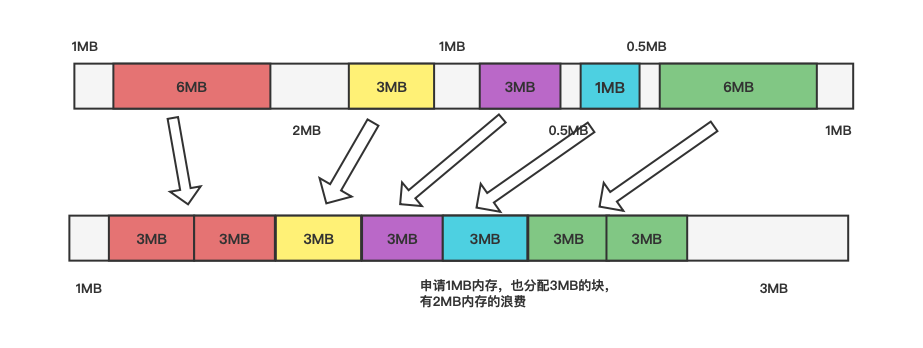
图2 内部碎片
如图2所示,还是这25MB内存,这次以3MB大小固定块来分配内存,申请6MB内存就分配两个固定块,申请3MB内存分配一个固定块,申请1MB内存,也分配一个固定块。可以看到此时外部碎片的问题是解决了,但是又引入了新的问题即只申请1MB内存,却分配了3MB内存,多出的2MB内存即为内部碎片。
下面会介绍linux系统中的页分配器和块分配器,页分配器用来解决外部碎片问题,而块分配器用来解决内部碎片问题,通过这两个分配器,可以有效减少内存碎片的产生,从而提高内存资源的利用率。
在介绍页分配器和块分配器之前,先来了解下现代计算的物理内存是如何组织的,因为有些概念在后面会用到。
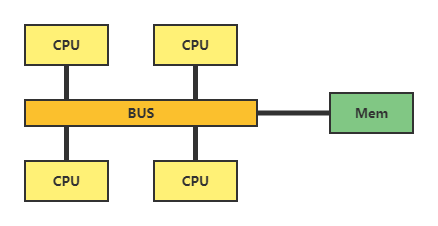
图3 SMP架构
SMP架构就是对称多处理器,所有的CPU必须通过相同的内存总线访问相同的内存资源。所以所有CPU访问内存等资源的速度是一样的,即对称。这种架构的缺点是,CPU数量增加,内存访问冲突将迅速增加,最终会造成CPU资源的浪费,使 CPU性能的有效性大大降低。

图4 NUMA架构
NUMA架构将CPU划分到多个Node中,每个node有自己独立的内存空间。各个node之间通过高速互联通讯。CPU访问不同类型节点内存的速度是不相同的,访问本地节点的速度最快,访问远端节点的速度最慢,即访问速度与节点的距离有关,距离越远访问速度越慢,即非一致。这种架构的缺点是,本node的内存不足时,需要垮节点访问内存,节点间的访问速度慢。
内存管理子系统使用节点(node)、区域(zone)、和页(page)三级结构描述物理内存。
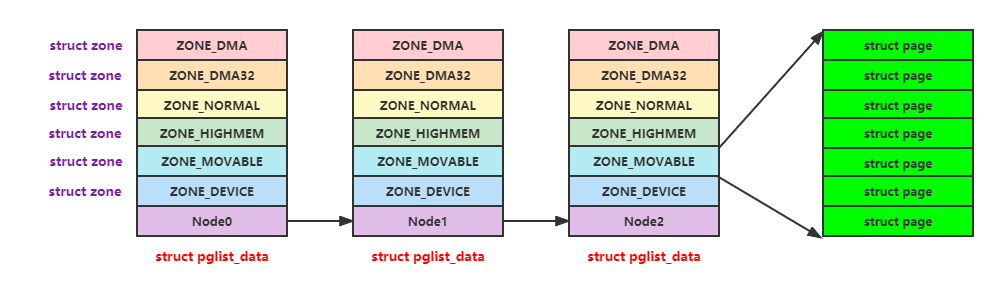
图5 物理内存三级结构
如图5所示,在linux中使用三级结构来描述物理内存。
节点(node):每个节点用一个struct pglist_data结构体来表示,每个节点内的内存会划分成不同的区域
区域(zone):每个区域用一个struct zone结构体来表示,每个区域又会划分成不同的页
页(page):每个页用一个struct page结构体来表示,页是伙伴算法分配的最小单位(比如:4K,16K,64K)。
伙伴算法的基本思想是将物理内存划分成连续的块,以块作为基本单位进行分配。不同的块大小可以不同,但每个块都由一个或多个连续的物理页组成,物理页的数量必须是2的n次幂(0 <= n < 预设的最大值)。
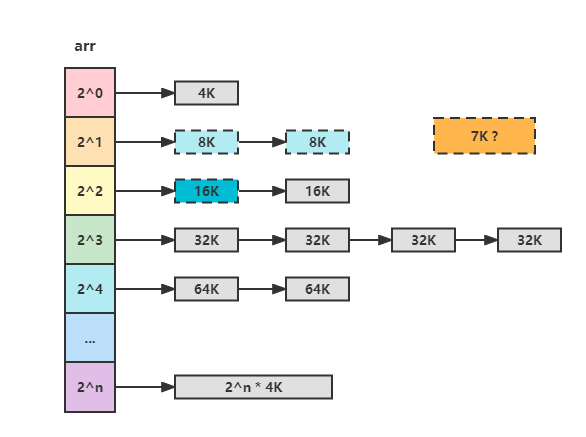
图6 伙伴系统的空闲链表数组
如图6所示伙伴算法一般使用空闲链表数组来实现,假如我们要申请一块7K大小的内存。
首先7K / 4K = 1,也就arr[1]这一个空闲链表上申请空闲块,结果发现链表为空。
然后发现下一级空闲链表arr[2]不为空,从arr[2]的链表头取出一个16K的空闲块,并分裂成2个8K的空闲块。
最后将分裂的2个8K空闲块,一个返回给申请者,另一个放到arr[1]的空闲链表中。
