二阶段投资 400 亿美元。该工厂将分别生产 N5 和 N3 系列芯片。本报告将涵盖工艺节点过渡、台积电最先进技术的过高成本,以及它将如何显着加速行业向先进封装和小芯片的转变。此外,我们将详细介绍 N5、N4、N3B 和 N3E 的各种间距、特性和 SRAM 单元尺寸。
台积电5nm晶圆厂成本
2018年初,台积电宣布投资新晶圆厂。这个新站点将拥有其最先进的技术 N5。随着苹果和华为承诺在 2020 年生产 N5 晶圆,这是进行大规模扩建的绝佳机会。台积电表示,他们对 Fab 18 第一至第三阶段的投资将超过新台币 5000 亿元,约合 170 亿美元。该站点计划每月生产超过 80,000 个晶圆。在 2020 年第一季度的财报电话会议上,台积电确认 N5 正在大批量生产,可能处于第一阶段。
尽管台南科学园区的 Fab 18 仍将是 N5 生产的主要地点,但台积电还宣布将其业务扩展到美国亚利桑那州凤凰城。2018年年中,台积电宣布该厂总投资120亿美元,月产2万片晶圆。这座工厂建成后,将成为台积电在中国台湾以外制造的最先进的技术节点。到 2022 年,台积电的 N5 产能将远超每月 12 万片晶圆,这仅占台积电 N5 产能的 15% 左右。
乍一看,中国台湾台南 N5 的第 1 至 3 期设施规模扩大了 4 倍,但成本仅高出 40%,这证明了在没有大量补贴的情况下在美国建造晶圆厂在经济上没有意义的论点。实际上,这些数字没有可比性。台积电为美国晶圆厂提供的数字包括 2021 年至 2029 年的所有总支出。这远远超过了最初的资本支出成本。台积电给中国台湾晶圆厂的数字只是最初的扩建,没有其他成本。
应该注意的是,在初始扩建期间,晶圆厂总成本的约 80% 来自设备。此外,超过 60% 的运营成本来自材料、化学品、工具维护和能源投入。无论晶圆厂位于何处,这些成本大多相同(能源确实不同)。
台积电 3nm 晶圆厂成本
位于台南科学园区的 Fab 18 也是生产 N3 系列节点的主要地点。位于新竹科学园区的 Fab 12 第 8 期和第 9 期也将生产该节点。近日,台积电又宣布投资Fab 21 Phase 2 。这扩大了其在亚利桑那州的现有工厂,以生产 N3 晶圆。亚利桑那州的新计划将使台积电的总支出增加到 400 亿美元,并将产能增加到每月 50,000 片晶圆。其中 20,000 个仍将是 N5,30,000 个将是 N3。完成后,N3 产能将占台积电全球 N3 产能的 25%。
这将是台积电首次分享同一地点不同代工厂之间的完整成本比较。由于成本超支的传言,台积电的 N5 晶圆厂成本可能已从最初的 120亿美元 增加到 130亿美元。最有可能的是,这些成本处于该范围的中间。
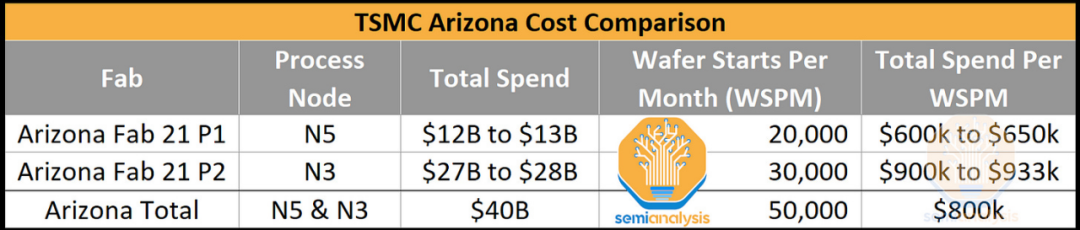
