CV-CUDA (Computer Vision – Compute Unified Device Architecture)高性能图像处理加速库,近日发布 Alpha 版本,正式向全球开发者开源。
用户可在 GitHub:https://github.com/CVCUDA/CV-CUDA 下载和试用。
CV-CUDA 是一个开源项目,可在 AI 成像和计算机视觉 (CV) 流程中通过 GPU 加速构建高效的预处理和后处理步骤。CV-CUDA 前期由 NVIDIA 和字节跳动的机器学习团队联合开发。

CV-CUDA 应用场景
随着短视频 APP、视频会议平台以及 VR/AR 等技术的发展,视频与图像已逐渐成为全球互联网流量的主要组成部分。包含我们平时接触到的这些视频图像,也有很多是被 AI 和计算机视觉(CV)算法处理并增强过的。然而,随着社交媒体和视频分享服务的快速增长,作为 AI 图像算法基础的视频图像处理部分,也早已成为计算流程中不可忽视的成本和瓶颈。我们先带大家简单回顾一下图像处理的一些常见的例子,以更好地理解 CV-CUDA 的应用场景。
(1)AI 算法图像背景模糊化

图 1. AI 背景模糊(CPU 前后处理方案)
图像背景模糊化通常会被应用于视频会议,美图修图等场景。在这些场景中,我们通常希望 AI 算法可以把主体之外的背景部分模糊化,这样可以保护用户隐私,美化图像等。图像背景模糊化的流程大体可以分为 3 个过程:前处理,DNN 网络以及后处理过程。前处理过程,通常包含了对图像做 Resize、Padding、Image2Tensor 等操作;DNN 网络可以是一些常见 segmentation network,比如 Unet 等;后处理过程,通常包括 Tensor2Mask、Crop、Resize、Denoise 等操作。
在传统的图像处理流程中,前处理和后处理部分通常都是使用 CPU 进行操作,这导致整个图像背景模糊化流程中,有 90% 的工作时间消耗在前后处理部分,因而成为了整个算法流水线的瓶颈。若能把前后处理妥善利用 GPU 加速,这将能大幅提升整体的计算性能。

图 2. AI 背景模糊(GPU 前后处理方案)
当我们把前后处理部分都放到 GPU 上后,我们就可以对整个 pipeline 进行端到端的 GPU 加速。经过测试,在单个 GPU 上,相比于传统图像处理方式,把整个 pipeline 移植到 GPU 后,可以获得 20 倍以上的吞吐率提升。这无疑会大大的节省计算成本。
(2)AI 算法图像分类

图 3. AI 图像分类
图像分类是最常见的 AI 图像算法之一,通常可以用于物体识别,以图搜图等场景,几乎是所有 AI 图像算法的基础。图像分类的 pipeline 大体可以分为 2 个部分:前处理部分和 DNN 部分。其中前处理部分,在训练和推理过程中最常见的 4 种操作包括:图片解码、Resize、Padding、Normalize。DNN 部分已经有了 GPU 的加速,而前处理部分通常都会使用 CPU 上的库函数进行处理。如果能够把前处理部分也移植到 GPU 上,那么一方面可以释放 CPU 资源,另一方面也可以进一步提升 GPU 利用率,从而可以对整个 pipeline 进行加速。
当前图像处理主流方案
针对前后处理部分,我们总结一下目前已有的一些主流应用方案:
(1)目前应用最广泛的图像处理库是 OpenCV
前后处理中的操作,往往是依赖于任务类型的,这导致了前后处理相关的操作种类繁多,数量庞杂。利用 OpenCV 确实可以实现大部分的图像处理操作,不过,这些操作大部分是用 CPU 实现的,缺少对应的 GPU 加速版本。而部分 CPU 操作虽然存在对应的 GPU 版本,但是这些 GPU 版本的实现可能存在一些问题,包括:
a. 部分算子的 CPU 和 GPU 结果无法对齐。在某些场景下,我们的算法团队使用了 CPU 的算子进行训练,而在推理阶段负责部署的同学考虑到性能问题,决定使用 GPU 算子,然而在测试过程中,发现 CPU 和 GPU 算子结果无法对齐,这可能会导致端到端的处理结果出现精度异常。
b. 部分算子 GPU 性能比 CPU 性能还弱。除了某些算法本身就不太适合 GPU 化之外,我们还发现部分 GPU 实现并不是很高效。比如,有些算子会在运行过程中,临时申请显存空间,导致增加了额外的耗时。
c. 在真实的部署 pipeline 中,可能有些算子只有 CPU 版本,而有些算子既有 CPU 版本又有 GPU 版本。如果 pipeline 里既有 CPU 算子又有 GPU 算子,那么会存在 GPU 和 CPU 同步,以及 H2D,D2H 内存拷贝问题,从而引入额外的耗时。
(2)使用 PyTorch 框架进行模型训练引入的 torchvision 图像处理库
在算法开发阶段,出于训练考虑,算法工程师可能会优先使用 torchvision 来完成图像处理操作。然而在模型部署阶段,负责模型部署的工程师通常会使用 C++ 作为开发语言,没有办法使用 torchvision 完成图像处理操作,那么可能会使用其他的 C++ 图像处理库,比如 OpenCV,然而这就涉及到,torchvision 和 OpenCV 结果对齐的问题。此外,与使用 OpenCV 的情况类似,torchvision 中的算子也有不支持 GPU 加速,或者 GPU 加速效果不佳的情况。
CV-CUDA 特点
如上所述,传统的图像预处理操作一般在 CPU 上进行,一方面会占用大量的 CPU 资源,使得 CPU 和 GPU 的负载不均衡;另一方面由于基于 CPU 的图像加速库不支持 batch 操作,导致预处理的效率低下。为了解决当前主流的图像处理库所存在的一些问题,NVIDIA 和字节跳动的机器学习团队联合开发了基于 GPU 的图像处理加速库 CV-CUDA,并拥有以下特点:
(1)Batch
支持 batch 操作,可以充分利用 GPU 高并发、高吞吐的并行加速特性,提升计算效率和吞吐率。
(2)Variable Shape
支持同一 batch 中图片尺寸各不相同,保证了使用上的灵活性。此外,在对图片进行处理时,可以对每张图片指定不同的参数。例如调用 RotateVarShape 算子时,可以对 batch 中每张图片指定不同的旋转角度。
(3)C/C++/Python 接口
在部署机器学习算法时需要对齐训练和推理流程。一般来说,训练时利用 python 进行快速验证,推理时利用 C++ 进行高性能部署,然而一些图像处理库仅支持 python,这给部署带来了极大的不便。如果在训练和推理采用不同的图像处理库,则又需要在推理端重新实现一遍逻辑,过程会非常繁琐。
CV-CUDA 提供了 C、C++ 和 Python 接口,可以同时服务于训练和推理场景。从训练迁移到推理场景时,也可免去繁琐的对齐流程,提高部署效率。
(4)独立算子设计
CV-CUDA 作为基础图像处理库,采用了独立算子设计,不需要预先定义流水线。独立算子的设计具有更高的灵活性,使调试变得更加的容易,而且可以使其与其他的图像处理交互,或者将其集成在用户自己的图像处理上层框架中。
(5)结果对齐 OpenCV
不同的图像处理库由于对一些算子的实现方式不一致导致计算结果难以对齐。例如常见的 Resize 操作,OpenCV、OpenCV-gpu 以及 torchvision 的实现方式都不一样,计算结果存在差异。因此如果在训练时用 OpenCV CPU 版本而推理时若要采用 GPU 版本或其他图像处理库,就会面临结果存在误差的问题。
