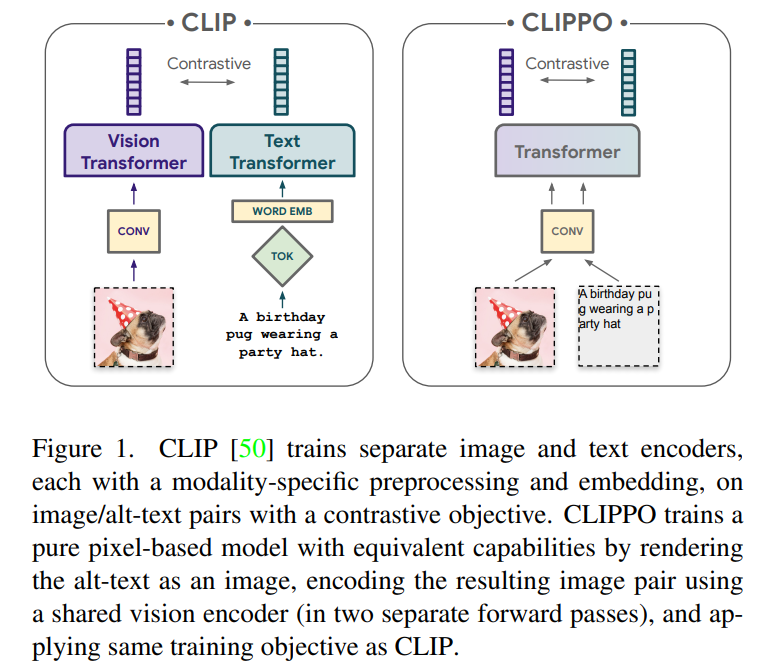
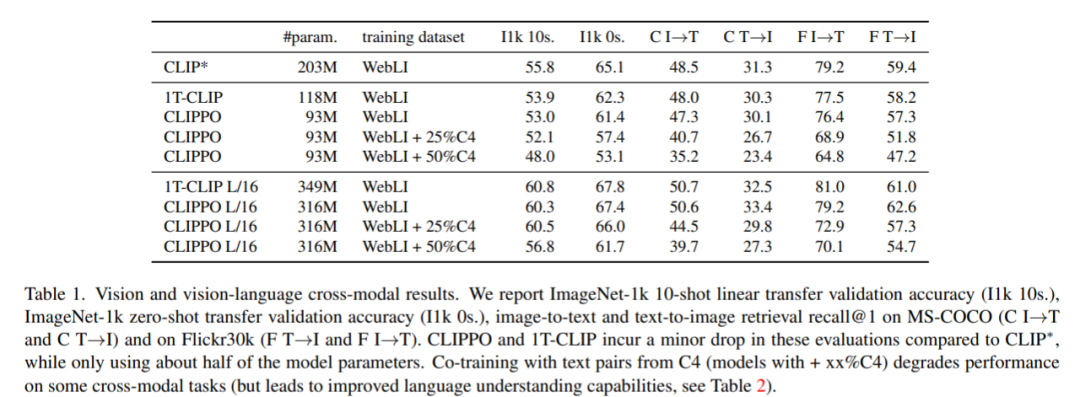
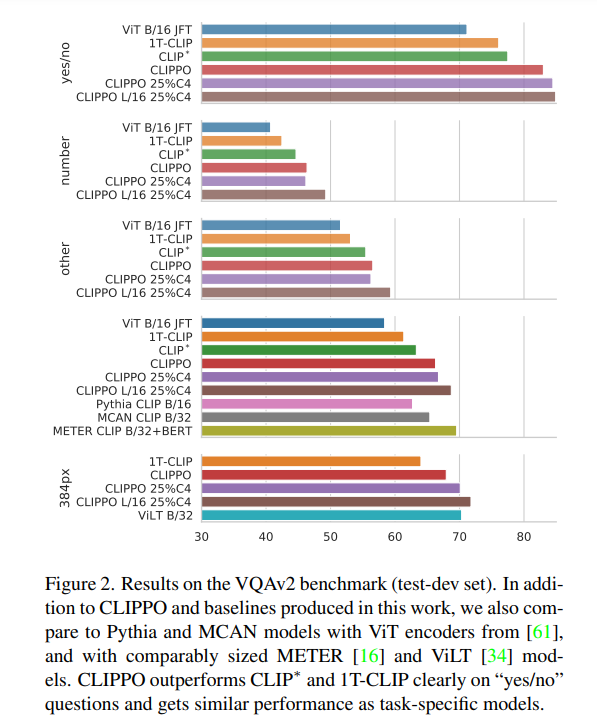
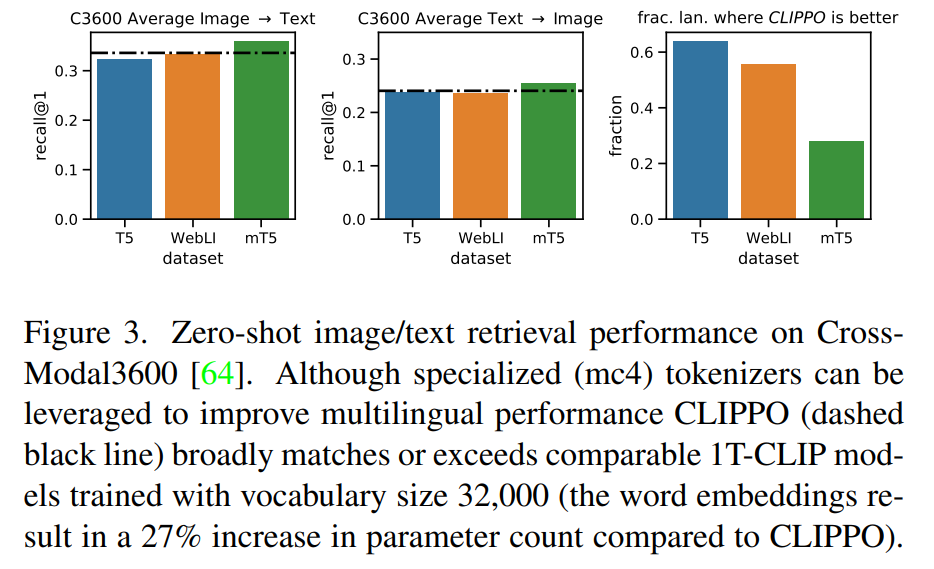
后摄像头是长这个样子,如下图。5孔(D-,D+,5V,12V,GND),说的是连接线的个数,如下图。4LED,+12V驱动4颗LED灯珠,给摄像头补光用的,如下图。打开后盖,发现里面有透明白胶(防水)和白色硬胶(固定),用合适的工具,清理其中的胶状物。BOT层,AN3860,Panasonic Semiconductor (松下电器)制造的,Cylinder Motor Driver IC for Video Camera,如下图。TOP层,感光芯片和广角聚焦镜头组合,如下图。感光芯片,看着是玻