每个晶圆开始的每月总支出从 38% 增加到 55%。这与我们听到的 N3 定价比 N5 高出约 40% 的其他传言非常吻合。与DigiTimes 的传言相反,晶圆价格不是 20,000 美元。
N3 的故事很复杂。最初,考虑到不温不火的性能、功率和密度改进,N3 的产量和价格都具有挑战性,超出了大多数客户愿意支付的价格。它有大约 25 个 EUV 层,几乎是 N5 的两倍。N3 出现了许多问题,最终导致台积电错过了典型的 2 年主要工艺节点发布周期。对公众来说最值得注意的变化是,随着摩尔定律的放缓,苹果公司被迫彻底改变其产品的芯片计划。
除了将 N3 从 2022 款 iPhone 推出到 2023 款 iPhone Pro 之外,许多其他客户也放弃了他们最初的 N3 计划。关于 Zen 5、英特尔 GPU 和一些 Broadcom 定制 ASIC 存在许多谣言。据传,这些公司选择坚持使用 N5 级工艺节点或转向宽松的 N3E 工艺。最初的 N3 被大多数人称为 N3B,并且不会超越 Apple。我们将在本报告后面深入探讨技术差异,但 N3E 与 N5 类工艺节点共享相同的 SRAM 位单元大小,并减少了 EUV 曝光的次数。
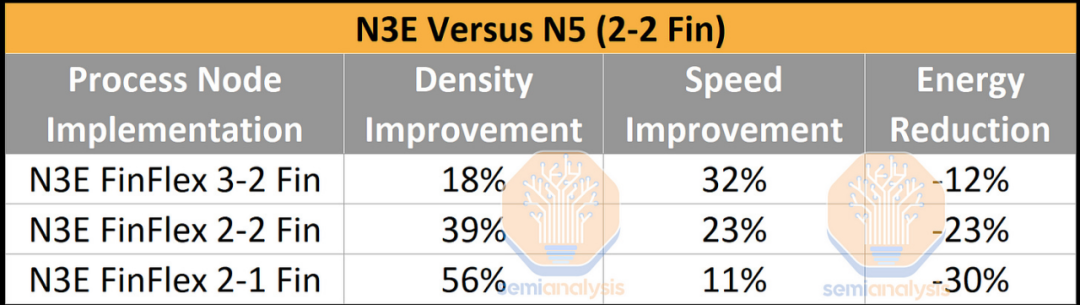
密度的提高充其量只是略高于晶圆成本的增加。通过 FinFlex 2-1 实施,密度提高了 56%,成本增加了 40%。这导致每个晶体管的成本降低了 11%,这是 50 多年来主要工艺技术的最弱扩展。
其他实现要么在每个晶体管的成本上持平,要么甚至为负,但每个晶体管的速度都有更大的改进。请注意,上述一代又一代的改进是使用 Arm Cortex A72 测量的。密度改进将根据正在实施的 IP 而有所不同。
大多数芯片设计不会实现 56% 的密度提升,而是低得多,约为 30%。这意味着每个晶体管的成本增加,但公司正在调整设计以确保不会发生这种情况。这将在工艺技术部分进行解释。
3nm 实施成本
当采用最先进的工艺技术实现芯片的成本变得更高时,转向 3nm 或留在 N5 系列的决定变得更加棘手。
我们在上面详细解释了这个问题,但在最新的工艺技术中实施产品的固定成本变得如此之大,以至于对公司来说意味着巨大的风险。延迟变得越来越棘手,重新设计的成本越来越高,最糟糕的是,实现每晶体管成本改进所需的体积越来越大。
出于这个原因,许多公司将在未来很长一段时间内坚持使用 N5 级工艺节点。许多其他公司只会将计算小芯片转移到 N3 类,同时保留所有其他 IP,例如 SRAM 和模拟的旧工艺技术。台积电 N3 将导致小芯片和先进封装的爆炸式增长。