申请完毕,就是这么简单。
查找空闲链表的过程十分简单,比如页大小来4K,如果申请7K内存的话,直接7K / 4K = 1计算一下就可以找到空闲链表位置。
确定一个块的伙伴块十分简单,比如arr[0]空闲链表块A(0 ~ 4K)和块B(4K ~ 8K)互为伙伴块,块A物理地址为0x0,块B物理地址为0x1000,可以看出只有12位不同,同时块大小也是2^12;再比如arr[1]空闲链表块A(16K ~ 24K)和块B(24K ~ 32K)互为伙伴块,块A物理地址为0x4000,块B物理地址0x6000,可以看出只有13位不同,同时块大小也是2^13(很神奇)。
由于伙伴算法的这种特点,在块的分裂与合并的计算都很高效,有效的管理了物理内存,很好的缓解了外部碎片的问题。
前面介绍了Linux使用三级结构来描述物理内存,Linux伙伴算法是基于区域(zone)这一级来实现。
/* include/linuxmmzone.h */#ifndef CONFIG_FORCE_MAX_ZONEORDER#define MAX_ORDER 11#else#define MAX_ORDER CONFIG_FORCE_MAX_ZONEORDER#endifstruct free_area { struct list_head free_list[MIGRATE_TYPES]; unsigned long nr_free;};struct zone {... /* free areas of different sizes */ struct free_area free_area[MAX_ORDER]; ....} ____cacheline_internodealigned_in_smp;
实现方法也很简单,就是在struct zone结构体中定义了一个struct free_area结构体数据,这个数组也就是我们前面提到了空闲链表数组。可以看到MAX_ORDER默认值为11,也就是说最大的块为为2^10 * 4K(4K页大小) = 4M,假如申请内存大小超过4M,会申请成功吗?。
/ # cat /proc/buddyinfoNode 0, zone DMA 1 4 2 3 1 4 2 5 3 3 207/ #
如上为使用qemu模拟的环境,可以看出2^10的大小块有207个,2^9的大小块为3个……
可移动性分组
到前一小节为止,伙伴系统的主要内容已经介绍完了,但是Linux针对内存碎片问题还有很多优化,本小节会介绍下可移动性分组的实现原理。

图7 内存碎片整理
如图7所示,假如系统运行一段时间后,被使用的内存为紫色部分,空闲的为淡蓝色部分,此时可使用的连续的物理内存只有8K;如果经过内存碎片整理,把使用的内存都放到一起,那么可使的连续的物理内存就有16K了。伙伴算法只会保证在内存申请的时候尽量避免内存碎片的产生,但是内存碎片不可避免的还是会产生,这时就需要在运行时对内存碎片进行整理,从而获取更大的连续内存。
如图7所示是对编号5的内存块进行了迁移,假如编号5的内存块不能移动,中间的内存碎片就得不到整理,这种情况咱办呢?