在设计之初,我们考虑到当前图像处理库中,很多用户习惯使用 OpenCV 的 CPU 版本,因此在设计算子时,不管是函数参数还是图像处理结果上,尽可能对齐 OpenCV CPU 版本的算子。当用户从 OpenCV 迁移到 CV-CUDA 时,只需做少许改动便可使用,且图片处理结果和 OpenCV 一致,不需要重新训练模型。
(6)易用性
CV-CUDA 提供了 Image、ImageBatchVarShape 等结构体,方便用户的使用。同时还提供了 Allocator 类,用户可以自定义显存分配策略(例如用户可以设计显存池分配策略来提高显存分配速度),方便上层框架集成和管理资源。目前 CV-CUDA 提供了 PyTorch、OpenCV 和 Pillow 的数据转化接口,方便用户进行算子替换和进行不同图像库之间的混用。
(7)针对不同 GPU 架构的性能高度优化
CV-CUDA 可以支持 Volta、Turing、Ampere 等 GPU 架构,并针对不同架构 GPU 的特点,在 CUDA kernel 层面进行了性能上的高度优化,可在云服务场景中规模化部署。
算子数量及其性能
(1) CV-CUDA 目前提供了 25 种算子
包括常用的 CvtColor、Resize、Crop、PadStack、Normalize 等。当前算子能够覆盖大部分应用场景,后续将会支持更多算子。
算子清单:

图 4. CV-CUDA 支持算子清单
(2) 性能对比
在本文开头的背景模糊算法里,采用 CV-CUDA 替代 OpenCV 和 TorchVision 的前后处理后,整个推理流程的吞吐率提升了 20 倍以上。下图展示了在同一个计算节点上(2x Intel Xeon Platinum 8168 CPUs , 1x NVIDIA A100 GPU),以 30fps 的帧率处理 1080p 视频,采用不同的 CV 库所能支持的最大的并行流数。测试采用了 4 个进程,每个进程 batchSize 为 64。
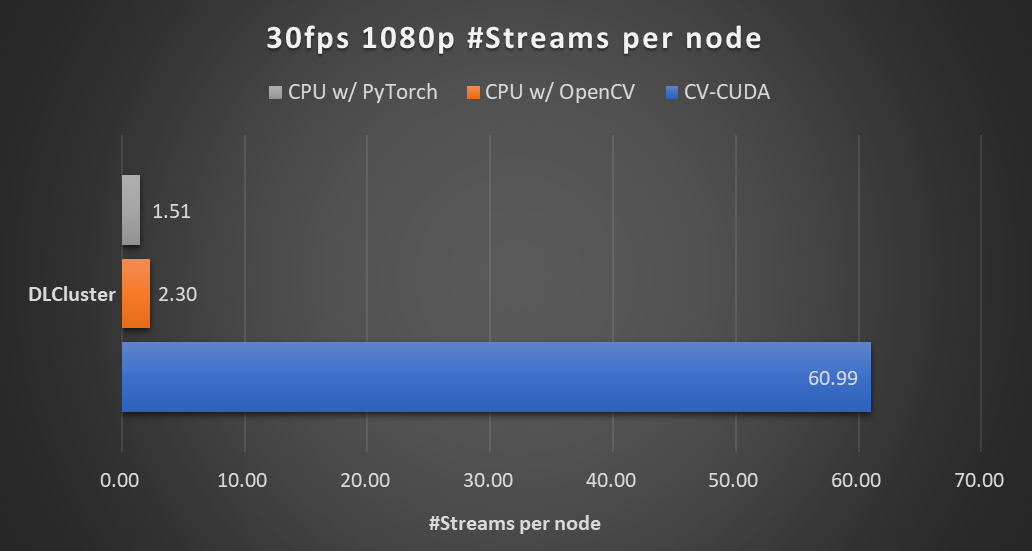
图 5. AI 背景模糊(2x Intel Xeon Platinum 8168 CPUs , 1x NVIDIA A100 GPU)
其中涉及到的前处理操作有:
Resize (Downscale)、Padding、Convert Data Type、Normalize 及 Image to Tensor
涉及到的后处理操作有:Tensor to Mask、Convert Data Type、Crop、Resize (Upscale)、Bilateral Filter (Denoise)、Gaussian Blur 及 Composite
对于单个算子的性能,我们也做了性能测试,下图的测试场景选用的图片大小为 480*360,CPU 选择为 Intel(R) Core(TM) i9-7900X,BatchSize 大小为 1,进程数为 1。
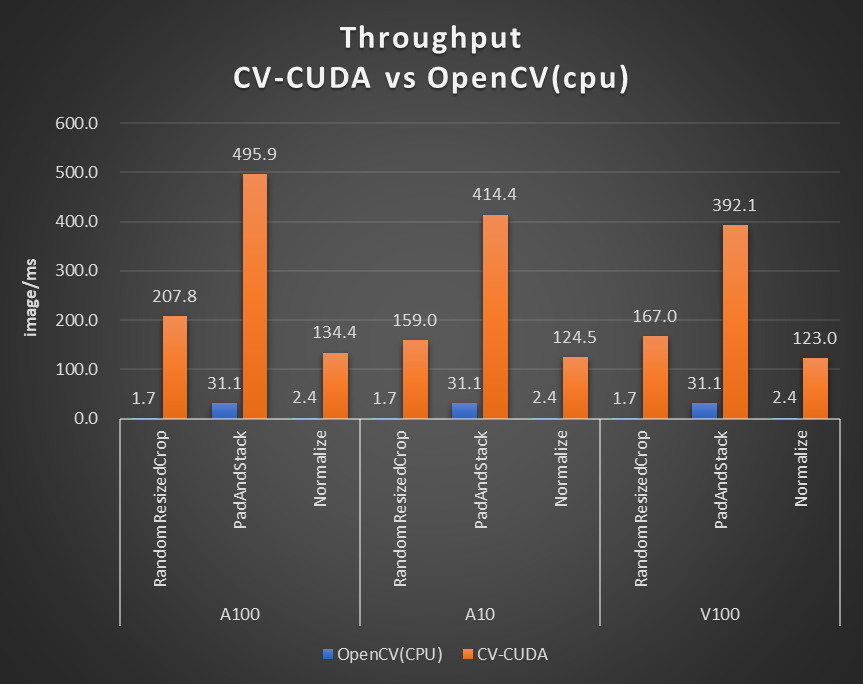
图 6. CV-CUDA 性能对比(CPU: Intel(R) Core(TM) i9-7900X CPU @ 3.30 GHz)
性能优化手段及例子
为了使 CV-CUDA 能够更加高效的运行在 GPU 上,我们采取了一系列的优化手段。
(1)kernel 融合
采用了大量的 kernel 融合策略,减少了 kernel launch 和 global memory 的访问时间。
(2)访存优化
采用了合并访存,向量化读写,shared memory 等策略,提高了数据读写的效率。
(3)异步处理
CV-CUDA 中所有算子均采用异步处理的方式,可以减少同步带来的等待耗时。