在我们进入 N3 工艺细节之前,我们想详细介绍一下 N5 系列,因为它真实地证明了台积电的惊人之处。迭代的不是一个流程节点,而是最适合每种不同类型客户需求的许多并发风格和修改。
5nm工艺族技术详解
台积电 N5 系列的一部分包括:N5、N5P、N5A、N4、N4P 和 N4X。除了那些已宣布的变体之外,我们预计台积电将在未来几年内发布 RF 优化和泄漏优化版本。通过所有这些变体,台积电希望延长工艺技术的寿命,并将更多客户推向 N4 节点,部分原因是它们的生产成本较低,客户的固定成本也较低。N4 是量产的最新节点,已在联发科天玑 9200、高通骁龙 8 Gen 2 和 Apple A16 中实现。
N5 是一个工程奇迹,在其发布时无疑是最先进的节点。台积电宣布其逻辑密度提高1.84倍,同等功耗下性能提升15%,同等性能下功耗降低30%。虽然无数芯片在性能和功率方面确实得到了改进,但似乎从未实现过规定的密度增益。
正如 Angstronomics 最近报道的那样,这是因为台积电撒谎了。逻辑密度的增益接近 52%。虽然台积电可能在密度上撒了谎,但台积电N5仍然是量产中最好的节点。
N5 的鳍间距为 28nm,仅略低于三星 5LPE,接触栅极间距为 51nm,仅略低于 Intel 4。通过连续扩散的新方法,他们设法减小了单元宽度。
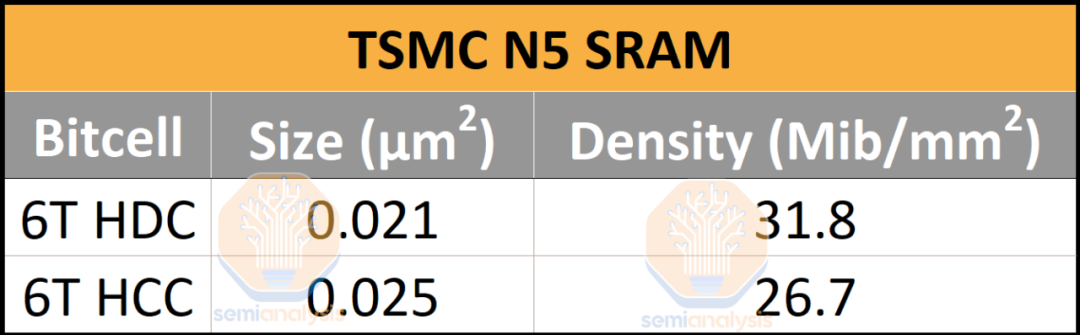
N5 在 M0 上的最小金属间距为 28nm,比 N7 减少了 30%。这将有助于减少可能由信号和电源路由引起的瓶颈。台积电的 M2 金属间距为 35 纳米,拥有一个 6 轨标准单元,尽可能密集,使用带有 2 个 PMOS 鳍片和 2 个 NMOS 鳍片的 FinFET。N5 还拥有最小的 6T 高密度 SRAM 位单元,尺寸为 0.021 μm2,低于 Intel 4 的 0.0240 μm2 和三星 4LPE 的 0.0262 μm2 位单元。台积电 的 6T 高电流 SRAM 位单元也非常小,只有 0.025 μm2,是迄今为止密度第三高的。
N5P是N5的流程优化。通过增强工艺的 FEOL 和 MOL,台积电的性能提高了 7%,功耗降低了 15%。虽然这看起来可能不多,但好处是这种流程优化与 N5 是 IP 兼容的。任何 N5 设计都可以轻松移植到 N5P 并看到这些收益。随着半导体设计固定成本的飙升,其影响不可低估。

N4是N5的另一项工艺优化,但它有一个小的设计收缩。这也称为“小节点”。通过标准单元库的优化、较小的光学收缩和设计规则的改变,N4 实现了更好的面积效率。N4 还减少了掩模数量和工艺复杂性。这使得台积电能够以低于每片晶圆 N5 的成本生产 N4。