针对前面提到的问题,Linux将物理内存进行了划分,分为不可移动页,可移动页,可回收页。
不可移动页:位置必须固定,不能移动,直接映射到内核虚拟地址空间的页属于这一类。
可移动页:使用页表映射的页属于这一类,可以移动到其他位置,然后修改页表映射。
可回收页:不能移动,但可以回收,需要数据的时候,可以重新从数据源获取。后备存储设备支持的页属于这一类。
/* include/linuxmmzone.h */enum migratetype { MIGRATE_UNMOVABLE, MIGRATE_MOVABLE, MIGRATE_RECLAIMABLE, MIGRATE_PCPTYPES, /* the number of types on the pcp lists */ MIGRATE_HIGHATOMIC = MIGRATE_PCPTYPES,#ifdef CONFIG_CMA MIGRATE_CMA,#endif#ifdef CONFIG_MEMORY_ISOLATION MIGRATE_ISOLATE, /* can't allocate from here */#endif MIGRATE_TYPES};struct free_area { struct list_head free_list[MIGRATE_TYPES]; unsigned long nr_free;};struct zone {... /* free areas of different sizes */ struct free_area free_area[MAX_ORDER]; ....} ____cacheline_internodealigned_in_smp;
继续看struct free_area结构体,里面定义了一个数组链表,数组索引为当前块的迁移类型。所以在申请内存的时候,可以通过flag来告诉系统,要申请什么类型的内存,系统会将相同类型的内存放在一起,从而解决上面的提到的问题。这里的思路也是在内存申请时,尽量减少内存碎片的产生。
假如申请内存大小超过4M,会申请成功吗?
/* mm/page_alloc.c */struct page *__alloc_pages_nodemask(gfp_t gfp_mask, unsigned int order, int preferred_nid, nodemask_t *nodemask){... /* * There are several places where we assume that the order value is sane * so bail out early if the request is out of bound. */ if (unlikely(order >= MAX_ORDER)) { WARN_ON_ONCE(!(gfp_mask & __GFP_NOWARN)); return NULL; }... return page;}EXPORT_SYMBOL(__alloc_pages_nodemask);
如上代码10 ~ 13行,当申请内存大小超过系统最大块时,内存申请会失败的。但如果就想申请大块内存,比如像图像数据这种就需要大块内存,怎么办呢?可以使用保留内存的方式。
# 这里申请16M大小物理内存,可能看到内存申请不成功,系统报了一个warning/ # insmod /app/cdev-test.ko[ 11.895824] cdev_test: loading out-of-tree module taints kernel.[ 11.921420] [cdev_test_init:151]devno = 0x0e600000[ 11.921561] <__alloc_pages_nodemask: 4984>order = 12[ 11.922725] ------------[ cut here ]------------[ 11.923045] WARNING: CPU: 2 PID: 47 at mm/page_alloc.c:4985 __alloc_pages_nodemask+0x8c/0x268[ 11.923509] Modules linked in: cdev_test(O+)[ 11.924604] CPU: 2 PID: 