(4)高效计算
采用了 fast math、warp/block reduce、table lookup 等优化手段,可以有效提升计算效率。
(5)预分配显存
CV-CUDA 采用了预分配显存策略,并且提供了 Allocator 类,帮助使用者自定义显存分配策略或者可采取默认的显存分配策略。算子所需要的 buffer 和图片显存会在初始化阶段分配好,而在执行阶段不会再进行耗时的显存分配操作。
框架和 API
(1)CV-CUDA 整体架构
整个 CV-CUDA 库包含了以下几个组成部分
a. CV-CUDA 核心模块
核心模块包含了 C/C++ 和 Python API、NVCV 模块,Operator 算子模块以及 CV-CUDA Tools。
b. CV-CUDA Interop 模块
这个模块包含了和其他图像处理库以及推理框架的交互接口,目前支持 OpenCV、Pytorch 和 Pillow,后续将陆续加入其他图像处理库的交互接口。
c. CV-CUDA Tools/Tests
包含一些单元测试模块和工具函数
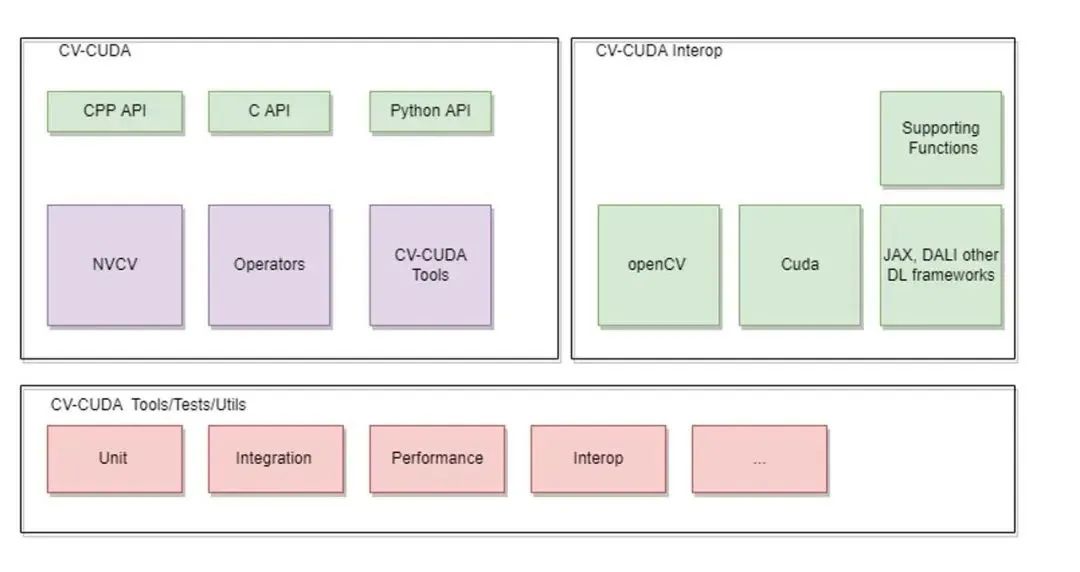
图 7. CV-CUDA 整体架构
(2)CV-CUDA 核心模块
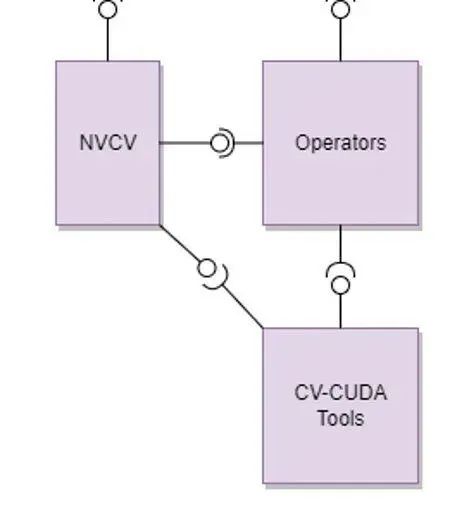
图 8. CV-CUDA 核心模块
核心模块包含以下几个部分
a. NVCV 核心支持库
包含 Image 抽象类、Memory workspace 类、Allocator 和 Batch/VarShapeBatch 类
b. Operators CV 算子
包含了各种独立算子(resize、filter 等等)
c. CV-CUDA Tools
包含了用于开发算子所需的各种功能函数
(3)API
图 9. ImageBatchVarShape
图 10. Resize
字节跳动机器学习团队应用案例
最初,CV-CUDA 项目的启动,主要目的是为了解决内部模型训练和推理过程中预处理瓶颈问题。以模型训练为例,正如大家所熟知的,传统的数据读取和预处理过程都是由 CPU 完成的。当 CPU 多核算力足够时,能为模型训练提供稳定高效的数据,但当 CPU 算力不足时,数据准备过程即会成为瓶颈,从而导致 GPU 利用率低下,造成 GPU 资源的浪费。一直以来,工业界有不少模型的训练推理过程,都存在因为 CPU 资源竞争而影响着性能的问题。这个问题在图像类模型,尤其是针对图像有比较复杂的预处理的场景中尤为明显。而随着 GPU 算力的不断提升,CPU 资源竞争将会越来越凸显出来。为了解决这个问题,非常朴素的一个想法是,将造成 CPU 算力不足的预处理逻辑搬到 GPU 上来进行,利用 GPU 庞大的算力,来高效的产生模型所需的数据。
但我们对这个 GPU 预处理算子库显然是有要求的。首先是性能需要足够好,如果预处理部分 GPU kernel 的实现跑起来非常慢,可能反而得不偿失;其次预处理搬到 GPU 上做,对模型迭代本身的影响要小,我们的预期是预处理 kernel 是见缝插针似的,在模型迭代过程中仅用一点点 GPU 闲散资源即可;最后,预处理 kernel 需要支持定制化,字节跳动机器学习团队内部训练的模型多,需要的预处理逻辑也多种多样,因此有许多定制的预处理逻辑需求。而 CV-CUDA 就很好的满足了以上几点的要求:每个 op 支持 batch 数据输入的设计,减少了频繁 Kernel launch 的开销,保证了高效的运行性能;每个 op 都支持 stream 对象和显存指针的传入,使得我们能更加灵活的配置相应的 GPU 资源;每个 op 设计开发时,既兼顾了通用性,也能按需提供定制化接口,能够覆盖内部的图片类预处理需求。