Nikkei Asia曾有传言称 Apple A16 的制造成本是其制造商的 2 倍,但这完全是错误的。与 N5P 非常相似,通过改进 FEOL 和 MOL 改进了功率和性能特征。
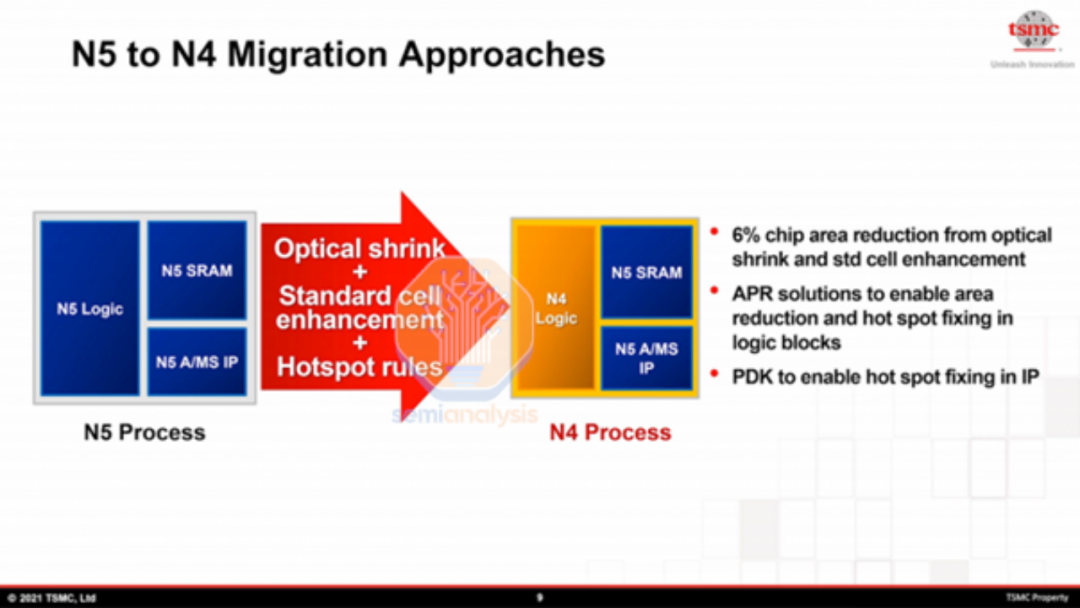
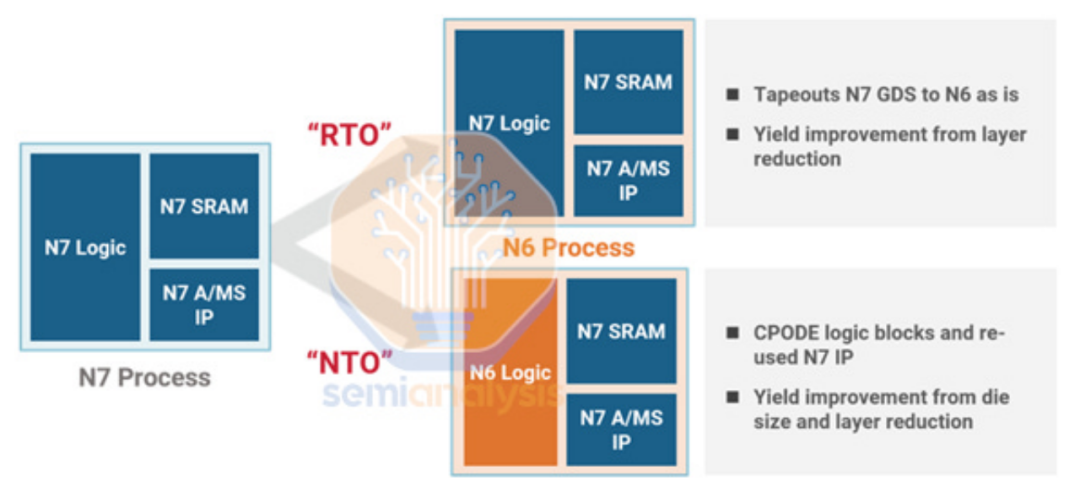
与台积电的其他 nodelet N6 一样,N4 提供了两种从现有 N5 设计迁移的方法。两者都有其权衡取舍。首先是 RTO 或重新流片,涉及使用与 N5 相同的设计规则。这更便宜,需要更少的工程,并且提供更少的 N4 的好处。这就是联发科能够在风险生产后这么快就在“N4”上发布天玑 9000 的原因。
接下来是 NTO 或新流片,这需要使用 N4 提供的最新库和更多优化来重新实现逻辑块。这需要更多的工程,但提供了更多的好处,包括较小的面积缩小。
2021 年底,台积电宣布 N4P ,这是 N4 的工艺优化。通过进一步改进 FEOL 和 MOL,台积电 的性能比 N4 又提高了 6%,功耗比 N5 降低了 22%。现在进入专业技术;N5A基于台积电的N5工艺。这个节点在技术上并不是特别独特。但是,它已通过汽车公司在使用工艺节点时寻求的所有标准的认证。它经过优化,可以在车辆中长时间(10 年或 20 年)存活而不会降解。
N4X 是台积电首款 HPC 优化制程技术。N4X 针对超过 1.2V 的高压设备进行了优化,性能比 N4P 提高了 4%。FEOL 对鳍片进行了改进,以允许更高的电流、电压和更高的频率。金属堆栈经过精心设计,可通过降低电阻和寄生电容来改善这些高性能设备的功率传输和信号完整性。金属堆栈还具有改进的金属金属电容器,可通过减少电压降并将性能进一步提高 2-3% 来提供更强大的电力传输。
为了达到如此高的频率,可能放宽了一些设计规则,但这可能不是问题,因为高性能设备更受金属堆叠的限制,无论如何都无法利用密度。在泄漏方面也有一些让步,必须做出这些让步才能实现更高的性能。大多数半导体公司不会使用此节点,因为他们更喜欢较低的功耗/泄漏,但 N4X 是一些最高性能应用的有力竞争者。
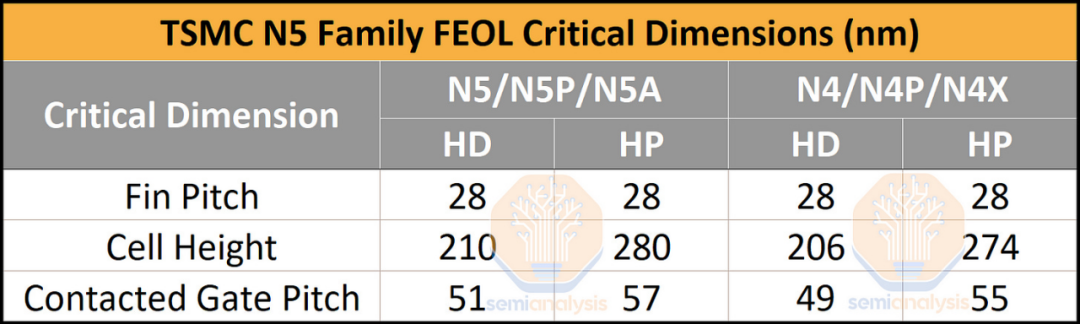
现在,我们将讨论 N5 系列节点的关键间距,并专门详细介绍台积电的 N4 节点的间距。N5 的高密度 (HD) 库的鳍间距为 28nm,具有 8 条扩散线,单元高度为 210nm。接触栅极间距 (CGP) 为 51nm。N5 的高性能 (HP) 库具有相同的间距,但为 280nm 的单元高度添加了 2 条扩散线。高性能库还将 CGP 略微放宽至 57nm,从而实现更高的性能。正如台积电所说,N4 通过光学缩小提供了 6% 的面积减少。为实现这一目标,HD 和 HP 库的单元高度分别缩小到 206 纳米和 274 纳米。此外,CGP已经缩小到49nm和55nm。