47 Comm: insmod Tainted: G O 5.12.0-00008-g48ca89975eb3-dirty #14[ 11.925044] Hardware name: linux,dummy-virt (DT)[ 11.925521] pstate: 40000005 (nZcv daif -PAN -UAO -TCO BTYPE=--)[ 11.925885] pc : __alloc_pages_nodemask+0x8c/0x268[ 11.926191] lr : __alloc_pages_nodemask+0x68/0x268[ 11.926467] sp : ffff800010223a50[ 11.926677] x29: ffff800010223a50 x28: ffff6a86485ff8d0[ 11.927121] x27: ffff6a86485ff880 x26: 0000000000000001[ 11.927477] x25: ffff6a86485ff8d0 x24: ffff6a8648521bc0[ 11.927835] x23: 0000000000000000 x22: ffffdafc7ac98000[ 11.928186] x21: 000000000000000c x20: 000000000000000c[ 11.928540] x19: 0000000000040cc0 x18: 000000000000000a[ 11.928892] x17: 0000000000000000 x16: ffffdafc7a8e840c[ 11.929246] x15: 00000000000e0fd9 x14: 000000000000008c[ 11.929606] x13: ffff800010223720 x12: 00000000ffffffea[ 11.929962] x11: ffffdafc7af65410 x10: ffffdafc7aca5468[ 11.930312] x9 : ffff800010223718 x8 : ffff800010223720[ 11.930732] x7 : ffffdafc7b025450 x6 : 00000000ffff7fff[ 11.931082] x5 : 00000000002bffa8 x4 : 0000000000000000[ 11.931440] x3 : 0000000000000000 x2 : 7aafd30192e33000[ 11.931791] x1 : 0000000000000000 x0 : 0000000000000028[ 11.932244] Call trace:[ 11.932464] __alloc_pages_nodemask+0x8c/0x268[ 11.932727] alloc_pages_current+0xc4/0xc8[ 11.932964] kmalloc_order+0x34/0xa4[ 11.933190] cdev_test_init+0x48/0x1000 [cdev_test][ 11.934498] do_one_initcall+0x74/0x184[ 11.934726] do_init_module+0x54/0x1f4[ 11.934956] load_module+0x1870/0x1f24[ 11.935184] __do_sys_init_module+0x154/0x184[ 11.935421] __arm64_sys_init_module+0x14/0x1c[ 11.935666] do_el0_svc+0x100/0x144[ 11.935885] el0_svc+0x10/0x18[ 11.936090] el0_sync_handler+0x64/0x12c[ 11.936314] el0_sync+0x13c/0x140[ 11.936632] ---[ end trace 206fd1429c29dfb5 ]---[ 11.937737] kmalloc failedinsmod: can't insert '/app/cdev-test.ko': Operation not permitted
块分配器(slab)