CV-CUDA 目前在抖音集团内部的多个线上线下场景得到了应用,比如搜索多模态,图片分类 等,下面分模型训练和推理分别介绍一个典型应用。(模型相关的细节这里就不多做介绍了,主要展示下 CV-CUDA 的应用场景和获得的收益。)
(1)模型训练
在字节跳动机器学习团队内部,CV-CUDA 在预处理逻辑复杂的训练任务上加速效果明显。在模型训练过程中,数据准备和模型迭代是个异步的过程,数据准备只要不比模型迭代来的慢,其性能就是满足需求的。但随着新一代强力 GPU 的投入使用,模型本身的计算时间被进一步缩短,因而对数据准备的性能要求越来越高。此时预处理逻辑一复杂,CPU 竞争就会变得激烈,这个时候 CV-CUDA 就能发挥很大的作用。
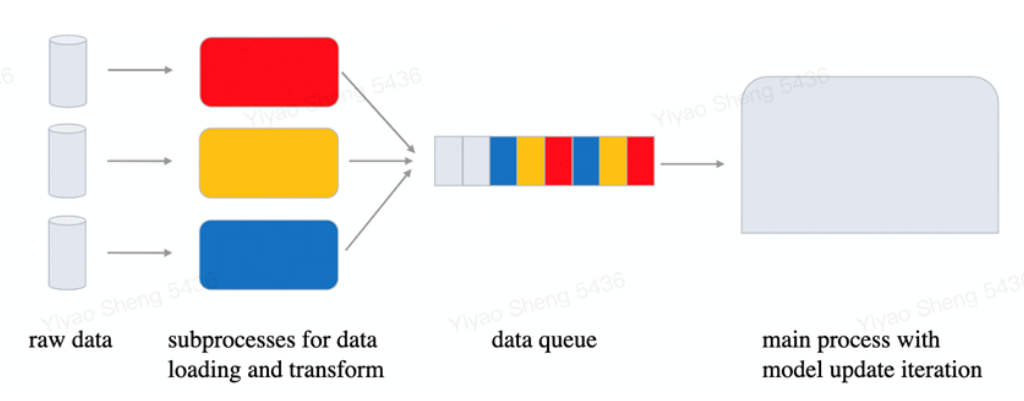
图 11. 模型训练流程示意图
字节跳动机器学习团队某个视频相关的多模态任务,CV-CUDA 应用后就获得了不小的性能收益。该任务预处理部分逻辑很复杂,既有多帧视频的解码,也有很多的数据增强,导致在 A100 上多卡训练时 CPU 资源竞争非常明显,因而虽然已经充分利用了 CPU(Intel Xeon Platinum 8336C)的多核性能,但数据预处理的速度仍然满足不了模型计算的需求。而使用了 CV-CUDA,预处理逻辑被全部迁移到了 GPU,相应的训练瓶颈也由数据预处理转移到了模型计算本身,从而在模型训练的整体性能上我们获得了近 90% 的收益。另一个获得收益的 OCR 任务也十分相似,其预处理链路有十几个算子,使用 CV-CUDA 后我们在 V100 上训练即获得了 80% 的加速。
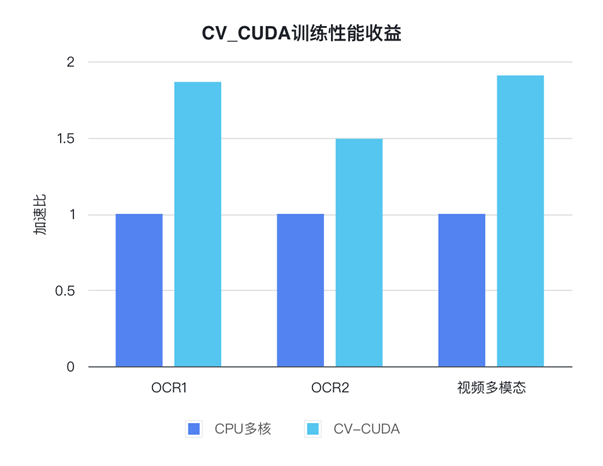
图 12. CV-CUDA 训练性能收益
需要注意的是,前后处理耗时占比不同的应用在使用 CV-CUDA 后带来的收益提升会有所差异。例如前后处理耗时占比为 50% 的应用,使用 CV-CUDA 后,端到端吞吐率提升的理论上限为原始的 2 倍(理论上限是指预处理耗时为 0,端到端中模型的耗时占比为 100%,实际上前后处理加速后,依然会有耗时,因此理论上限仅用于分析理想情况能达到的最大加速比);而前后处理占比 90%以上的应用,使用 CV-CUDA 后的吞吐率提升理论上限为原始的 10 倍以上。此外,CPU 性能的差异也会影响到最终的加速效果。
(2) 模型推理
模型推理和训练略有不同:因为模型训练时数据读取和模型更新是异步的,所以基本上提升模型训练性能可以与提高 GPU 利用率划等号。但模型推理过程,数据读取和模型计算是一个串行的过程,加速数据准备过程本身即会对整体性能造成直接影响。再加上模型推理时只涉及到模型前向的计算,计算量一般都较小,GPU 通常有足够的剩余资源来进行其他的工作。因而模型推理阶段,把预处理逻辑搬到 GPU 上来加速性能,既合理而又有可行性。

图 13. 模型推理流程示意图
字节跳动机器学习团队的某个搜索多模态任务,在使用 CV-CUDA 之后,整体的上线吞吐相比于用 CPU 做预处理时有了 2 倍多的提升,值得一提的是,这里的基线本身即是经过 CPU(Intel Xeon Platinum 8336C)多核等方式优化过后的结果,虽然涉及到的预处理逻辑较简单,但使用 CV-CUDA 之后加速效果依然非常明显。
附录
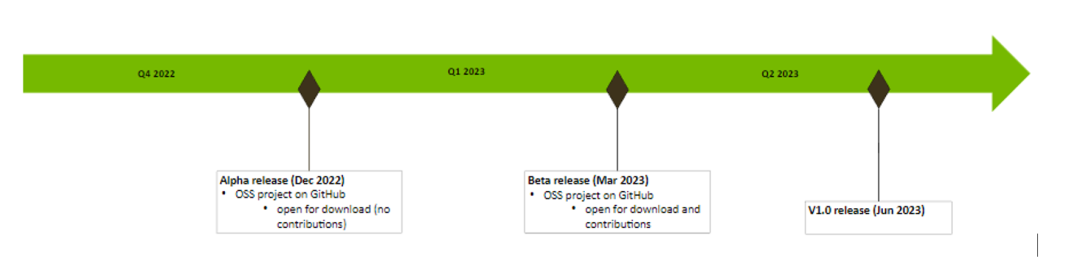
(1)开源计划
(2)代码示例
以图片分类为例,以下代码展示了如何利用 CV-CUDA 对图片进行预处理,以及如何和 Pytorch 进行交互。
流程图:

Python 代码:
import torchfrom torchvision import modelsfrom torchvision.io.image import read_file, decode_jpegimport numpy as np# Import CV-CUDA moduleimport nvcv"""Image Classification python sampleThe image classification sample uses Resnet50 based model trained on ImagenetThe sample app pipeline includes preprocessing, inference and post process stageswhich takes as input a batch of images and returns the TopN classification resultsof each image.This sample gives an overview of the interoperability of pytorch with CVCUDAtensors and operators"""# Set the image and labels filefilename = "./assets/tabby_tiger_cat.jpg"labelsfile = "./models/imagenet-classes.txt"# Read the input imagea filedata = read_file(filename) # raw data is on CPU# NvJpeg can be used to decode the image# to the necessary color format on the deviceinputImage = decode_jpeg(data, device="cuda") # decoded image in on GPUimageWidth = inputImage.shape[2]imageHeight = inputImage.shape[1]# decode_jpeg is currently limited to batchSize 1# and Planar format (CHW)# A torch tensor can be wrapped into a CV-CUDA Object using the "as_tensor"# function in the specified layout. The datatype and dimensions are derived# directly from the torch tensor.nvcvInputTensor = nvcv.as_tensor(inputImage, "CHW")# The input image is now ready to be used# The Reformat operator can be used to convert CHW format to NHWC# for the rest of the preprocessing operationsnvcvInterleavedTensor = nvcvInputTensor.reformat("NHWC")"""Preprocessing includes the following sequence of operations.Resize -> DataType Convert(U8->F32) -> Normalize(Apply mean and std deviation)-> Interleaved to Planar"""# Model