N5 为其最低金属层提供 28nm 的间距,这是生产中最小的。这也是节点的最小金属间距。它还提供 35nm 的金属 2 间距,这是生产中最小的间距。
正如我们所提到的,N5 在每个 6T HD 和 HP 位单元类别中都具有生产中最密集的位单元。借助 30% 的辅助电路开销,HD SRAM 密度达到 31.8 Mib/mm2,HP SRAM 密度达到 26.7 Mib/mm2。尽管 N4 并未带来 SRAM 位单元尺寸的进一步缩小,但台积电仍处于领先地位。
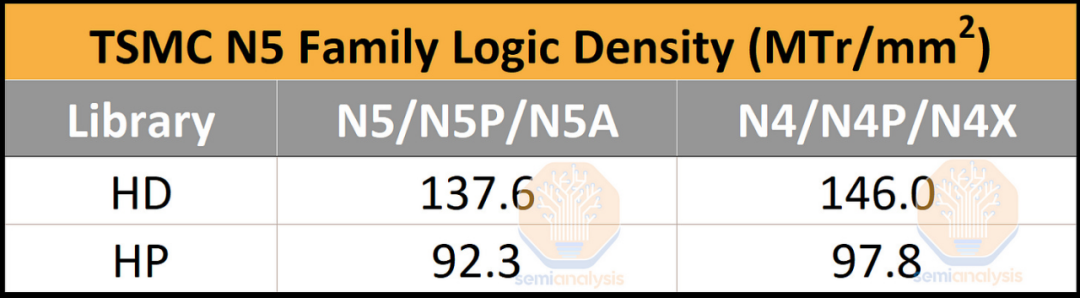
现在,进入主要吸引力,逻辑密度。虽然这可能是最引人注目的数字,但它并不能单独描述一个节点。必须考虑所有其他特性,从其 SRAM 位单元到功率和性能。这些指标是使用 Bohr 公式计算的,该公式将 60% 的权重分配给小而稀疏的 NAND2 单元,将 40% 的权重分配给大但密集的 Scan Flip-Flop 单元。台积电在这一指标上处于领先地位,但在其他因素上略逊一筹。
虽然其HD库的密度是生产中最高的,但其HP库的密度落后于Intel 4的HP。需要明确的是,根据英特尔的说法,intel 4 已经“准备好制造”,但真正的大批量生产还需要几个季度。然而,密度是使用台积电的 N5 系列节点的最诱人的原因之一。
台积电的 N5 系列是一组出色的节点,单靠这些指标并不能说明问题。它在功率、性能、面积、易用性、IP 生态系统和成本方面的组合是无与伦比的。
N3技术节点
N3 系列节点包括 N3B、N3E、N3P、N3X 和 N3S。其中许多是针对特定目的优化的小节点,但有所不同。N3B,即原来的 N3,与 N3E 无关。与其将其视为 nodelet,不如将其视为一个完全不同的节点。
在 IEDM 2022 上,台积电透露了 N3B 的一些方面。N3B 具有 45nm 的 CGP,与 N5 相比缩小了 0.88 倍。台积电还实施了自对准接触,从而可以更大程度地扩展 CGP。我们将在以后的系列中详细介绍这一点以及其他 DTCO 缩放。台积电还展示了 0.0199 μm2 的 6 晶体管高密度 SRAM 位单元。这仅缩小了 5%,这对于 SRAM 未来的扩展来说是个坏兆头。
近年来,芯片设计人员严重依赖 SRAM 来提高性能。SRAM 缩放的消亡带走了提高性能的一个重要杠杆,并将增加架构在提高功率和性能特征方面的重要性。

与N5相比,台积电最初表示,N3在同等功率下性能提升约12%,同等性能下功耗降低27%。这将具有 1.2× SRAM 密度和 1.1× 模拟密度。