伙伴系统最小的分配单位是一个物理页,但是大多数情况下,内核需要分配的内存大小通常是几十个字节或者几百个字节,远远小于一个物理页的大小。如果仅仅使用伙伴系统进行内存分配,会出现严重的内部碎片问题,从而导致资源利用率降低。
块分配器(slab)就是用来解决这个问题的,slab分配器做的事情是把伙伴系统分配的大块内存进一步细分成小块内存进行管理。一方面由于操作系统频繁分配的对象大小相对固定,另一方面为了避免外部碎片问题。其实现也比较简单,一般slab分配器只分配固定大小的内存块,大小通常是2^n个字节(一般来说,3 <= n < 12,4K大小页)。
SLAB发展
20世纪90年代,Jeff Bonwick最先在Solaris 2.4操作系统内核中设计并实现了SLAB分配器。之后,该分配器广泛地被Linux、FreeBSD等操作系统使用并得以发展。21世纪,操作系统开发人员逐渐发现SLAB分配器存在一些问题,比如维护了太多了队列、实现日趋复杂、存储开销也由于复杂的设计而增大等。于是,开发人员在SLAB的分配器的基础上设计了SLUB分配器。
SLUB分配器极大简化了SLAB分配器的设计和数据结构,在降低复杂度的同时依然能够提供与原来相当甚至更好的性能,同时也继承了SLAB分配器的接口。
此外,SLAB分配器家族中还有一种最简单的分配器称为SLOB分配器,它的出现主要为了满足内存资源稀缺的场景(比如嵌入式设备)的需求,它具有最小的存储开销,但在碎片问题的处理方面比不上其他两种分配器。
SLAB、SLUB、SLOB三种分配器往往被统称为SLAB分配器。
基本原理
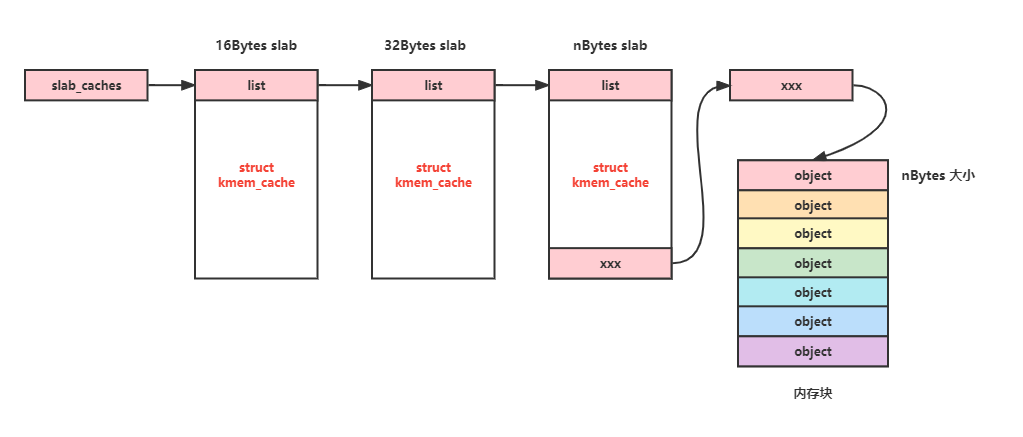
图8 slab空闲链表
slab分配器实现也很简单,如图8所示,Linux通过链表来维护不同大小的slab结构(struct kmem_cache结构体), 每个slab结构中都会记录内存块的信息,并将大的内存块划分内多个小的内存块备用。当有内存申请时,首先会找到合适大小的slab结构,然后从小的内存块中返回一个给申请者就可以了(看就是这么简单)。用链表来维护slab结构,难道申请内存的时候需要遍历一次链表?当然不会!
struct kmem_cache结构体一般有两种初始化方式。
系统初始化
在系统初始化时,会初始化一批常用大小的slab结构体,其对应全局变量kmalloc_caches,使用类似kmalloc()这种接口时,会根据申请内存大小直接找到对应的slab结构。
/* mm/slab_common.c */struct kmem_cache *kmalloc_caches[NR_KMALLOC_TYPES][KMALLOC_SHIFT_HIGH + 1] ={ /* initialization for https://bugs.llvm.org/show_bug.cgi?id=42570 */ };EXPORT_SYMBOL(kmalloc_caches);
自己初始化
除了系统自带的slab结构,当然也可以使用自己创建的slab结构,常用接口如下,相信大家基于都使用过,就不多介绍了
/* linux/slab.h */struct kmem_cache *kmem_cache_create(const char *name, unsigned int size, unsigned int align, slab_flags_t flags, void (*ctor)(void *));void *kmem_cache_alloc(struct kmem_cache *s, gfp_t gfpflags);void kmem_cache_free(struct kmem_cache *s, void *x);void kmem_cache_destroy(struct kmem_cache *s);
调试slab分配器
Linux对slab分配器还做了很多优化,比如per cpu支持,numa构架的支持,这里面有很多细节,可以研究研究源码。本小节从实际需求出发,比如我们有如下需求:
kmalloc/kfree时间戳kmalloc/kfree堆栈信息内存重复释放申请内存模块id访问释放后的内存
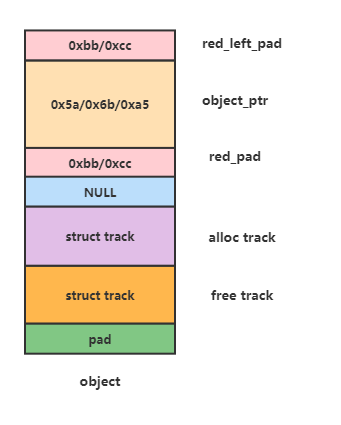
图9 object内存结构