settingslayerHeight = 224layerWidth = 224batchSize = 1# Resize# Resize to the input network dimensionsnvcvResizeTensor = nvcvInterleavedTensor.resize((batchSize, layerWidth, layerHeight, 3), nvcv.Interp.CUBIC)# Convert to the data type and range of values needed by the input layer# i.e uint8->float. A Scale is applied to normalize the values in the range 0-1nvcvConvertTensor = nvcvResizeTensor.convertto(np.float32, scale=1 / 255)"""The input to the network needs to be normalized based on the mean andstd deviation value to standardize the input data."""# Create a torch tensor to store the mean and standard deviation values for R,G,Bscale = [0.485, 0.456, 0.406]std = [0.229, 0.224, 0.225]scaleTensor = torch.Tensor(scale)stdTensor = torch.Tensor(std)# Reshape the the number of channels. The R,G,B values scale and offset will be# applied to every color plane respectively across the batchscaleTensor = torch.reshape(scaleTensor, (1, 1, 1, 3)).cuda()stdTensor = torch.reshape(stdTensor, (1, 1, 1, 3)).cuda()# Wrap the torch tensor in a CV-CUDA TensornvcvScaleTensor = nvcv.as_tensor(scaleTensor, "NHWC")nvcvBaseTensor = nvcv.as_tensor(stdTensor, "NHWC")# Apply the normalize operator and indicate the scale values are std deviation# i.e scale = 1/stddevnvcvNormTensor = nvcvConvertTensor.normalize(nvcvBaseTensor, nvcvScaleTensor, nvcv.NormalizeFlags.SCALE_IS_STDDEV)# The final stage in the preprocess pipeline includes converting the RGB buffer# into a planar buffernvcvPreprocessedTensor = nvcvNormTensor.reformat("NCHW")# Inference uses pytorch to run a resnet50 model on the preprocessed input and