IEDM 上公开的高密度位单元仅将 SRAM 密度提高了约 5%,与最初声称的 20% 相去甚远。
在 IEDM 期间,台积电透露 N3B 的 CGP 为 45nm,是迄今为止透露的最密集的。这领先于Intel 4的50nm CGP、三星4LPP的54nm CGP和台积电 N5的51nm CGP。
虽然逻辑密度的增加无疑是有希望的,但低 SRAM 密度增益意味着 SRAM-heavy 设计可能会经历显着的成本增加。N3B 的良率和金属堆叠性能也很差。基于这些原因,N3B 不会成为台积电的主要节点。

由于 N3B 未能达到台积电的性能、功率和产量目标,因此开发了 N3E。其目的是修复N3B的缺点。第一个重大变化是金属间距略有放松。台积电没有在 M0、M1 和 M2 金属层上使用多重图案化 EUV,而是退缩并切换到单一图案化。
这是在保持功率和性能数据相似的同时实现的。逻辑密度也略有下降。此外,使用标准单片芯片(50% 逻辑 + 30% SRAM + 20% 模拟),密度仅增加 1.3 倍。
在 IEDM 期间,台积电透露 N3E 的位单元尺寸为 0.021 μm2,与 N5 完全相同。这对SRAM来说是毁灭性的打击。由于良率,台积电放弃了 SRAM 单元尺寸而不是 N3B。
N3E 比 N3B 做得好得多,明年年中将量产。这是 AMD、Nvidia、Broadcom、Qualcomm、MediaTek、Marvell和许多其他公司最终将使用 N3E 作为其领先优势的节点。
与台积电为其 N7 和 N5 系列节点推出的先前 nodelet 不同,N3E 与 N3B IP 不兼容。这意味着必须重新实现 IP 块。因此,许多公司,例如 GUC,选择只在更持久的 N3E 节点上实现他们的 IP。
N3P 将是 N3E 的后续节点。它与 N5P 非常相似,通过优化提供较小的性能和功率增益,同时保持 IP 兼容性。N3X 与 N4X 类似,并针对非常高的性能进行了优化。到目前为止,功率、性能目标和时间表尚未公布。
N3S 是最终公开的变体,据说是密度优化的节点。目前知道的不多,但有一些谣言。Angstronomics 认为这可能是一个单鳍库,可以让台积电进一步缩小单元高度。由于金属堆叠的限制因素,这可能会受到限制,但设计会尽可能使用它。N3S 甚至可能实施背面供电网络来缓解许多金属堆叠问题,尽管这尚未得到证实。
作为台积电的最后一个 FinFET 节点,N3E 及其后续节点有机会获得与台积电最成功的节点之一 N28 类似的地位。鉴于其动荡的历史,这将是一项艰巨的任务,但台积电已经多次证明了自己的能力,尤其是在其生态系统方面。
编译自semianalysis
推荐阅读


添加微信回复“进群”
拉你进技术交流群!
国产芯|汽车电子|物联网|新能源|电源|工业|嵌入式…..