前一小节介绍了,slab分配器会将大块内存划分成多个小块内存,每一个小块内存对应一个object结构(如图9),对于上面的需求,基本思路就是给每个object多分配一些内存,用来存储与该内存块相关的额外信息。下面分析下object内存结构。
red_left_pad:该区域会填充两个值0xbb或0xcc,分别表示该内存块是否被使用,这个区域就可以用来做一些内存检查。
/* linux/poison.h */#define SLUB_RED_INACTIVE 0xbb#define SLUB_RED_ACTIVE 0xcc
object_ptr:该区域是真正给申请都使用的内存区域,如果开启毒化功能的话,该区域会填充0x5a、0x6b、0xa5,从伙伴系统申请大块内存后,会填充成0x5a,划分成小块后会填充0x6b,而该区域最后一个字节填充0xa5,这个区域也可以用来做一些内存检查。
/* linux/poison.h *//* ...and for poisoning */#define POISON_INUSE 0x5a /* for use-uninitialised poisoning */#define POISON_FREE 0x6b /* for use-after-free poisoning */#define POISON_END 0xa5 /* end-byte of poisoning */
track:该区域用来记录内存申请或者释放相关的信息,比如申请或释放的堆栈,申请或释放的cpu/pid/时间等信息。
/* mm/slub.c */
/* * Tracking user of a slab. */#define TRACK_ADDRS_COUNT 16struct track { unsigned long addr; /* Called from address */#ifdef CONFIG_STACKTRACE unsigned long addrs[TRACK_ADDRS_COUNT]; /* Called from address */#endif int cpu; /* Was running on cpu */ int pid; /* Pid context */ unsigned long when; /* When did the operation occur */};
所以当进行内存的申请与释放时,只需要把这些额外的信息记录下来就可以了。
总结
内存分配设计的两个维度,提高内存的利用率,减少内存分配时的延时与CPU占用率。
页分配器用来解决外部碎片问题,块分配器用来解决内部碎片问题,从而提高内存的利用率。
页分配器与块分配器的算法简单、高效。
其它
实验环境
kernel version:v5.12
qemu version:v6.0.0
参考
http://www.wowotech.net/memory_management/426.html
http://www.wowotech.net/memory_management/427.html
https://blog.csdn.net/weixin_42319496/article/details/125940807
https://zhuanlan.zhihu.com/p/149581303
《现代操作系统原理与实现》
《Linux内核深度解析》
如果你觉得你现在走得辛苦,那就证明你在走上坡路。🔥 网络
免责声明:
该内容由专栏作者授权发布或作者转载,目的在于传递更多信息,并不代表本网赞同其观点,本站亦不保证或承诺内容真实性等。若内容或图片侵犯您的权益,请及时联系本站删除。侵权投诉联系:
nick.zong@aspencore.com!
 Linux阅码场
专业的Linux技术社区和Linux操作系统学习平台,内容涉及Linux内核,Linux内存管理,Linux进程管理,Linux文件系统和IO,Linux性能调优,Linux设备驱动以及Linux虚拟化和云计算等各方各面.
进入专栏
评论
Linux阅码场
专业的Linux技术社区和Linux操作系统学习平台,内容涉及Linux内核,Linux内存管理,Linux进程管理,Linux文件系统和IO,Linux性能调优,Linux设备驱动以及Linux虚拟化和云计算等各方各面.