outputs# the classification scores for 1000 classes# Load Resnet model pretrained on Imagenetresnet50 = models.resnet50(pretrained=True)resnet50.to("cuda")resnet50.eval()# Run inference on the preprocessed inputtorchPreprocessedTensor = torch.as_tensor(nvcvPreprocessedTensor.cuda(), device="cuda")inferOutput = resnet50(torchPreprocessedTensor)"""Postprocessing function normalizes the classification score from the network and sortsthe scores to get the TopN classification scores."""# top results to print outtopN = 5# Read and parse the classeswith open(labelsfile, "r") as f:classes = [line.strip() for line in f.readlines()]# Apply softmax to Normalize scores between 0-1scores = torch.nn.functional.softmax(inferOutput, dim=1)[0]# Sort output scores in descending order_, indices = torch.sort(inferOutput, descending=True)# Display Top N Results[print("Class : ", classes[idx], " Score : ", scores[idx].item())for idx in indices[0][:topN]]
关于作者

张毅 | NVIDIA GPU计算专家团队的工程师
主要从事计算机视觉领域的算法加速工作,同时也是 CV-CUDA 项目的发起人,负责 CV-CUDA 项目早期的框架设计和算子开发工作。此外,他还是 PyTorch 转 TensorRT 编译工具 Torch-TensorRT 的核心开发人员。在加入 NVIDIA 之前,于腾讯优图从事计算机视觉算法研发工作。分别于浙江大学和上海交通大学获得学士和硕士学位。

郭若乾 | NVIDIA GPU计算专家团队的工程师
于浙江大学取得硕士学位后,他在 2020 年加入 NVIDIA,主要从事计算机视觉领域的算法加速工作,以及 PyTorch 模型转 TensorRT 编译工具 Torch-Tensor 的开发工作。作为 CV-CUDA 项目的主要开发人员,负责了 CV-CUDA 项目背景调研以及早期算子的开发优化工作。

盛一耀 | 字节跳动机器学习系统团队工程师
他是 CV-CUDA 项目主要的开发者之一。他于美国卡耐基梅隆大学获得硕士学位后,2019 年加入字节跳动,主要从事机器学习系统相关工作,对模型训练和推理性能优化有较深刻的理解。在 CV-CUDA 项目中,他在把握并提供字节跳动内部视觉相关算子需求的同时,也参与开发了许多 GPU 视觉类算子。
即刻点击 “阅读原文” 或扫描下方海报二维码,收下这份 GTC22 精选演讲合集清单,在NVIDIA on-Demand 上点播观看主题演讲精选、中国精选、元宇宙应用领域与全球各行业及领域的最新成果!