进入专栏
评论
-
IPC-2581是基于ODB++标准、结合PCB行业特点而指定的PCB加工文件规范。 IPC-2581旨在替代CAM350格式,成为PCB加工行业的新的工业规范。 有一些免费软件,可以查看(不可修改)IPC-2581数据文件。这些软件典型用途是工艺校核。 1. Vu2581 出品:Downstream
-
临近春节,各方社交及应酬也变得多起来了,甚至一月份就排满了各式约见。有的是关系好的专业朋友的周末“恳谈会”,基本是关于2025年经济预判的话题,以及如何稳定工作等话题;但更多的预约是来自几个客户老板及副总裁们的见面,他们为今年的经济预判与企业发展焦虑而来。在聊天过程中,我发现今年的聊天有个很有意思的“点”,挺多人尤其关心我到底是怎么成长成现在的多领域风格的,还能掌握一些经济趋势的分析能力,到底学过哪些专业、在企业管过哪些具体事情?单单就这个一个月内,我就重复了数次“为什么”,再辅以我上次写的:《
-
现在为止,我们已经完成了Purple Pi OH主板的串口调试和部分配件的连接,接下来,让我们趁热打铁,完成剩余配件的连接!注:配件连接前请断开主板所有供电,避免敏感电路损坏!1.1 耳机接口主板有一路OTMP 标准四节耳机座J6,具备进行音频输出及录音功能,接入耳机后声音将优先从耳机输出,如下图所示:1.21.2 相机接口MIPI CSI 接口如上图所示,支持OV5648 和OV8858 摄像头模组。接入摄像头模组后,使用系统相机软件打开相机拍照和录像,如下图所示:1.3 以太网接口主板有一路
-
光伏及击穿,都可视之为 复合的逆过程,但是,复合、光伏与击穿,不单是进程的方向相反,偏置状态也不一样,复合的工况,是正偏,光伏是零偏,击穿与漂移则是反偏,光伏的能源是外来的,而击穿消耗的是结区自身和电源的能量,漂移的载流子是 客席载流子,须借外延层才能引入,客席载流子 不受反偏PN结的空乏区阻碍,能漂不能漂,只取决于反偏PN结是否处于外延层的「射程」范围,而穿通的成因,则是因耗尽层的过度扩张,致使跟 端子、外延层或其他空乏区 碰触,当耗尽层融通,耐压 (反向阻断能力) 即告彻底丧失,
-
嘿,咱来聊聊RISC-V MCU技术哈。 这RISC-V MCU技术呢,简单来说就是基于一个叫RISC-V的指令集架构做出的微控制器技术。RISC-V这个啊,2010年的时候,是加州大学伯克利分校的研究团队弄出来的,目的就是想搞个新的、开放的指令集架构,能跟上现代计算的需要。到了2015年,专门成立了个RISC-V基金会,让这个架构更标准,也更好地推广开了。这几年啊,这个RISC-V的生态系统发展得可快了,好多公司和机构都加入了RISC-V International,还推出了不少RISC-V
-
2024年是很平淡的一年,能保住饭碗就是万幸了,公司业绩不好,跳槽又不敢跳,还有一个原因就是老板对我们这些员工还是很好的,碍于人情也不能在公司困难时去雪上加霜。在工作其间遇到的大问题没有,小问题还是有不少,这里就举一两个来说一下。第一个就是,先看下下面的这个封装,你能猜出它的引脚间距是多少吗?这种排线座比较常规的是0.6mm间距(即排线是0.3mm间距)的,而这个规格也是我们用得最多的,所以我们按惯性思维来看的话,就会认为这个座子就是0.6mm间距的,这样往往就不会去细看规格书了,所以这次的运气
-
Ubuntu20.04默认情况下为root账号自动登录,本文介绍如何取消root账号自动登录,改为通过输入账号密码登录,使用触觉智能EVB3568鸿蒙开发板演示,搭载瑞芯微RK3568,四核A55处理器,主频2.0Ghz,1T算力NPU;支持OpenHarmony5.0及Linux、Android等操作系统,接口丰富,开发评估快人一步!添加新账号1、使用adduser命令来添加新用户,用户名以industio为例,系统会提示设置密码以及其他信息,您可以根据需要填写或跳过,命令如下:root@id
-
本文介绍瑞芯微开发板/主板Android配置APK默认开启性能模式方法,开启性能模式后,APK的CPU使用优先级会有所提高。触觉智能RK3562开发板演示,搭载4核A53处理器,主频高达2.0GHz;内置独立1Tops算力NPU,可应用于物联网网关、平板电脑、智能家居、教育电子、工业显示与控制等行业。源码修改修改源码根目录下文件device/rockchip/rk3562/package_performance.xml并添加以下内容,注意"+"号为添加内容,"com.tencent.mm"为AP
-
日前,商务部等部门办公厅印发《手机、平板、智能手表(手环)购新补贴实施方案》明确,个人消费者购买手机、平板、智能手表(手环)3类数码产品(单件销售价格不超过6000元),可享受购新补贴。每人每类可补贴1件,每件补贴比例为减去生产、流通环节及移动运营商所有优惠后最终销售价格的15%,每件最高不超过500元。目前,京东已经做好了承接手机、平板等数码产品国补优惠的落地准备工作,未来随着各省市关于手机、平板等品类的国补开启,京东将第一时间率先上线,满足消费者的换新升级需求。为保障国补的真实有效发放,基于
-
万万没想到!科幻电影中的人形机器人,正在一步步走进我们人类的日常生活中来了。1月17日,乐聚将第100台全尺寸人形机器人交付北汽越野车,再次吹响了人形机器人疯狂进厂打工的号角。无独有尔,银河通用机器人作为一家成立不到两年时间的创业公司,在短短一年多时间内推出革命性的第一代产品Galbot G1,这是一款轮式、双臂、身体可折叠的人形机器人,得到了美团战投、经纬创投、IDG资本等众多投资方的认可。作为一家成立仅仅只有两年多时间的企业,智元机器人也把机器人从梦想带进了现实。2024年8月1
-
高速先生成员--黄刚这不马上就要过年了嘛,高速先生就不打算给大家上难度了,整一篇简单但很实用的文章给大伙瞧瞧好了。相信这个标题一出来,尤其对于PCB设计工程师来说,心就立马凉了半截。他们辛辛苦苦进行PCB的过孔设计,高速先生居然说设计多大的过孔他们不关心!另外估计这时候就跳出很多“挑刺”的粉丝了哈,因为翻看很多以往的文章,高速先生都表达了过孔孔径对高速性能的影响是很大的哦!咋滴,今天居然说孔径不关心了?别,别急哈,听高速先生在这篇文章中娓娓道来。首先还是要对各位设计工程师的设计表示肯定,毕竟像我
-
数字隔离芯片是一种实现电气隔离功能的集成电路,在工业自动化、汽车电子、光伏储能与电力通信等领域的电气系统中发挥着至关重要的作用。其不仅可令高、低压系统之间相互独立,提高低压系统的抗干扰能力,同时还可确保高、低压系统之间的安全交互,使系统稳定工作,并避免操作者遭受来自高压系统的电击伤害。典型数字隔离芯片的简化原理图值得一提的是,数字隔离芯片历经多年发展,其应用范围已十分广泛,凡涉及到在高、低压系统之间进行信号传输的场景中基本都需要应用到此种芯片。那么,电气工程师在进行电路设计时到底该如何评估选择一
Linux阅码场
专业的Linux技术社区和Linux操作系统学习平台,内容涉及Linux内核,Linux内存管理,Linux进程管理,Linux文件系统和IO,Linux性能调优,Linux设备驱动以及Linux虚拟化和云计算等各方各面.
文章:1337篇
粉丝:55人
最近文章
热门文章
广告
在线研讨会
-
-
-
-
EE直播间
-
Fabless100系列技术和应用直播 —实时控制、BMS:国产MCU迈向高性能应用
直播时间:02月18日 10:00
-
高效协同与版本管理:Cliosoft助力现代芯片设计
直播时间:02月26日 10:00
-
第三代功率半导体器件测试解决方案
直播时间:03月06日 10:00
E聘热招职位
资料
文库
帖子
博文
-
1
元能芯24V全集成电机专用开发板
-
2
电子元器件检测技能速成
-
3
晶体管电路设计-铃木雅臣(上).pdf
-
4
开关电源设计 反激控制思路的了解-4
-
5
静电学手册 21312321
-
6
开关电源设计 反激电路设计
-
7
基于单片机自动电阻测试仪设计论文
-
8
智算中心建设导则
-
9
开关电源设计 反激控制思路的了解-3
-
10
基于Labview的家居控制平台设计论文
我要评论
0
-
分享到微信
点击右上角,分享到朋友圈
我知道啦
请使用浏览器分享功能
我知道啦
提示!
您尚未开通专栏,立即申请专栏入驻
